
Building agentic AI systems | Tutorials & experiments on local LLMs and retrieval | Open-sourcing what I learn.
Joined February 2026
- Tweets 397
- Following 169
- Followers 9
- Likes 53
14 Photos and videos
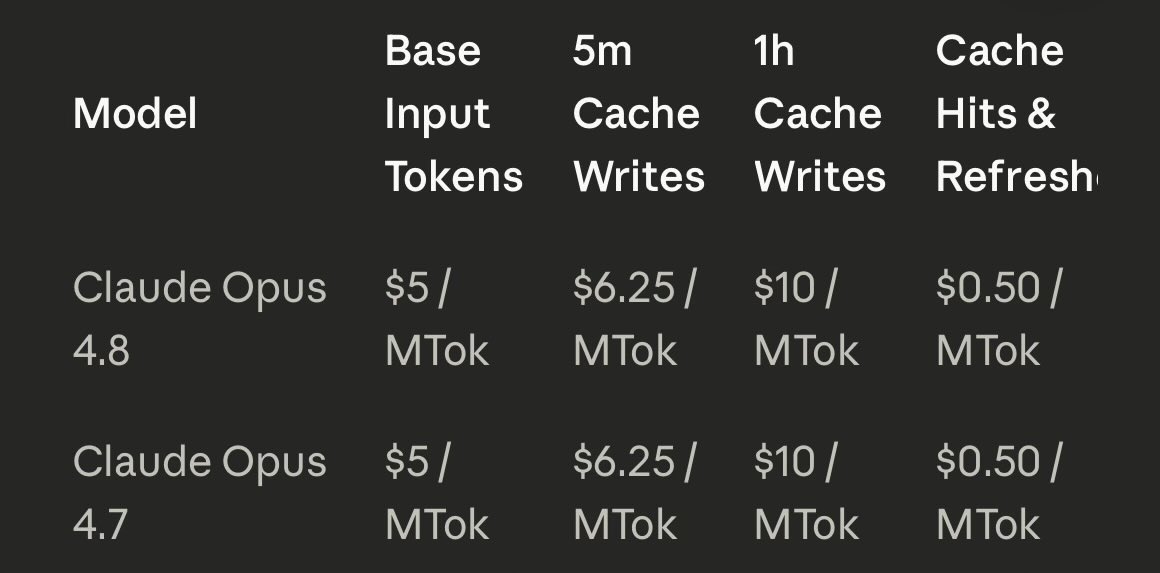












🚀 Claude Fable 5 is here — and it's the most capable model we've EVER made generally available. State-of-the-art on nearly every benchmark we tested: coding, knowledge work, vision, science, you name it. 🤯
The harder the task, the bigger its lead. A thread 🧵👇
1
27
🛡️ Releasing power this big means safety first. Sensitive queries (cyber, bio/chem) safely fall back to Opus 4.8 — but 95% of sessions never trigger a fallback at all. Survived 1,000 hrs of red-teaming with zero universal jailbreaks. 🔒
1
8
💰 And it's less than HALF the price of Mythos Preview: $10/M input, $50/M output.
Fable 5 is available everywhere today. ✨
Read the full announcement 👇
anthropic.com/news/claude-fa…
12
How do you evaluate an AI that can write essays, debug code, and roleplay characters?
Traditional benchmarks like MMLU can't cut it anymore. 🤔
A 2023 NeurIPS paper from UC Berkeley proposed a clever solution: use a strong LLM as the judge.
Let's break it down 🧵👇
1
36
LLM-as-a-Judge isn't just a research trick — it's now the backbone of how many AI labs run evaluations.
It's fast, cheap, explainable, and scalable.
The benchmarks (MT-Bench, Chatbot Arena) are publicly available and still widely used today. 🌍
Open science at its best. 🙌
1
26
TL;DR of "Judging LLM-as-a-Judge" (Zheng et al., NeurIPS 2023):
✅ GPT-4 judges match human agreement (~80%)
✅ MT-Bench & Chatbot Arena fill the benchmark gap
⚠️ Biases exist but can be mitigated
🔑 Hybrid evaluation (capability preference) is the future
Read the paper 👇
arxiv.org/pdf/2306.05685
37
The authors didn't just celebrate — they stress-tested the approach and found 3 key biases:
⚠️ Position bias — judges favor whichever answer appears first
📝 Verbosity bias — longer answers win, even if they're just padded
🪞 Self-enhancement bias — models may favor their own style
Knowing is half the battle.
1
1
50
They proposed practical mitigations too:
🔄 Swap answer positions and only declare a winner if results are consistent
🧠 Use chain-of-thought prompting for reasoning/math questions
📎 Provide reference answers to anchor the judge
Simple ideas, measurable improvements. 📈
14