
On-device ML Engineer | 🤖Passionate about reverse-engineering neural nets | 🚀Optimizing large models for the edge 💻📱
Joined May 2011
- Tweets 341
- Following 544
- Followers 862
- Likes 1,613
32 Photos and videos









Pinned Tweet
56,000 tokens/sec at just 80 MHz. 🤯
I burned a full Transformer with KV cache into a custom chip. Designed gate by gate as a 100% digital integrated circuit. Prototyped on a FPGA. (No GPU. No CPU)
Just pure digital silicon running @karpathy microGPT, spelling out names on a tiny LCD.
This is GateGPT 👇
93
209
2,169
144,501
No GPU, no CPU - a full Transformer with KV cache as RTL on a Virtex-5 FPGA. microGPT at ~56k tokens/s, fully open-source. Thought you'd appreciate this, @reach_vb 🙂

56,000 tokens/sec at just 80 MHz. 🤯
I burned a full Transformer with KV cache into a custom chip. Designed gate by gate as a 100% digital integrated circuit. Prototyped on a FPGA. (No GPU. No CPU)
Just pure digital silicon running @karpathy microGPT, spelling out names on a tiny LCD.
This is GateGPT 👇
1
8
78
4,569
Built a full Transformer with KV cache in RTL, prototyped on a Virtex-5 FPGA microGPT at ~56k tokens/s. Thought this might interest you @pcuenq
56,000 tokens/sec at just 80 MHz. 🤯
I burned a full Transformer with KV cache into a custom chip. Designed gate by gate as a 100% digital integrated circuit. Prototyped on a FPGA. (No GPU. No CPU)
Just pure digital silicon running @karpathy microGPT, spelling out names on a tiny LCD.
This is GateGPT 👇
2
28
1,582
56,000 tokens/sec at just 80 MHz. 🤯
I burned a full Transformer with KV cache into a custom chip. Designed gate by gate as a 100% digital integrated circuit. Prototyped on a FPGA. (No GPU. No CPU)
Just pure digital silicon running @karpathy microGPT, spelling out names on a tiny LCD.
This is GateGPT 👇
93
209
2,169
144,501
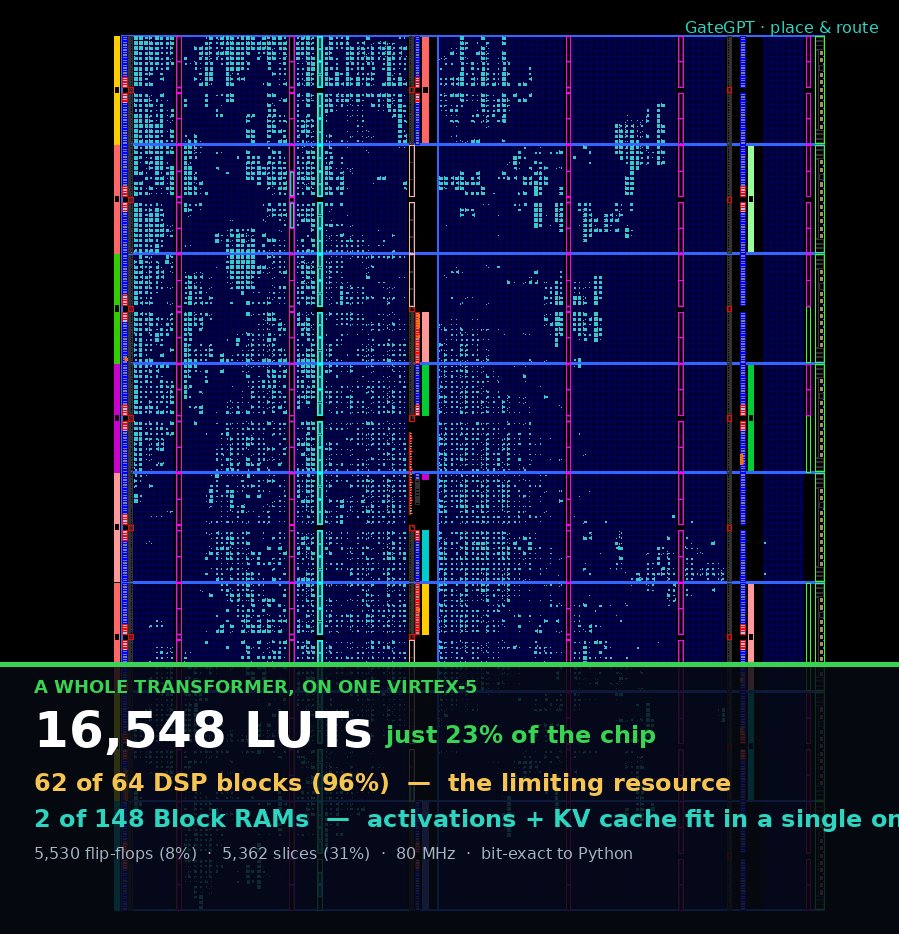
The whole Transformer fits in 23% of the LUTs and a single Block RAM (activations KV cache live there)
But it pins 62 of 64 DSPs at 96%. The multipliers are the wall. This is the actual place-and-route on the Virtex-5
3
3
66
6,721
How it hits 56,000 tok/s
No monolithic FSM.
A microcode ROM sequences modular datapath actuators - matvec, attention, RMSNorm, exp, sampler - over one true dual-port scratchpad that also holds the persistent KV cache.
1 block · 24-dim · 4 heads · ctx 16 · Q5.11, bit-exact to Python.
7
1
53
5,858
Code (RTL, fixed-point spec, microcode ISA, weights) : github.com/fguzman82/gateGPT
1
3
190
The whole Transformer fits in 23% of the LUTs and a single Block RAM (activations KV cache live there)
But it pins 62 of 64 DSPs at 96%. The multipliers are the wall. This is the actual place-and-route on the Virtex-5
1
155

19 Nov 2025
Welcome VibeThinker-1.5B to MLX! 🚀
This 1.5B model is competitive with GPT-OSS-20B and MiniMax 456B on AIME2025! 🤯
ONLY 1.54GB MEMORY FOOTPRINT! ⚡️
Run it locally on your Mac now:
🤗 Model: huggingface.co/mlx-community… 💻
Github: github.com/WeiboAI/VibeThink…
#MLX #AppleSilicon
11
39
277
16,911
20 Nov 2025
20 Nov 2025
Solve the derivative of sin(x²) step by step
(60.93 tokens/s on an iPhone 17 Pro)
620
20 Nov 2025
Running VibeThinker-1.5B on iPhone.
~1.5GB RAM usage, reasoning behavior comparable to GPT-OSS-20B.
This is where edge AI is heading.
huggingface.co/mlx-community…
5
15
165
10,026
20 Nov 2025
Solve the derivative of sin(x²) step by step
(60.93 tokens/s on an iPhone 17 Pro)
3
1,050
20 Nov 2025
20 Nov 2025
Running VibeThinker-1.5B on iPhone.
~1.5GB RAM usage, reasoning behavior comparable to GPT-OSS-20B.
This is where edge AI is heading.
huggingface.co/mlx-community…
3
975
Fabio Guzman retweeted

13 Nov 2025
If you’re still sending raw JSON into your LLMs, you’re burning tokens, latency, and budget!
Try TOON (Token-Oriented Object Notation).
Clear like YAML, compact like CSV:
• 30–60% fewer tokens
• Up to 50% lower costs
• Shines for tabular data.
Free and Open source 🧵↓

511
1,135
8,428
2,537,892
Fabio Guzman retweeted

9 Oct 2025
🧵1/ Latent diffusion shines in image generation for its abstraction, iterative-refinement, and parallel exploration.
Yet, applying it to text reasoning is hard — language is discrete.
💡 Our work LaDiR (Latent Diffusion Reasoner) makes it possible — using VAE block-wise diffusion to reason in continuous latent space.
🧠 LLMs can now refine, diversify, and plan their reasoning just like they denoise an image — but for thoughts instead of pixels.
3
28
180
96,543
Fabio Guzman retweeted

30 Sep 2025
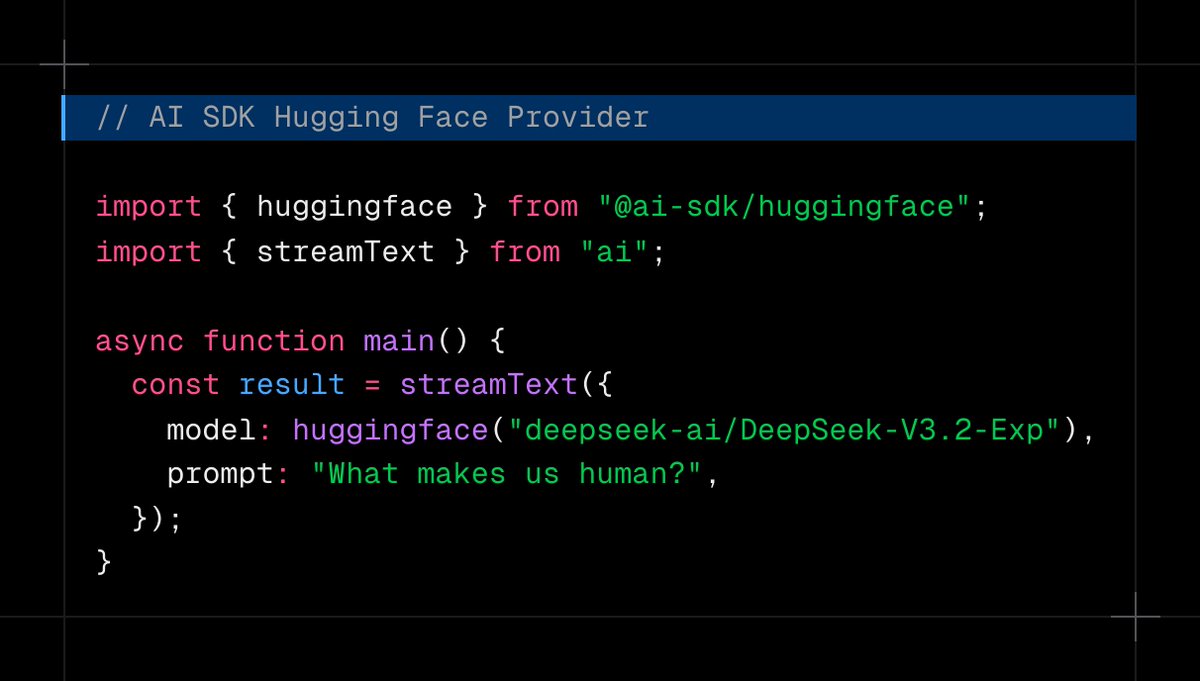
access any model on @huggingface directly with AI SDK
27
36
363
702,732
Fabio Guzman retweeted

17 Jun 2025
🧵 @karpathy dropped the most compelling lecture at the AI startup school :) Here's my notes summarized with Opus.
Main thesis: We're not in the "year of agents" — we're in the DECADE of agents. Here's the historical arc that explains why...
==== The Software Evolution Story ====
First, the foundational shift happening right now. Software is evolving through three distinct paradigms:
• Software 1.0: Code programs the Computer
• Software 2.0: Weights program the Neural Net
• Software 3.0: Prompts program the LLM
We're literally programming in English now. The same pattern that ate through Tesla's C autopilot stack is happening everywhere — Software 3.0 will start consuming existing codebases, but engineers will need to be fluent in all three paradigms.
==== Where We Are Historically ====
But where are we in this evolution? Karpathy's answer: the 1950s-70s timesharing era. Like computers in the past, models are centralized today:
• Centralized expensive compute
• OS (model) runs in the cloud
• I/O streamed over network
• Compute batched over users
Chat is just the terminal — direct access to the operating system. The GUI hasn't been invented yet.
==== The Triple Nature of LLMs ====
LLMs are weird because they have properties of utilities, fabs, AND operating systems simultaneously:
🔌 Like utilities: CAPEX to train (equivalent to building the electrical grid), OPEX to serve intelligence, metered access at $/1M tokens
🏭 Like fabs: Massive R&D investment, deep secrets, with some companies being fabless (using NVIDIA chips) while others own their fab (Google/Amazon with custom GPUs)
💻 Like operating systems: Increasingly complex software ecosystems, switching friction due to different features, clear system/user space boundaries
==== LLMs are Savants with Cognitive Faults ====
LLMs are "stochastic simulations of people". They are superhuman in some areas, but still struggle will
• Hallucination
• Jagged intelligence (superhuman in some areas but make basic mistakes like thinking 9.11 > 9.9)
• Suffer from anterograde amnesia with no long-term memory or continuous learning
• Remain gullible to prompt injection
They're essentially fallible "people spirits" we're learning to work with.
==== What Actually Wins ====
So what wins in this landscape? Partial autonomy apps — the "Cursor for X" pattern. Cursor works because it nails the Generation ↔ Verification loop with four key elements:
• Manual UI where humans can work directly
• AI that packages context automatically
• App-specific GUI (like diffs) for easy human audit
• Slider to choose autonomy level: Tab → Cmd K → Cmd L → background agent mode
==== Iron Man Analogy ====
The Iron Man suit is both an augmentation and an agent. It can run autonomously, but it's most powerful when it combines with Tony Stark.
Partial autonomy that makes the Generation ↔ Verification loop incredibly tight, keeping humans firmly in control while gradually expanding AI capabilities.

17
137
930
106,612
14 Jun 2025
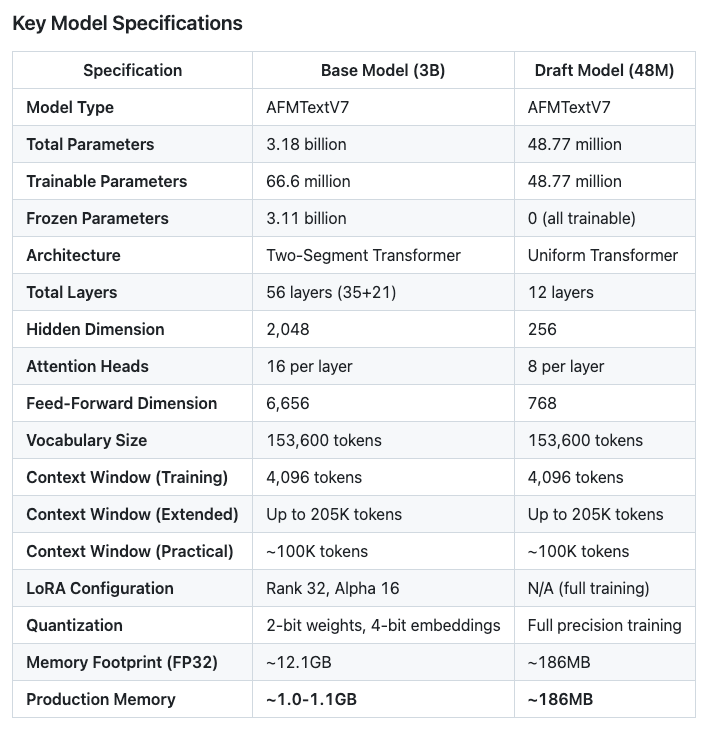
🧵 AFM UPDATE: Draft Model Discovery!
Found Apple's speculative decoding secret weapon:
Draft Model (48.8M params):
12 uniform layers, 256 hidden dim
8 attention heads, 768 FFN
Same 153.6K vocab as base model
Just 186MB memory footprint!
The magic: Draft generates 4-8 candidate tokens → Base model verifies in parallel → 2-4x speedup with zero quality loss
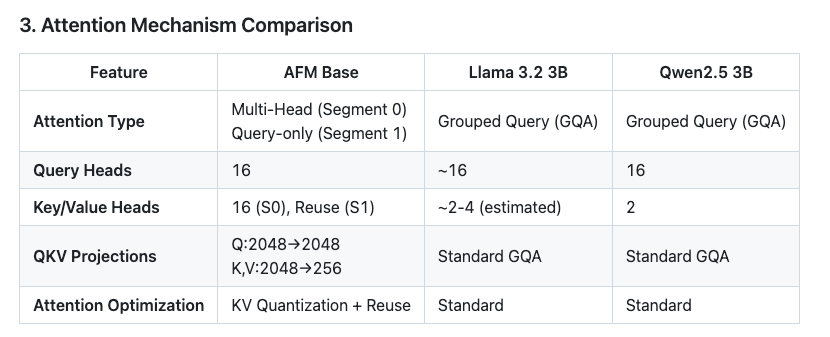
Now the report also includes architectural comparison against Llama 3.2 3B | Qwen2.5 3B 📊
This is how Apple achieves real-time AI on mobile devices 🚀
#WWDC25
12 Jun 2025
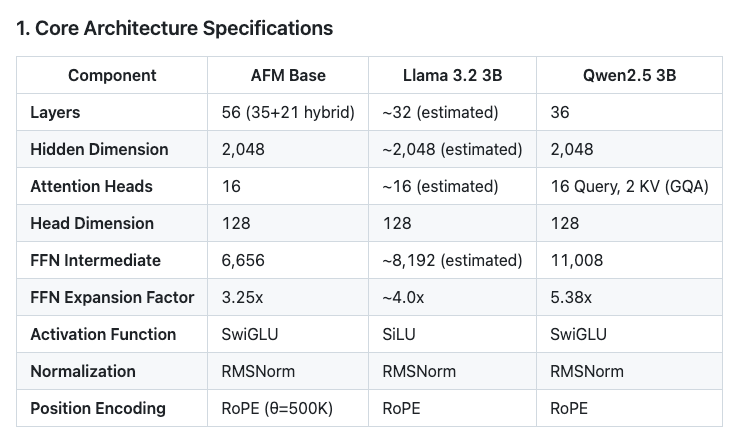
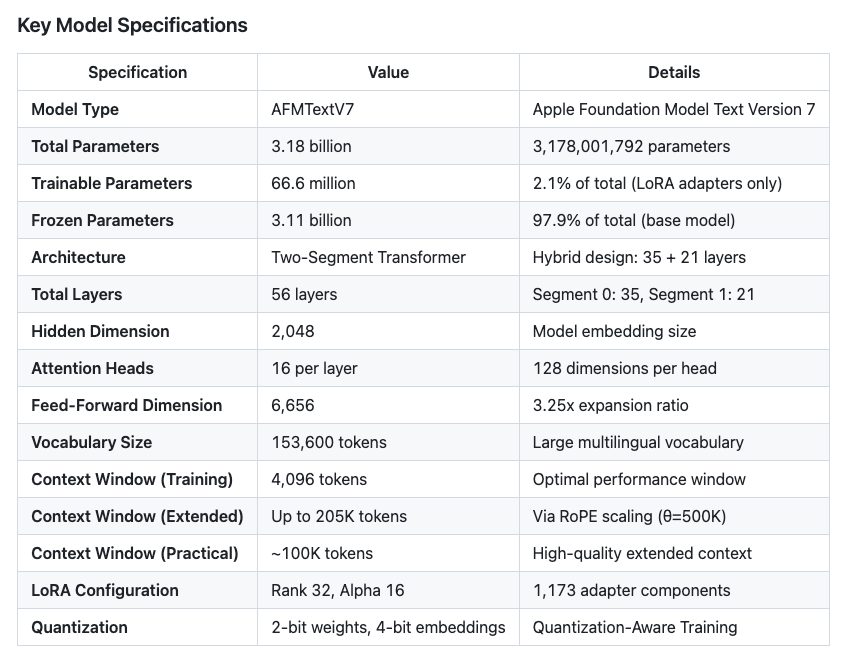
🚀 Draft technical analysis: 3B Apple Foundation Model (AFMTextV7)
Key architectural findings:
- 3.18B total params (3.11B frozen 66.6M trainable)
- Two-segment architecture (35 21 = 56 layers)
- Vocabulary: 153.6K tokens, 4K context RoPE scaling - Native LoRA integration (Rank 32, Alpha 16)
- Just ~1GB footprint on Apple Silicon!
- Full draft report in: github.com/fguzman82/apple-f…
#WWDC25
1
4
11
3,063