
working on optimization for machine learning. currently postdoc @inria_paris.
Joined July 2020
- Tweets 524
- Following 754
- Followers 1,274
- Likes 1,873
95 Photos and videos




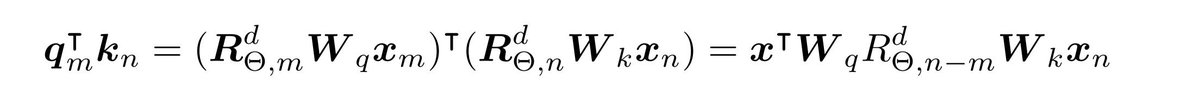







Pinned Tweet

5 Feb 2025
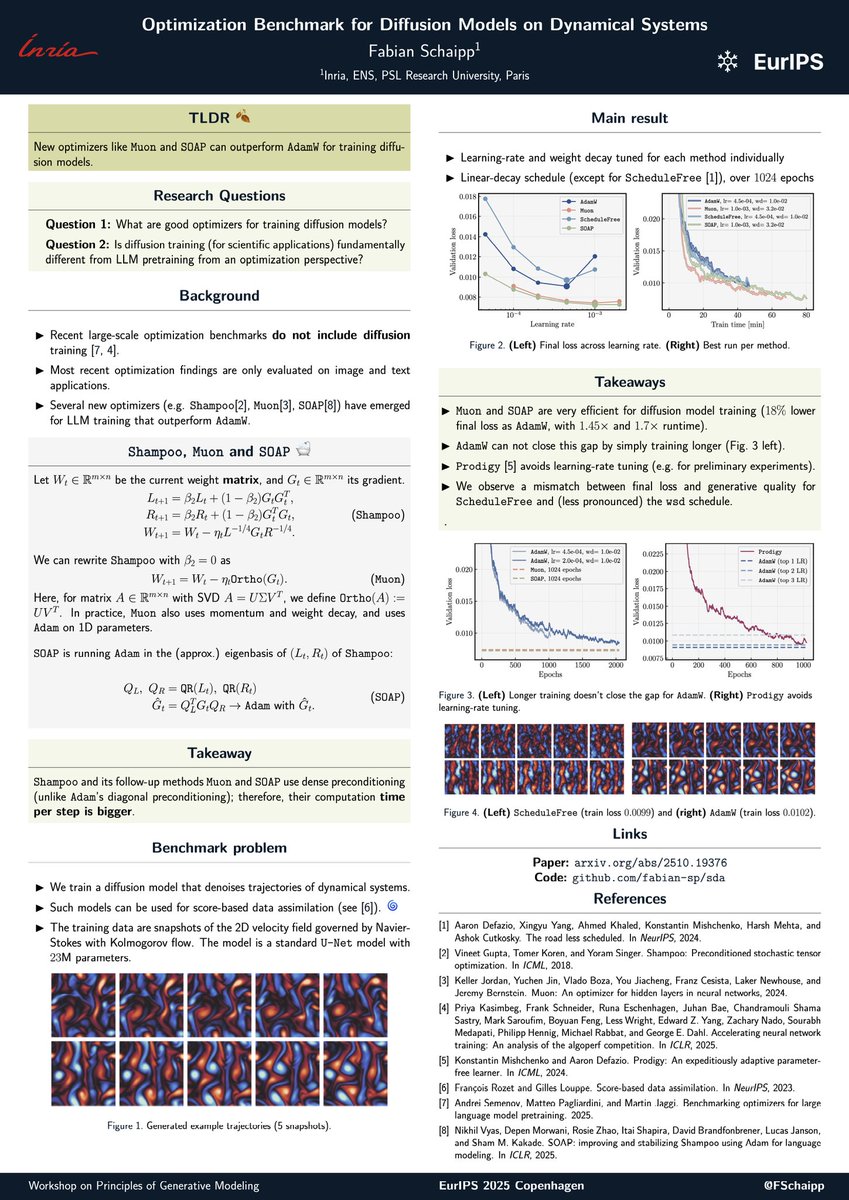
Learning rate schedules seem mysterious?
Turns out that their behaviour can be described with a bound from *convex, nonsmooth* optimization.
Short thread on our latest paper 🚇
arxiv.org/abs/2501.18965
3 Feb 2025

The sudden loss drop when annealing the learning rate at the end of a WSD (warmup-stable-decay) schedule can be explained without relying on non-convexity or even smoothness, a new paper shows that it can be precisely predicted by theory in the convex, non-smooth setting!
1/2
5
27
141
31,661
May 27
"It's easier to tune the LR for method A than for B."
We tried to formalize this for model-based stochastic optimization methods.
We find a key quantity, called stability index, that describes how stable a (weakly) convex bound is as a function of LR.
📚arxiv.org/abs/2602.09842
3
9
67
7,245
May 27
1
1
2
472
May 27
The theory is with SGD as base update step. But all these adaptive step sizes can be used to obtain practical methods. For example, Polyak step sizes in combination with
- Muon (@CrichaelMawshaw): arxiv.org/abs/2510.09827
- ScheduleFree (@aaron_defazio ): arxiv.org/abs/2605.19095
2
7
379
May 21
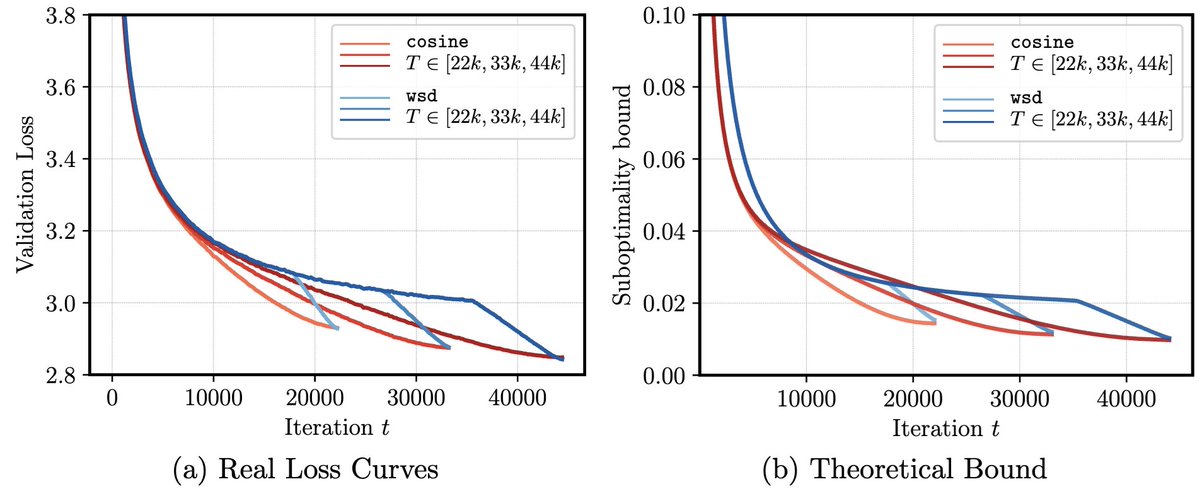
Polyak step size is back!
May 20
🚨 New Paper 🚨
ScheduleFree : Scaling Learning-Rate-Free & Schedule-Free Learning to Large Language Models
A few modifications to Schedule-Free Learning make it completely LR tuning free, and allow it to greatly outperform schedules for long duration training!
arxiv.org/abs/2605.19095v1
38
6,461
Apr 16
Nice result! (from arxiv.org/pdf/2604.13870)
no anytime-schedule can obtain the optimal rate for (S)GD.
to my knowledge, WSD is the closest candidate we know of, as it removes the log-factor in the rate for any cooldown length proportional to T.
1
6
58
4,516
Mar 31
Going to Zurich for a couple of days. I will give a talk on recent optimization stuff @zurichnlp. Always happy to chat 🍫
3
1
29
3,101
Feb 12
After LLMs and diffusion, Muon also shines on tabular foundation models!
Also nice to see they used cautious weight decay 🥌

Super excited that TabICLv2 is out 🎉
🚀Beats RealTabPFN-2.5 with no tuning and purely synthetic pre-training data.
👉Introduces QASSMax for long-context generalization, early target embedding, repeated feature grouping, Muon, etc., and a much diversified synthetic data prior.
1
15
1,053
Feb 8
not to offend anyone, but how tf do these papers get through review when not even the LR of the baseline is properly tuned?
Feb 7

Learning rate matters more than your LoRA variant.
In this study they sweep LR hard across LoRA variants (DoRA, Init[AB], PiSSA, MiLoRA) and find:
> If you tune LR properly, they all converge to approx the same peak perf.
> Rank still matters and can flip which variant looks best depending on dataset.
> Optimal learning rate is a function of how steeply curved the loss is:
>> more curved → smaller steps (lower LR)
>> less curve → larger steps (higher LR)

8
6
155
28,709
Jan 30
> 4.5k citations, but two typos in one of the central equations
3
14
3,163
Jan 26
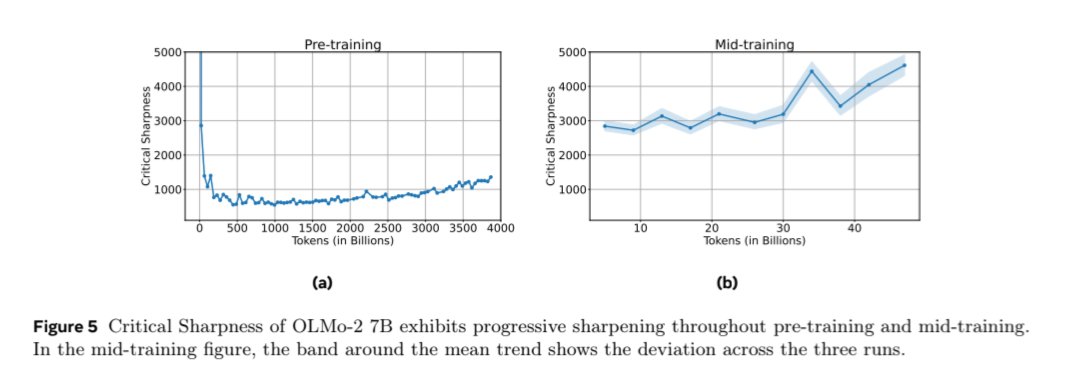
however, the "progressive sharpening at 7B scale" claim seems less convincing to me. the increase here looks mostly to be caused by the cosine schedule
1
2
314

7 Dec 2025
Congrats to the @EurIPSConf organizers, and also thanks to all workshop organizers! In many ways the best conference I have been to.
And Copenhagen is the perfect host city 🇩🇰
1
11
608
2 Dec 2025
Very excited to be in Copenhagen for #EurIPS 🇪🇺
I am presenting an optimizer benchmark for diffusion model training (sunday @ PriGM workshop). it compares new methods (Muon, SOAP, ScheduleFree) to good old AdamW.
Happy to chat anytime ❄️
2
5
40
2,140
2 Dec 2025
i've never been to CPH in christmas seadon before, but already love it
1
290