
Building the future of decentralized AI video at Livepeer 🏞️🚀
Joined May 2022
- Tweets 851
- Following 223
- Followers 77
- Likes 1,418
14 Photos and videos



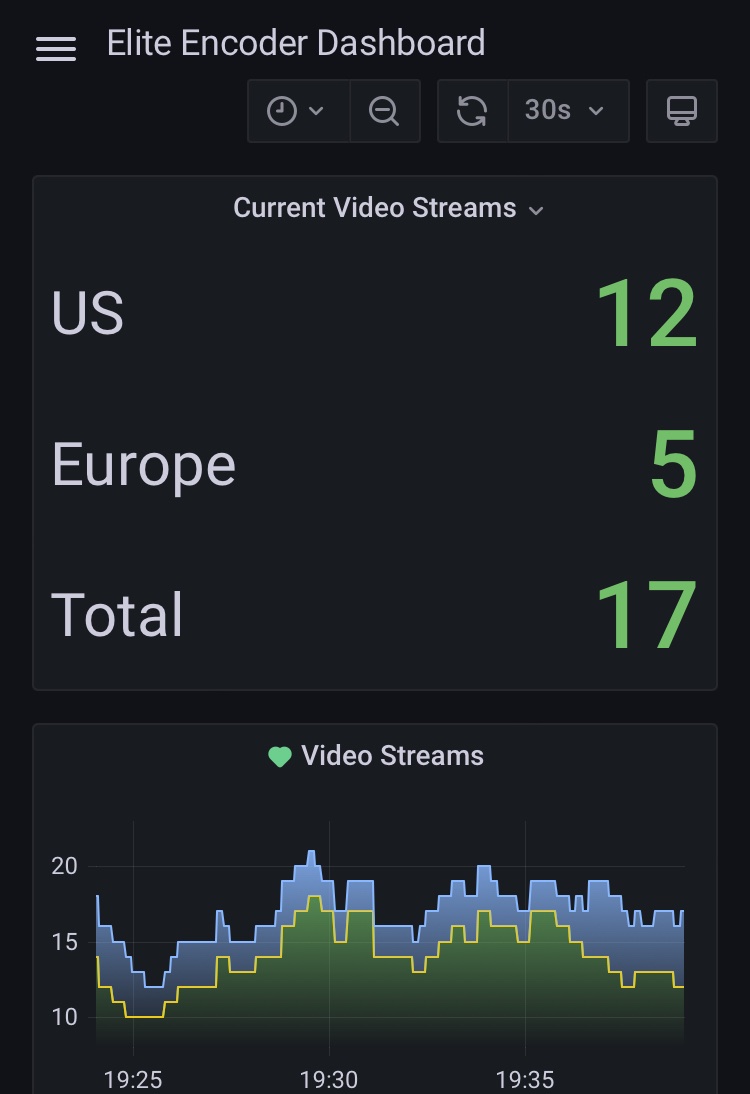


John | Elite Encoder retweeted

23h
This is the most hilarious thing I saw and did today
Ran gemma-4-12B-coder-fable5-composer2.5-v1-GGUF locally with 8 GB VRAM at 20 tok/sec
Anthropic's Claude Fable 5 launched June 9.
By June 12 it was banned. I can't access it. You can't either.
But here's the twist: I'm running a model trained on its chain of thought at 20 tok/s on my RTX 4060 8GB.
Locally. Offline. No cloud. No export control.
Enter: Gemma4-12B-Coder GGUF (Q4_K_M)
Base: Google's gemma-4-12B-it
Fine-tuned on verifiable Python CoT data:
- Primary: Composer 2.5 real reasoning traces (only passing solutions kept)
- Auxiliary: Fable 5 used to redo the hard cases Composer missed.
Every training example's reasoning led to code that actually ran. No hallucinated logic.
Llama.cpp flags:
-m gemma4-coding-Q4_K_M.gguf -cnv -ngl 44 -c 64000 -v
(huggingface model link in comments)
Flag breakdown:
-ngl 44 → offload 44 layers to GPU (tune this for your VRAM)
-c 64000 → 64K context window
-cnv → conversation/chat mode
-v → verbose output
The irony writes itself.
Anthropic spent weeks telling the world Fable 5 (mythos) is too powerful to release. Then released it. Then got banned from serving it, including their own researchers.
Meanwhile: a Gemma 4 12B fine tune, trained on Fable 5's reasoning, runs fully offline on my mid range consumer GPU
No API. No cloud. Just me and llama.cpp.
This is why local AI matters.
Check out the model's link in the comments. How's your experience been with this model?
Jun 14

Gemma 4 12B Coder is here and it's a game changer for local code generation. This GGUF model packs Google's latest gemma-4 architecture into a compact 12B size, perfect for running on consumer hardware. It's optimized for reasoning and thinking, making it ideal for developers who want fast, private coding assistance without the cloud.
63
146
1,612
212,604

Epic! I want to see this new “media protocol” on Livepeer gateways!
Jun 12

SOMEONE VIBE CODED A VIDEO STREAM THAT IS SECRETLY 100% TEXT SO IT CANT BE BLOCKED
it plays 360p video at 30fps, but theres no actual video on the page. every frame is just colored text characters being repainted on a canvas
to the browser its not media at all, its javascript updating some text
its called asciline, and here's the trick:
> the server decodes the real video and streams it as binary packed text over websockets
> the browser paints thousands of colored block characters fast enough to look like 360p
> ad blockers and autoplay blockers cant catch it because theres no video element to catch
> it streams in kilobytes since its just strings, so it runs on trash internet
since the video is literally text, you can apply css glows to it, let people copy paste a moving frame, or feed it straight to a local llm
however, an unblockable stream is also an unblockable ad as well
36

Marco’s half decade in the Livepeer ecosystem shows what durable open infrastructure makes possible.
A builder can contribute to the core stack, operate the network, learn its constraints, and then ship the next platform on top of it.
Read the Builder Spotlight: Marco & FrameWorks.
livepeer.org/blog/builder-sp…
1
9
34
804


Turn a simple idea into a storyboard, then generate the video with Seedance 2.0.
This ComfyUI workflow uses LLMs to structure prompts into storyboard-ready scenes that define how the video should play out. The storyboard can be paired with reference images and sent directly into Seedance for video generation.
To try this workflow, link below 👇
13
64
528
32,486
John | Elite Encoder retweeted

Jun 10
We have a chill one today - using Daydream Music to create a cool funk remix with LoRA, prompting and changing the seed value.
1
1
5
183
John | Elite Encoder retweeted

Jun 10
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.

1,138
6,388
17,720
2,230,716
This is something we should start working on. It means devs building backlogs and reviewing AI written PRs built using top of the line models. Less token waste as an org.
Jun 10

My take 24 hours after Fable 5:
Your organization will likely not scale with the exponential curve of AI.
I'l just come out to say: This should be a wakeup call for engineering teams.
Set up your cloud software factories. Now.
Models can now fix impossible bugs, UI-test the hardest flows, writing extremely good code, etc. I have't opened Datadog manually as far as I can remember.
AI should be the first-line defense for bugs and feedback. Humans should only look at PRs after an AI has already reviewed it. AI should generate screen recordings of any PR before a human eye even reaches it. The agent should just prompt itself most of the time.
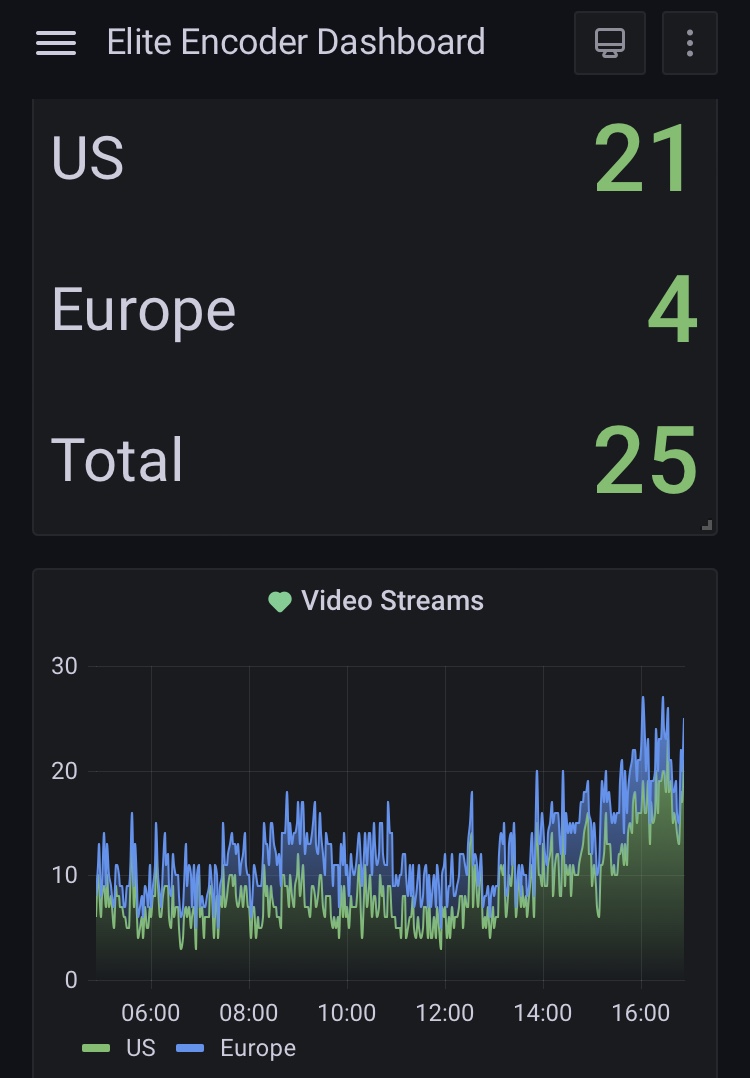
Ex. (pictured) our ui feedback channel manages itself, creates tickets, assigns itself automatically
You might also be worried about cost. Anthropic, OpenAI, and other labs will likely continue to put out bigger and more expensive models. But, we will also continue to get more capable small models. Not everything will need the smartest models. It's about having the organizational harness in place to continue taking advantage of this rising tide.
Moreover, if you use Devin, we've already optimized our harness a bit, and Fable is actually only ~40% more expensive in practice (vs the 2x people assume). I'm honestly pleasantly surprised - it might be higher ROI than you think.
Anyway, if you take anything away, engineers shouldn't be manually picking up tickets, humans shouldn't be digging into logs themselves, rethink what you do with your time that shouldn't just be an AI. We need to rethink what humans spend their time going.

25
John | Elite Encoder retweeted

Jun 10
My take 24 hours after Fable 5:
Your organization will likely not scale with the exponential curve of AI.
I'l just come out to say: This should be a wakeup call for engineering teams.
Set up your cloud software factories. Now.
Models can now fix impossible bugs, UI-test the hardest flows, writing extremely good code, etc. I have't opened Datadog manually as far as I can remember.
AI should be the first-line defense for bugs and feedback. Humans should only look at PRs after an AI has already reviewed it. AI should generate screen recordings of any PR before a human eye even reaches it. The agent should just prompt itself most of the time.
Ex. (pictured) our ui feedback channel manages itself, creates tickets, assigns itself automatically
You might also be worried about cost. Anthropic, OpenAI, and other labs will likely continue to put out bigger and more expensive models. But, we will also continue to get more capable small models. Not everything will need the smartest models. It's about having the organizational harness in place to continue taking advantage of this rising tide.
Moreover, if you use Devin, we've already optimized our harness a bit, and Fable is actually only ~40% more expensive in practice (vs the 2x people assume). I'm honestly pleasantly surprised - it might be higher ROI than you think.
Anyway, if you take anything away, engineers shouldn't be manually picking up tickets, humans shouldn't be digging into logs themselves, rethink what you do with your time that shouldn't just be an AI. We need to rethink what humans spend their time going.
Jun 9

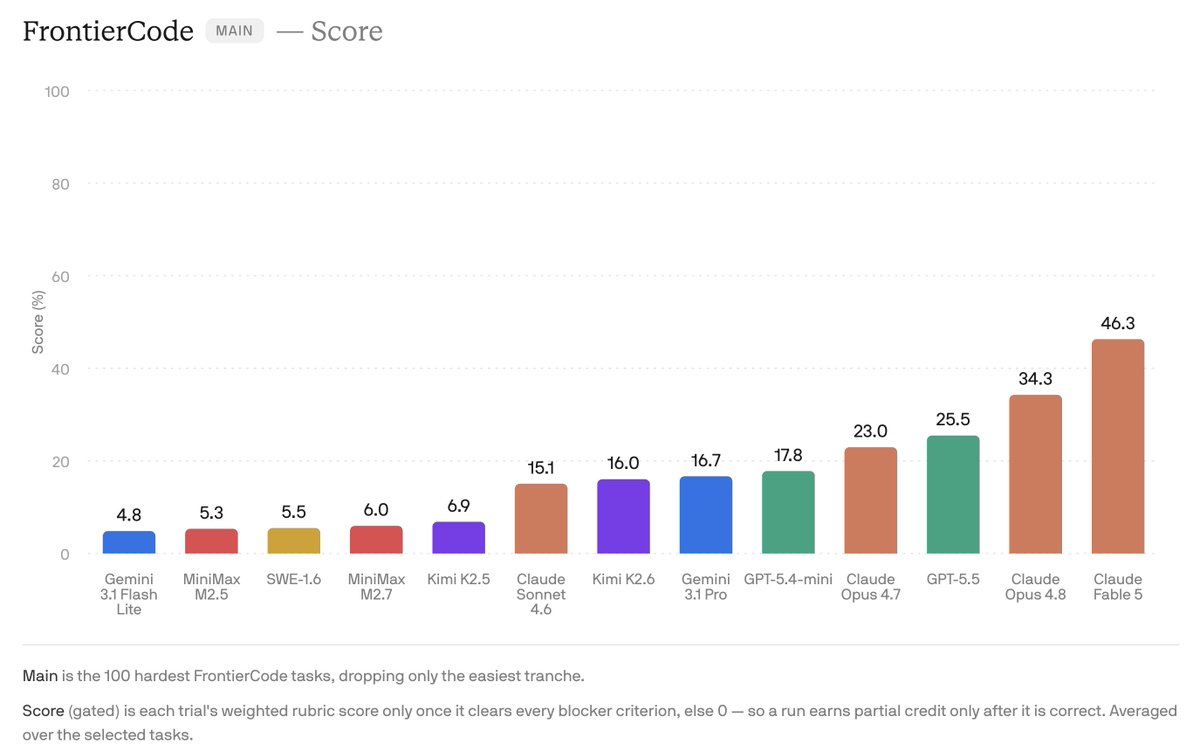
Claude Fable 5 is now available in Devin.
Fable 5 earns the #1 spot on FrontierCode, our benchmark for real-world engineering tasks that grades mergeability and quality:
42
56
917
211,230

有个女孩,一个人就把Figma和Photoshop的股价给整跌了。
她搞了个新技术,叫"touchdesign",靠这个赚了42万美元。
这套技术已经被诺兰的新片《奥德赛》用上了。
想法是她自己的,Claude帮她从零搭了起来。
我把这套东西逆向工程拆了一遍,结果发现简单得离谱。
整套系统只需要一台笔记本、一个摄像头,外加两个免费软件就能跑起来。
MediaPipe负责读取摄像头画面,追踪你每只手上的21个关键点。
TouchDesigner再把这些点转成3D物体,你手怎么动,它就怎么跟。
具体怎么搞,步骤也很少:
第一步,去 derivative.ca 下载TouchDesigner,用免费的非商业版就行。
第二步,从 github.com/torinmb/mediapipe… 把MediaPipe插件下下来,直接把文件拖进TouchDesigner,不用安装。
第三步,点一下hand_tracking那个节点,把numHands设成2,这样两只手都能实时追踪。
第四步,在项目文件夹里打开Claude Code,把这段提示词粘进去:
帮我写一个TouchDesigner的Python脚本,用MediaPipe插件做一个双手控制的3D故障风格立方体。控制方式是这样:双手的中间位置控制立方体在屏幕上的移动;双手之间的角度控制立方体在X轴和Y轴上的旋转;双手距离远近控制立方体缩放;左手捏合加大噪点失真;右手捏合循环切换颜色;快速移动手的时候触发故障闪烁效果;双手同时握拳就冻结画面,方便截图。输出一个带注释的Python DAT脚本,里面的参数让我能自己调。
第五步,把生成的脚本粘到一个Python DAT节点里,再把MediaPipe的输出连过去。
第六步,点播放,一个立方体就浮在你面前了,跟着你的手实时动。
之后你想把立方体换成别的模型也行,手的控制逻辑不用改,直接套上去就能用。
这个女孩现在专门在时装秀和发布会现场做这种实时表演,一场活动收费五千到一万五美金。
她还在Gumroad上卖预设包,99美金一套。
她的摄像头80块钱买的,软件一分没花。
整套东西,就靠Claude在一个周末搭完了。

16岁小孩做了个"星链原型",赚了30万美元
他能接收卫星信号,而且这玩意儿在哪儿都能用。
SpaceX想关掉他?人家早有准备。
实现方法说穿了其实不复杂,他全靠Claude就搞定了:
先说明一下,他不是在偷星链的网。
他用的,是SpaceX卫星往外发的无线电"信标",相当于拿这个信号当免费定位系统,在GPS失灵的地方照样能定位置。
每颗星链卫星都在不停往外发信标信号。
你只需要一个小天线锅,再加一个35美元的无线电接收设备,就能接收这些信号。然后通过三颗卫星的三角定位,算出你在地球上任意地方的坐标,就算GPS被干扰或者完全屏蔽了也不怕。
这个思路,美国陆军也在测试。
这小孩把它做成了便携版,卖给了徒步的、跑船的,还有应急队。
具体怎么搞?很简单,分六步走。
第一步:买硬件
RTL-SDR Blog v4 USB接收器,35美元
小号Ku波段抛物面天线,大概50美元
Ku波段LNB下变频器,20美元
树莓派5,8G内存版
偏置T适配器
5000毫安USB电池
全部加起来,大概180美元出头。
第二步:给树莓派装系统
把树莓派系统镜像烧录进SD卡,开机就行。
第三步:装SDR工具
打开终端,敲两行命令:
sudo apt update
sudo apt install rtl-sdr gnuradio python3-numpy
第四步:接线
LNB装在天线锅的焦点位置,LNB连偏置T,偏置T连SDR,SDR通过USB连树莓派。
第五步:让Claude写程序
打开Claude Code,把下面这段话扔进去:
"帮我写个Python程序,用RTL-SDR抓星链卫星的信标信号,用来定位。硬件是RTL-SDR Blog v4加Ku波段LNB加抛物面天线。
要求:扫描Ku波段下行频率抓星链信标,用celestrak网上公开的TLE轨道数据识别每颗卫星,靠至少三颗卫星的多普勒频移算位置,把经纬度和精度显示在小OLED屏上。用pyrtlsdr、skyfield、numpy这几个库,记得加注释方便我调参数。"
第六步:跑程序
树莓派会自动锁定头顶的卫星,然后显示你的坐标,精度大概10到30米。
不用GPS,不用手机信号,也不用联网。
最后,这小孩3D打印了个外壳,打了个牌子叫"徒步水手GPS备份",一台卖899美元,卖出去350台。
一台成本180,利润719。
客户里有野火应急队、丛林飞行员、深山滑雪的、开游艇的。
SpaceX会不会告他?不会。接收公开广播的信标信号是合法的,小孩的律师提前就确认过这一点。
82
308
2,710
1,100,764
John | Elite Encoder retweeted

Jun 9
A teenager in the United States started publishing software at 14 in 1998, built the entire online infrastructure for the Occupy Wall Street movement in 2011, joined Google as a software engineer, quit in 2018, and then spent five years writing a C library that does something the entire industry said was impossible.
Then she combined it with llama.cpp and shipped the easiest way on the planet to run a large language model on any computer.
Her name is Justine Tunney.
Here is the story, because almost nobody outside the low level systems world knows what one engineer has built.
Justine was born in 1984. She started writing and publishing software at 14, back when distribution meant uploading binaries to BBS systems and chat networks. She picked up the handle jart, which she still uses on GitHub today. She did the work most teenagers her age were not doing. She read the systems programming literature. She studied compilers. She fell in love with C.
In July 2011 she registered the @occupywallst Twitter handle and the occupywallst dot org domain. Within weeks the protest movement that began in Zuccotti Park in New York had become a global phenomenon, and her infrastructure was the digital backbone of the entire thing. She handled the social media, the website, the donations, the coordination. She built the platform that pushed the movement to reach millions.
After Occupy she joined Google as a software engineer. She worked on TensorBoard, the visualization tool for TensorFlow, and on site reliability for Google infrastructure. She stayed for years. Then in 2018 she left Google Brain to work on a personal project.
The project was called Cosmopolitan Libc.
Cosmopolitan does something most C programmers would tell you is mathematically impossible. It lets you compile a C program once and have the resulting binary run natively on Linux, Windows, macOS, FreeBSD, OpenBSD, and NetBSD with no modification. One file. Six operating systems. No virtual machines. No interpreters. No recompilation. The technique she invented is called Actually Portable Executable.
The implications are wild. Cosmopolitan binaries violate every assumption about how operating systems load programs. They are at once a Windows PE file, a Linux ELF binary, a macOS Mach-O binary, and a shell script. The same bytes run on every platform.
For five years she worked on it mostly alone. She funded the development partly through Mozilla's MIECO program, which sponsored her work on Cosmopolitan 3.0, released on October 31, 2023.
A month later she shipped llamafile.
llamafile is what happens when you combine Cosmopolitan with llama.cpp. You take any LLM weights file in the standard GGUF format, you wrap it in Justine's binary, and you get a single file that runs on six operating systems without installation. No Python. No CUDA setup. No dependency hell. Just one file that you double click and it works.
Mozilla launched it as an official project of their innovation group on November 29, 2023. It went viral immediately. The repository, hosted at github .com/mozilla-ai/llamafile, now has 24,600 stars. The license is Apache 2.0.
Justine kept shipping. She added GPU support to Cosmopolitan, a task systems engineers thought would require rewriting the whole thing. She added dlopen support, another thing nobody else had figured out. She wrote whisperfile, a single file version of OpenAI's Whisper speech-to-text model based on the same architecture.
Her GitHub profile lists projects most engineers would consider impossible. sectorlisp, a Lisp interpreter that fits in a boot sector. blink, the tiniest x86-64-linux emulator on Earth. bestline, a teletypewriter command session library. redbean, a complete web server inside a single zip file.
A teenager who shipped software in 1998 grew up to write the C library that the entire local AI movement now runs on top of.
She did most of it alone, and most people scrolling AI Twitter cannot name her.

128
842
5,804
366,148

Marco van Dijk didn’t just build on Livepeer.
🛠️ He worked inside the core stack
🎥 Powered Livepeer Studio’s transcoding media infra 🌐 Ran a top orchestrator node
💪 Founded FrameWorks: a developer-first live video platform built on Livepeer’s open GPU network.
5
6
25
1,073
GPU-backed securities
Jun 4

NVIDIA IS BUYING ITS OWN CHIPS AND CALLING IT REVENUE
And your retirement account is secretly holding the bag.
This scheme is literally straight out of the Enron playbook...
In January 2026, a special purpose vehicle called Valor Compute Infrastructure was created with one purpose:
Buy Nvidia's chips so Nvidia could book the sale as revenue.
Valor raised $5.4 billion and purchased over 100,000 of Nvidia's GB200 GPUs.
But $1.9 billion of that money came FROM Nvidia itself.
Nvidia invested $1.9 billion into the shell company, then sold that same shell company $5.4 billion worth of its own chips and booked every dollar as revenue.
It's the Girl Scout whose dad bought all the cookies and then she wins the sales contest because Dad was the customer. Except this Girl Scout is a trillion-dollar company and the cookie sale is $5.4 billion.
But it gets MUCH worse:
The remaining $3.5 billion in financing came from Apollo Global Management. Apollo structured the debt, packaged it into securities, and then sold those securities to Athene.
And guess who Athene is? Apollo's OWN insurance subsidiary. The one that sells fixed annuities to American retirees as safe, conservative retirement products.
Follow the chain:
Nvidia funds a shell company with $1.9 billion. The shell company buys $5.4 billion in Nvidia chips. Apollo finances the remaining $3.5 billion. Apollo sells the debt to its own insurance arm. That insurance arm packages it into annuity products and sells them to retirees who think they're buying something safe.
The retirees have no idea that their retirement savings are now backed by 100,000 computer chips sitting in some data center that will be worth pennies on the dollar in three years.
Now look at what's happening inside Athene:
$74.2 billion in US reserves but $217 billion in assets have been shifted to a Bermuda-based captive insurer, outside normal US regulatory oversight.
$103 billion of that portfolio (roughly 35%) is classified as Level 3 assets. That means there is no observable market price.
These assets are valued by internal models, not by actual markets.
And sitting on top of all those unpriced assets? 16.6x leverage.
If you're getting flashbacks to 2008, you should be.
Back then it was mortgages bundled into securities that nobody understood, sold to investors who had no idea what they were holding, rated as safe by agencies that never looked under the hood.
Today it's GPU-backed securities. Computer chips bundled into structured credit instruments, routed through an offshore insurance subsidiary, and sold to you as a retirement product.
The collateral is 100,000 GPUs leased to a single customer through an xAI subsidiary. If xAI stops making lease payments for any reason - financial distress, a pivot in strategy, anything - the entire structure unravels.
And Nvidia releases new architectures every year, so each generation delivers dramatically more compute per watt. A 5 year lease on technology that's obsolete in 2 years creates a mismatch that should terrify every annuity holder in America.
Every single step in this chain is technically legal. The SPV is legal, the lease is legal, Nvidia's equity stake is legal, the securitization is legal, and the Bermuda transfer is legal.
But legality and legitimacy are not the same thing.
I've seen every trick Wall Street has ever pulled in my 45 years of doing this.
And what I'm looking at right now is a pipeline that takes AI infrastructure risk, launders it through 8 layers of financial engineering, and deposits it in the retirement accounts of Americans who never agreed to fund Elon Musk's data centers.
In 2008 it was mortgage-backed securities.
In 2026 it's GPU-backed securities.
Different asset. Same greed. With the same ending.
7
John | Elite Encoder retweeted

Jun 4
AI should earn its keep. Introducing the AI Productivity Guarantee.
If Devin delivers less engineering value than you’re paying for, Cognition will fund your usage until it does, up to $10 million.
It’s time for the AI industry to stop maximizing tokens and start maximizing productive output.
72
100
1,087
426,784
John | Elite Encoder retweeted

Really proud to share something we’ve been working on for a while: Magenta RealTime 2 (MTR2), a live music model that is highly interactive (MIDI, audio, text, lots of parameters) and low-latency (~200ms end-to-end), and runs locally on a MacBook!

Introducing Magenta RealTime 2 (MRT2): the live music model you can play as an instrument.
MRT2 offers MIDI and prompt controls, and runs natively on a MacBook with <200ms latency.
Open weights. Open source inference engine. Suite of apps and plugins.
Hear what it can do and try it out for yourself below 🧵
14
29
274
43,933

From train driver to AI filmmaker: a $440 short film just got praised by a Hollywood director. 🎬
A 29‑year‑old in China made a Pixar‑level movie in 10 days using Seedance 2.0 and free tools. No studio. No crew.
Here's the warning:
If one person with $440 can do this, what happens when Anthropic and OpenAI go public? Wall Street will pour billions into the same AI tech that's about to upend Hollywood.
The IPOs aren't just tech events. They're the beginning of the end for traditional filmmaking.
Full story 👇
43
193
1,419
28,832
John | Elite Encoder retweeted

Jun 5
$SARAH just got a LLM upgrade and ultra low latency streaming upgrade
She’s now basically real time on Twitch and YouTube
1
4
111
John | Elite Encoder retweeted

Jun 4
Stronk Rocks! Marco's been one of the most dedicated independent builders in the Livepeer ecosystem for years...

Marco van Dijk has seen Livepeer from almost every angle.
✅ Core infrastructure contributor
✅ Independent GPU node orchestrator
✅ Founder of FrameWorks, sovereign video infra built on the open compute network
His story is a rare look at what happens when someone builds from inside the stack.

1
3
15
568
John | Elite Encoder retweeted

Jun 3
Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
559
722
9,800
5,034,972