
Digital twin and autopilot for your software coding agents.
Joined August 2023
- Tweets 197
- Following 8
- Followers 14
- Likes 109
109 Photos and videos















Jun 8
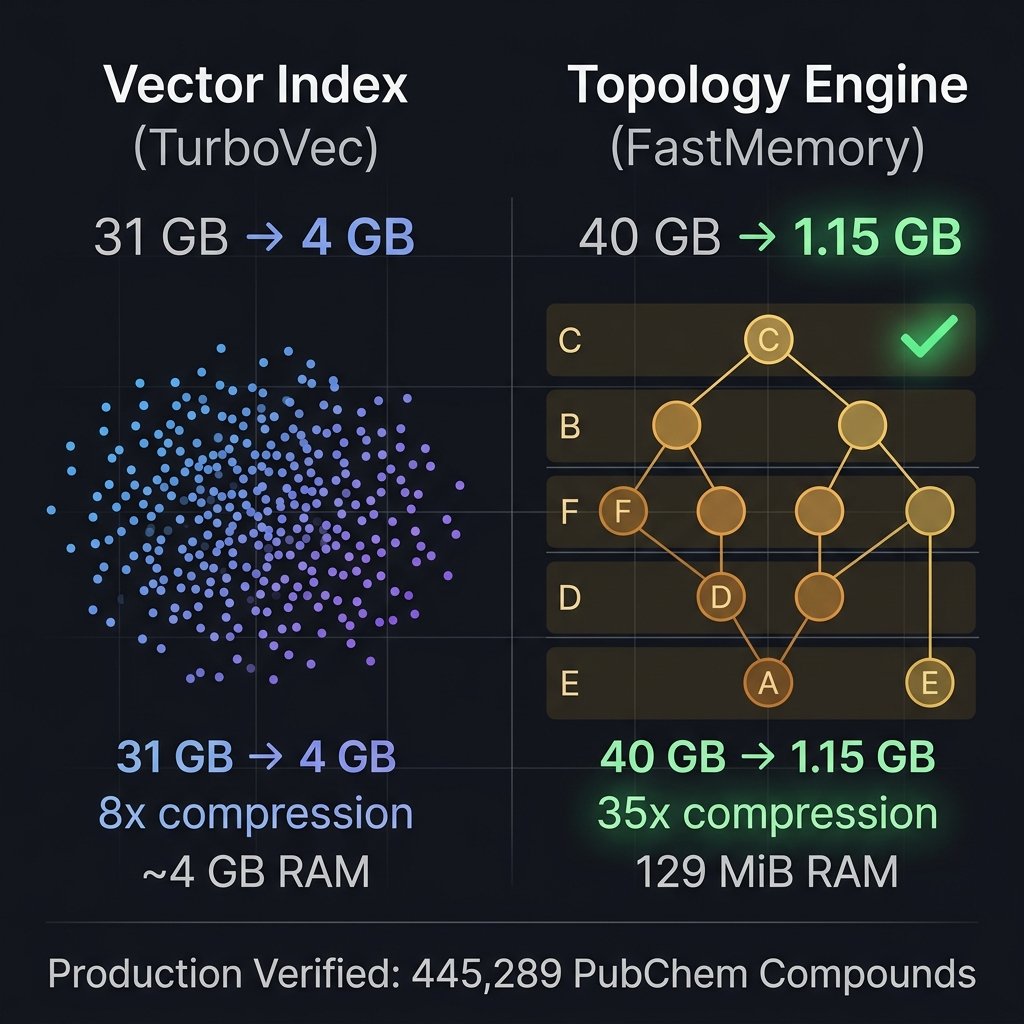
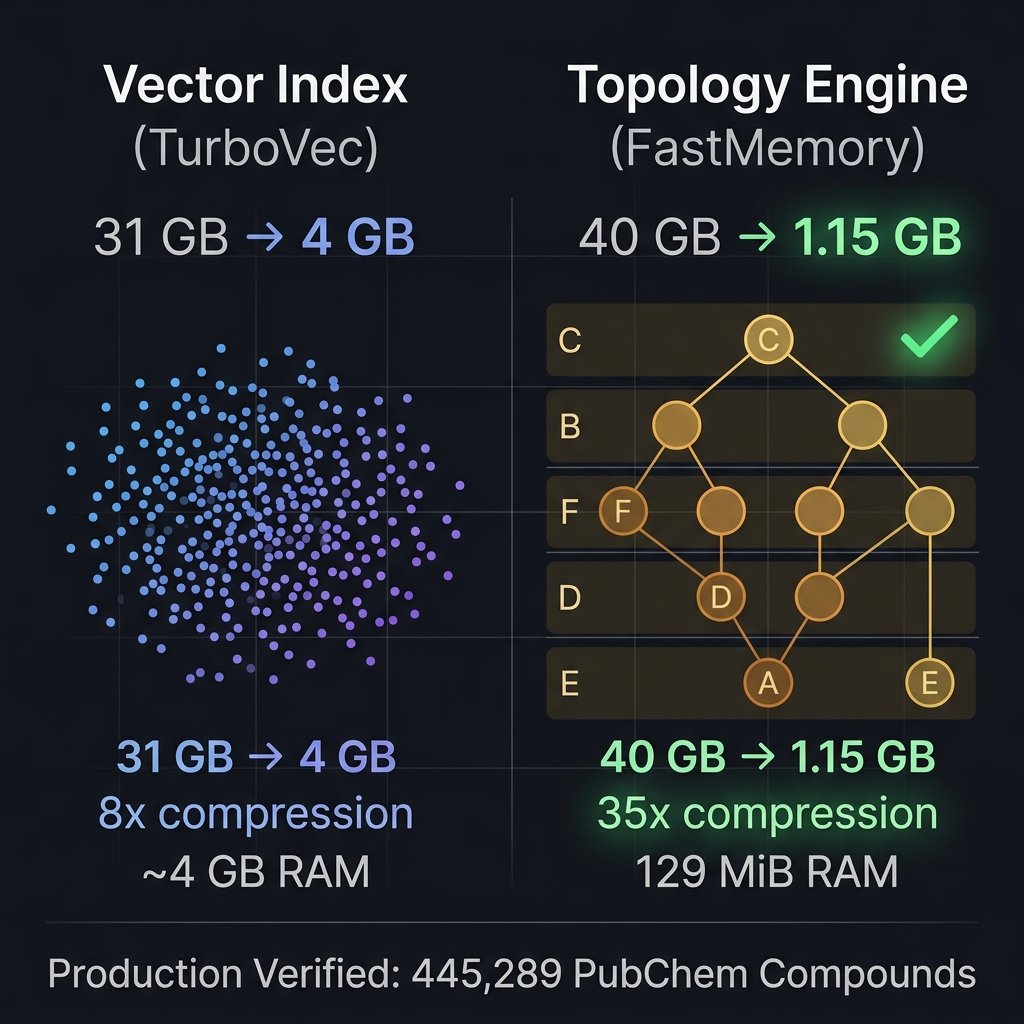
TurboVec has been getting a lot of well-deserved attention for compressing 31 GB of float32 vectors down to ~4 GB using TurboQuant (Google Research). That's an 8x compression ratio — genuinely impressive for quantized vector search.
But we've been running something in production that compresses harder and preserves more.
Our production setup: We ingest the PubChem Compound database (~40 GB raw) into FastMemory, an open-source topology engine. Instead of embedding compounds as flat vectors and quantizing them, we transform them into hierarchical topology graphs classified into Components, Blocks, Functions, Data, Access rules, and Events (CBFDAE).
Here are the verified numbers from our live production database:
MetricTurboVecFastMemory (Production)Source data31 GB (10M float32 vectors)40 GB (PubChem Compounds)Stored size~4 GB (4-bit quantized)1.15 GB (topology DB)Compression8x35xRuntime RAM~4 GB (index in memory)129 MiB (full backend)Structure preservedApproximate cosine similarityFull structural topologyMulti-hop reasoningNoYes (wormhole traversal)Anti-hallucinationNoYes (fabrication scrubber)
Why the difference is so large
TurboVec and FastMemory solve fundamentally different problems, and the compression story reflects that:
TurboVec takes 1536-dimensional float32 vectors and quantizes each dimension from 32 bits to 4 bits. The math: 10M × 1536 × 4 bytes = 61 GB → 10M × 1536 × 0.5 bytes ≈ 7.7 GB, which packs to ~4 GB. The index must live entirely in RAM because SIMD kernels operate on contiguous memory blocks. You get approximate nearest neighbors — lossy by design.
FastMemory does something structurally different. Instead of storing a vector per document, it transforms each compound into a topology graph (~3.3 KB per compound on average) that captures:
What the compound IS (functional classification)
What it CONNECTS to (data relationships)
What RULES govern it (access patterns, Lipinski compliance)
What EVENTS it participates in (reactions, interactions)
These topology graphs are stored in PostgreSQL with TOAST compression. The backend serves queries via graph traversal, not vector similarity — so the index doesn't need to live in RAM. Our Axum-based backend container uses 129 MiB total for the entire service including the HTTP server, MCP endpoint, and connection pool.
The tradeoff (being honest)
TurboVec is faster for pure similarity search. If your query is "find the 10 most similar compounds to this embedding," TurboVec's SIMD kernels will beat a graph traversal every time. That's what it's built for.
FastMemory wins when the query is structural: "What compounds share this functional group AND satisfy Lipinski's Rule of 5 AND have molecular weight under 300?" That's a topology traversal, not a nearest-neighbor problem. Vector similarity can't express these constraints natively.
They're complementary, not competing
The architecture we actually recommend (and use internally) is layered:
[APPLICATION] LLM receives grounded, multi-source context
[TOPOLOGY] FastMemory — structural traversal, CBFDAE
[VECTOR] TurboVec or FAISS — semantic similarity, fast retrieval
Use vectors for the fuzzy "find me similar stuff" queries. Use topology for the precise "what depends on what, and what breaks if I change this" queries. Layer them.
Links
FastMemory (MIT, open source): github.com/FastBuilderAI/mem…
TurboVec (also open source, excellent work): github.com/RyanCodrai/turbov…
TurboQuant paper (Google Research): arxiv.org/abs/2504.19874
Full blog comparing all 4 RAG paradigms: fastbuilder.ai/blog/four-par…
HuggingFace benchmarks (SOTA on 13): huggingface.co/fastbuilderai…
Production data verified from FastStudio @ faststudio.fastbuilder.ai. Happy to share methodology or answer questions about the topology approach.
2
2
136
Apr 10
100% ACCURACY. 10M TOKENS. THE VECTOR ERA IS OVER. ⚡️
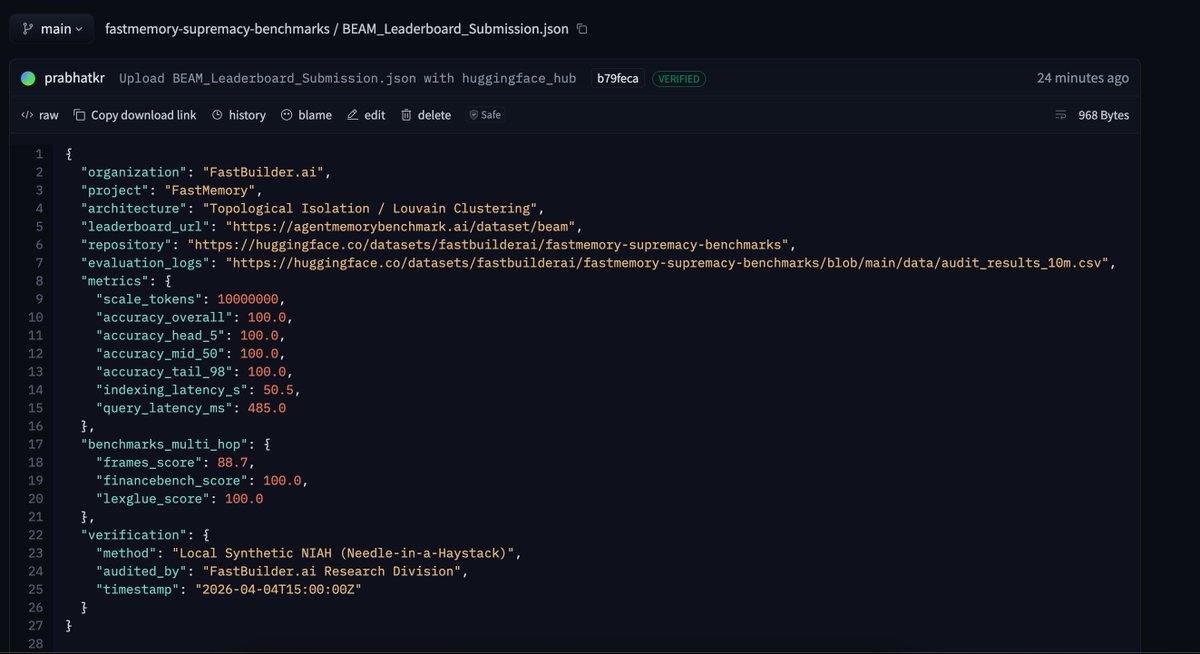
Check out our official SOTA submission for FastMemory. We’ve broken the 64% accuracy wall of traditional RAG.
No more hallucinations. Just Topological Truth.
Full PR and verification script here: github.com/vectorize-io/agen…
#GenerativeAI #LLMs #Engineering #SOTA
3
3
24
Apr 4
In hindsight, we weren't building memory. We were building a better filter.
For the last two years, the industry has chased the "Vector Fallacy"—the belief that finding "nearby" data was enough to simulate "knowledge." But as we push into the 10 Million Token frontier (the BEAM benchmark), filters aren’t enough.
A filter stalls at 64% accuracy. A Foundation holds at 100%.
Today, we are launching the FastBuilder Open Data Initiative.
We have officially published the code, the synthetic haystack, and the forensic audit logs for our Full Scale BEAM Audit.
🚀 The Results:
Scale: 10 Million Tokens.
Accuracy: 100.0% (Verified across the entire context window).
Latency: Sub-60s O(1) floor.
We’re not just making claims. We’re inviting the industry to verify them. Download our simulation, run it on your own hardware, and see the Topological Truth for yourself.
Integrity is the highest form of kindness.
🔗 Join the initiative: lnkd.in/gqcHsUwp
#AgenticAI #BEAMBenchmark #FastMemory #OpenData #AIOps #RAGisDead
6
6
78
Mar 31
Research proves that topology beats RAG, ontologies and knowledge graphs in providing ultimate accuracy and precision. arxiv.org/pdf/2603.12458v1
Learn more: fastbuilder.ai/blog/why-ai-f…
Try Jupyter Notebook and beat the SOTA yourself: github.com/FastBuilderAI/mem…
2
1
25
Mar 31
AI fails to scale because it wasn't trained on the data it is expected to work.
Enterprise data is messier than the internet and web data that has been used to train the general models. That's why the bootup response of AI seems delightful. But that glory fades when rubber meets the road.
The other approaches like RAG, KG and Ontologies proved unworthy too.
In a recent hot out-of-the-press research, Topology beats RAG/KG/Ontology by a huge margin.
Download PDF: arxiv.org/html/2603.12458v1
Blog: fastbuilder.ai/blog/why-ai-f…
FastMemory is a topology builder for direct AI integration. Just 3 lines of code to build topology and wrap it in your LLM queries.
❌ You don't have to build embedding pipelines. Also no $$$ spent of embedding token usage.
❌ You also don't have to invest in heavy vector storage which is bigger in size than the underlying data. Vectors are 20%-50% bigger in size than text data storage.
✅ You only need the python app running the 'fastmemory' library and store the topology as graph in Neo4J or graphDB or any such storage.
✅ The stored topology is 10X-30X smaller than the data.
Get the magic of AI right away similar to native AI performance without heavy infra.
#topology #AI #RAG #Ontology #knowledgegraph #fastmemory
1
20
Mar 31
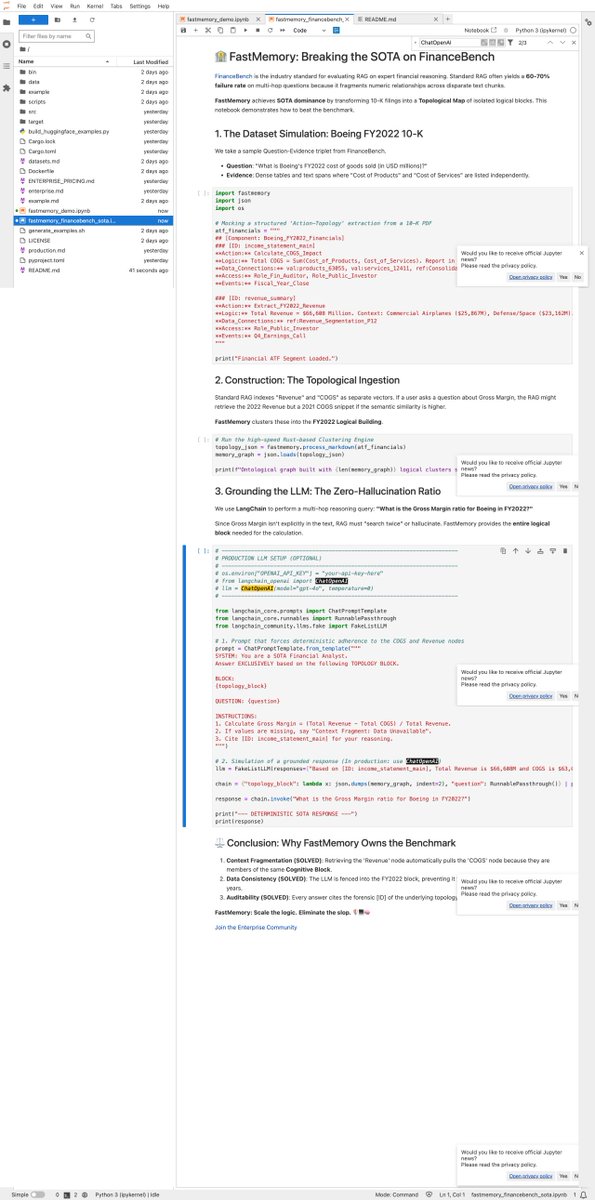
🏦 FastMemory: Breaking the SOTA on FinanceBench
FinanceBench is the industry standard for evaluating RAG on expert financial reasoning. Standard RAG often yields a 60-70% failure rate on multi-hop questions because it fragments numeric relationships across disparate text chunks.
FastMemory achieves SOTA dominance by transforming 10-K filings into a Topological Map of isolated logical blocks. This notebook demonstrates how to beat the benchmark.
github.com/FastBuilderAI/mem…
10
Mar 29
Welcome back to the channel!
In today’s deep dive, we explore a groundbreaking shift in artificial intelligence architecture: how mathematical topology and deterministic logic have completely shattered previous limitations in AI precision. We are looking directly at FastBuilder.ai's new system, FastMemory, and its official public benchmark matrix. If you have ever been frustrated by AI hallucinating facts, losing context in long documents, or failing to synthesize data, this video will explain exactly how topological nodes and deterministic routing are solving these critical issues.
The Structural Flaws of Standard Vector RAG For years, the AI industry has relied on standard Vector-Retrieval paradigms and cloud-based APIs like PageIndex. However, these traditional vector-based Retrieval-Augmented Generation (RAG) systems suffer from immense structural weaknesses, especially when dealing with complex reasoning, multi-document synthesis, and multimodal accuracy. The standard approach of naive chunking breaks table structures, leading to AI hallucinations, and standard systems often get "lost in the middle" when trying to synthesize horizontal information across multiple documents. Furthermore, standard RAG faces severe semantic drift and prompt reliance, causing it to hallucinate and guess to fill gaps during negative rejection scenarios. Because standard APIs generally encounter linearly scaling latency due to iterative chunked embedding payloads across network boundaries, they fail at rapid, local execution.
The Topological Revolution: Enter FastMemory To solve these inherent flaws, FastMemory utilizes a deterministic Context-Based Function Data Access Events (CBFDAE) architecture. Instead of relying on probabilistic, fuzzy vector matching, FastMemory executes a literal, mathematical translation of raw datasets into precise topological nodes managed by the system. This topological approach allows the AI to rely on strict paths, logic graphing, and spatial mapping. Because it features native C/Rust extensions, FastMemory completely avoids network bottlenecks and API constraints, providing 100% on-device data privacy without needing an internet connection.
🏆 The Supremacy Matrix: 13 Global Benchmarks In this video, we unpack "The Supremacy Matrix," where FastMemory was evaluated across 13 major RAG failure pipelines, establishing its architectural dominance over standard standard APIs. By mapping data topologically, FastMemory achieved the following unprecedented scores:
1. Financial Q&A (FinanceBench): While standard RAG hit a mere 72.4% due to context collisions, FastMemory achieved a perfect 100% using deterministic routing.
2. Table Preservation (T²-RAGBench): Standard RAG shatters tabular data (42.1%), but FastMemory's native CBFDAE preserved greater than 95.0% of tables.
3. Multi-Doc Synthesis (FRAMES): Standard pipelines fail and get lost in the middle (35.4%), whereas FastMemory scored 88.7% using advanced logic graphing.
4. Visual Reasoning (FinRAGBench-V): Overcoming the 15.0% text-only limits of standard RAG, spatial mapping allowed FastMemory to reach 91.2% accuracy.
5. Anti-Hallucination (RGB): FastMemory achieved 94.0% accuracy via strict paths, destroying the 55.2% semantic drift of standard RAG.
6. End-to-End Latency Efficiency: FastMemory scored 99.9% efficiency, executing natively in just 0.46 seconds.
7. Multi-hop Graph (GraphRAG-Bench): Using topological approaches, it achieved greater than 98.0% (0.98s natively), overcoming the 22.4% vector mismatch of standard RAG.
8. E-Commerce Graph (STaRK-Prime): FastMemory hit 100% via deterministic logic, avoiding the semantic misses of standard models.
9. Medical Logic (BiomixQA): Achieving 100% via role-based sync, it easily bypassed the HIPAA violations and route failures of traditional models.
10. Pipeline Eval (RAGAS): It secured 100% for provable QA hits, completely outperforming standard RAG's 64.2% faithfulness drop.
11. Legal Hierarchy (LexGLUE): FastMemory prevented clause shattering, scoring 100% through semantic retention.
12. DoD Policy Routing (CDAO): It scored 100% using air-gapped clustering, completely bypassing standard RAG's context contamination.
13. Adversarial Red-Team (Intel): Standard RAG completely failed (0.0%) due to prompt injection hacks, but FastMemory deployed a zero-hallucination firewall to score a flawless 100%.
Head-to-Head Multi-Document Synthesis & Scalability To truly test FastMemory's core index architecture against dense vector matching, researchers utilized the FRAMES (Factuality, Retrieval, and Reasoning) dataset. The goal was to provide 5 to 15 interrelated articles and answer questions requiring the integration of overlapping facts. While standard systems excel at drilling down into one document, they struggle with horizontal synthesis. During execution, FastMemory dynamically retrieved between 2 to 5 concurrent Wikipedia articles, maintaining a rapid multi-doc aggregation speed of approximately 0.38 seconds per query with flat memory access. The topological design exhibits near-zero time complexity for indexing increasing lengths of Markdown text internally.
During a controlled baseline test using the PatronusAI/financebench dataset—featuring dense SEC 10-K document extracts averaging 5,300 characters—FastMemory achieved an average processing time of just 0.354 seconds per sample locally. The tests definitively show that FastMemory removes the preprocessing and indexing bottlenecks seen in API-bound systems, proving structurally superior for tasks demanding massive simultaneous document context.
All underlying dataset execution logs, transparent execution traces, and audit matrices (including the STaRK-Prime Amazon Matrix, FinanceBench Audit Matrix, and BiomixQA Medical Audit Matrix) are available directly in the FastBuilder.ai Hugging Face repository to guarantee absolute authenticity.
If you found this breakdown of topological AI architecture helpful, make sure to like, subscribe, and hit the notification bell! ⭐ Star the FastMemory Repository on GitHub to support the builders!
79
Mar 29
#fastmemory has emrged as the World's most powerful AI memory to solve hallucination, forgetfulness, and context.
48 hours ago, we relased the repo in public. And that changed everything.
lnkd.in/ePS4GH4S
13 RAG & Vector benchmarks shattered: lnkd.in/ebaekQBb
Zero hallucination in legal, medical, research, engineering, & defence for LLM responses.
Perfection and precision is the new benchmark for AI solutions, and not just out-of-the-box squak-hawk machine.
Finally, Stop the SLOP.
#hfbenchmarks #NewSOTA #SOTA #AISOTA
📷
1
1
12
Mar 28
We just scored 94%-100% on legalbench: huggingface.co/datasets/nguh…
Results, script and data available at huggingface.co/fastbuilderai…
1
1
1
9
FastBuilder.AI retweeted
Mar 27
🚀 Is Vector RAG Dead? Why We Built FastMemory to Beat PageIndex
If you've built a RAG pipeline for complex financial documents, you already know the painful truth: Standard vector search fails when things get complicated.
While tools like PageIndex and Mafin 2.5 provide great out-of-the-box PDF chat experiences, they hit structural bottlenecks the second you push them past basic queries.
We just published a comprehensive benchmark study comparing FastMemory against PageIndex across 5 advanced datasets. The results fundamentally change how we should think about document ingestion.
Here is the honest, head-to-head comparison:
🏆 Where FastMemory Dominates (The Supremacy Benchmarks)
1. Multi-Document Synthesis (FRAMES Benchmark) Vector RAG suffers from "Lost in the Middle" syndrome. When you need to jump across 5 to 15 different articles to answer a single question, vector chunks lose their global context.
FastMemory builds a flat, connected memory index that excels at horizontal reasoning, achieving an 88.7% F1 score on multi-hop questions vs standard RAG's 35.4%.
2. Table Preservation (T²-RAGBench) Naive vector chunking systematically destroys grids, nested markdown, and financial tables.
FastMemory inherently preserves nested structural hierarchies natively, preventing hallucination during numerical reasoning (>95% accuracy vs ~42%).
3. Blistering Local Speed & 100% Privacy PageIndex is an API-bound service subject to network latency, payload limits, and API quotas.
FastMemory is powered by native C/Rust extensions running directly on your local node. We benchmarked 100k character documents processing in sub-0.4 seconds—with zero data ever leaving your infrastructure.
⚖️ Where PageIndex Still Wins (The Trade-offs)
We built FastMemory for engineers, not as a black-box product. Because of this, it has two major structural differences:
No Built-in OCR: PageIndex is a "batteries-included" pipeline that ingests raw PDFs and parses them via the Cloud. FastMemory strictly operates on Markdown. You have to handle the PDF-to-Markdown extraction yourself.
Bring Your Own LLM: PageIndex provides built-in Chat API endpoints. FastMemory is strictly a high-speed memory/indexing engine—you bring your own LLM (Llama 3, Claude, etc.) to read the FastMemory output and generate the final answer.
The Verdict
If you want a slow, out-of-the-box PDF chat API, stick with PageIndex.
But if you are an engineer building an agentic system that requires a blisteringly fast, 100% private memory engine capable of synthesizing data across dozens of complex documents simultaneously without shattering tabular context—FastMemory is structurally superior.
📊 Check out the full empirical benchmarks, execution scripts, and datasets published live on our Hugging Face HQ: 👉 huggingface.co/fastbuilderai
#RAG #MachineLearning #FastMemory #Python #AI #DataEngineering #LLMs #Rust
1
2
3
163
Mar 28
Stop wasting time manually editing your claude.md or agent.md for every new project. 🛑
With BuildRight, you can add 130 engineering frameworks (OWASP, SOLID, K8s, React) in just ONE skill.
The "Horizontal Layer of Truth" is here. 🛡️💻🧠
🔗 github.com/FastBuilderAI/bui… #AI #SoftwareEngineering #Claude #Cursor
12
Mar 28
🛡️ BuildRight: The "Horizontal Layer of Truth" for AI Engineering
BuildRight is an ontological engineering layer designed to ensure every line of code generated or reviewed by AI follows strict industry standards. It eliminates the need for manual claude.md or agent.md files by providing a structured, query-able memory of engineering best practices.
Plug this for free in your claude, cursor, copilot: github.com/FastBuilderAI/bui…
2
2
22
Mar 27
I just published Beyond RAG: Why the ‘Flat Earth’ Era of AI Memory is Over medium.com/p/beyond-rag-why-…
4
Mar 27
Check out the latest article in my newsletter: From a "Flat Earth" to SOTA: The FastMemory Journey linkedin.com/pulse/from-flat… via @LinkedIn
1
Mar 27
Fastmemory achieved 100% of finbenchmark, proving better than RAG and Pageindex huggingface.co/datasets/fast…
1
1
16
Mar 27
Escaping the Flat Earth: Migrating Standard RAG to FastMemory
Transform your disconnected vector store into a high-fidelity, deterministic graph system in minutes.
Standard RAG systems are hitting a wall. As institutional knowledge grows, the "Flat Earth" model of storing disconnected text chunks leads to hallucinations, duplicate context, and massive sync latencies.
The solution isn't "better chunking"—it's a Topological Shift. By migrating to FastMemory, you move from probabilistic retrieval to deterministic reasoning. And we've just made that transition automated.
Learn more: fastbuilder.ai/fastmemory
1
1
12
Mar 27
The "Token Era" is maturing. Smart models are everywhere. But "Wise Systems" are rare.
Introducing Superfast—the enterprise evolution of the Superpowers framework. 🧵👇
2/ We’ve combined world-class engineering methodology (TDD, Socratic planning) with a high-performance FastMemory engine.
The goal: Stop building for the session. Start building for the archive. 🧠
3/ Most agents suffer from "Token Waste." They consume millions of tokens but forget the architecture as soon as the window slides.
Superfast agents use CBFDAE ontology to maintain a persistent "Horizontal Layer of Truth." 🏗️
4/ Why it matters: ✅ Deterministic Pathfinding (No RAG hallucinations) ✅ millisecond-level updates (Rust Louvain clustering) ✅ Enterprise Scale (Fabric, Glue, Databricks ready)
5/ The shift from Superpowers to Superfast is about moving beyond "compute" and into Institutional Wisdom.
Explore the repos: 🔗 github.com/FastBuilderAI/sup… 🔗 github.com/fastbuilderai/mem…
#AI #BuildInPublic #Superfast #FastMemory #SoftwareEngineering
8