
large language models @kyutai_labs
Joined October 2012
- Tweets 128
- Following 166
- Followers 2,897
- Likes 238
8 Photos and videos

Edouard Grave retweeted

Apr 2
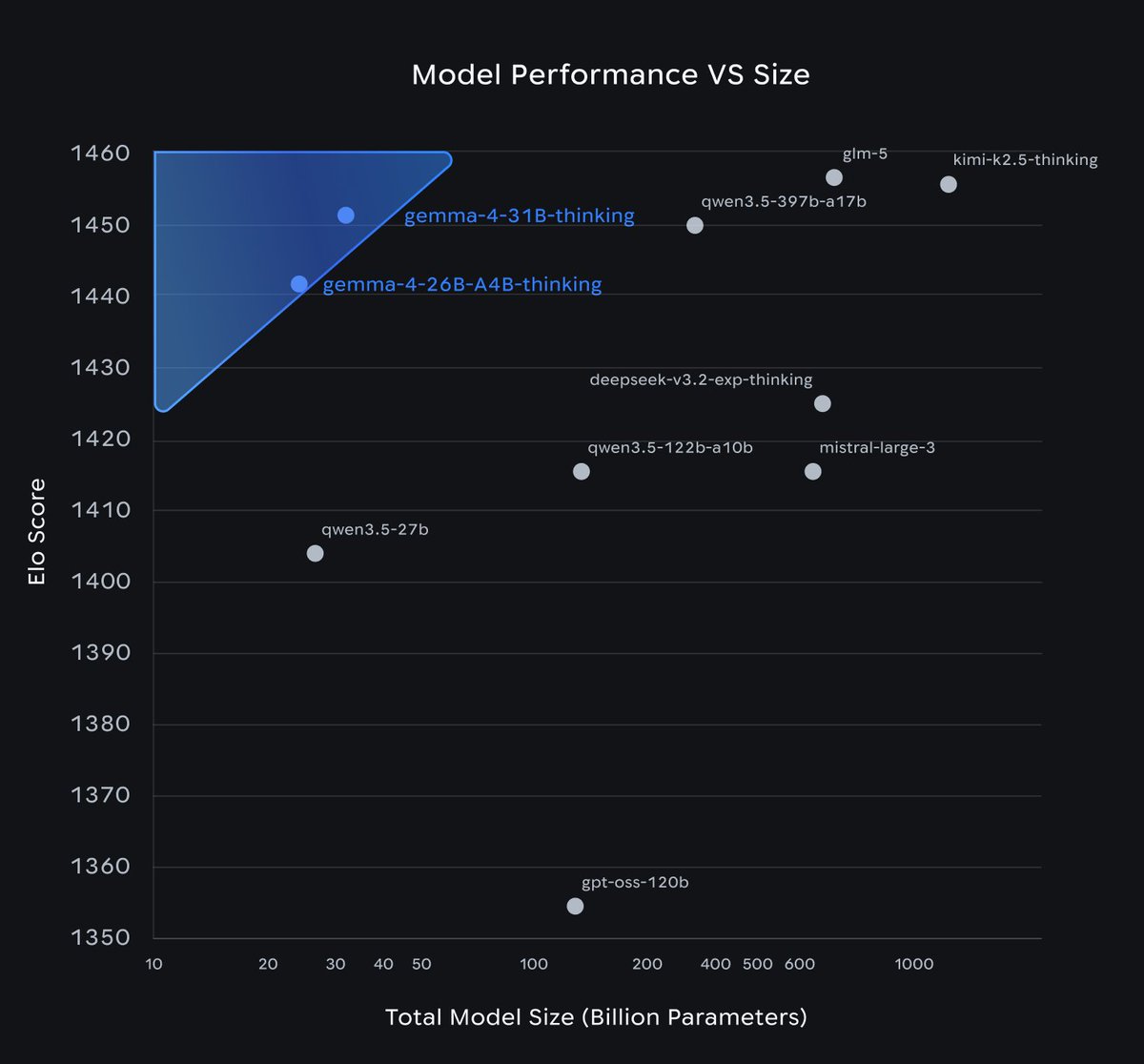
Gemma 4 is here!
🧠 31B and 26B A4B for models with impressive intelligence per parameter
🤏E2B and E4B for mobile and IoT
🤗Apache 2.0
🤖Base and IT checkpoints available
Available in AI Studio, Hugging Face, Ollama, Android, and your favorite OS tools 🚀Download it today!
53
112
899
123,029

6 Feb 2025
Today, we release our 🇫🇷 to 🇬🇧 simultaneous speech-to-speech translation system, called Hibiki. It runs on-device & the model, inference code and tech report are available. This is built using the same audio LLM as Moshi, showing its versatility. 🟢
6 Feb 2025

Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧.
Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the source speech.
Based on objective and human evaluations, Hibiki outperforms previous systems for quality, naturalness and speaker similarity and approaches human interpreters. 🧵
1
20
1,699
13 Jan 2025
Excited to release a preview of Helium-1, our 2B LLM targeting edge and mobile devices. 🚀
More to come in the future: training code, support for more languages, data pipeline, tech report & more… 🟢
13 Jan 2025
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/helium…
4
44
6,352
Edouard Grave retweeted

13 Jan 2025
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/helium…
10
89
375
58,316
18 Sep 2024
Local voice models FTW 🚀
18 Sep 2024
Talking to Moshi locally on a Macbook M series (python 3.12) in 2 lines:
pip install moshi_mlx
python -m moshi_mlx.local_web -q 4
3
17
1,991
23 Jul 2024
I am at ICML in Vienna! Let me know if you want to chat about (or to) Moshi, multimodal LLMs, Kyutai & more.
2
5
31
11,255
Edouard Grave retweeted

13 Dec 2023
Looking forward to discuss open research at @kyutai_labs. If you want to work on large scale multimodal LLMs, come and talk to us, this is what we look like 👇☕️

13 Dec 2023

Look for my @kyutai_labs colleagues at #NeurIPS2023 if you want to learn more about our mission. We are recruiting permanent staff, post-docs and interns!
4
9
101
29,545
8 Dec 2023
✈️ I will be attending #NeurIPS2023: let me know if you want to chat about the future of LLMs, and how to democratize them.
🌐 We are also hiring members of technical staff and interns @kyutai_labs. Happy to talk about the lab and our mission.
1
6
57
13,401
17 Nov 2023
/kyutai has landed! Super excited to build this new research lab. Pure focus on research. As open as it gets.
17 Nov 2023
Announcing Kyutai: a non-profit AI lab dedicated to open science. Thanks to Xavier Niel (@GroupeIliad), Rodolphe Saadé (@cmacgm) and Eric Schmidt (@SchmidtFutures ), we are starting with almost 300M€ of philanthropic support. Meet the team ⬇️

13
6
152
12,536
24 Feb 2023
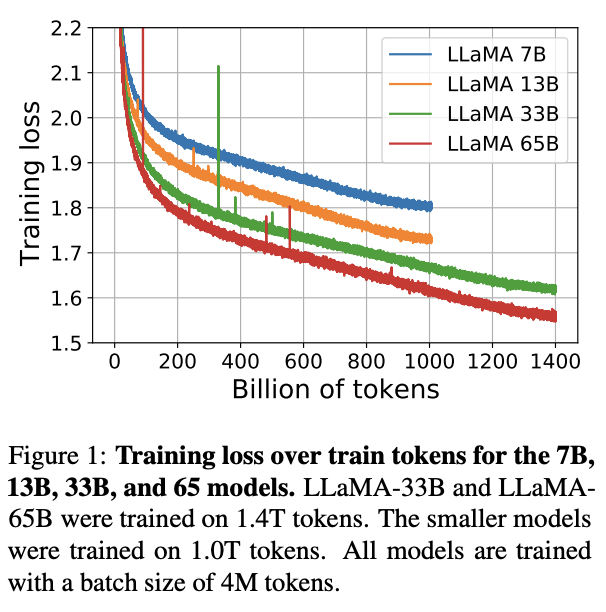
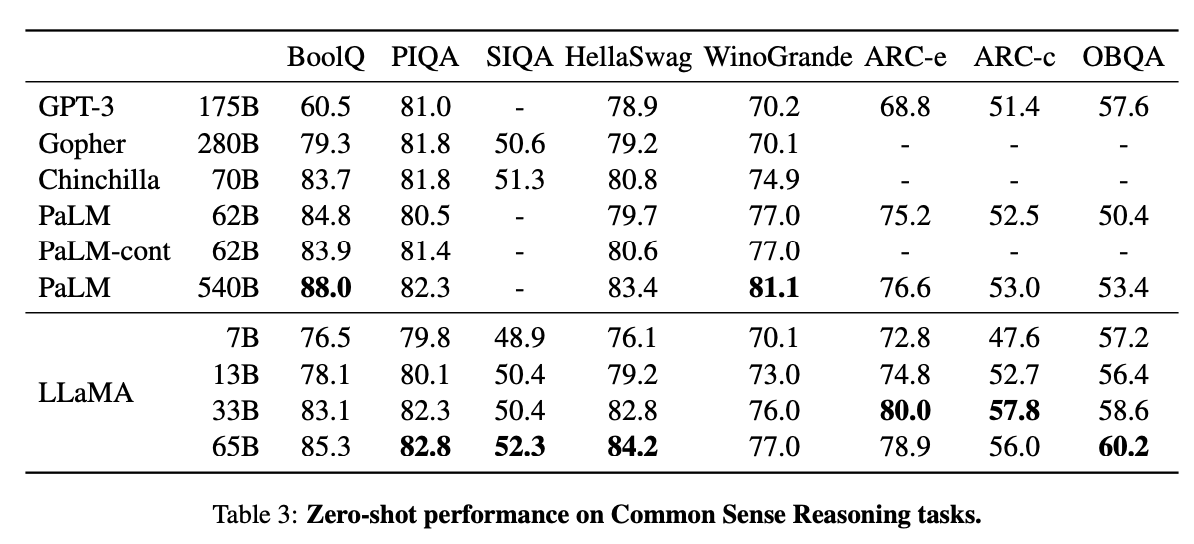
Super excited by the release of LLaMA, a serie of large language models, from 7B to 65B parameters. 🎉
By training longer, LLaMA obtains GPT3 level performance with a 13B model, which can run on a single GPU. Excited to see what the research community will do with these models.
24 Feb 2023

Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters.
LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B.
The weights for all models are open and available at research.facebook.com/public…
1/n

7
51
36,755

25 Aug 2022
Introducing PEER, a new language model which makes text generation and editing more collaborative and controllable. It adds human in the loop, by following instructions and providing explanations.
Work lead @timo_schick.
Paper: arxiv.org/abs/2208.11663
25 Aug 2022

🎉 New paper 🎉 We introduce PEER, a language model trained to incrementally write texts & collaborate w/ humans in a more natural way. It can write drafts, add suggestions, follow instructions, perform edits, correct itself & provide explanations.
Link: arxiv.org/abs/2208.11663
1
1
11
8 Aug 2022
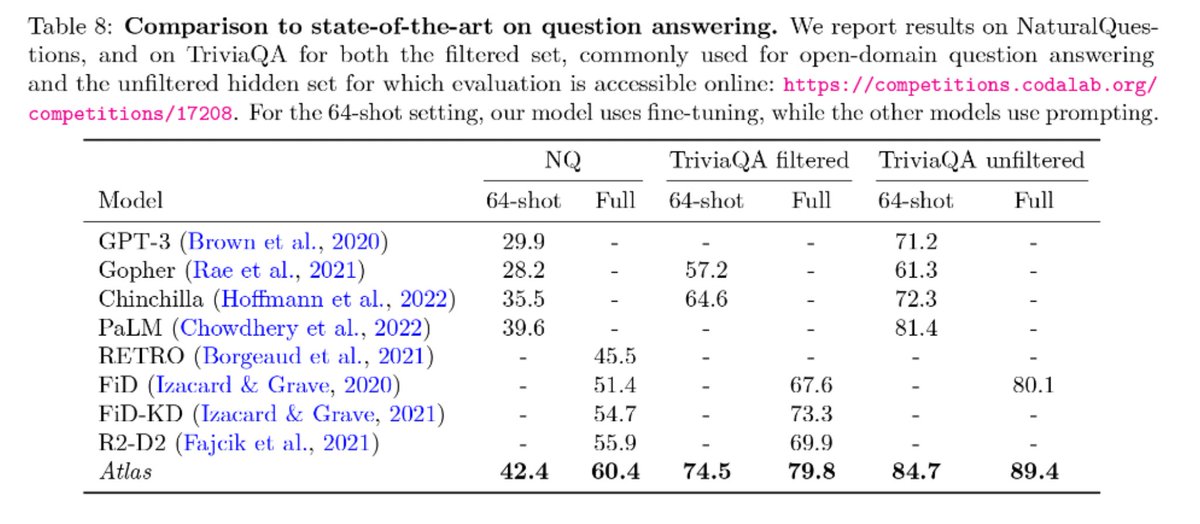
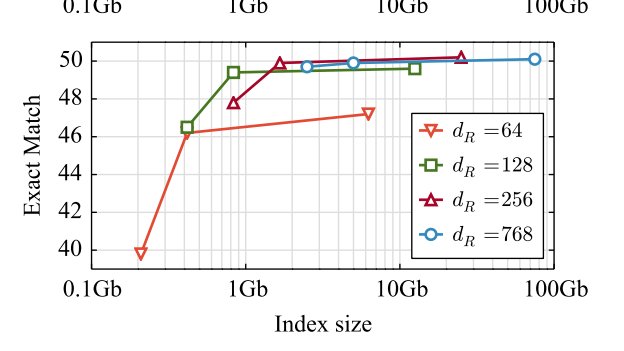
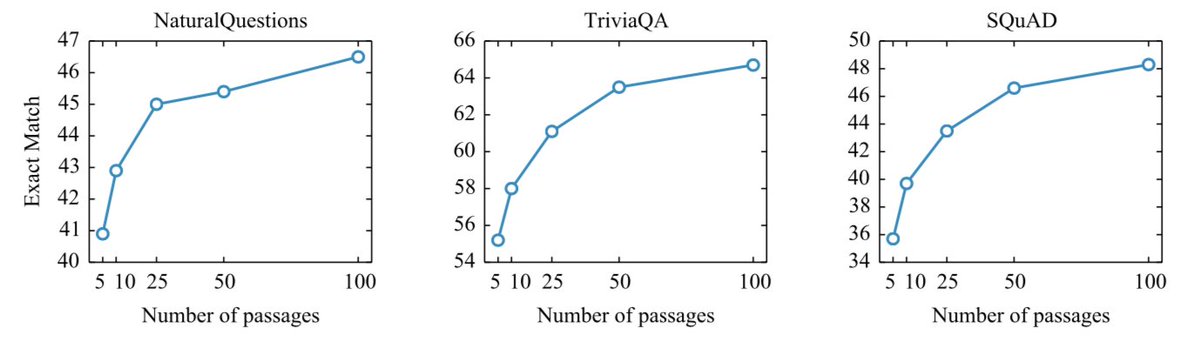
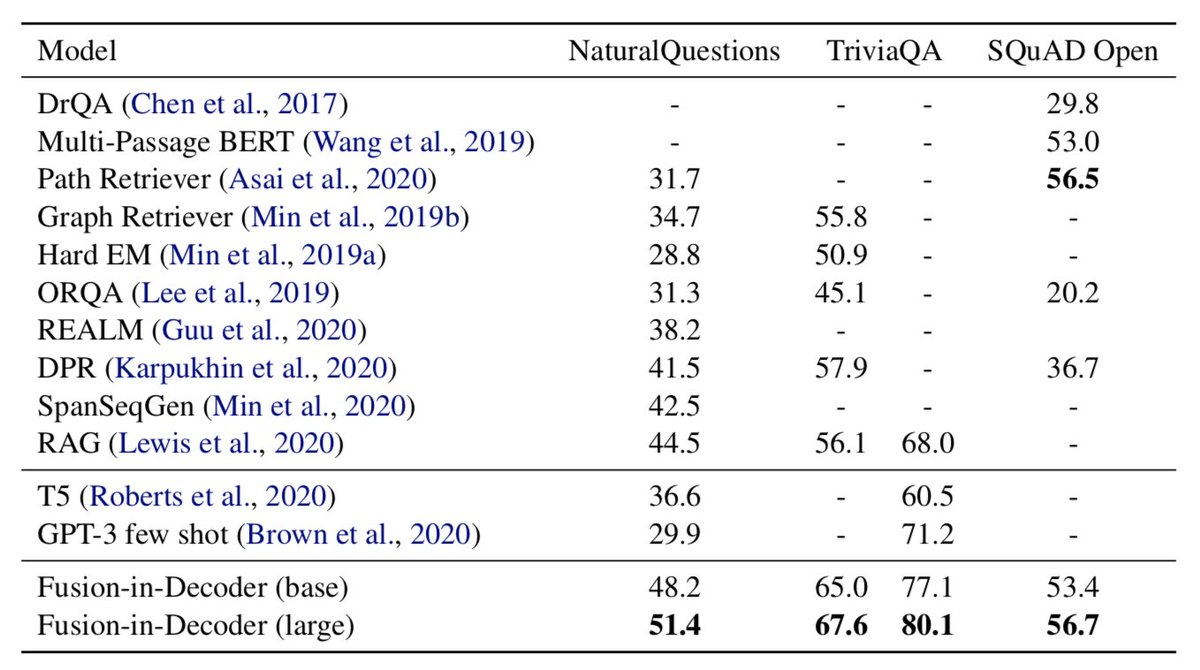
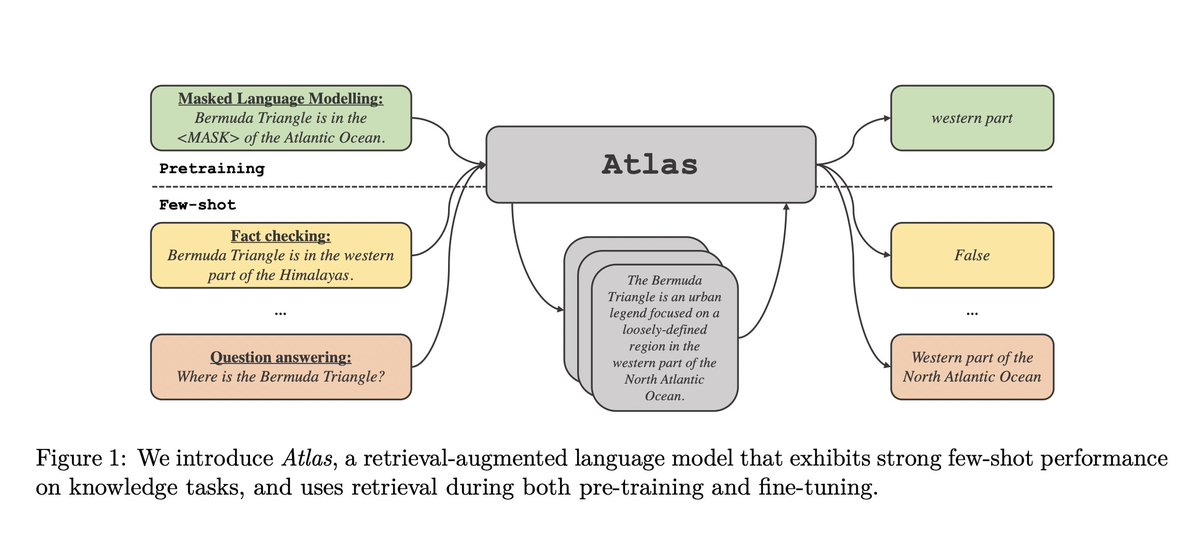
Very excited to introduce Atlas, a new retrieval augmented language model which is competitive with larger models on few-shot tasks such as question answering or fact checking.
Work lead by @gizacard and @PSH_Lewis.
Paper: arxiv.org/abs/2208.03299
8 Aug 2022

🚨We’ve been working on better retrieval-augmented models & thrilled to present Atlas, led by @gizacard @EXGRV & myself🚨
Atlas is a end2end pretrained "RAG"-like model, beats models 50x its size on fewshot QA, sets numerous SotA on knowledge-intensive NLP arxiv.org/abs/2208.03299
2
11
73
8 Aug 2022
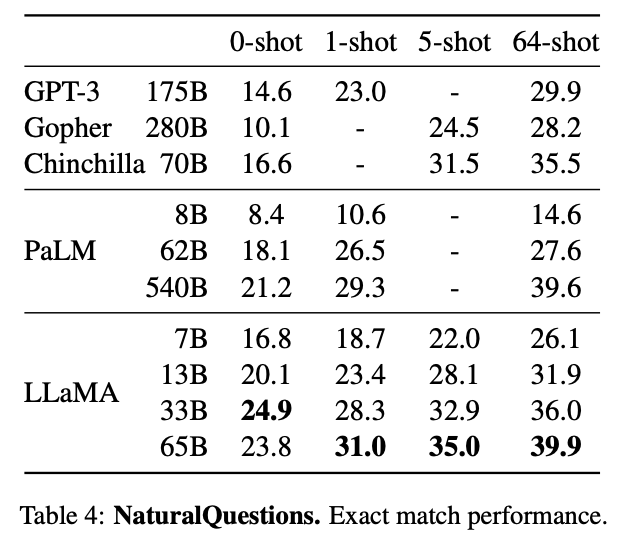
Our model, at 11B parameters, and significantly less training compute, outperforms LLMs on 64-shot question answering ( 3 pts wrt SOTA) or 15-shot fact checking ( 5 pts wrt SOTA).
1
5
8 Aug 2022
Joint work with the great following team:
@gizacard @PSH_Lewis @MariaLomeli_ @lucas_hosseini @Fabio_Petroni @timo_schick Jane Dwivedi-Yu @armandjoulin @riedelcastro
7
Edouard Grave retweeted

21 Jul 2022
Excited to present our work on single-sequence protein folding from a language model! By stacking a simple folding trunk and Alphafold2's structure module on top of the language model, we get accurate structure prediction in a fraction of the runtime.
21 Jul 2022

We have trained ESMFold to predict full atomic protein structure directly from language model representations of a single sequence. Accuracy is competitive with AlphaFold on most proteins with order of magnitude faster inference. By @MetaAI Protein Team.
biorxiv.org/content/10.1101/…
4
12
80
1 Jun 2022
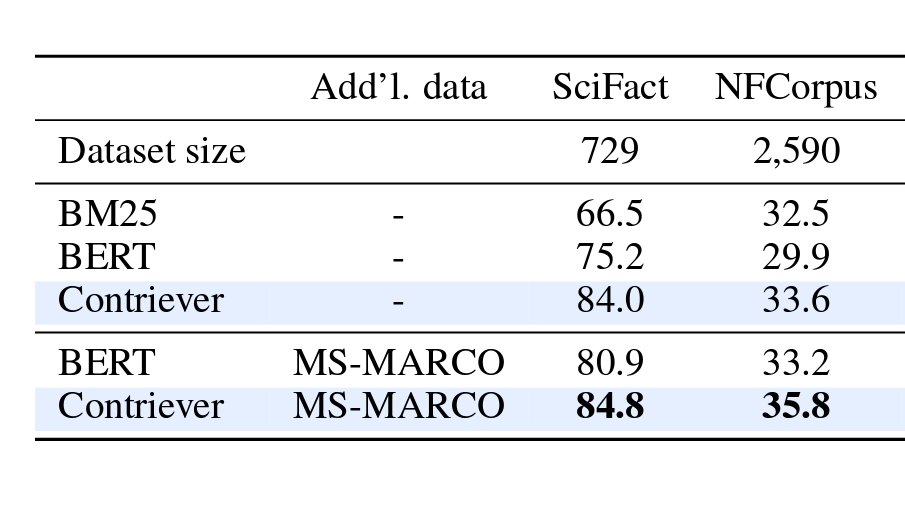
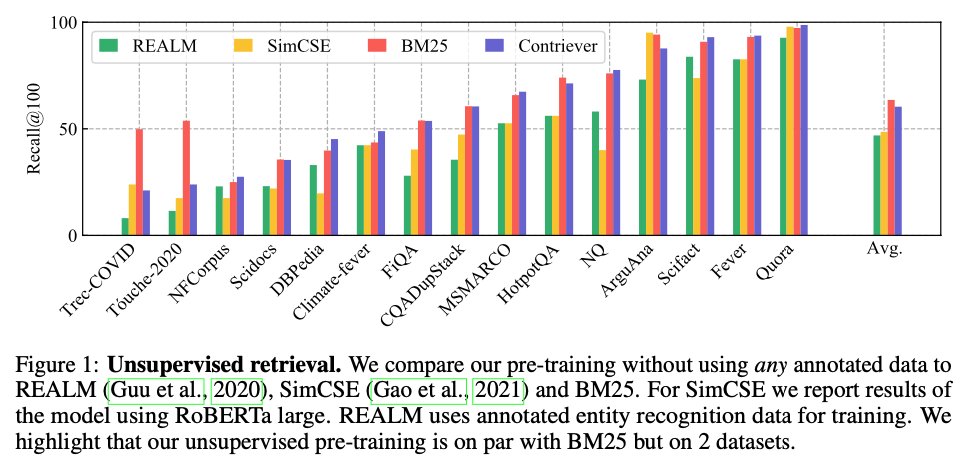
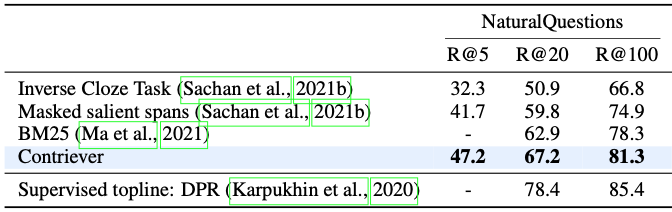
New release of our Contriever project! It includes multi-lingual models which can perform cross-lingual retrieval (eg, retrieve English documents to answer a question in Swahili), the code to (pre-)train your own retrievers, and an updated version of the paper with new results.
31 May 2022

Code for Contriever is now available!
Code: github.com/facebookresearch/…
Paper: arxiv.org/pdf/2112.09118.pdf
Additionally we trained mContriever, a state-of-the-art multilingual neural retriever, by applying a similar contrastive learning method.
2
12