
Joined April 2024
- Tweets 215
- Following 44
- Followers 702
- Likes 66
93 Photos and videos









Jun 9
𝗔𝘀𝗽𝗶𝗿𝗲 𝟭𝟯.𝟯 𝘀𝗵𝗶𝗽𝘀 𝗞𝘂𝗯𝗲𝗿𝗻𝗲𝘁𝗲𝘀 𝗱𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 📦
The new Aspire version brings first-class 𝗞𝘂𝗯𝗲𝗿𝗻𝗲𝘁𝗲𝘀 𝗮𝗻𝗱 𝗔𝗞𝗦 𝗱𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 in preview with Helm chart generation. You can declare a Kubernetes environment in your AppHost, run aspire deploy, and Aspire generates a complete Helm chart and applies it end-to-end against your cluster — no separate helm install, kustomize, or hand-rolled manifests required. aspire destroy removes the Helm release and namespace cleanly.
New first-class 𝗜𝗻𝗴𝗿𝗲𝘀𝘀 𝗮𝗻𝗱 𝗚𝗮𝘁𝗲𝘄𝗮𝘆 𝗔𝗣𝗜 𝗿𝗼𝘂𝘁𝗶𝗻𝗴 resources let you declare how traffic enters your Kubernetes cluster directly from the AppHost. Aspire generates the corresponding Ingress, IngressClass, Gateway, HTTPRoute, and cert-manager Certificate resources.
Learn more: aspire.dev/whats-new/aspire-…
#aspire #dotnet
2
2
85
Jun 2
𝗔𝘇𝘂𝗿𝗲 𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗲𝗿 𝗔𝗽𝗽𝘀 𝗘𝘅𝗽𝗿𝗲𝘀𝘀 (𝗽𝘂𝗯𝗹𝗶𝗰 𝗽𝗿𝗲𝘃𝗶𝗲𝘄) 💬
If you want to quickly upload an image and have a running app within minutes, you can use the new 𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗲𝗿 𝗔𝗽𝗽𝘀 𝗘𝘅𝗽𝗿𝗲𝘀𝘀. It’s simple to set up, requires only essential configuration, and is well-suited for prototypes, AI front-end applications, development tools, and agent backends.
𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗲𝗿 𝗔𝗽𝗽𝘀 𝗘𝘅𝗽𝗿𝗲𝘀𝘀 do not support advanced platform capabilities such as VNet integration, Private Endpoints, secrets management, managed identity, storage volumes, health probes, or custom domains.
You can also now use the Azure portal dedicated to container apps:
containerapps.azure.com/logi…
#azure #dotnet
1
51
May 26
𝗙𝗼𝘂𝗻𝗱𝗿𝘆 𝗟𝗼𝗰𝗮𝗹 𝟭.𝟭.𝟬 𝗶𝘀 𝗻𝗼𝘄 𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗹𝗲 💡
Foundry Local is Microsoft’s cross-platform local AI solution that allows you to run LLMs directly with no cloud dependency, no network latency, and no per-token costs.
The new version adds live audio transcription, text embeddings, and the Responses API, making Foundry Local a viable solution for a wide range of use cases.
Foundry Local offers advantages over Ollama by automatically detecting your hardware and downloading the most suitable model variant for your system specifications. This plug-and-play approach helps avoid memory allocation issues and reduces the need for technical trial and error.
Overall, it is designed to integrate directly into corporate workflows and the Microsoft AI stack.
𝗟𝗲𝗮𝗿𝗻 𝗺𝗼𝗿𝗲: learn.microsoft.com/en-us/az…
#dotnet #foundry
1
3
105
May 19
𝗖𝗹𝗼𝘀𝗲𝗱 𝗛𝗶𝗲𝗿𝗮𝗿𝗰𝗵𝗶𝗲𝘀 𝗮𝗿𝗲 𝗰𝗼𝗺𝗶𝗻𝗴 𝘁𝗼 𝗖# 💡
The new 𝗰𝗹𝗼𝘀𝗲𝗱 keyword will allow a class to be marked as closed, restricting inheritance so that derived classes can only be declared within the same assembly.
Closed hierarchies, closed enums, and unions together will give C# a complete compile-time exhaustiveness: the compiler tells you about the missing case instead of a runtime error.
Over the past week several "closed classes" PRs were merged into Roslyn: abstract-modifier restrictions and fixes to invalid type suggestions in inexhaustive switch expressions. That is the compiler groundwork for closed hierarchies.
Learn more: github.com/dotnet/csharplang…
#dotnet #csharp
1
108
May 12
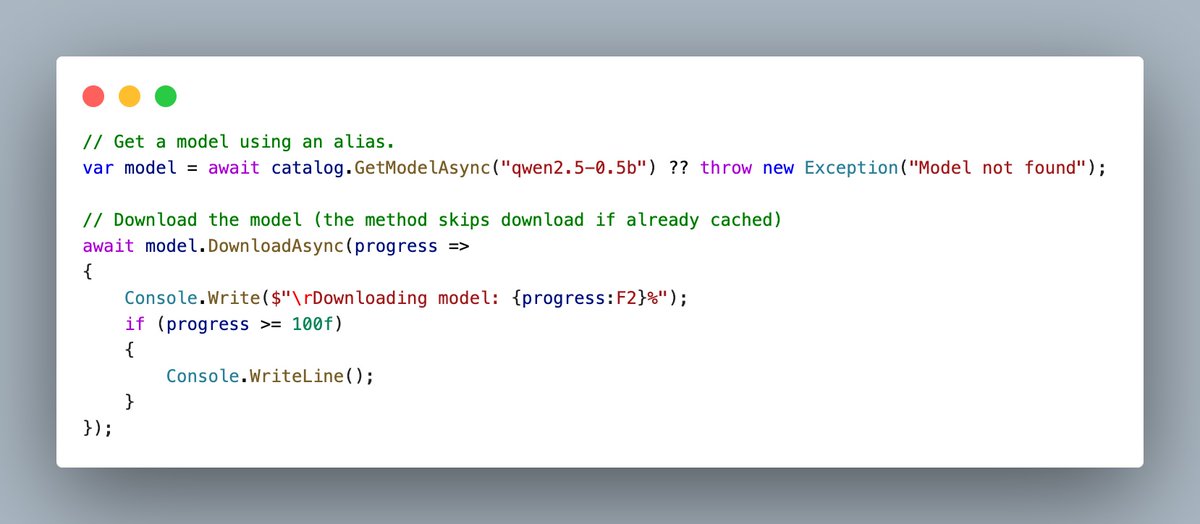
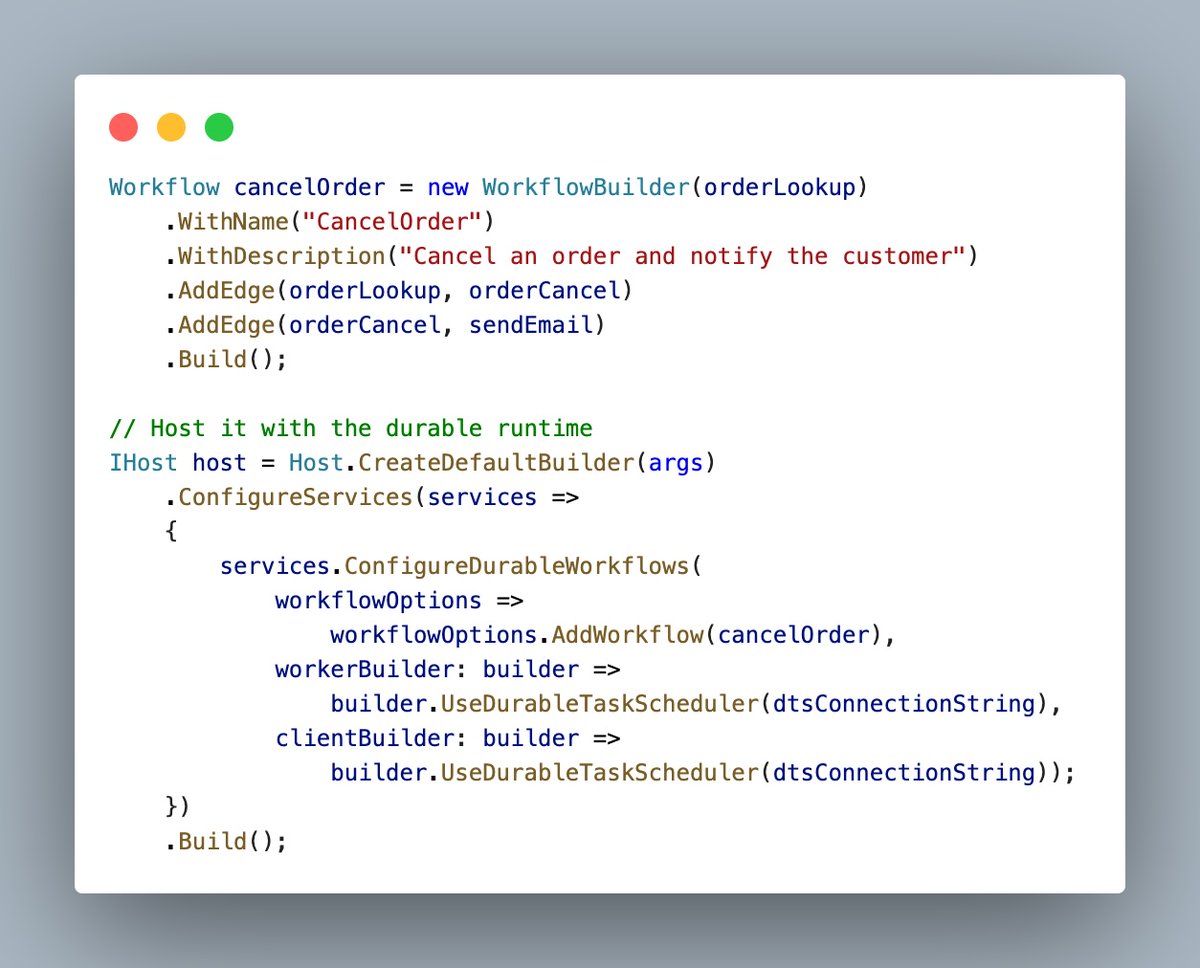
𝗗𝘂𝗿𝗮𝗯𝗹𝗲 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄𝘀 𝗶𝗻 𝘁𝗵𝗲 𝗠𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁 𝗔𝗴𝗲𝗻𝘁 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 🧭
The Agent Framework now has a 𝗱𝘂𝗿𝗮𝗯𝗹𝗲 workflow programming model via prerelease package 𝗠𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁.𝗔𝗴𝗲𝗻𝘁𝘀.𝗔𝗜.𝗗𝘂𝗿𝗮𝗯𝗹𝗲𝗧𝗮𝘀𝗸. You define executors that take input, do work, and produce output, then wire them into a directed graph with WorkflowBuilder. The framework checkpoints state via the Durable Task Scheduler so an orchestration survives process restarts and can span hours or days without losing context.
A key feature is that the same workflow runs locally in a single process during development, and using Azure Functions in production. The framework also includes built-in support for parallel agent execution, approval steps with human input, and MCP tool sharing.
devblogs.microsoft.com/dotne…
#dotnet #agentframework
1
92
May 5
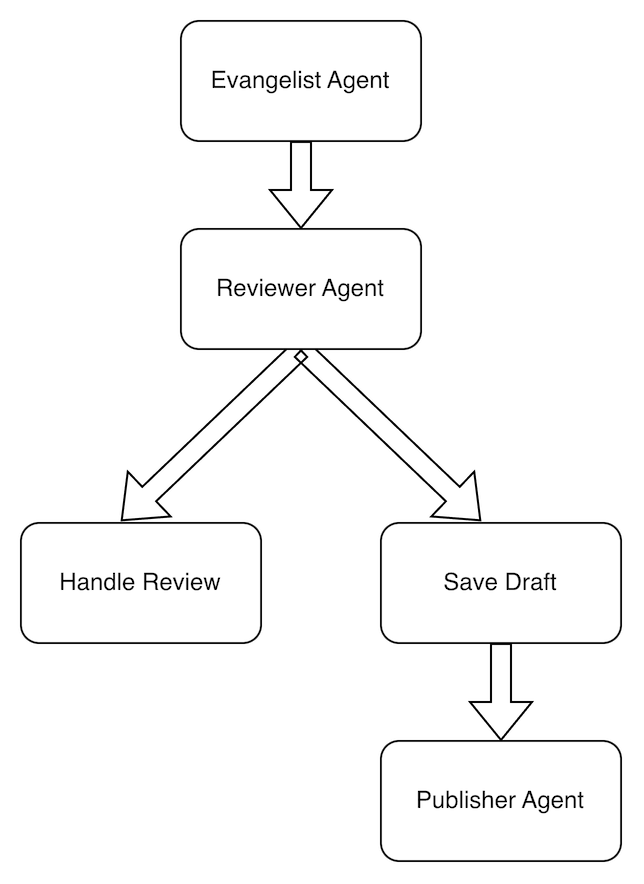
𝗚𝗼𝘃𝗲𝗿𝗻𝗶𝗻𝗴 𝗠𝗖𝗣 𝘁𝗼𝗼𝗹 𝗰𝗮𝗹𝗹𝘀 𝘄𝗶𝘁𝗵 𝘁𝗵𝗲 𝗔𝗴𝗲𝗻𝘁 𝗚𝗼𝘃𝗲𝗿𝗻𝗮𝗻𝗰𝗲 𝗧𝗼𝗼𝗹𝗸𝗶𝘁 💡
If you have an MCP-driven agent anywhere near production, you have probably had the conversation about what happens when a tool returns something it shouldn't. Microsoft launched the 𝗔𝗴𝗲𝗻𝘁 𝗚𝗼𝘃𝗲𝗿𝗻𝗮𝗻𝗰𝗲 𝗧𝗼𝗼𝗹𝗸𝗶𝘁 (Microsoft.AgentGovernance) - a new MIT-licensed package that adds a policy layer between your agent and its tools. Every tool call, resource access, and inter-agent message is evaluated against policy before execution. Deterministic - not probabilistic.
Here is the flow 👇
Agent Action ► Policy Check ► Allow/Deny ► Audit Log
The toolkit ships with a quick start called "Your first governed agent" that gets you a working policy in under a screenful of code. If you have not yet figured out how you'll satisfy your security team about agent behavior, this is a good starting point.
devblogs.microsoft.com/dotne…
#dotnet
60
Apr 28
𝗛𝗼𝘄 𝘁𝗼 𝗲𝘅𝘁𝗲𝗻𝗱 𝗖𝗼𝗽𝗶𝗹𝗼𝘁 𝗖𝗟𝗜 🧩
GitHub Copilot CLI has a 𝗳𝘂𝗹𝗹 𝗲𝘅𝘁𝗲𝗻𝘀𝗶𝗼𝗻 𝘀𝘆𝘀𝘁𝗲𝗺 that lets you create custom tools, intercept every agent action, inject context, block dangerous operations, and auto-retry errors - and there’s essentially zero public documentation about it. The extensions feature is experimental but is very promising.
The architecture is elegant. Your 𝗲𝘅𝘁𝗲𝗻𝘀𝗶𝗼𝗻 runs as a separate child process that talks to the CLI over JSON-RPC via stdio.
If you’ve used Claude Code hooks, you might think this is the same concept but it's quite different. Claude Code hooks are shell commands defined in a JSON settings file. They fire at lifecycle points and execute commands. That’s useful, but limited. Copilot CLI extensions are programmable processes that participate in the agent loop.
How to start: check the video by the 𝗦𝘁𝗲𝘃𝗲 𝗦𝗮𝗻𝗱𝗲𝗿𝘀𝗼𝗻 👇
youtube.com/watch?v=HcjUnrS4…
#github #copilotcli #copilot
162
Apr 21
𝗥𝗲𝗺𝗼𝘁𝗲 𝗰𝗼𝗻𝘁𝗿𝗼𝗹 𝘃𝗶𝗮 𝗖𝗼𝗽𝗶𝗹𝗼𝘁 𝗖𝗟𝗜 𝗶𝗻 𝗽𝘂𝗯𝗹𝗶𝗰 𝗽𝗿𝗲𝘃𝗶𝗲𝘄 🏖️
With the new remote control for Copilot CLI, you can start a session on your machine and continue monitoring and steering it from your phone or browser.
Think about it:
• Run long tasks locally
• Walk away from your desk
• Check progress and intervene in real time
• Approve actions or adjust direction remotely
This is a shift toward more asynchronous, agent-style development where you supervise instead of constantly driving.
Start with: 𝗰𝗼𝗽𝗶𝗹𝗼𝘁 --𝗿𝗲𝗺𝗼𝘁𝗲
Note: The remote control and CLI policies has to be enabled from an Github administrator first.
github.blog/changelog/2026-0…
#GitHub #Copilot
84
Apr 15
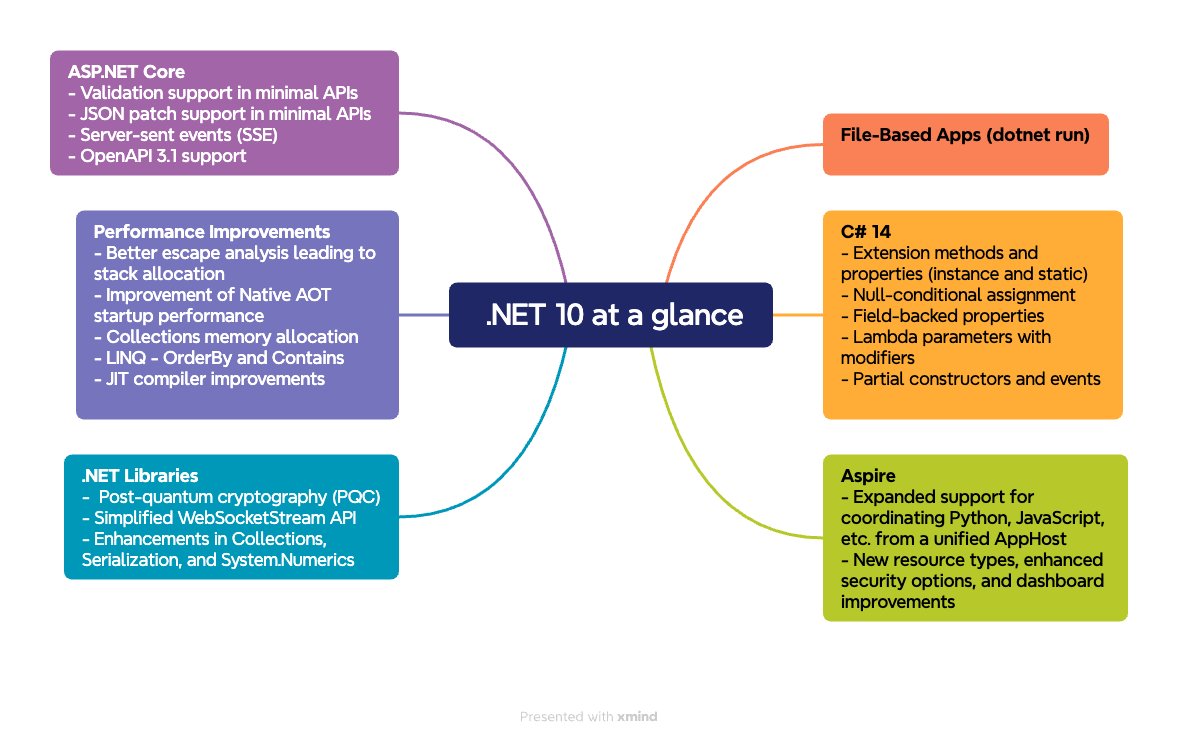
.𝗡𝗘𝗧 𝟭𝟭 𝗣𝗿𝗲𝘃𝗶𝗲𝘄 𝟯 𝗯𝗿𝗶𝗻𝗴𝘀 𝘂𝗽𝗱𝗮𝘁𝗲𝘀 𝘁𝗼 𝗱𝗼𝘁𝗻𝗲𝘁 𝗿𝘂𝗻 𝗮𝗻𝗱 𝗮𝗱𝘃𝗮𝗻𝗰𝗲𝘀 𝗶𝗻 𝘂𝗻𝗶𝗼𝗻 𝘁𝘆𝗽𝗲 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 🔎
🔹IDE support improvements for 𝘂𝗻𝗶𝗼𝗻 types (note that polyfills are still required)
🔹𝗱𝗼𝘁𝗻𝗲𝘁 𝗿𝘂𝗻 -e (inline environment variables)
🔹File-based apps → multi-file support (#:include)
🔹dotnet watch improvements with Aspire integration
and more...
Start today:
devblogs.microsoft.com/dotne…
#dotnet #uniontypes
1
2
9
416
Apr 16
Apr 15

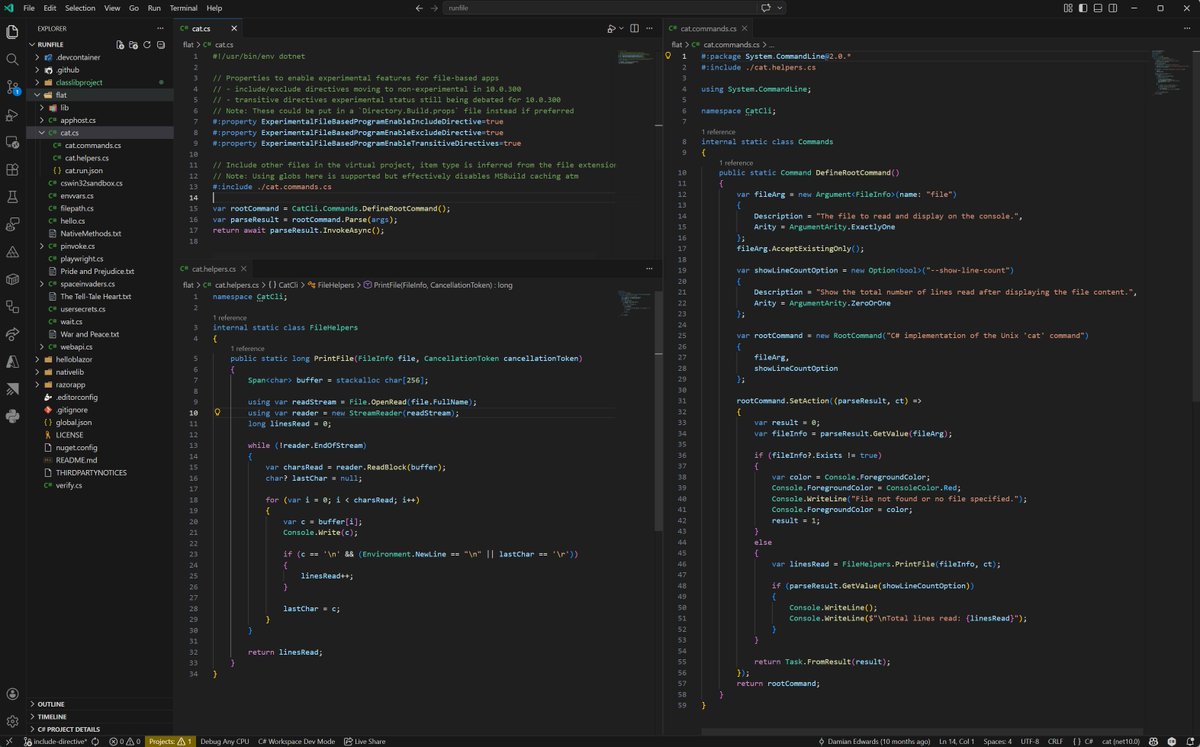
C# file-based apps with multiple files anybody? Coming in .NET 10.0.300 & future .NET 11 previews...
@dotnet
github.com/DamianEdwards/run…
59
Apr 7
𝗦𝘁𝗼𝗽 𝗲𝘅𝗽𝗹𝗮𝗶𝗻𝗶𝗻𝗴 .𝗡𝗘𝗧 𝘁𝗼 𝘆𝗼𝘂𝗿 𝗔𝗜 𝘄𝗶𝘁𝗵 𝗱𝗼𝘁𝗻𝗲𝘁-𝘀𝗸𝗶𝗹𝗹𝘀 💬
𝗱𝗼𝘁𝗻𝗲𝘁-𝘀𝗸𝗶𝗹𝗹𝘀 is a community-built CLI for installing and managing skills that AI coding agents can use when working on .NET projects.
Probably you have tried asking Claude for Entity Framework in a .NET 8 project and getting EF6 patterns and explaining to Copilot that Blazor Server and WebAssembly aren’t the same.
This catalog of community driven skills will fix this.
You can choose among many various skills or even get concrete skill recommendations for your project using:
𝗱𝗼𝘁𝗻𝗲𝘁 𝘀𝗸𝗶𝗹𝗹𝘀 𝗿𝗲𝗰𝗼𝗺𝗺𝗲𝗻𝗱
github.com/managedcode/dotne…
#dotnet #ai
5
36
251
12,943
Mar 31
𝗧𝗲𝗻 𝗠𝗼𝗻𝘁𝗵𝘀 𝗼𝗳 𝗖𝗼𝗽𝗶𝗹𝗼𝘁 𝗖𝗼𝗱𝗶𝗻𝗴 𝗔𝗴𝗲𝗻𝘁 𝗶𝗻 𝗱𝗼𝘁𝗻𝗲𝘁/𝗿𝘂𝗻𝘁𝗶𝗺𝗲 💡
Steven Toub published the most data-driven public retrospective on AI coding agents in a production open-source project that has appeared to date. Over 10 months, GitHub Copilot Coding Agent submitted 878 pull requests to dotnet/runtime. 535 were merged, a 67.9% success rate. In month one, the merge rate was 41.7%. By month ten, it was 71%. Of all merged Copilot PRs, 0.6% were reverted, which is roughly in line with the human PR revert rate on the repository.
The dotnet/runtime team went from "we don't have enough engineers to work on these issues" to "we don't have enough reviewer bandwidth to process the incoming PRs."
Writing code is no longer the constraint. Reviewing is(as expected).
devblogs.microsoft.com/dotne…
#dotnet #copilot
2
3
204
Mar 31
The post includes breakdowns by PR category (bug fixes, tests, refactors, new features), common failure modes (build breaks, test failures, incorrect logic), and the types of tasks where Copilot performs well versus poorly.
In conclusion: Copilot is excellent at implementing 𝘄𝗲𝗹𝗹-𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗲𝗱 𝗰𝗵𝗮𝗻𝗴𝗲𝘀, 𝘃𝗲𝗿𝘆 𝗴𝗼𝗼𝗱 𝗮𝘁 𝗶𝗻𝘃𝗲𝘀𝘁𝗶𝗴𝗮𝘁𝗶𝗻𝗴 𝗶𝘀𝘀𝘂𝗲𝘀, 𝗮𝗻𝗱 𝗿𝗲𝗹𝗮𝘁𝗶𝘃𝗲𝗹𝘆 𝗽𝗼𝗼𝗿 𝗮𝘁 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝗶𝗻𝗴 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻𝘀, 𝗲𝘀𝗽𝗲𝗰𝗶𝗮𝗹𝗹𝘆 𝗶𝗻 𝗹𝗮𝗿𝗴𝗲 𝗰𝗼𝗱𝗲𝗯𝗮𝘀𝗲𝘀 𝘁𝗵𝗮𝘁 𝗿𝗲𝗾𝘂𝗶𝗿𝗲 𝗯𝗿𝗼𝗮𝗱 𝘂𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴. If your team is seriously evaluating AI coding agents, this is a don’t-miss post: the dotnet/runtime context provides real-world complexity that synthetic benchmarks cannot replicate.
99
Mar 24
𝗔𝗴𝗲𝗻𝘁 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸: 𝗕𝗮𝗰𝗸𝗴𝗿𝗼𝘂𝗻𝗱 𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲𝘀 𝗦𝗼𝗹𝘃𝗲 𝘁𝗵𝗲 𝗟𝗼𝗻𝗴-𝗥𝘂𝗻𝗻𝗶𝗻𝗴 𝗔𝗴𝗲𝗻𝘁 𝗧𝗶𝗺𝗲𝗼𝘂𝘁 💤
Agents using reasoning models can take minutes to finish a task - deep research, multi-step analysis, lengthy content generation. Keeping an HTTP connection open for that duration is unreliable: load balancers time out, mobile clients disconnect, and any failure discards all progress made so far.
Background responses in 𝗠𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁 𝗔𝗴𝗲𝗻𝘁 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 let you offload these long-running operations so your application stays responsive and resilient, regardless of how long the agent takes to think.
#dotnet #ai
devblogs.microsoft.com/agent…
1
125
Mar 23
𝗔𝘀𝗽𝗶𝗿𝗲 𝗖𝗼𝗻𝗳 𝗧𝗼𝗱𝗮𝘆 ⏰
Aspire got its own conference and dropped the ".NET" from its name.
AspireConf streams live today alongside the Aspire 13.2 release, which brings TypeScript AppHost support, Java integrations, and an agent-ready CLI.
Agenda: aspire.dev/aspireconf/?cid=a…
#dotnet #aspire #aspireconf
3
131
Mar 17
𝗘𝗻𝗵𝗮𝗻𝗰𝗲𝗺𝗲𝗻𝘁𝘀 𝗶𝗻 𝗘𝗙 𝗖𝗼𝗿𝗲 𝟭𝟭 𝗣𝗿𝗲𝘃𝗶𝗲𝘄 𝟮 𝗳𝗼𝗿 𝗦𝗤𝗟 𝗦𝗲𝗿𝘃𝗲𝗿 📊
🔸 Support for MaxBy() and MinBy() operators in LINQ queries.
🔸 Integration with SQL Server DiskANN vector indexes and the new VECTOR_SEARCH() function, enabling high-performance vector similarity search scenarios.
🔸 Create SQL Server full-text catalogs and indexes directly from EF Core.
Support for FREETEXTTABLE() and CONTAINSTABLE() full-text search functions.
🔸 Support for JSON_CONTAINS() to simplify querying JSON data stored in SQL Server.
EF Core 11 requires the .NET 11 SDK.
learn.microsoft.com/en-us/ef…
#dotnet #efcore
1
131
Mar 10
𝗡𝘂𝗚𝗲𝘁 𝘀𝘂𝗽𝗽𝗹𝘆 𝗰𝗵𝗮𝗶𝗻 𝗮𝘁𝘁𝗮𝗰𝗸 - 𝘄𝗼𝗿𝘁𝗵 𝗿𝗮𝗶𝘀𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝘆𝗼𝘂𝗿 𝘁𝗲𝗮𝗺 𝘁𝗵𝗶𝘀 𝘄𝗲𝗲𝗸 🔐
Four malicious packages (NCryptYo, DOMOAuth2, IRAOAuth2.0, SimpleWriter) targeted ASP.NET developers using typosquatting and JIT hooking.
The goal wasn't to compromise the developer's machine - it was to compromise the applications being built. NCryptYo mimicked Windows' native CNG cryptography provider at the namespace level and installed a local proxy; companion packages exfiltrated ASP.NET Identity data and injected attacker-controlled authorization rules that persisted into deployed production apps.
socket.dev/blog/four-malicio…
#dotnet
1
2
81
Mar 10
Over 4,500 downloads before removal. The packages are gone from NuGet.org, but the method is worth understanding because the next campaign will use it again. 📌 𝗧𝗵𝗲 𝗽𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗮𝗰𝘁𝗶𝗼𝗻: if you don't have automated NuGet dependency scanning in CI - via Socket, Snyk, or GitHub's built-in Dependabot alerts with NuGet support - this is a good week to add it. The attack surface is your build pipeline, not just your runtime.
53