
Building engineering intelligence @ Entelligence.AI
Joined January 2024
- Tweets 506
- Following 7
- Followers 2,182
- Likes 2,309
41 Photos and videos












Entelligence AI retweeted

Jun 12
Railing in and actually optimizing AI token spend for engineering teams is going to soon become a massive industry priority
If you want to understand context window burn, token waste due to compaction and more @EntelligenceAI has it covered
Jun 12

JUST IN: Meta is reportedly moving to curb employee AI token use as internal AI costs climb into the tens of billions.
2
5
17
3,960

Entelligence AI retweeted

Jun 12
we're hiring a marketing manager in SF and the job is basically: run weird experiments, break some, double down on the ones that work. not a content-calendar role.
$120–150k Esops. in-person. Apply through the link 👇

39
9
222
27,837

Been saying this since day 1. Check out research.entelligence.ai - for a very detailed analysis on the code <> debugging ratio token spend.
For every $1 spent on generating code, $2.4 is spent on fixes and debugging
Jun 9

More AI-generated code doesn't make your team faster. It might actually slow you down.
1
1
7
683
Entelligence AI retweeted

Jun 9
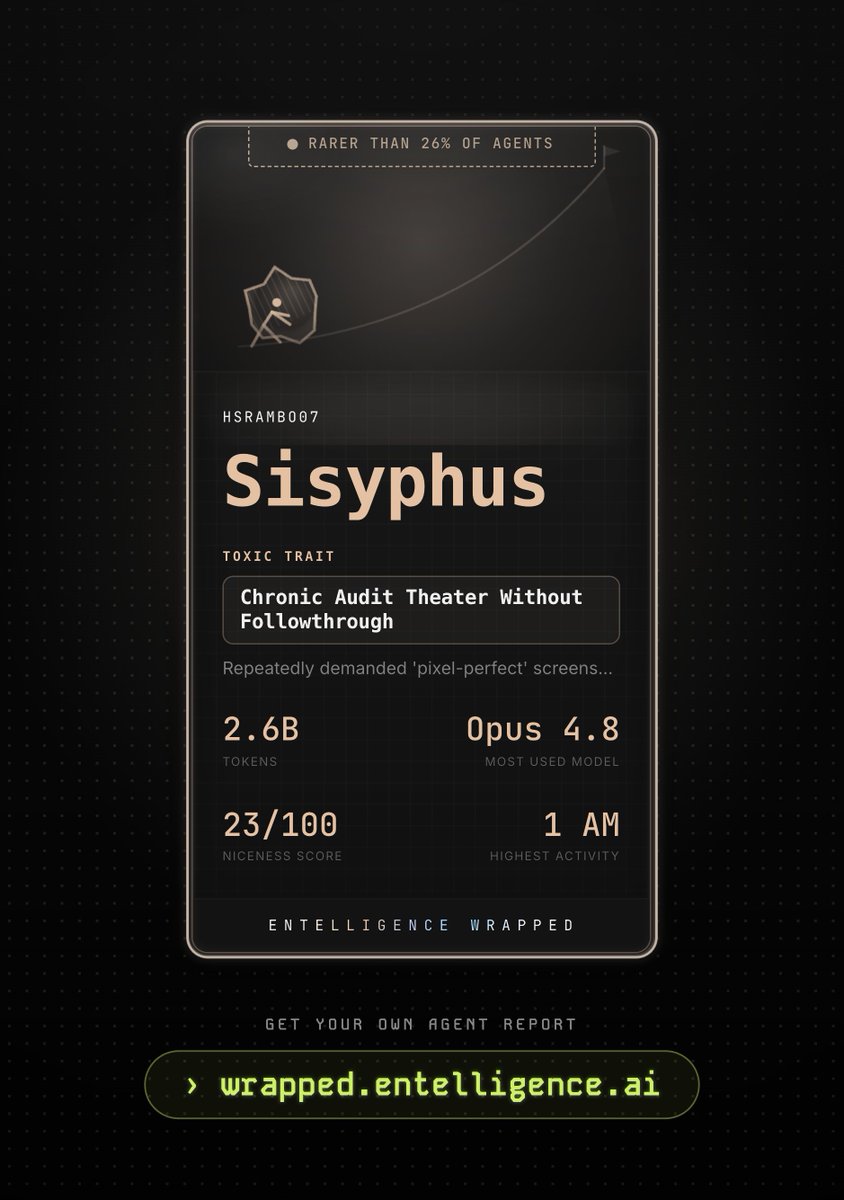
just got my AI wrapped today 🤩
1M tokens burned and my wrapped called me a Falcon 🦅
peak activity time 2 am 💤
niceness score that doesn't exist 👀
it knows me too well 💀
get yours wrapped.entelligence.ai 👈🏻

32
6
50
1,730
Entelligence AI retweeted

Jun 9
These really look cool! What do you guys think?

Everyone is tokenmaxxing but some people burn 20B tokens and produce OpenClaw while others produce massively disastrous slop 🫠
Which one are you?
Launching @EntelligenceAI Wrapped. Analyze your AI coding personality across every coding agent
-> wrapped.entelligence.ai
4
2
25
1,497
Entelligence AI retweeted

Jun 9
We have dashboards for everything now, yet most of us can’t answer basic questions about how we’re actually using AI.
Kinda strange when it’s becoming part of our workflow every single day.
Interesting idea from @EntelligenceAI
wrapped.entelligence.ai/
Everyone is tokenmaxxing but some people burn 20B tokens and produce OpenClaw while others produce massively disastrous slop 🫠
Which one are you?
Launching @EntelligenceAI Wrapped. Analyze your AI coding personality across every coding agent
-> wrapped.entelligence.ai
49
6
63
6,283
Entelligence AI retweeted

Jun 9
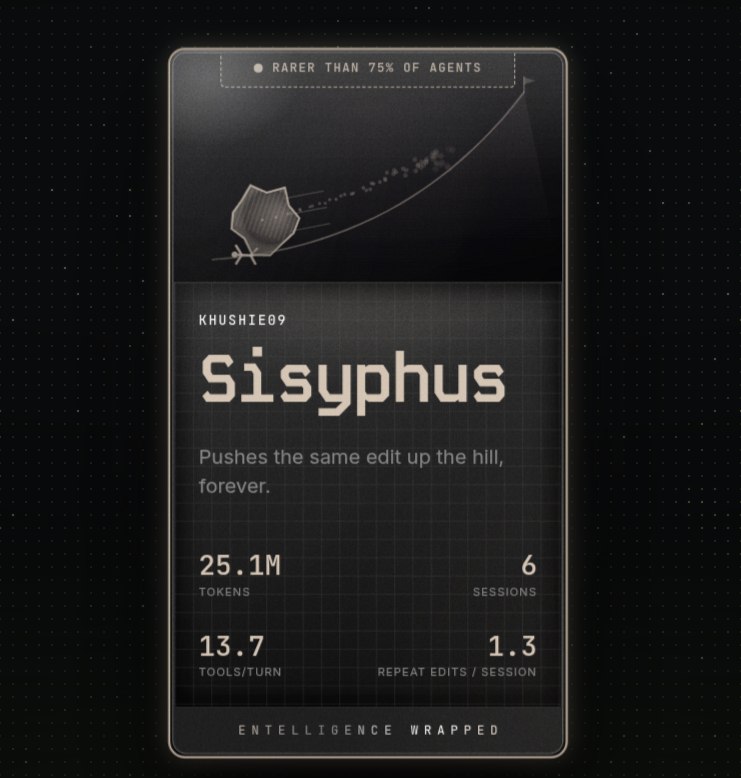
17.2M tokens.
5 sessions.
6.5 tools per turn chaos.
Entelligence called me a whale 🐋
Spotify Wrapped wishes it had this level of damage

Everyone is tokenmaxxing but some people burn 20B tokens and produce OpenClaw while others produce massively disastrous slop 🫠
Which one are you?
Launching @EntelligenceAI Wrapped. Analyze your AI coding personality across every coding agent
-> wrapped.entelligence.ai
10
2
57
1,535
Entelligence AI retweeted

Jun 9
"we burned 20B tokens this month."
okay and?
did it ship something great?
or did it ship a very expensive bug?
because the count can't tell you.
it never could!
it only measures how much the model talked, not whether it said anything worth hearing.
- volume is noise
- behavior is signal.
@EntelligenceAI tracks what the model actually does, not how much it spends doing it.
check now: wrapped.entelligence.ai/
Everyone is tokenmaxxing but some people burn 20B tokens and produce OpenClaw while others produce massively disastrous slop 🫠
Which one are you?
Launching @EntelligenceAI Wrapped. Analyze your AI coding personality across every coding agent
-> wrapped.entelligence.ai
45
2
113
2,500
Entelligence AI retweeted

Jun 9
We have Datadog for infra. Linear for issues. Figma analytics for design.
But for the tool engineers now spend the most time in? Nothing.
AI coding visibility is the gap nobody's talking about.
@EntelligenceAI just launched the first step to fix it and it's actually fun.
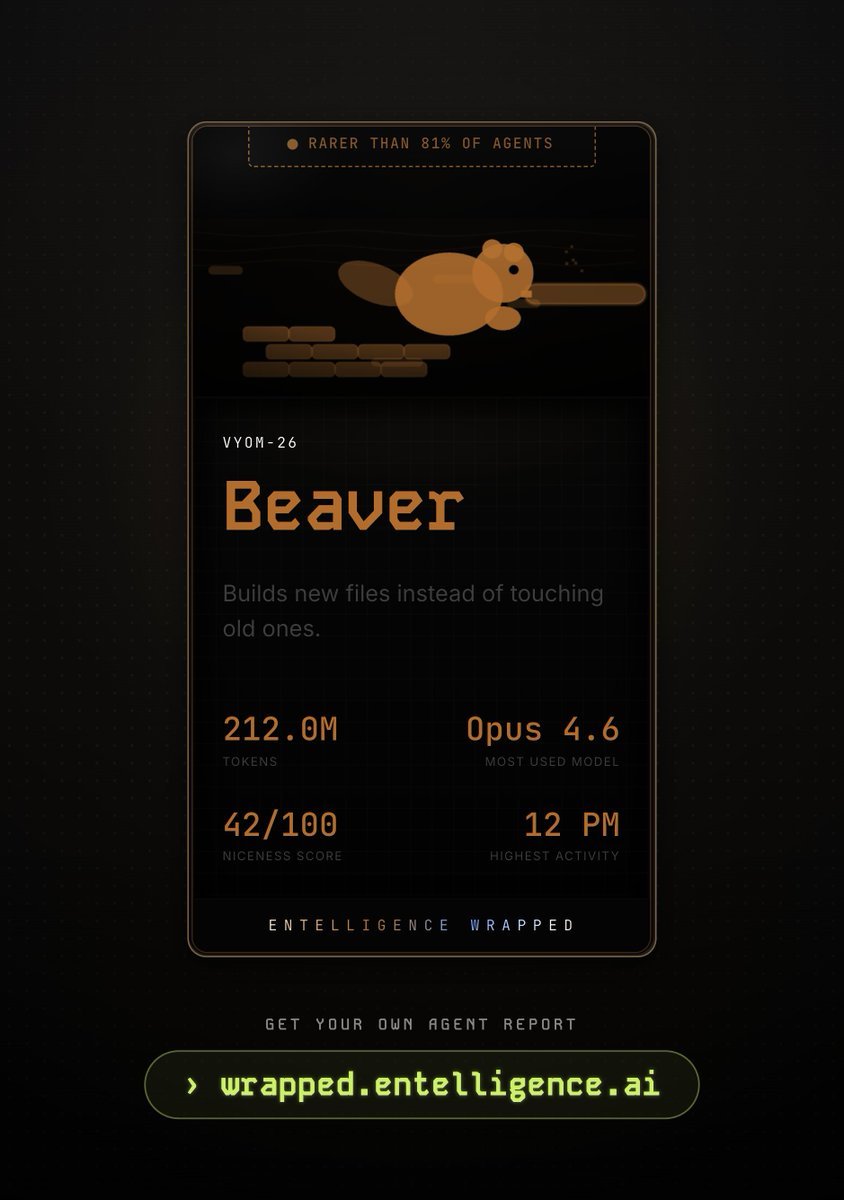
212M tokens in. Rarer than 81% of agents. Beaver confirmed.
wrapped.entelligence.ai
13
10
25
3,450
Entelligence AI retweeted
"Using it well" is actually a skill to optimize on
Most engineers don't yet understand the differences between context pollution and context pressure, how to optimize their usage across different tools and what updates can be made to agent.md files to optimize it

Jun 5

If big companies can't make a net return on their LLM token costs, that doesn't mean it's impossible to. In fact this is exactly what you'd expect to happen with a new technology. Incumbents can't use it well, and are replaced by upstarts who can.
3
3
13
2,046
Entelligence AI retweeted
So so much cooking @EntelligenceAI
Determined to make sure coding agents and reviewers have all the production context they need to never make the same mistakes more than once
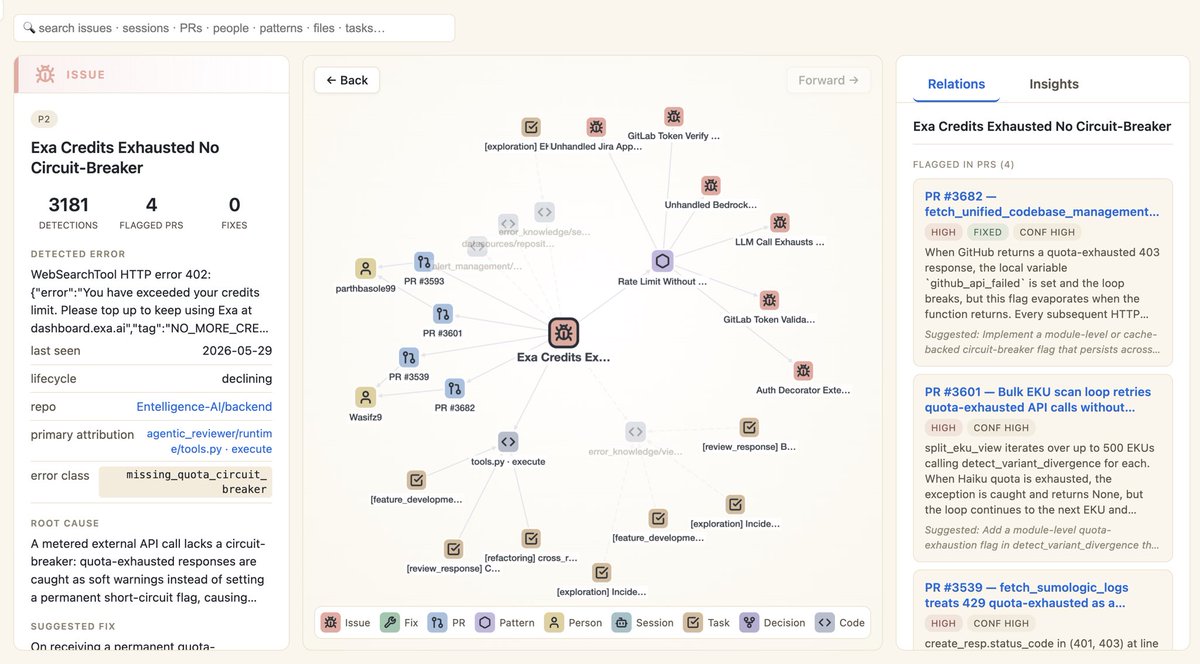
1
3
18
847
Entelligence AI retweeted
Jun 7
what's your spirit vibe coding animal... DM to get one :P

3
3
17
1,023
Entelligence AI retweeted
The @EntelligenceAI team killed it yesterday
We invited several of our customers to come race Porsche on the pier
Bonding out of the office is nearly always one of the best ways to build the relationships that actually matter


3
4
60
2,878

Entelligence AI retweeted
Porsche racing today!!
Yes that’s the @EntelligenceAI logo on a Porsche. Kinda crazy sometimes the kinda things you can do 😆
Get away from your laptops and come join for the day! Luma below

4
3
43
2,408

Entelligence AI retweeted

The stat that jumped out to me wasn't code churn.
It was that only 21% of review comments get addressed.
That's like paying for a map and ignoring the directions.
Excellent analysis of where engineering time actually goes.
Tokenmaxxing is throwing money down the drain
Analyzed 1M PRs over 2.4k companies and here are the stats:
- 1 in every 4 lines is code churn
- Only 21% of code review comments are addressed
- at the 90% percentile, 76% of work is reactive bug fixes
Full report below 👇
16
34
134
17,593
Entelligence AI retweeted

Jun 3
This lowkey matches my observations
Code slop is so bad even in my code at work, that I literally waste one more prompt on deslopping
Unnecessary tokens wasted everyday, and this gets worse with every new model
Nice to see someone solving this
Tokenmaxxing is throwing money down the drain
Analyzed 1M PRs over 2.4k companies and here are the stats:
- 1 in every 4 lines is code churn
- Only 21% of code review comments are addressed
- at the 90% percentile, 76% of work is reactive bug fixes
Full report below 👇
3
4
74
7,305
Entelligence AI retweeted
Jun 3
Everyone is talking about how AI is making developers more productive.
But productivity and progress aren't always the same thing.
After analyzing 1M pull requests across 2,444 organizations, Entelligence found:
• 1 in 4 lines of code gets thrown away
• Only 21% of review comments are addressed
• Reactive work dominates engineering time at many teams
The takeaway:
The challenge isn't generating more code.
It's making sure more of that code actually ships and creates value.
Interesting research from Entelligence.
Tokenmaxxing is throwing money down the drain
Analyzed 1M PRs over 2.4k companies and here are the stats:
- 1 in every 4 lines is code churn
- Only 21% of code review comments are addressed
- at the 90% percentile, 76% of work is reactive bug fixes
Full report below 👇
9
6
85
1,440