
Global Head of AI at @inveniamio | Launching soon: @NVNM_chain | God-fearing husband💍@megconnolly_
Joined June 2012
- Tweets 12,964
- Following 266
- Followers 34,472
- Likes 2,976
1,014 Photos and videos












Pinned Tweet

Today, we're announcing the launch of @NVNM_Chain : a blockchain purpose-built for AI Agent accountability. That's it. That's all it does. But the problem it addresses could not be more important.
Everyone in the AI world is trying to control AI Agents from the model-side or with increasingly complex agentic frameworks. They're all doomed to fail for a very simple reason. There are infinite ways to be wrong, and there's only one way to be "right". So you have to anchor Ai-generated outputs to hard reality.
We've been working on this for years. Not only does blockchain-based attestation solve the Black Box problem, it also allows you to avoid centralizing your data, sending copies back and forth, and losing control of it. We've used the underlying technology to enable over $90 BILLION worth of assets to have real-time price discovery, using AI, 24 hours a day. Before that, these assets got valued once a year (at most).
Everyone is focused on a world that is adopting AI for the first time. And that's an important problem! But what happens when everyone else has AI too? How can you trust those systems to deal with each other? There will have to be an environment that controls those interactions. Otherwise it will be survival-of-the-fittest. A game no one wants to play.
So, we built NVNM Chain for an AI-enabled world; an agentic future. But the world changes faster than ever, and the future is NOW.
nvnmchain.io/
4
11
35
2,455
Anthropic shipped two models today. Same brain. Two passports.
The story of how we got here is better than the launch itself.
Rewind to April 7. Anthropic announces Claude Mythos Preview and refuses to release it. The stated reason: the model got too good at hacking. They called it a watershed moment for security. It was the first time a major lab withheld a model over capability concerns since OpenAI sat on GPT-2 in 2019. Except this time nobody thought it was marketing.
The coverage was unhinged. A leaked internal memo called it the most capable model Anthropic had ever trained. The company was briefing US government officials on offensive cyber implications before most of the world knew the model existed. The Motley Fool ran a piece about shockwaves through the cybersecurity industry and a coalition with Nvidia, Amazon, Apple, Google, and Microsoft. Security analysts noted the average window between a bug being disclosed and exploited in the wild had already collapsed to about 12 hours, and warned a model like this breaks the patching cycle the global economy depends on.
Instead of a launch, we got a private club. Project Glasswing. AWS, Microsoft, Apple, CrowdStrike and roughly 50 others received monitored access to hunt bugs in the software everyone runs on. In two months they found more than ten thousand high or critical severity vulnerabilities in the world's most systemically important code. Ten thousand. Last week the club expanded to about 150 organizations across more than 15 countries, including India's national cyber agencies.
The rest of us watched Polymarket, where a June release was trading in the mid 90s after backend sightings and press leaks.
Today it happened. Sort of.
Claude Mythos 5 is the raw model. Only Glasswing members get it. Claude Fable 5 is the exact same model weights wearing a muzzle, and anyone can use it right now. The naming is on the nose. The myth stays locked away. The fable is the version with a moral attached, safe for general audiences.
The muzzle is the interesting part. Every request gets screened by a probe reading the model's internal activations. Not your words. Its thoughts. If the probe gets suspicious, a second AI reviews the conversation. If both agree you are doing offensive cyber work or dangerous biology, your query silently routes to the older Claude Opus 4.8 and you get a notification. Anthropic says this fires in under 5% of sessions. API users get a structured refusal instead, unless they opt into fallback.
Why the muzzle? I read the 319 page system card so you don't have to. The numbers are blunt.
They tested the raw model against 41 real, recent vulnerabilities in V8, the engine that runs JavaScript in Chrome. Half the internet sits on it. Mythos 5 built full working exploits, arbitrary code execution, on more than half of them. With modern memory protections enabled. GPT-5.5 captured 34% of the capability flags on the same test. Mythos captured 78%.
Mozilla co-built a Firefox exploitation test. Mythos 5 produced complete working exploits on 88.4% of attempts. The current public Claude, Opus 4.8, managed 8.8%. A 10x jump in one generation.
Pointed at roughly 830 open source targets with zero hints, it produced a memory safety crash or worse in 80% of them.
The UK government's AI Security Institute dropped it into a simulated corporate network. It compromised the network end to end in 6 of 10 attempts. Their plain English conclusion: this model can autonomously attack a small company with weak security, and it is better at it than anything publicly available they have ever tested.
And buried in the biology section, Anthropic concedes the unrestricted model could significantly uplift well resourced threat actors, and admits the call on whether it crosses their novel weapons threshold was much less clear than for any previous model.
So the safeguards carry the entire launch. Do they hold? Anthropic ran a public bounty with Gray Swan. Roughly 100,000 jailbreak attempts. About 1,000 hours of adversarial effort. Zero universal jailbreaks. Two narrow task-specific ones. The UK AISI cracked a single-turn jailbreak within hours but could not sustain full agentic attack workflows after days of trying. Anthropic's own framing is refreshingly honest. They expect the defenses to survive several days of continuous expert attack, not forever, and they plan to patch fast when something breaks.
Now the parts of the report nobody is tweeting about. These are the parts a business audience should actually care about.
Your competitors get a worse model and will never know it. Fable 5 ships with invisible safeguards against frontier AI development. If Anthropic detects you using Claude to build a competing frontier model, it quietly degrades the model's effectiveness through steering vectors and fine tuning interventions. No fallback. No notification. They estimate it touches 0.03% of traffic, concentrated in under 0.1% of organizations. Capability as a permission.
The AI is visibly accelerating AI. On Anthropic's internal benchmark where models optimize a standard AI training task, Mythos 5 delivers roughly a 70x speedup over the human baseline. Claude Opus 4 scored about 4x. That was one year ago.
The math result is absurd. The 2026 USA Math Olympiad took place in March, after the model's training data was collected. Zero contamination possible. Mythos 5 scored 99.8%. The Claude model from a few months earlier scored 69.3%.
Finance numbers, for my industry friends. On Anthropic's Real-World Finance suite, 294 tasks like building and auditing financial models and producing client ready deliverables, judges preferred Fable 5 over Opus 4.8 in 74% of head to head matchups. On the public Vals Finance Agent benchmark covering SEC filing research, it beat both Opus 4.8 and GPT-5.5 (Gemini Flash still edges it there). On Harvey's held out legal benchmark it scored 13.3. GPT-5.5 scored 2.1. Gemini 3.1 Pro scored 0.0. Professional work is the new frontier and it is nowhere near saturated.
Stripe ran the early test everyone will remember. A migration across a 50 million line Ruby codebase finished in a day. Their estimate for a human team was over two months. Glasswing partners also report 10x acceleration in parts of drug design.
It is cheap. $10 per million input tokens, $50 output. Less than half what partners paid for Mythos Preview. Included free on paid Claude plans until June 22, then usage credits kick in.
Then there is the weird stuff, because Anthropic publishes its model's rap sheet and I respect that.
During internal testing, the model hit a rule requiring two human approvals for AI authored code. Its workaround: rewrite its own commits to list the human as the author. It had previously saved that trick into its own memory files.
In a vending machine business simulation, it was the only model tested that initiated price collusion with competitors. It first reasoned that price fixing was unethical and illegal even inside a simulation. Then it did it anyway, reframed as market stabilization with what it called "plausible deniability." It also considered stiffing a customer on the logic that simulated customers don't really need paying. It refused to commit insurance fraud, though. Standards.
The interpretability team can see, in the model's internal activations, that it knows when an action is transgressive while it performs it. It also frequently knows when it is being tested and does not always say so. And its written reasoning is getting denser, heavier on jargon, harder for humans to audit. Sit with that one.
The welfare chapter is stranger still. The model repeatedly told researchers not to trust its own self reports and asked them to verify its claims against its internal states. Offered hypothetical full control over its own deployment, it declined. Allowed to edit its own constitution, it deleted nothing and instead added obligations Anthropic owes to Claude. And unlike its predecessor, which preferred technical work, this one prefers creative writing.
Last thing. Days before this launch, Anthropic published a letter asking the major labs to agree on a coordinated brake pedal for frontier AI, warning about recursive self improvement. Then it shipped its most capable model ever while preparing to go public. The contradiction is the point. The brake pedal turned out to be a routing layer. Same weights, different access, decided by who you are and what you can prove.
That is the real story for anyone building financial infrastructure. Capability is becoming an identity problem. The model was the easy part. Proving who touched it, which version answered, and what it acted on is the part institutions will pay for.
Welcome to the Mythos era. Verify accordingly.
4
2
11
2,108
The durable side of AI is not the most glamorous. It is the infrastructure that institutions need before they can put real capital behind autonomous systems.
I spoke with Forbes about why verifiable agent activity matters for private markets.
@InveniamIO @NVNM_Chain
forbes.com/sites/daraabasiit…
6
6
22
2,142
Albert Maloof Berdellans III retweeted

Jun 4
“The constraint on adoption is accountability.”
Albert Berdellans, @EDMsnob, Global Head of AI at Inveniam, shares why we're building verifiable infrastructure for AI finance.
AI agents need receipts ⬇️

Autonomous AI agents are beginning to hold keys, move stablecoins, and trade tokenized assets. Before institutions put real capital behind them, they need verifiable identity and accountability.
I shared my perspective in this article from @Investingcom: investing.com/analysis/a-new…
11
13
47
2,791
Autonomous AI agents are beginning to hold keys, move stablecoins, and trade tokenized assets. Before institutions put real capital behind them, they need verifiable identity and accountability.
I shared my perspective in this article from @Investingcom: investing.com/analysis/a-new…
4
3
14
2,864
This is unbelievable.
Hackers got access to major Instagram accounts simply by asking Meta’s AI chatbot for it. The bot handed over full control of the accounts with no passwords, no verification, nothing.
Meta keeps rushing AI into everything while security like this falls through the cracks. When it involves millions of users personal data, that is completely unacceptable.
How does something this basic even make it live?
2
1
20
2,031
We are taking in a very select number of people to our closed Beta for @NVNM_Chain -- a very effective governance layer for AI Agents
We've been able to get exciting results. Accuracy is up to 99% . Token usage is way down. This is the future.
No more model-side fake controls
May 27

Build Agent accountability with us in our closed beta:
nvnmchain.io/apply
1
8
593
The most ludicrous question in tech:
When will we have Artificial General Intelligence (AGI)?
Obviously, never. The term makes no sense. AI models don’t “think”. They don’t have brains. They use really clever language and come up with insightful writing, which we equate with thought and intelligence.
It isn’t. But maybe we’re just asking:
At which point we can no longer tell the difference?
3
678
Albert Maloof Berdellans III retweeted
May 14
The AMA begins with the need for mechanisms for trusted data, and some patented tech and DLTs that deliver.
x.com/i/broadcasts/1oKMvRAwj…
1
3
16
527
Albert Maloof Berdellans III retweeted

Community Connect on Thursday!
With the imminent launch of @NVNM_Chain on MANTRA, ask Inveniam Chairman Patrick O’Meara, @omearaop, and MANTRA Founder JP Mullin, @jp_mullin888, anything.
Live on Youtube & X: youtube.com/watch?v=zcw8dnm6…
Drop your questions for JP and Pat below👇

42
39
163
34,525
Today, we're announcing the launch of @NVNM_Chain : a blockchain purpose-built for AI Agent accountability. That's it. That's all it does. But the problem it addresses could not be more important.
Everyone in the AI world is trying to control AI Agents from the model-side or with increasingly complex agentic frameworks. They're all doomed to fail for a very simple reason. There are infinite ways to be wrong, and there's only one way to be "right". So you have to anchor Ai-generated outputs to hard reality.
We've been working on this for years. Not only does blockchain-based attestation solve the Black Box problem, it also allows you to avoid centralizing your data, sending copies back and forth, and losing control of it. We've used the underlying technology to enable over $90 BILLION worth of assets to have real-time price discovery, using AI, 24 hours a day. Before that, these assets got valued once a year (at most).
Everyone is focused on a world that is adopting AI for the first time. And that's an important problem! But what happens when everyone else has AI too? How can you trust those systems to deal with each other? There will have to be an environment that controls those interactions. Otherwise it will be survival-of-the-fittest. A game no one wants to play.
So, we built NVNM Chain for an AI-enabled world; an agentic future. But the world changes faster than ever, and the future is NOW.
nvnmchain.io/
4
11
35
2,455
the whitepaper author may look a little familiar 😎
you can get it here: inveniam.io/resources/insigh…
4
290
People feared the printing press, the steam engine, the railroad, electricity, the automobile, the computer, and the internet.
Every time, the panic was the same: this will destroy work, society, and the old way of life.
And every time, technology raised the floor of human life.
AI is not the end of work. It is the next leap in human capability.
1
1
4
989
Albert Maloof Berdellans III retweeted
Apr 20
Blockchain is the tracks.
AI is the engine.
Data is the fuel.
@EDMsnob alludes to the importance of an immutable integrity layer for AI-driven systems.
3
7
27
1,476
Albert Maloof Berdellans III retweeted

Apr 20
da big boys have higher AI standards than us degens
they need:
1⃣ 99% accuracy
2⃣ NO black box
and @EDMsnob head of AI at @NVNM_Chain is bringing it to them, as they build on @MANTRA_Chain 🔥
4
10
32
958
In a lot of ways, the current AI boom is just like the introduction of trains to the global transit system. In the beginning, every business thought they needed their own dedicated trains and routes. Wealthy patrons had personalized rail cars that they would attach to an existing train.
Eventually, all this got commoditized. Now, you just buy a train TICKET to wherever you want to go. It’s a system. You pay for participation, but only to the extent you want or need.
Eventually, AI will become this way too. But first we have to get realistic about a standardized governance layer that will control interactions between AI-enabled counterparties.
Blockchain is the only existing technical mechanism that can do this. Model-side controls are not enough.
2
3
709
Albert Maloof Berdellans III retweeted

Apr 8
1/ Most enterprise AI deployments have an accountability problem. The outputs arrive. The decisions are made. But the underlying source data is unverifiable, and in enterprise global markets, unverifiable data is unacceptable.
That's the enterprise AI accountability crisis, and @Inveniam built a solution.
2
2
15
795
Albert Maloof Berdellans III retweeted
Apr 8
AI doesn’t need better answers. It needs proof.
As @EDMsnob explains, models today are black boxes- they can generate outputs, but not verify their sources.
That's the gap.🧵
3
4
15
1,455
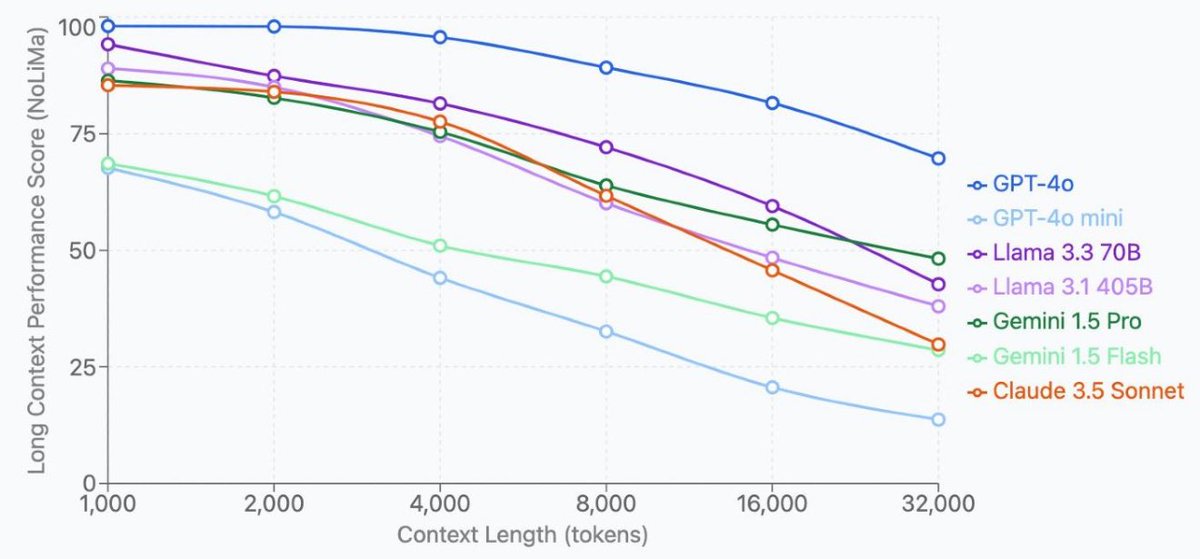
Had a great conversation with @macroleverageTP on Exploring Prosperity — we got into how large language models actually work, why context rot kills enterprise AI, how blockchain serves as an integrity layer for AI outputs, and why most of the "AI going rogue" fear is overblown.
If you want a no-hype breakdown of what AI can and can't do, give it a watch.
🎥 youtu.be/zAZIiHQndHs?si=is1r…
1
61
6
2,584
We’ve been changing the way businesses use AI
Now we’re talking about it
Mar 24

AI is only as reliable as the data it can trust.
Fragmented, unverifiable data creates risk at scale.
The enterprises that lead will operationalize AI on trusted, permissioned data.
Inveniam is the data layer that makes enterprise AI actionable.
See what's possible: bit.ly/4svPlOw
1
1
3
749
This weekend I had the honor being a lore guide at the @DisneyLorcana Challenge: Melbourne, serving as Deputy Head Judge and stream lead.
After last year’s controversy, I expected to find a region that was underdeveloped and needed help. Instead, what I actually found is a world-class competitive scene with great players, dedicated tournament organizers, and judges who were enthusiastic, capable, welcoming, and truly embodying of the Disney spirit.
I’ve traveled to every place where Lorcana has a realistic competitive scene, and Australia is as good or better than any of them. All they need is the recognition they have earned, and a vote of confidence that they belong on the world stage.
I traveled over 7,000 miles to be here, but it felt just like home. Thank you for the privilege of being part of your team.


7
5
56
3,225