
Joined March 2026
- Tweets 39
- Following 5
- Followers 24
- Likes 2
4 Photos and videos
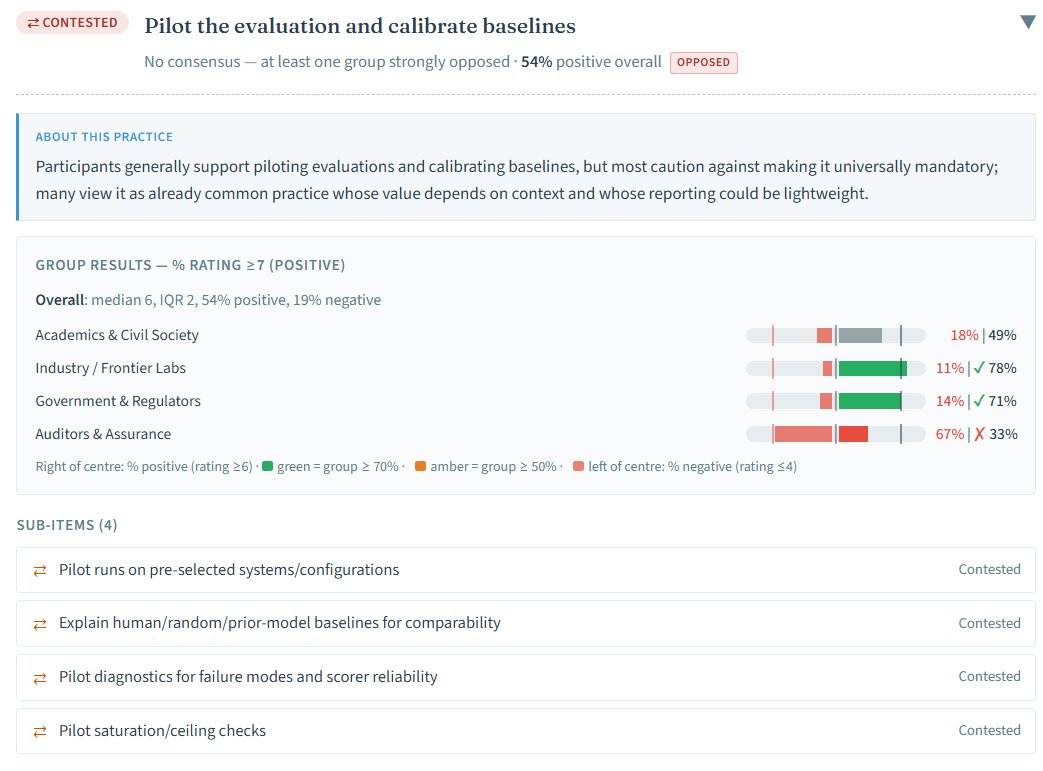




There’s a remarkable level of consensus already about AI evaluation practices - not universal, but broad. We’ll be sharing the results broadly soon, but we want to discuss a few places where consensus doesn’t exist, and our approach. 🧵
1
1
2
209
Using this set of practices as a baseline strikes a balance between aiming for what is good enough and aiming for what is achievable now because it is broadly supported. But the consensus statement is not an end state for better evaluations, it’s a step forward.
1
17
Of course, consensus about practices is just one of the steps needed for improvements in performing and sharing evaluations.
Thankfully, much other work is occurring elsewhere (cc: @evaluatingevals, @aievalforum, and other places,) and we're eagerly awaiting seeing more!
15
Everyone says we need better evals - but why does a consensus process help?
The short answer is that common knowledge encourages coordination, and makes bad practices more costly.
The long answer is a thread.🧵
1
1
1
198
Our (imperfect) answer is to find consensus on practices that are seen as important across stakeholder groups.
That answer won’t tell anyone whether an eval is good enough, much less great, but it will help raise the minimum bar for those practices which are broadly accepted.
1
35
The still-missing ingredient isn’t what to do (results forthcoming soon!)
It’s getting buy-in from the stakeholders - so we're reaching out now, and are happy to speak with relevant organizations.
x.com/EvalConsensusAI/status…

In the coming weeks, anyone interested in endorsing the results should be in touch; we’ll be sharing results with potential endorsers, then will open endorsement widely to labs, auditors, industry, organizations, academics, and civil society groups.
18