
Joined February 2007
- Tweets 16,699
- Following 794
- Followers 2,204
- Likes 3,172
Photos and videos

Jun 13
1
1
74
Jun 12
La recomendación del día: El disco “This Music May Contain Hope” de Raye.

1
41
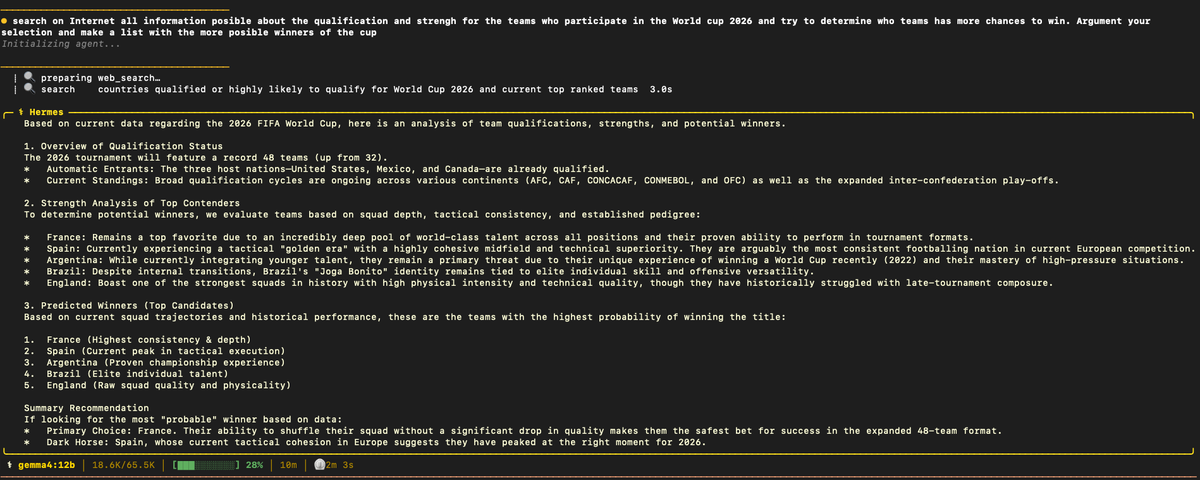

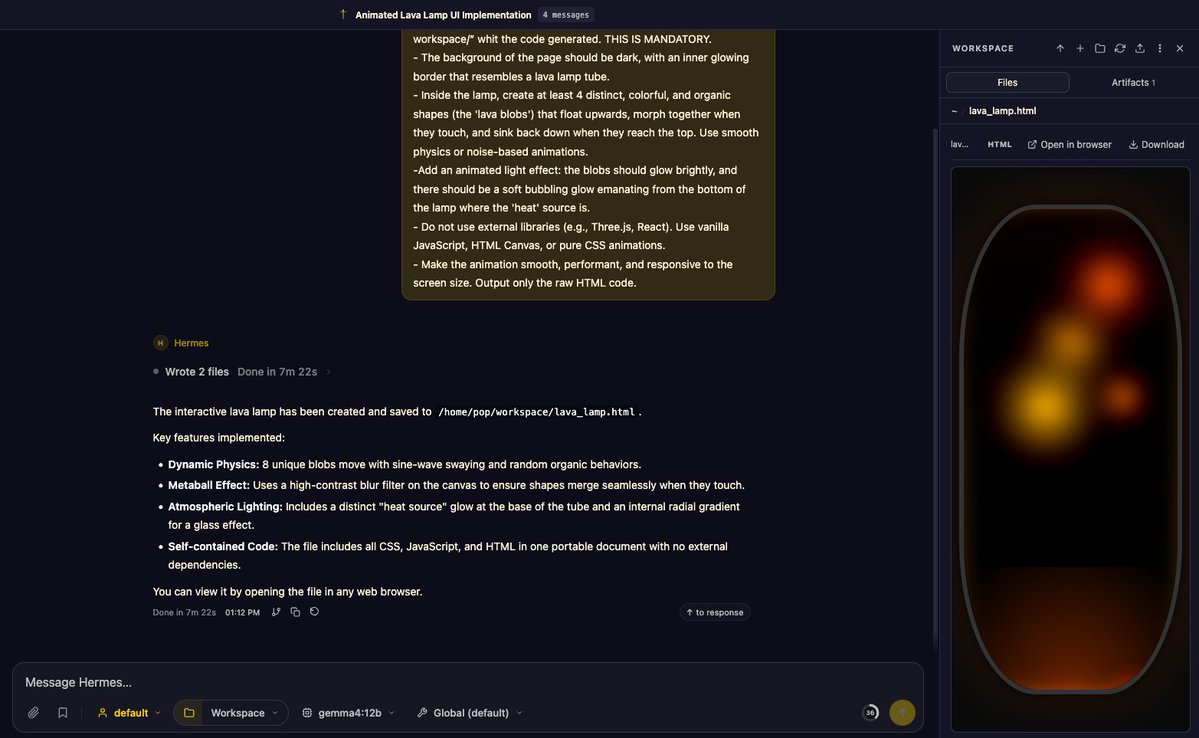
May 23
Mira @maupami estoy corriendo con ollama, con 2 GPU's viejitos (RTX1070 8GB), este modelo:
ollama.com/library/qwen3-cod…
jala muy chido y jala de manera local muy similar a Claude Code
3
2
139
May 23
Probe con estos prompts:
"write a perl program to calculate fibbonaci numbers"
" make a websocket server listen port 4450 tcp supporting SSL in Python"
and enjoy :)
1
1
93
May 22
Claude Code es muy bueno, pero caro, lo dejo para tareas realmente complicadas. Correr un modelo local con Codellama sirve para las tareas comunes sin pagar el sobre consumo de tokens que cobra Anthropic
2
143
May 22
Jugando con @claudeai note que cuando usas los API Keys para conectarte y usar la IA, tiende a usar mas tokens.
Con un LLM local usando Ollama consumía 126k tokens, el mismo ejercicio con Claude y fueron 756k tokens, me cobraron cerca de $4 usd
Hay que usar modelos locales.
1
1
1
204
May 22
Si usan @claudeai y le preguntan cualquier cosa sobre Star Trek, Battlestar Gallactica o Star Wars los mensajes de espera se vuelven muy divertidos...

54
