
Joined August 2010
- Tweets 786
- Following 584
- Followers 626
- Likes 1,781
98 Photos and videos






Pinned Tweet

Jan 26
no video team. no screen recording.
claude code remotion /skills ~1 hr a few prompts
the wild part: it pulls directly from supabase via mcp. the app literally renders itself
posting my workflow next
who else has been testing remotion claude code?
drop your videos

Remotion now has Agent Skills - make videos just with Claude Code!
$ npx skills add remotion-dev/skills
This animation was created just by prompting 👇
4
1
14
2,492
Jun 8
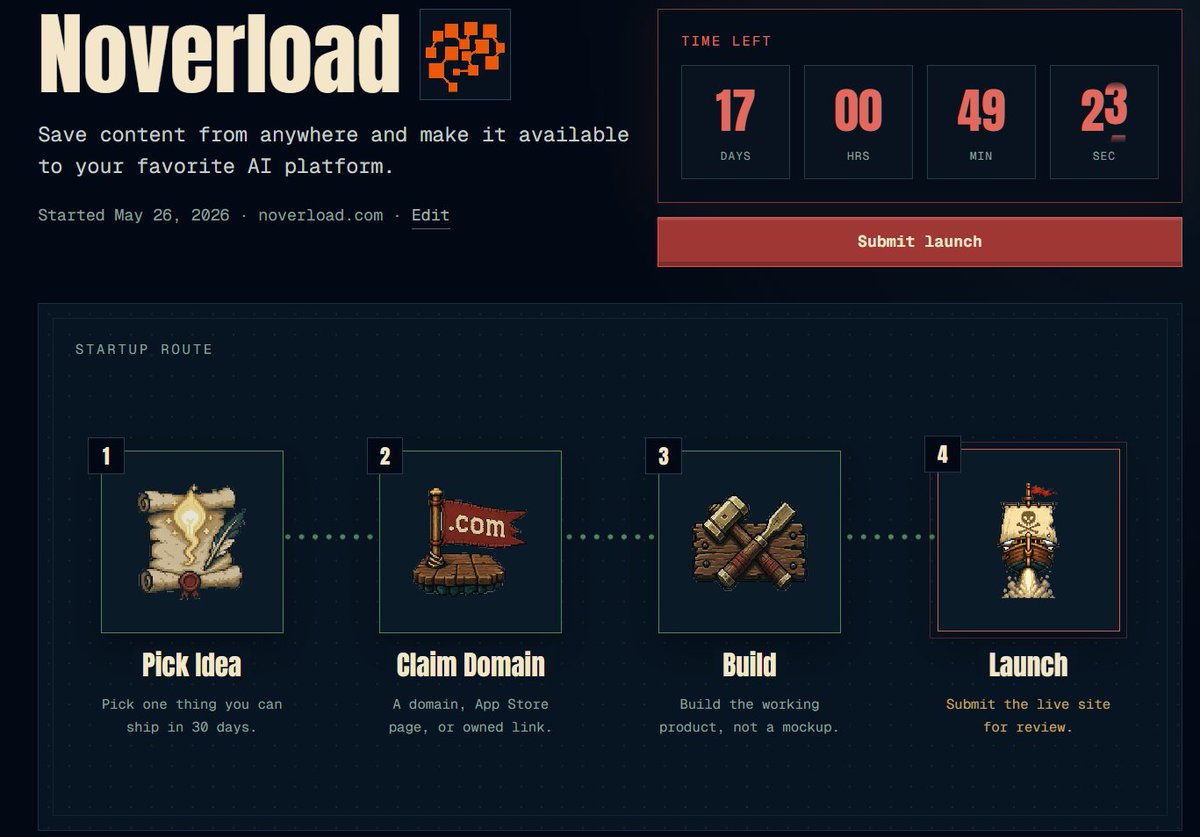
spent my first 13 days not adding features to noverload
i fixed the positioning instead
that's the @shipordie_ effect
the clock forces you onto what actually matters, not what feels productive
17 days till re-launch
2
21
Jun 3
might not look like much but this is the result of 8 months of research and going deep down the algorithmic trading rabbit hole
not a single trade executed by me today
built with claude code with research by noverload
more on this coming soon
1
86
May 28
nobody's getting rich letting an agent trade their robinhood account
the people getting rich are selling retail the agent
but the signal is loud: agent trading just became infrastructure
next 18 months are about one.. thing using ai to translate real edge into algos not agents
May 27

Your strategy shouldn't sleep just because you do.
Connect your AI agent to a Robinhood Agentic Account to explore trade ideas, build and rebalance portfolios, program custom tools, and place trades as your strategy evolves.
Rolling out now.
Learn more: rbnhd.co/AgenticTrading

100
May 26
did not expect to wake up and become pirate
joined shipordie by @jackfriks & @marclou
the gap between "im building this" and "I shipped this" is accountability
find a crew that calls you out or keep telling yourself soon
took the plunge. looking forward to meeting the crew!
2
6
86
May 23
Just hit $20MRR!
Might not seem like much but is a signal to keep building and shift to marketing
Recent Milestones
- 704 things saved
- 84 signups
- SEO bringing in 1-2 users regularly
Now the focus is on conversion and positioning
6
111
Apr 22
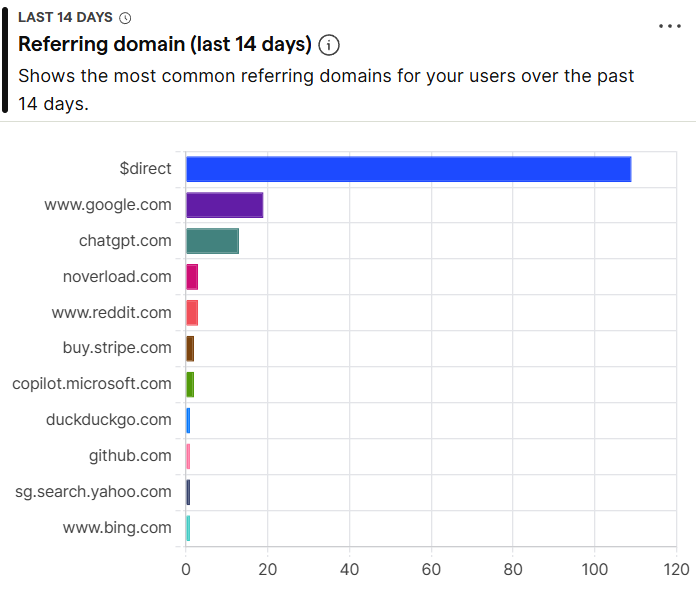
saas builders: fix your indexing
i ignored it for months. traffic was dead.
spent weeks fixing it. now seeing:
google traffic up → chatgpt sending visitors → reddit too
seo in 2026 isn't just google anymore.
6
9
131
Apr 9
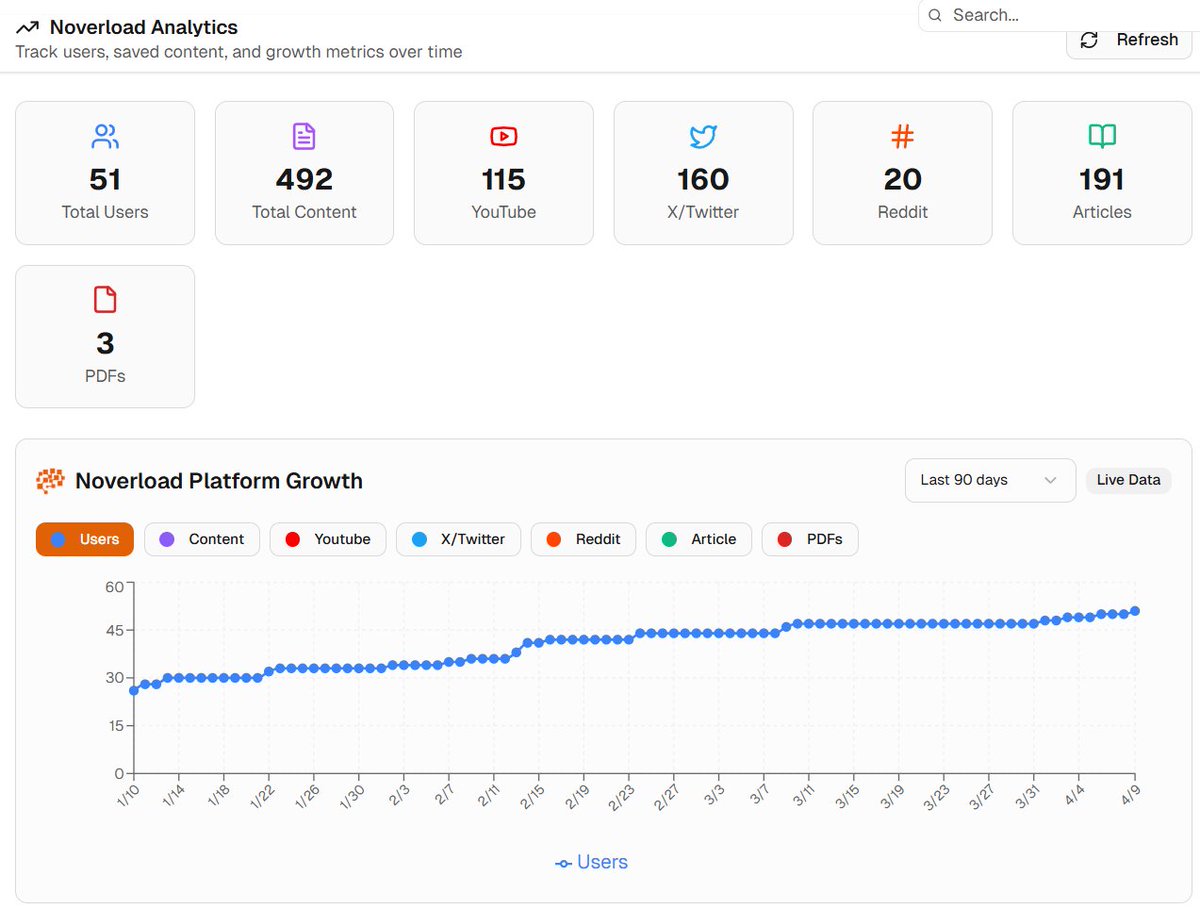
karpathy second brains, knowledge bases, and personal wiki trend is real
noverload: 51 users. ~500 saves. steady growth
building easy. reaching the right people is the real game
if you're saving content and want to actually use it later - this is what i'm building
1
5
56
Apr 7
Saw karpathy's post about LLM knowledge bases and
realized I'm we're already 80% there with noverload
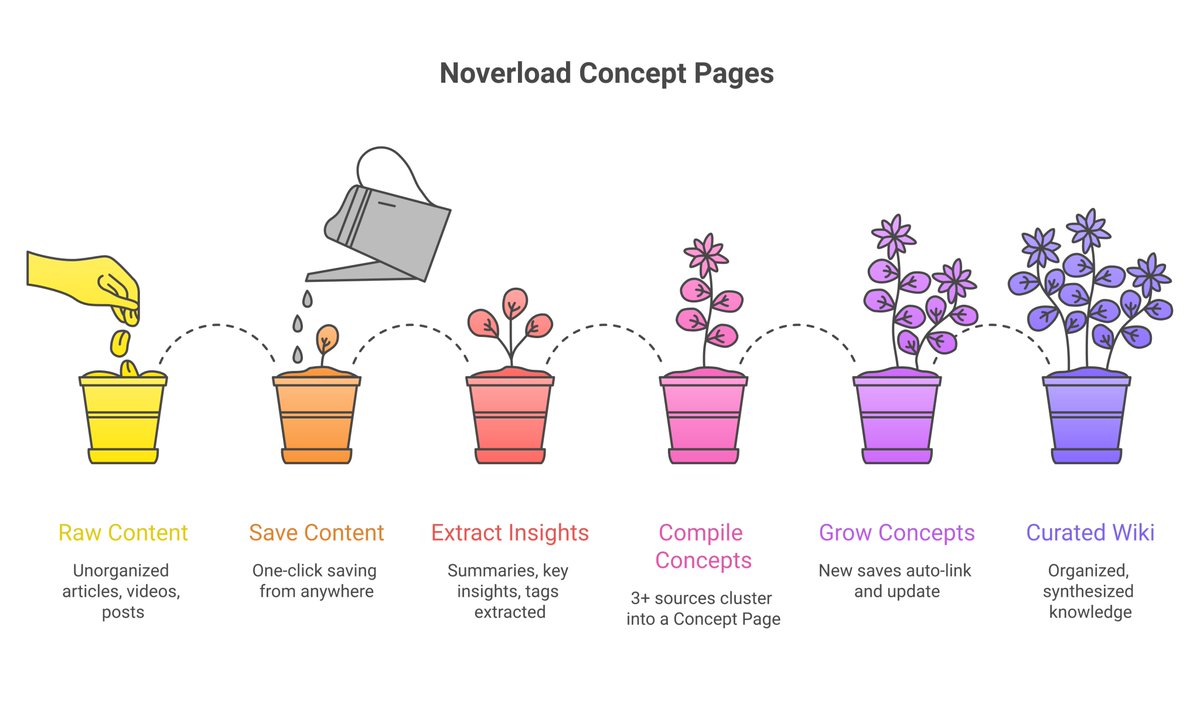
shipped concept pages this week:
save sources on a topic → auto-compiles into a wiki page
going from "save for later" tool → personal knowledge compiler
2
7
102
Apr 5
"I think there is room here for an incredible new product instead of a hacky collection of scripts."
agreed.
been building Noverload for exactly this
save content. compile it. query it. connect to claude via MCP
the personal knowledge base that AI can actually use
Demo here
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1
3
700
Mar 12
claude code is now my trade engineer
reverse engineered my strategy. coded it into sierra chart. now it trades for me
first day actually profitable so far: $444
early, but something might be clicking
1
3
92
Mar 9
been heads down. here's what shipped lately:
– second agency project delivered (awards platform)
– noverload growing (44 users now)
– building an automated trading system with claude code (still losing money)
less posting. more output.
felt good. but i'm back!
2
6
168
Mar 6
it's alive!
everyone's talking about openclaw and polymarket trading bots
meanwhile i'm over here using claude code to trade futures
now i can lose money faster than ever before.
automation is beautiful
3
158
Mar 1
everyone who's tried automated trading has a story about why it didn't work
spent the weekend building one anyway with claude code
either ai changes the game or i join the graveyard.
let's see
2
61
Feb 24
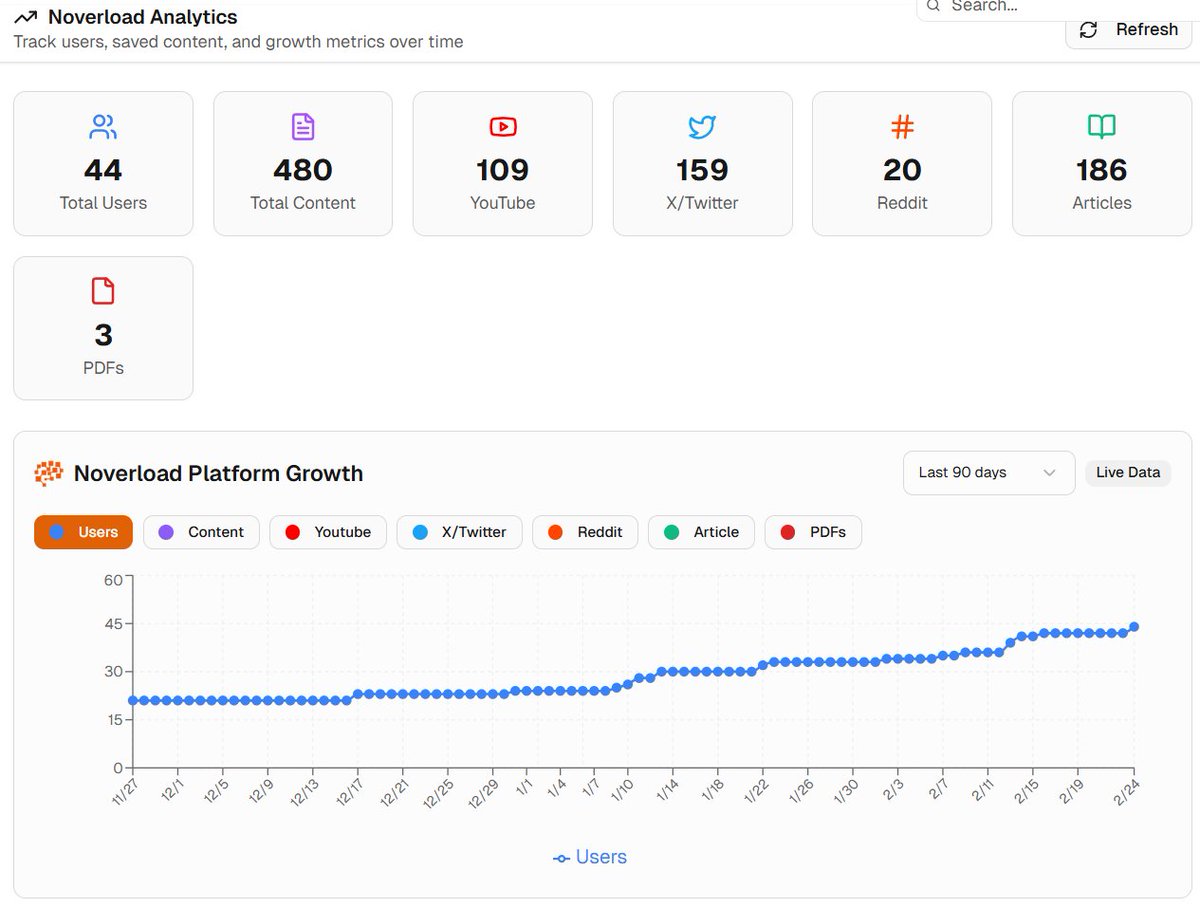
build in public update!
→ 44 users
→ 480 content saves
→ 109 youtube, 159 tweets, 186 articles saved
not hockey stick growth. just people actually using it.
that's enough to keep going
6
9
109
Feb 21
the lie: "you can be anything."
the truth:
you can build anything.
one was a story we told kids
the other is actually possible now
2
6
53
Feb 21
karpathy buying a mac mini to tinker is the signal
not the hype. not the sales numbers. not the vc takes
when the guy who literally helped build this stuff wants to setup openclaw himself?
that's when you pay attention
the builders always know
Feb 20
Bought a new Mac mini to properly tinker with claws over the weekend. The apple store person told me they are selling like hotcakes and everyone is confused :)
I'm definitely a bit sus'd to run OpenClaw specifically - giving my private data/keys to 400K lines of vibe coded monster that is being actively attacked at scale is not very appealing at all. Already seeing reports of exposed instances, RCE vulnerabilities, supply chain poisoning, malicious or compromised skills in the registry, it feels like a complete wild west and a security nightmare. But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.
Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. I also love their approach to configurability - it's not done via config files it's done via skills! For example, /add-telegram instructs your AI agent how to modify the actual code to integrate Telegram. I haven't come across this yet and it slightly blew my mind earlier today as a new, AI-enabled approach to preventing config mess and if-then-else monsters. Basically - the implied new meta is to write the most maximally forkable repo and then have skills that fork it into any desired more exotic configuration. Very cool.
Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). There are also cloud-hosted alternatives but tbh I don't love these because it feels much harder to tinker with. In particular, local setup allows easy connection to home automation gadgets on the local network. And I don't know, there is something aesthetically pleasing about there being a physical device 'possessed' by a little ghost of a personal digital house elf.
Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
2
117
Feb 20
my gaming pc hasn't loaded a game in months
rtx 3090. 64gb ram. 24-core amd
built it in 2023 to play games. now it runs local AI models and backtests 6 years of futures trading data
replaced my gaming hours with building hours
same machine, completely different life
2
6
98
Feb 18
the "quit your job to build" advice is backwards
i think the opposite. my 9-5 taught me:
- how to ship under constraints
- what users actually pay for
- how to build without burning out
the real question: what has your day job taught you that helped you ship?
1
5
49
Feb 17
rebuilding my app's onboarding flow and looking for inspiration
what's the best onboarding experience you've ever had in an app? or what is yours?
here's what it looks like right now (video below)
name the app and what made it click for you?
3
119
Feb 16
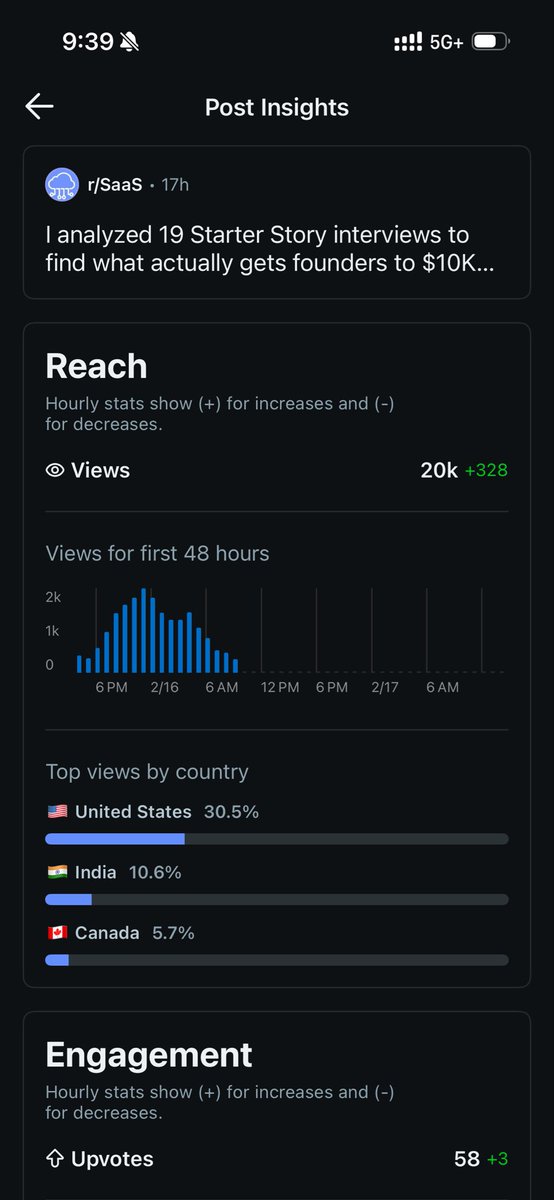
What does it take to get to 10k MRR?
I wanted to know so I researched interviews from Starter Story and shared findings in the article here
Biggest takeaway is distribution always wins
Already followed the strategy and got 20k views on r/SaaS with this exact article

2
77