Software Engineer
Joined December 2008
- Tweets 7,331
- Following 262
- Followers 273
- Likes 17,602
346 Photos and videos









Muon(Clip) used by GLM & Kimi has a RMS matching factor of 0.2 in order to reuse AdamW's optimal LR. My theory is that it actually makes Muon's momentum-dependent effective LR roughly match AdamW's (momentum-independent) LR: (1.95/0.05) ** .5 * 0.2 = 1.25
1/3
ALT Muon's effective LR

ALT MuonClip
1
1
4
353
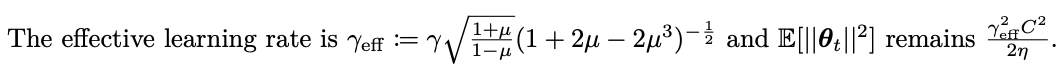

So their eff. LR matching is in fact more accurate. I don't know if they got it thru trial & error or they had their own theory internally.
DS V4 tech report: huggingface.co/deepseek-ai/D…
My preprint (that started about WD): arxiv.org/abs/2512.08217
3/3
2
4
285
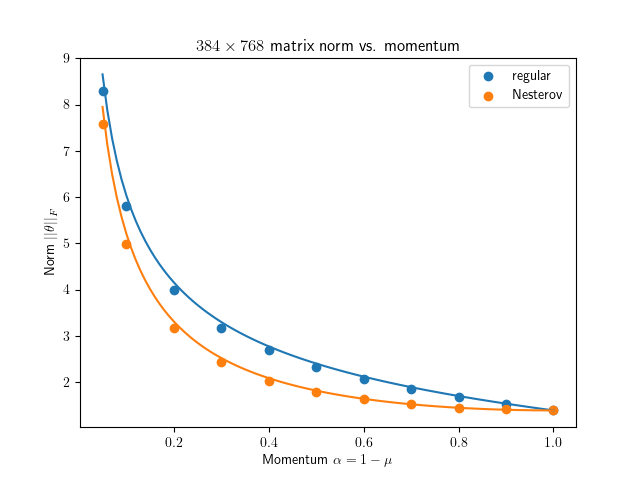
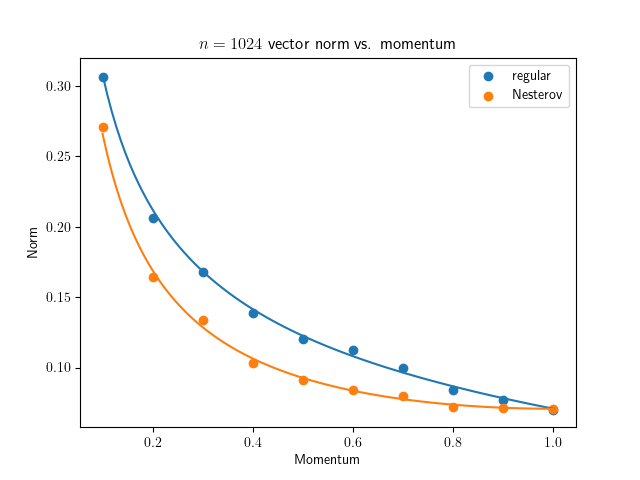
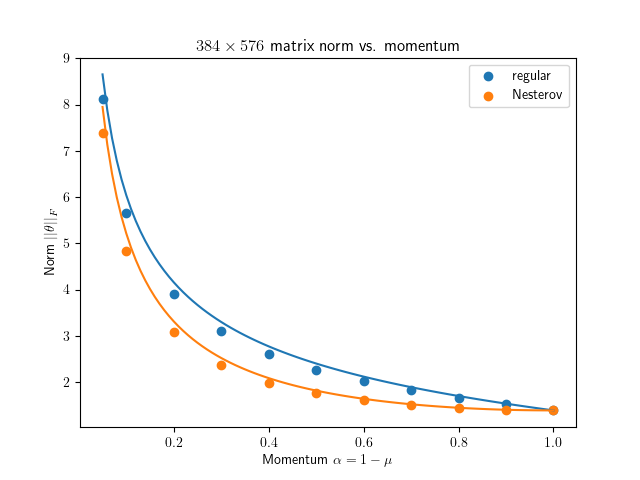
So I finally get around to test this thoroughly with Gaussian random vector / matrix: github.com/EIFY/normalized_u…
The prediction works great for normalized vector update and Muon / Scion spectral ortho. update with n=4m matrix, but not so much for steady-state norm when n=m. Why? 🤔
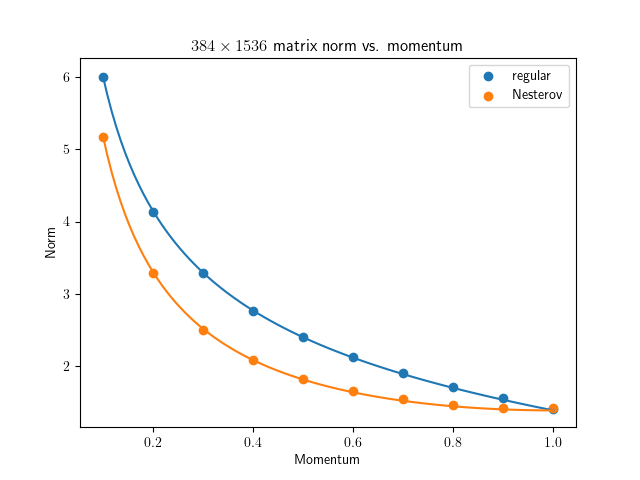
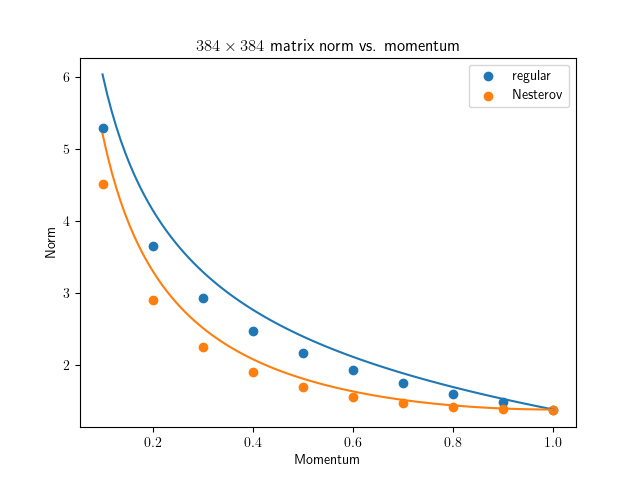
2
2
331
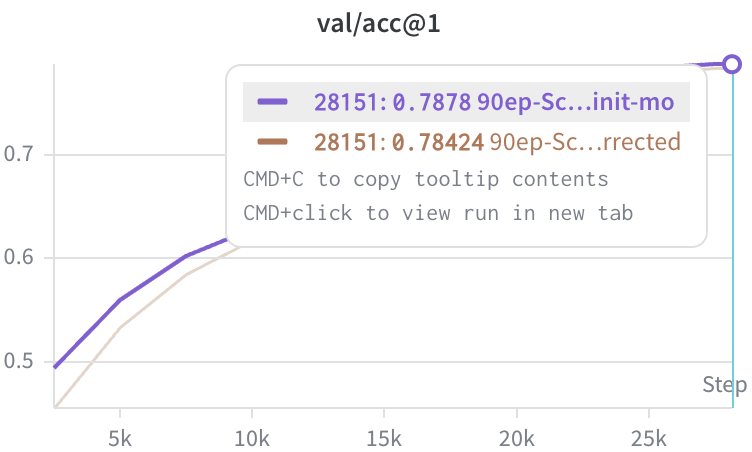
I happened to be running this ablation. Preliminary result based on training a ViT-S on ImageNet-1k for 90 epochs says it's better to leave the biases out 🤔
Background: A modified DeiT base has been the CV workhorse for Scion papers... 1/5
x.com/Ji_Ha_Kim/status/20372…
Mar 26

Nowadays biases are omitted in transformers for simplicity/same quality but it might matter more to keep affine layers for more expressivity, since bias doesn't affect Lipschitz
2
3
15
2,623
2. For my ViT-S I made sure that QKV grad. are separately orthogonalized and the input dim. of patchifier are flattened. In the process I already left out the bias of QKV.
3. I incorporated @tmpethick's 1.0 init. mo for the unbiased exp.
4/5
1
1
1
173
4. These are ScionC experiments, designed to keep the weight norm stable.
(I don't expect 2-4 to change the direction of the result)
5. Without biases somehow the avg. spectral norm is smaller and the L2 grad norm is higher. It's possible that the optimal WD may change...
5/5
1
3
163
If the hidden dimension D is a major bottleneck then we can expand it cheaply & exponentially in the last few layers by replacing residual connections with concatenation, tweaking the MLP shape, or activating more experts. Has anyone tried that?
x.com/nthngdy/status/2032172…
Mar 12

🧵New paper: "Lost in Backpropagation: The LM Head is a Gradient Bottleneck"
The output layer of LLMs destroys 95-99% of your training signal during backpropagation, and this significantly slows down pretraining 👇
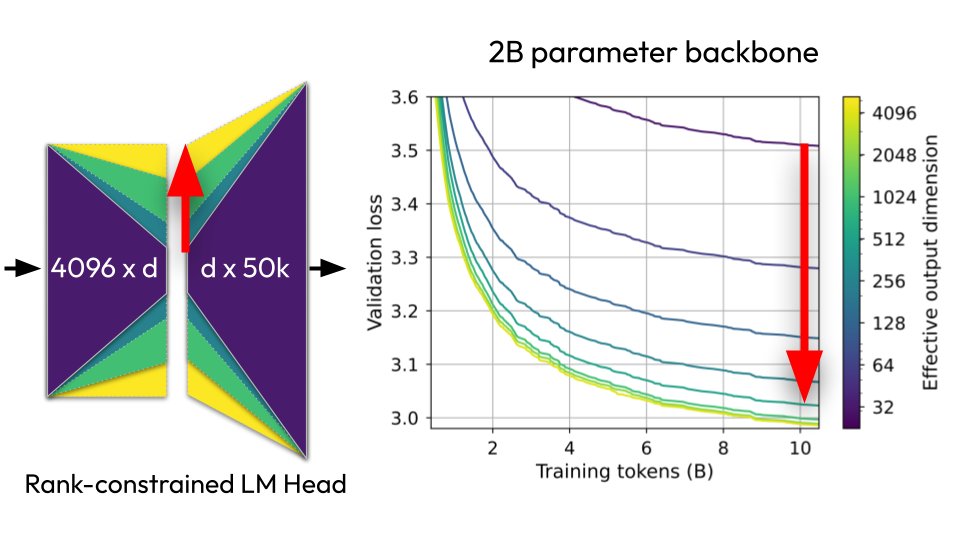
2
251
Quite a late bloomer, (constrained) Scion.
Diff. from the DeiT exp. in the paper: It's based on "better baseline" ViT-S/16 (global avg. pooling, sincos2d etc.) and trained for 90 ep. Parameters are all reinitialized and it uses Polar Express for msign.
github.com/EIFY/mup-vit/tree…

ALT ImageNet-1k Top-1 val. accuracy after 90 epochs: Scion 78.47, AdamW 77.45, unScion 73.61
1
1
612
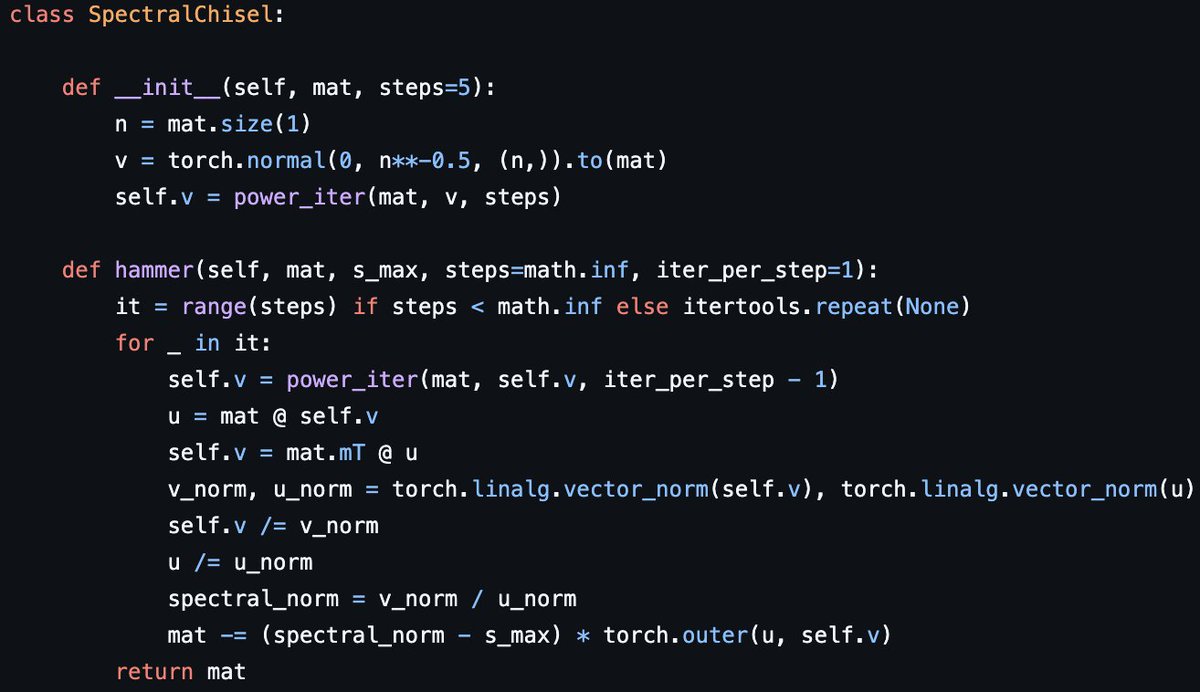
(4/4) So, spectral chisel can be as accurate as other methods except msign-based hardcapping. It may depend on how many singular values we need to cap but # of steps needed should be ~O(n), so the total cost is at most about that of a few matmuls. Repo: github.com/EIFY/spectral-chi…
1
1
306
P.S. I submitted a PR to fix that author name typo, lol
github.com/Arongil/lipschitz…
2
255
(1/4) Comparing such "spectral chisel" (1 iter/step) against the ground truth, direct hardcap (from @LakerNewhouse's repo), and msign-based hardcap (Newhouse et al., 2025) for capping n=4096 square unit gaussian random matrix at svdval <= 120:
x.com/EIFY/status/1947062171…
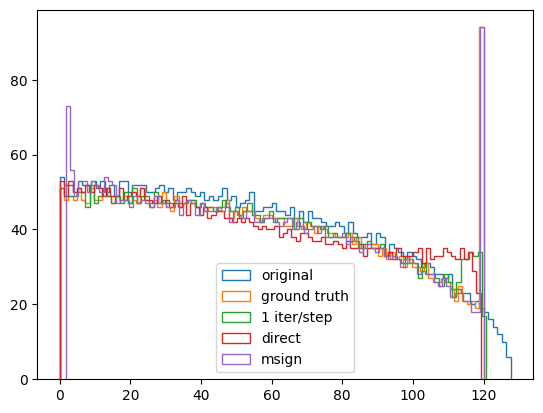
ALT Hardcapping method comparison

Approximating σ1, u1, and v1 with power iteration is O(n^2) per iter. while matmul alone is O(n^3). How about just repeating power iteration spectral weight decay / hammer a fixed number of times or till σ1 < σ_{max}?
1
1
247
(3/4) 🤨 Strangely the lipschitz-transformers repo doesn't implement the msign-based spectral hardcapping described in Appendix B. Instead it does this "direct hardcapping" attributed to @leloykun, presumably optimized with procedures similar to x.com/YouJiacheng/status/189…

ALT Direct hardcapping
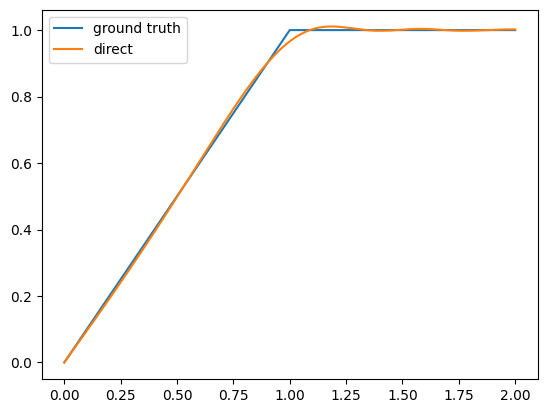
ALT Direct hardcapping vs. the ground truth, visualized
23 Feb 2025

Improved stability against noise, idea of the noise-stability loss is borrowed from @leloykun 's code.

1
1
170