
The AI Operating System For Work
Joined September 2025
- Tweets 27
- Following 12
- Followers 657
- Likes 30
6 Photos and videos


Eragon retweeted

Kinda crazy that @EragonAI just navigated through the entire DoorDash page via browser use and ordered us our favorite Oren's Hummus 😎🤑
1
1
4
1,398

2/ A core issue with parameter-only RL is that it forces task-specific learning into the model weights. Traditional RL can improve model performance on the current task, but it also tends to shift behavior away from the base model, increase forgetting and reduce plasticity. On the other hand, prompt optimization alone has the opposite limitation, as it is fast and cheap, but usually not enough to match the gains from weight updates.
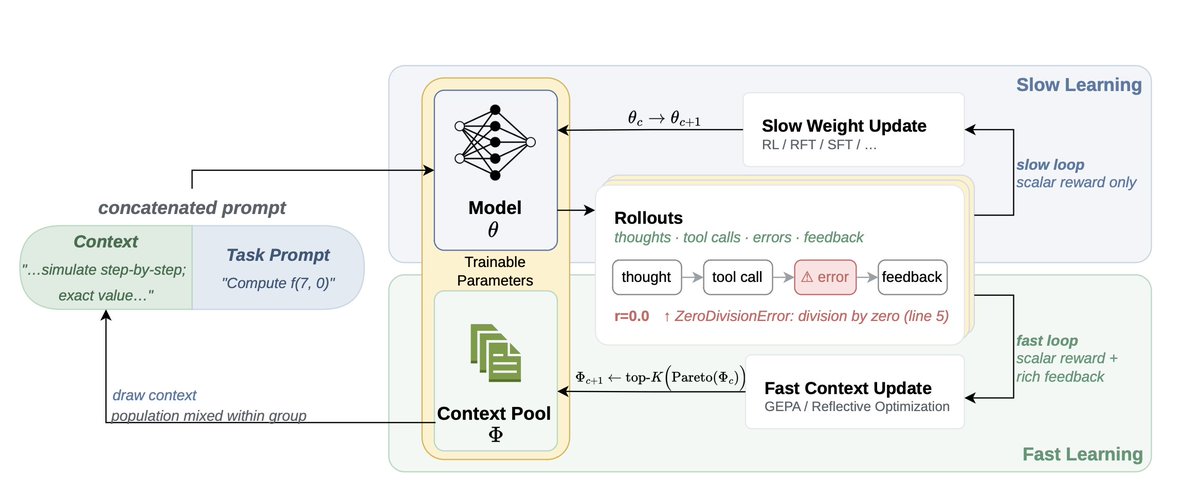
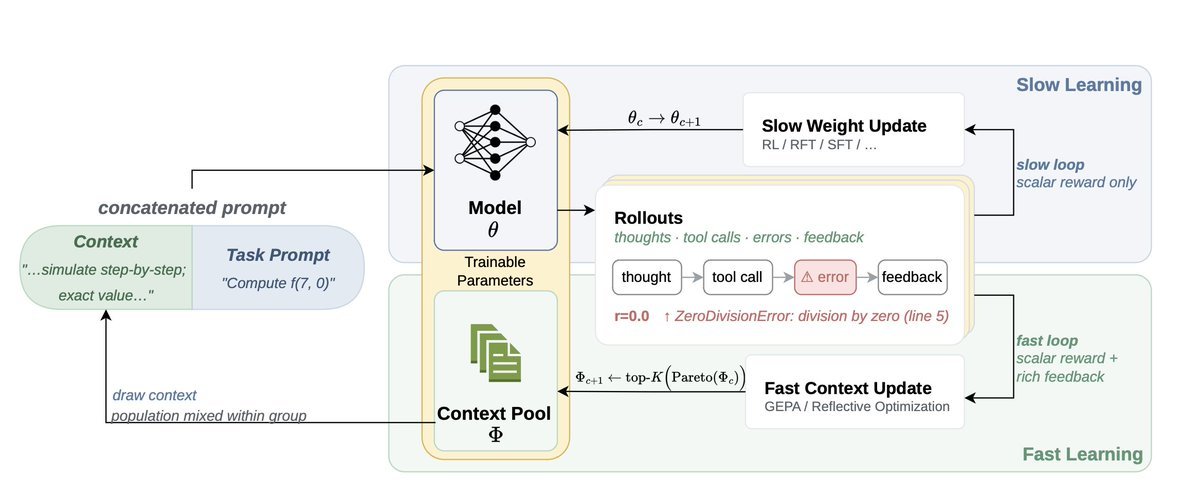
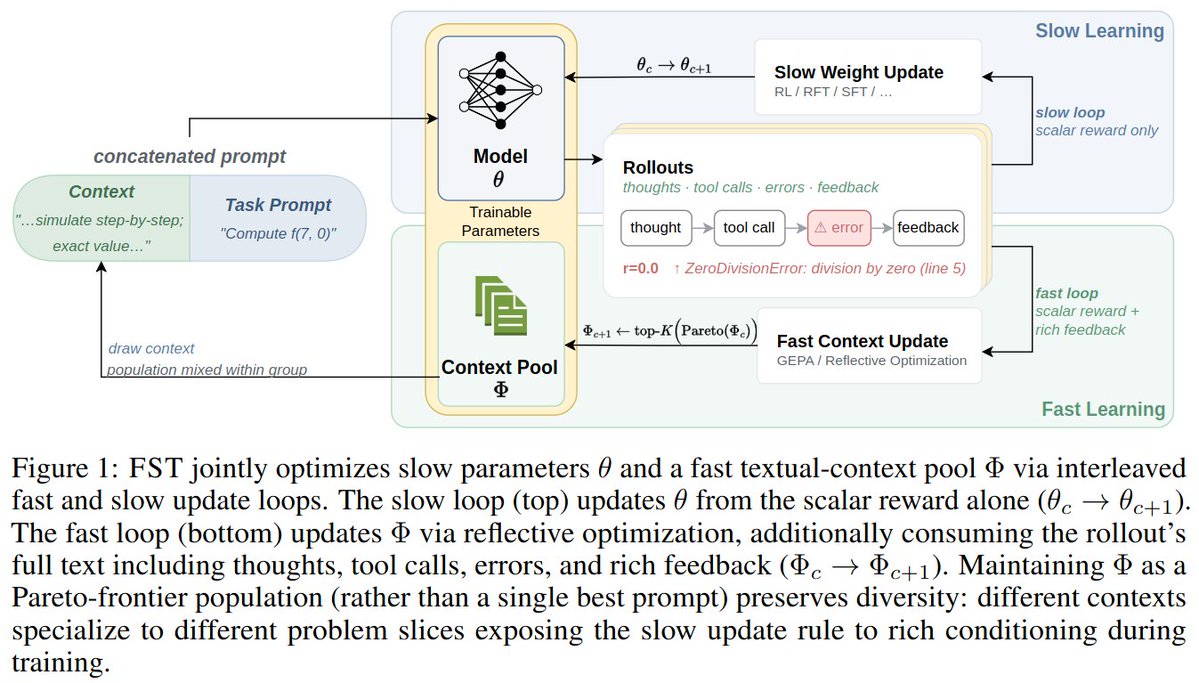
The paper introduces Fast-Slow Training (FST). FST splits adaptation into two co-evolving channels:
Slow weights (θ): the model parameters, updated by RL Fast weights (Φ): a population of prompts, evolved by GEPA
In FST, context is updated from rich textual feedback, while RL updates the model more gradually. Each round interleaves a GEPA reflection cycle — a reflection model rewrites prompts from failure traces — with a few RL steps sampled across that prompt population. Both channels optimize the same reward, concurrently. No parameter freeze, no sequential hand-off.
This lets task-specific lessons move quickly through the fast channel, while preserving more of the base model’s general behavior in the slow channel.
1
2
175
4/ This reframes post-training. The default view treats adaptation as one channel — push every improvement into the weights — and pays for it with forgetting, eroded generality, and lost plasticity. FST splits that into two channels that co-evolve: task-specific nuance lives in fast weights (prompts), durable capability in slow weights (parameters). And it's a blueprint, not a single algorithm.
At Eragon, we are interested in AI systems that keep getting better at new things without getting worse at everything else.
If you are an engineer working in Applied AI and/or Machine Learning, join Eragon to build the future underlying layer of the next form of human organization.
eragon.ai/careers
2
142
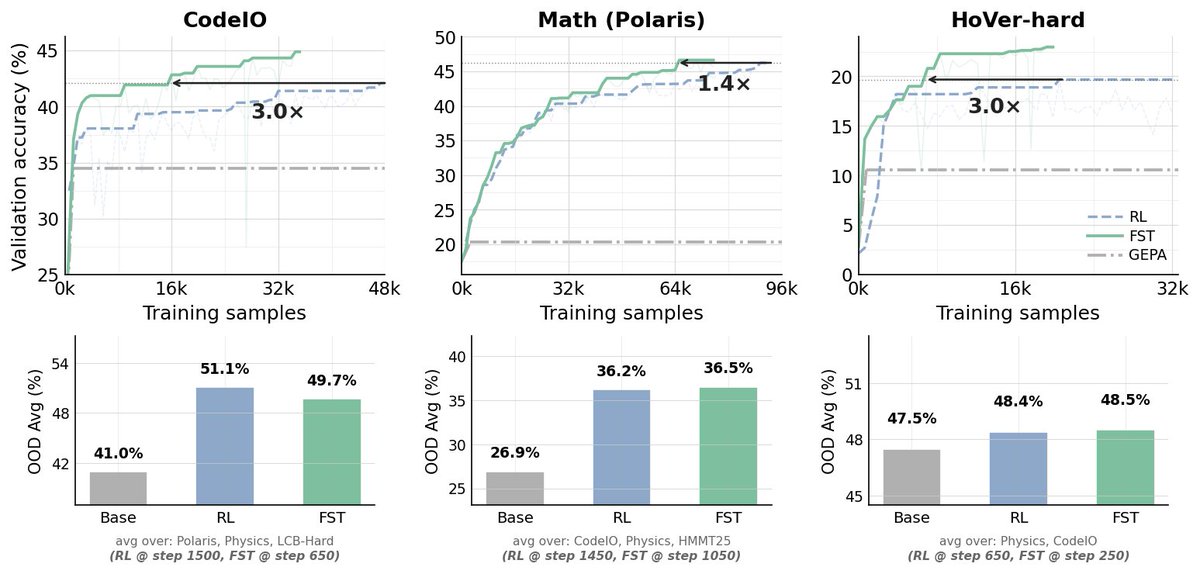
3/ FST beats RL-only across four axes:
- Data efficiency: FST reaches RL's running peak in substantially fewer optimizer steps — 3.0× fewer on CodeIO, 1.4× on Math (Polaris), and 3.0× on HoVer-hard — and continuing past the crossover, FST's running peak also exceeds RL's on all three tasks.
- Higher performance asymptote: FST scores higher than RL across all three performance asymptote: 4.4pp on CodeIO, 2.9pp on math, 7.7pp on HoVer-hard
- Preserved plasticity: at matched reward, FST models have up to 70% lower KL to the base policy than RL-only baselines. Starting from a Math or Physics checkpoint trained with either method, a fresh RL pass on HoVer-hard over 400 steps, while FST-init preserves more capacity for the new task than RL-init on both arms, and on the Math arm prior RL collapses HoVer-hard learnability to near-zero.
- Continual learning: in a 3-task stream, FST gained ~20pp in a stage where RL gained ~2.5pp (~8× the acquisition rate)
1
109
Eragon retweeted

May 29
How FST Works: To leverage the strong in-context learning of current LLMs, we treat the context as "fast weights" and model parameters as "slow weights", drawing from a rich literature in classic ML
2
6
726
Eragon retweeted
May 29
Announcing Fast-Slow Training (FST) pairing "slow" weights with "fast" context.
We try to answer the question, can LLMs adapt continually without losing base skills?
FST vs RL:
- 3x more sample-efficient
-Higher performance ceiling
- Less KL drift
- Continual learning: succeeds where RL stalls

2
3
12
1,088
Eragon retweeted

May 28
Excited to share our first research paper Learning, Fast and Slow: Towards LLMs That Adapt Continually.
Fast-Slow Training (FST) combines optimized context with model weight updates.
Read more here: arxiv.org/pdf/2605.12484

1/ At Eragon, we’re building an AI operating system that connects a company’s entire tech stack into a single interface for work, powered by a model post-trained on the customer’s own data so it understands the company’s unique context.
We believe that AI system post-training shouldn’t have to choose between adapting quickly and learning durably: the future of adaptive AI is fast learning slow learning:
- fast enough to absorb task-specific lessons
- slow enough to improve without forgetting
Our recent research paper: Learning, Fast and Slow, makes that case.
arxiv.org/abs/2605.12484
2
2
705
1/ At Eragon, we’re building an AI operating system that connects a company’s entire tech stack into a single interface for work, powered by a model post-trained on the customer’s own data so it understands the company’s unique context.
We believe that AI system post-training shouldn’t have to choose between adapting quickly and learning durably: the future of adaptive AI is fast learning slow learning:
- fast enough to absorb task-specific lessons
- slow enough to improve without forgetting
Our recent research paper: Learning, Fast and Slow, makes that case.
arxiv.org/abs/2605.12484
13
9
68
5,406
Shoutout to researchers from @UCBerkeley @Mila_Quebec @UTAustin @periodiclabs and Mirendil on this collaboration!
1
1
475
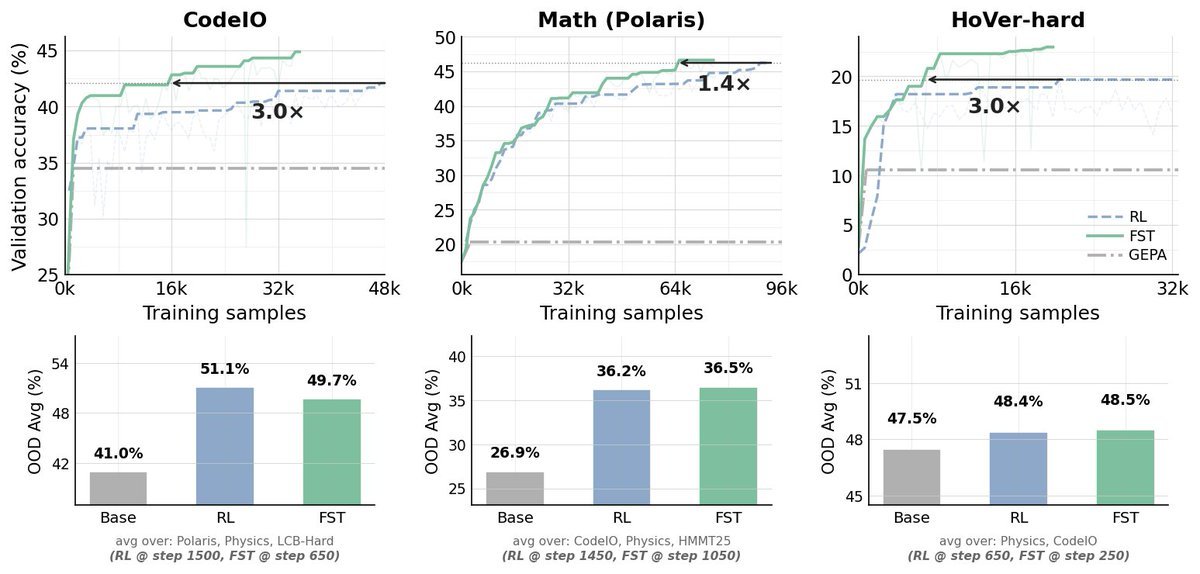
3/ FST beats RL-only across four axes:
- Data efficiency: FST reaches RL's running peak in substantially fewer optimizer steps — 3.0× fewer on CodeIO, 1.4× on Math (Polaris), and 3.0× on HoVer-hard — and continuing past the crossover, FST's running peak also exceeds RL's on all three tasks.
- Higher performance asymptote: FST scores higher than RL across all three performance asymptote: 4.4pp on CodeIO, 2.9pp on math, 7.7pp on HoVer-hard
- Preserved plasticity: at matched reward, FST models have up to 70% lower KL to the base policy than RL-only baselines. Starting from a Math or Physics checkpoint trained with either method, a fresh RL pass on HoVer-hard over 400 steps, while FST-init preserves more capacity for the new task than RL-init on both arms, and on the Math arm prior RL collapses HoVer-hard learnability to near-zero.
- Continual learning: in a 3-task stream, FST gained ~20pp in a stage where RL gained ~2.5pp (~8× the acquisition rate)
1
1
4
499
4/ This reframes post-training. The default view treats adaptation as one channel — push every improvement into the weights — and pays for it with forgetting, eroded generality, and lost plasticity. FST splits that into two channels that co-evolve: task-specific nuance lives in fast weights (prompts), durable capability in slow weights (parameters). And it's a blueprint, not a single algorithm.
At Eragon, we are interested in AI systems that keep getting better at new things without getting worse at everything else.
If you are an engineer working in Applied AI and Machine Learning, join Eragon to build the future underlying layer of the next form of human organization.
eragon.ai/careers
1
3
400
The biggest. Don't miss it.
Live and Direct.
7 Oct 2025

Ȁ�THIS FRIDAY we are hosting the biggest hackathon at sf @Techweek_. win $25K in prizes and network with sf’s top talent.
link to rsvp is in the comments!
supported by @OpenAI, @elevenlabs, @windsurf, @convex, @FireworksAI_HQ, @EragonAI, @vibekanban, and more.

2
11
7,679
Eragon retweeted
8 Sep 2025
What's faster?
@EragonAI or jumping out of a plane?
@michaelhyunkim , @haakamaujla , @RealJonMaynard @wgenesen and I wanted to put it to the test.
9
3
31
6,264
Eragon retweeted
4 Sep 2025
Today I am introducing @EragonAI , your AI Operating System for work.
Our goal is simple: Build the AI that can help you run your company from idea to IPO.
In order to truly fix work, we need to solve the root problem.
We all use tons of business apps from ERP to CRM to Product Analytics but we still have to endlessly switch, search, and export just to answer a single question.
The bottleneck is not having more tools, it's the lack of a unified layer that connects and understands them all.
That's why we built @EragonAI
-Through MCP we connect to every business app.
-Through custom agents, each tool gets its own intelligence.
-And inside one workspace all you have to do is ask
Eragon for any business insight:
- "Walk me through our sales forecast and what deals are at risk."
- "Which users hit paywall but didn't convert?"
- "Where's the bottleneck in our factories this week?"
Already, teams are cutting days of manual work into minutes.
We're working with the fastest growing startups and some of the worlds largest enterprises.
And we would love to work with you!
Book a demo with us today and usher in the new era of vibe working.
50
22
202
99,898