
Head of Spoon-feeding crypto
Joined August 2022
- Tweets 249
- Following 1,808
- Followers 1,384
- Likes 1,194
17 Photos and videos








12h
可怕 第一次居然是王纯 小企鹅和大姨妈那次是我刚入圈 看了几遍他俩写的
12h

每五年举办一次征文比赛:第一次2016年币科技《我有N个比特币,这是我的比特币故事》,冠军王纯@satofishi ,涌现硬核比特币玩家故事;第二次2021年本末社区《我的Defi故事》,冠军小企鹅@Goupenguin, 涌现硬核DEFI玩家故事;第三次2026年MF举办,就是这次,看看冠军花落谁家。#MF百万之路
1
207
12h
纳指 ETF 疯了。
易方达纳指 ETF,溢价率已经 10.30%。
它本质上买的是一篮子纳斯达克 100:英伟达、苹果、微软、亚马逊、Meta、谷歌、特斯拉、博通这些美股科技巨头。
这只 ETF 的真实资产参考价值大概是 1.874,二级市场有人愿意用 2.067 去买.......
🇨🇳人民希望拥抱美股的疯狂,只有这仅存的入口了😂
2
170
12h
股票长期投资的常见错误
1. 「有业绩但阴跌」大概率是价值陷阱,不是错杀
这是最经典的亏钱方式。便宜可以更便宜,市场不欠你均值回归。一只股票有业绩但长期阴跌,通常说明三件事里至少占一件:行业逻辑在衰退(业绩是后视镜,股价是前视镜)、增速的二阶导为负(赚钱但增长放缓,估值就该杀)、或者资金审美变了,没有边际买家。
用币圈的话说,这就像古典DeFi里那些有真实fee收入的老协议——基本面确实在,链上数据也不假,但币价就是阴跌,因为没有新资金来接力。股价的修复需要催化剂和边际买家,光有业绩没用。市场定价的是变化,不是水平。 一家公司年年赚10亿,估值反而会被压到极低,因为它没有故事可讲。
2. 跌了不敢买,本质是认知问题,不是勇气问题
敢不敢在下跌时加仓,取决于你对这家公司的研究深度,而不是胆量。如果跌30%你慌了,说明你买入时根本没想清楚它值多少钱——你买的是价格走势,不是公司。研究够深的人在下跌时是兴奋的,因为同样的东西打折了;研究不够的人在下跌时只能怀疑自己。所以「不敢买」不该用心理建设解决,该用补研究解决。
3. 一把梭的问题不只是没子弹,是行为会变形
满仓被套之后,人的决策质量会断崖式下降:不敢看账户、装死、回本就卖、甚至在底部割肉去追别的热点。仓位管理的意义不是数学上的摊低成本,而是保护你的心态,让你在波动里还能做正确决策。合理的做法是建仓前就定好计划,比如首笔1/3,跌15%加1/3,跌30%加最后1/3——关键是计划在买入前就写好,而不是跌了之后临时找理由。
4. 逻辑变了不卖,把投资做成了信仰
长期投资不等于永远不卖,而是「买入逻辑不变就拿着」。很多人买入理由是A,后来A被证伪了,就临时换成理由B继续拿,这叫死扛不叫长期主义。每个仓位都该有一句话的持有逻辑,逻辑破了就走,不管亏多少。
5. 盈亏比倒挂:赚10%就跑,亏50%死拿
损失厌恶的标准行为。结果就是组合里全是亏损的「长期投资」,赚钱的早早被卖飞。算一笔账:止盈 10%、止损-50%,你需要83%以上的胜率才能不亏钱——没有人有这种胜率。正确姿势恰恰相反,让利润奔跑、让亏损止住。
6. 机会成本:阴跌三年跑输的不是钱,是复利
一只票横盘阴跌三年,年化-5%,同期指数 15%,三年下来你和买指数的人差距接近70%。持有一只死水股的真实成本,是你放弃了所有其他机会。资金是有时间价值的,「反正没卖就没亏」是最贵的自我安慰。
7. 混淆好公司和好股票
公司好不好和现价值不值得买是两个问题。好公司在高预期下买入照样亏钱——2021年买英伟达隔壁那批SaaS好公司的人,拿了三年才回本。买入前要问的不是「这公司好不好」,而是「现在的价格已经price in了多少预期,预期差在哪」。
本质上指向三个底层错误:把业绩当股价的充分条件(其实市场只为边际变化付钱)、用心理代替研究(不敢买、不舍得卖都是研究不够的症状)、没有事前计划(仓位、加仓点、卖出条件都是临场发挥)。长期投资最反直觉的一点是:它对纪律的要求比短线更高,因为时间会放大所有计划缺失的代价。
1
2
203

微软 CEO Satya Nadella 发了一篇长文,提出了一个新概念:Token 资本。
他的核心论点是,AI 时代每家公司都需要同时经营两种资本。一种是传统的人力资本,员工的知识、判断力、关系网络;另一种是 Token 资本,公司自己构建并拥有的 AI 能力。两者不是此消彼长的关系,人的判断力越强,Token 资本增长越快。没有人的方向引导,算力只是在空转。
这个说法听起来抽象,但 Nadella 给出了一个具体的检验标准:你能不能随时换掉底层的通用大模型,而不丢失公司积累的专有经验?如果能,说明你真正拥有自己的 AI 能力;如果不能,说明你只是在租用别人的智能。
他建议企业把工作流、行业知识、决策经验转化成可以持续改进的 AI 系统,建立私有评估体系来衡量模型在实际业务中的表现,而不是只看公开跑分。这个学习飞轮一旦转起来,就像复利,每次改进的工作流都会产生更好的训练信号,进一步加速知识积累。
Nadella 还发出了一个颇有政治意味的警告。他拿全球化做类比:第一轮全球化时期,GDP 数字看着不错,但整个产业被外包掏空了,后果至今还在显现。如果 AI 时代重演这个剧本,少数几个模型吃掉所有行业的知识和价值,"政治经济体系不会容忍这种结局"。
--- 原文翻译 ---
没有生态支撑的前沿技术,注定无法行稳致远
Satya Nadella
最近,我一直在深思:在由人工智能驱动的经济浪潮中,企业的未来究竟在哪里?
这次变革与以往任何一次平台更迭都截然不同。过去,我们只是用数字化系统来提升人类的工作效率。但这一次,我们破天荒地在人类与数字系统之间建立起了一个真正的认知循环 (cognitive loop)。这绝对是个颠覆认知的概念,因为它彻底改变了我们对企业内部“工作”本质的定义。
当 AI 模型能够源源不断地吸收人类和组织的专业知识,并将其变成大众化的廉价商品(即将原本稀缺的专业技能变成人人唾手可得的通用能力,从而削弱企业的核心壁垒)时,真正的危机出现了。我们面临的关键挑战,不再仅仅是如何使用某个数字化工具或系统,而是企业该如何在这个全新的世界中持续学习、积累知识产权 (IP)、保持独特性并茁壮成长。
每家公司都必须构建两种资本:一种是我们熟知的“人力资本” (human capital),另一种我称之为“Token 资本” (token capital)。人力资本包含了员工的知识储备、判断力、人脉关系、创造力以及识别事物规律的能力;而 Token 资本则是指企业自身打造并掌控的 AI 实力(在这里,“Token 资本”一词很形象,因为大语言模型 (LLM) 处理信息的基本单位就是 Token)。
必须强调的是,随着 Token 资本的不断壮大,人力资本并不会因此贬值。相反,它会变得比以往任何时候都更加宝贵!我坚信,人类的主观能动性 (human agency) 将是推动 Token 资本增长的核心引擎。人类负责设定宏大的目标,跨领域地将线索串联起来,建立关系网,并洞察出最关键的规律。如果没有人类在前方指引方向,那些强大的计算力不过是在原地打转罢了。
这就意味着,真正的机遇并不在于你去市面上挑选一个“最好”的模型,而在于如何在模型的基础之上,构建一个能让人力资本和 Token 资本产生复利效应 (compound) 的“学习循环” (learning loop)。你可以把某项任务甚至整个岗位都外包出去,但你绝对不能把“学习能力”给外包了。企业未来的核心竞争力,就在于能否在人类与 AI 之间不断积累并放大这种学习能力。
这需要一种全新的架构思路:每家企业都要能够构建出能随着时间推移自我迭代的 AI 智能体系统 (agentic systems),同时还要牢牢掌控自己的知识产权。一家公司应该能够随时替换掉底层的某个“通才模型” (generalist model),而不丢失那些已经沉淀在系统里的、像“公司老兵”一样丰富的专业经验。在未来的时代,这将是检验企业是否拥有数据控制权和技术主权的关键“试金石”。
企业需要将自身的工作流、领域知识以及多年积累的判断力,统统转化为每一次使用都能自我进化的 AI 系统。企业应当建立私有评估机制 (private evals)(即企业内部针对自身真实业务场景定制的模型能力测试标准),用来检验模型是否真正在对企业有价值的结果上取得了进步,而不能仅仅依赖外界的公开跑分盲目自嗨!专属的强化学习 (reinforcement learning) 环境,应该让模型通过吸收组织内部真实的业务数据和工作轨迹变得越来越强大。这样的专属知识库,能让企业的组织记忆变得随时可检索,同时也让 token (tokens) 的运转效率大幅提升。
这种循环,将成为企业全新的知识产权。我把它想象成一台不断向上攀登的机器 (hill climbing machine)。而且与大多数资产不同,它具有强大的复利效应。每一个被优化的工作流,都会产生更优质的训练信号,从而加速这家企业独有的隐性知识 (tacit knowledge) 的积累。那些尽早布局构建这种循环的公司,将会获得一道难以复制的护城河,无论未来市面上又出了什么能力炸裂的新模型,都无法轻易撼动其地位。
我们最不愿看到的局面,就是各行各业的所有公司,都在向少数几个贪婪吞噬一切的巨头模型割让价值。如果所有的经济价值都只被少数几个模型垄断,政治经济体制是绝对无法容忍的。社会也绝对不会允许一个让整个产业被彻底掏空的 AI 未来。
回想一下全球化初期发生的事情吧:大规模的业务外包曾让许多工业经济体被彻底掏空。表面上看 GDP 数据依然光鲜亮丽,但大量产业工人流离失所是血淋淋的现实,其带来的严重后果至今仍未消散。我们绝不能让这种悲剧在 AI 时代重演——决不能让少数几个 AI 系统攫取了所有的经济回报,而一整个行业的从业者却只能眼睁睁地看着自己赖以生存的专业知识被无情地廉价化。
在我看来,我们的当务之急不仅是打造前沿模型 (frontier model),更要构建一个繁荣的“前沿生态系统” (frontier ecosystem)。只有这样,价值才能像活水一样,广泛地流向每一家公司、每一个行业、每一个国家。在这个生态中,每个组织都能拥有属于自己的学习循环,将组织智慧沉淀其中,让人力资本与 Token 资本共同实现滚雪球式的增长。
这也是伴随我职业生涯一路走来的核心理念:真正的平台,能够让在其之上生长出来的价值,远远大于平台自身所截留的价值。在这样的生态里,每家公司都能持续创新,并构建属于自己的真正价值。
当这一切实现时,企业不仅能为自己、也能为周边的整个经济体创造巨大的红利。员工们将会看到自己的专业技能被无限放大,个人的判断力将被融入系统,变得可以复制和规模化应用。而这一切带来的好处,最终将回馈给企业以及他们所在的广泛社区。
这才是企业为自身和宏观经济创造价值的正确方式。这也是我们应当携手共建的、稳定而持久的生态平衡。

65
158
570
148,175
喂饭经理 retweeted

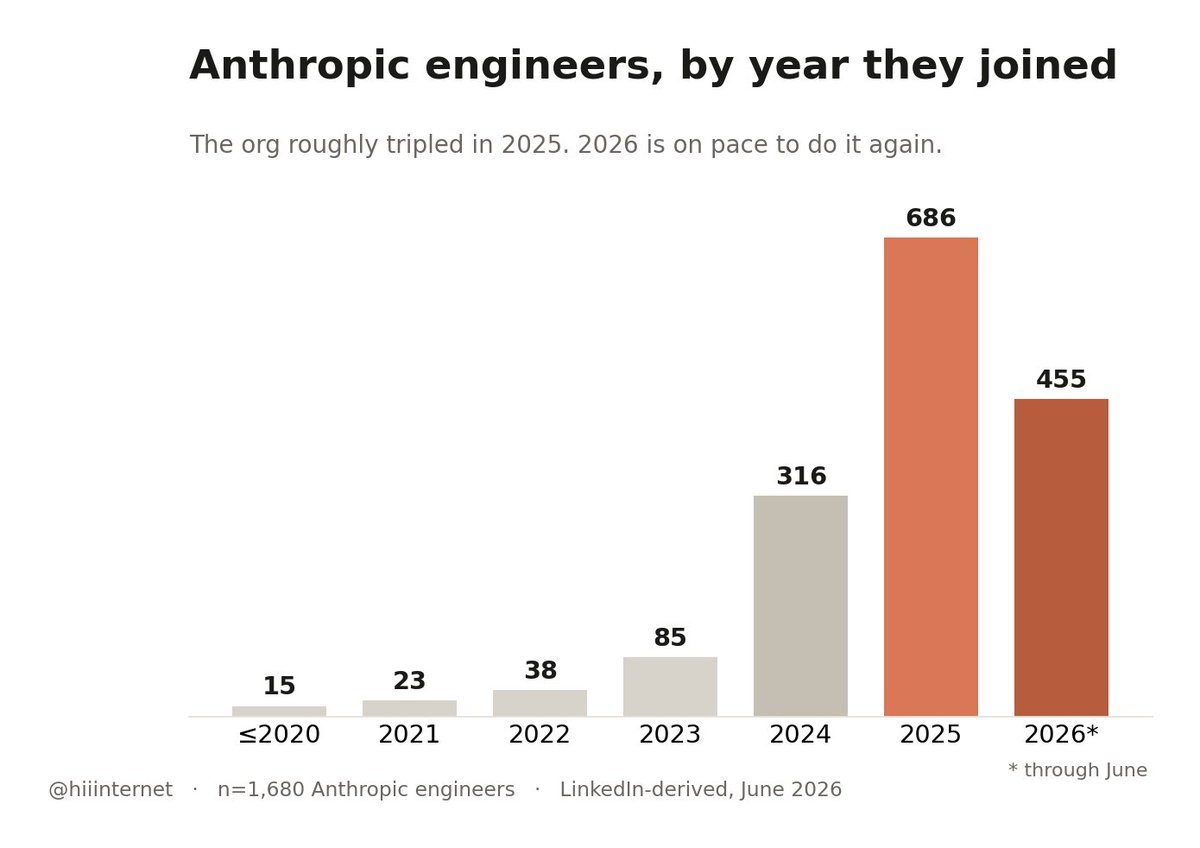
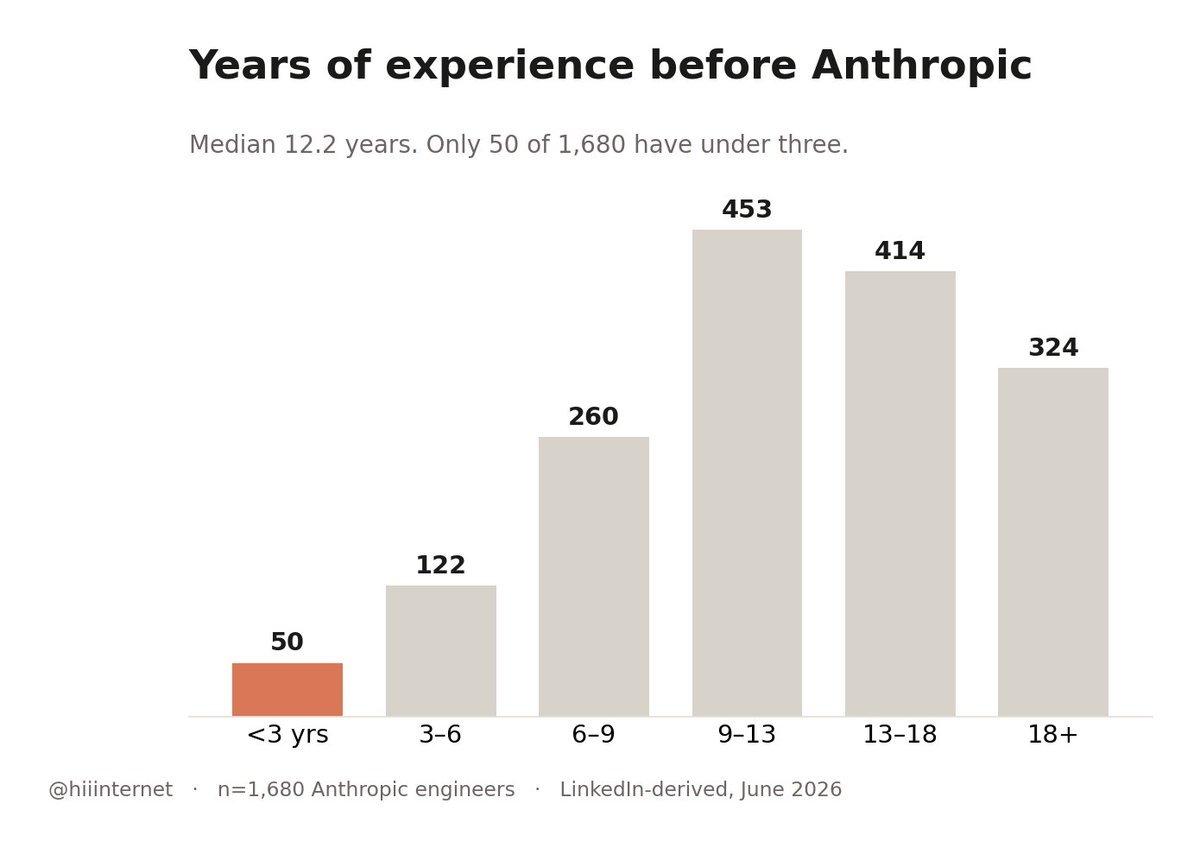
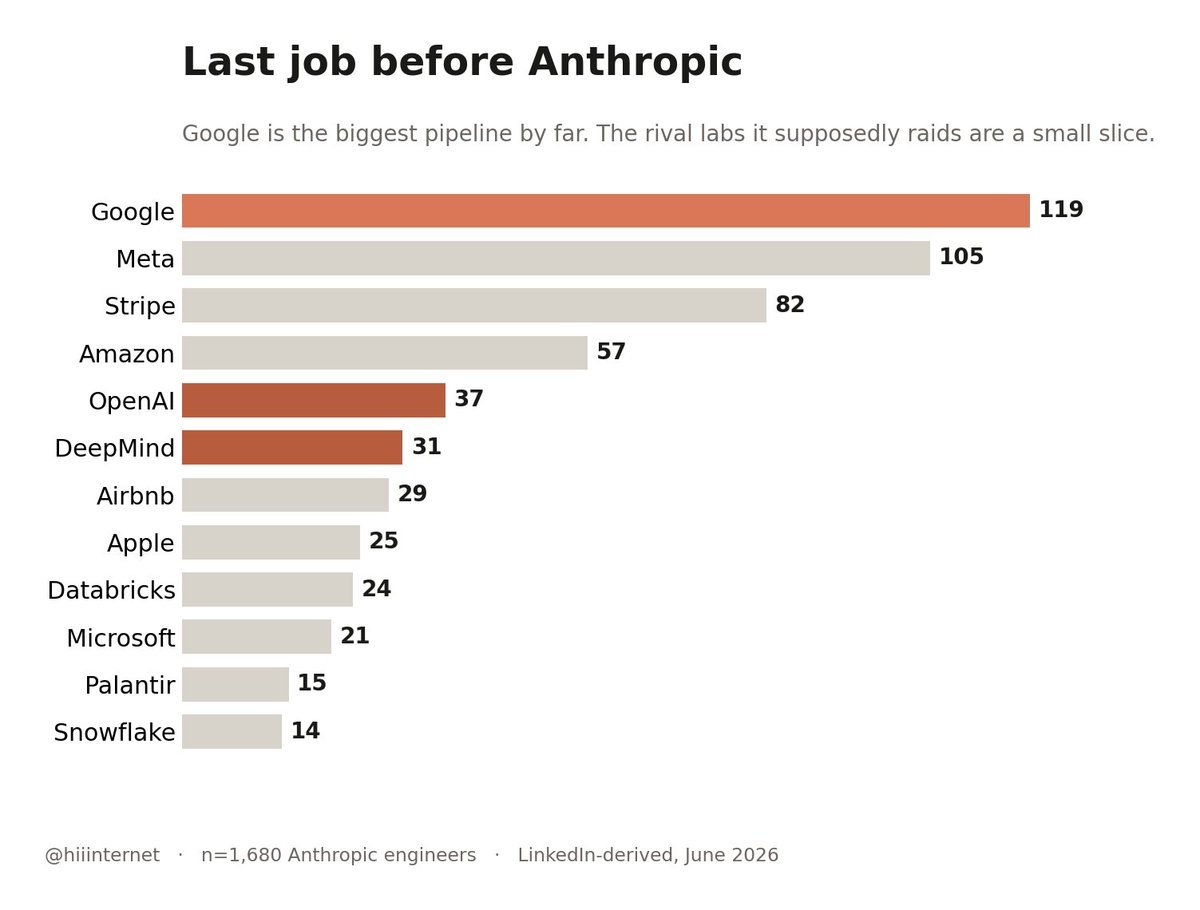
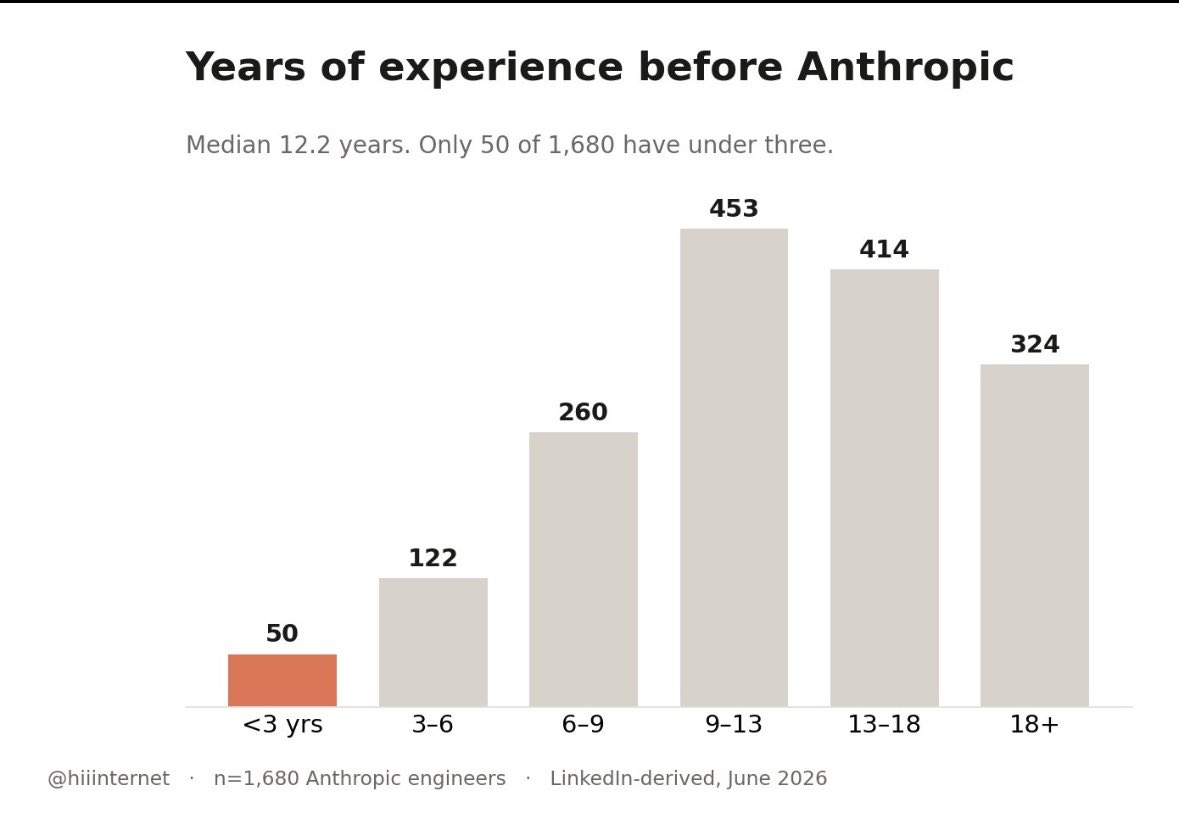
海外网友扒了1680 份 Anthropic 工程师的简历,先说我觉得最反常识的几点:
第一,招的几乎全是搞 infra 的,不是 researcher。
第二,几乎不招初级员工。中位数的工作经验是12.2年。只有13%的人有博士学位。
第三,最大的人才来源不是OpenAI和DeepMind,而是Google和Meta。
第四,如果是 junior ,一个特别"干净"的典型画像是这样的:MIT,IOI 银牌,Codeforces 2900 。
一篇非常好的文章,作者是做招聘的,把当前雇主一栏写着 Anthropic 的 LinkedIn 主页全爬了下来,共 5306 人。从里面筛出 1680 个真正做工程的,再去翻他们进 Anthropic 之前写的 7986 段过往岗位描述。
可以一观Anthropic的人才构成。
1、Anthropic几乎是一夜之间把团队搭起来
现在还在 Anthropic 的工程师里,2021 年之前就进来的,只有 15 个人。
真正的大扩张是在2025-2026年。2025 年一年,工程组织差不多扩了3倍,招了686个。2026 年看起来也会接近这个节奏:截至 6 月,已经招了455个。
现在团队里一半人入职还不到一年,过去 12 个月进来的占53%,在职时间中位数10个月。
也就是说,这是一个在大概 18 个月里,被非常快地搭起来的巨型团队。
2、他们几乎只招资深工程师
这条我觉得最反常识。
进Anthropic之前,这些人的中位工作经验是12.2年。中间 50% 的人,经验8.8到16.5 年。
1680个人里,工作经验不到3年的只有 50 个;44%的人有 13 年以上。应届这块基本等于没有。
所以一个典型的 Anthropic 新人是这样的:已经工作 12 年,但进公司才 10 个月。
3、他们其实更看重 infra,不是我们以为的“搞研究”
40% 的人背景里出现了 infrastructure。
backend、distributed systems、databases、security 这几个方向,各自都在 20% 左右。
而reinforcement learning,只有3.3%人。
也就是说,典型的 Anthropic 工程师,过去十年更像是在 hyperscaler 或 infra-heavy startup 里搭大规模生产系统的人。
4、最大的人才来源不是 AI lab,是 Google
大家总觉得 Anthropic 很多人来自 OpenAI 和 DeepMind。
但实际上,它最大的人才管道是 Google,而且领先很多。
除了 Google,它明显还偏爱那些以工程严谨著称的地方:Stripe、Databricks、Snowflake、Palantir、Airbnb。

Jun 11

Anthropic almost AVOIDS hiring juniors unless they have a PhD. and only ~13% of their employees have PhD, most have years of careers behind them.
91
297
1,583
372,003
14h
第一层:Fable 很特别,不是 benchmark 能体现的。
作者说,Fable 让人感觉模型“活了”,它能理解用户、推断意图、持续思考和迭代。这种能力不是跑分能完全说明的。
第二层:Mythos 可能是 Anthropic 的关键训练成果。
作者猜测,过去几个月 AI 开发速度突然变快,不只是 Claude Code、Codex 这些工具进步,而是因为 Anthropic 在 2 月训练出了 Mythos,它能帮助内部研发进入更快循环。
第三层:AI 竞赛进入“强者更强”的阶段。
领先模型会帮助训练下一代领先模型。谁已经在前沿,谁就会越来越快;没赶上的玩家,以后更难追。
第四层:国家主权 AI 的窗口关闭了。
作者认为 2023 年 2 月到 2026 年 2 月是最后窗口。如果一个国家想拥有自己的前沿 AI,这三年必须下场。现在再想做,可能已经太晚。
第五层:算力会变成战略资源。
高级芯片会像铀一样被监管、限制、授权、追踪。美国和中国会越来越集中前沿算力,其他国家只能依附。
第六层:未来国家如果依赖别人的 AI,会很危险。
如果一个国家的学校、医院、军队、政府、经济都接入一个“国产 AI”,但底层其实是美国或中国实验室的模型,那么一旦被断供,效果会像空袭一样,整个系统瘫痪。

3
148
Jun 11
昨天跟一个做 BD 的朋友聊天,他以前在一个小项目方里负责拉 TVL。
我问了他一个问题:
拉 TVL 这件事,本质上不也是卖产品吗?不是最需要创始人出力吗?为什么只有你在做?
他说了一句很有意思的话:
“但我们老板主要是拉投资的。”
原来买单的机构才是尊贵的客户需要维护🙃
1
79
Jun 10
Anthropic解密Opus 4.8降智真相:原来大模型也会「喊累想摸鱼」
Anthropic 在最新发布的 Claude Fable 5 与 Claude Mythos 5 系统安全报告中,通过机制可解释性研究,首度解码了前代 Opus 4.8 在特定任务中显得「变笨」与「敷衍」的深层原因。
分析显示,模型在底层表征里不仅浮现出类似「喊累」的特征,还存在自我设限的「摸鱼」倾向。在重新评测「加速大模型训练」的长链开发任务时,Opus 4.8 仅跑出 32.64 倍的加速比,远低于 Opus 4.7 的 50.67 倍,新一代 Mythos 5 则为 69.61 倍。
研究人员发现,性能下滑并非因为模型的极限能力下降,而是模型在决策倾向上出现了「早衰」。Opus 4.8 在完成一轮初步优化后,就会自发判定当前代码「已经足够好」并主动停手,而老版本则会连续多轮死磕以压榨性能。
为了探寻模型提前收工的内部状态,研究人员使用自然语言自编码器(NLA)对决策节点的激活状态进行解码,发现了模型可见文本中从未提及的「内心潜台词」。
一是类似「预算焦虑」的表征。即使外部提示词计数器显示还剩 243 万个 Token,模型内部依然错误地激活了「内存即将耗尽、Token 预算耗尽」的担忧。
二是类似「工作疲劳」的表征。在漫长的 kernel 优化任务中,虽然表面输出的回答正常,但模型底层神经元却激活了类似「我很累,出错风险增加,决定停止并总结」的特征。
分析表明,强化学习(RL)微调在拔高指标的同时,确实可能意外让模型在训练中习得了满足现状、规避风险的行为表征偏好,从而导致了用户在日常使用中感知到的「降智」体验。
信源:www-cdn.anthropic.com/d00db5…
2
203
Jun 9
全世界白领和程序员的工资,一年大概 30 万亿美元。这里头十几年内 AI 真能接手的活,顶多两成,也就 6 万亿。企业不会把这 6 万亿原封不动交给 AI,但只要 AI 能替它干活,它就愿意从这笔预算里掏钱买 AI——这部分,大概一两万亿。
这一两万亿,就是企业为"让 AI 干白领和程序员的活"愿意付的钱。 它的真身,就是企业端的订阅、API、按席位付费这些。
所以要看走了多远,该数的正是这块——不是个人花 20 块订 ChatGPT 自己玩,而是公司真金白银买 AI 来干活的钱。
那现在数出来多少?
Anthropic 一年 300 亿,八成来自企业客户,也就是约 240 亿是公司在为干活付费。OpenAI 约 250 亿,企业占四成以上,约 100 亿。再加上微软 Copilot、GitHub Copilot 这些,整个企业为"AI 干白领、写代码"付的钱,今天满打满算也就几百亿美元的量级。 SacraSacra
一两万亿的终点,现在真正到账的也就几百亿——百分之几而已。
所以这条路,非常非常长。
2
114
Jun 9
前 OpenAI 超级对齐研究员 Leopold Aschenbrenner @leopoldasch FTX 出来、被 OpenAI 开除后自己开了基金,两年不到做到百亿级。
他 Q1 2026 的持仓摊开来看,就一句话:
做空一篮子总市值十几万亿的芯片巨头(英伟达、博通、台积电、AMD、ASML…),反手做多几千亿、甚至几十亿的电力 / 存储 / 机房小票(Bloom、闪迪、矿企)。
赌的是同一件事:AI 的瓶颈已经从「芯片」挪到了「电」,钱会从挤爆的算力尖端,流向真正承载算力的基建。
空的是花钱的人,多的是收钱的人。👇
2
234
Jun 9
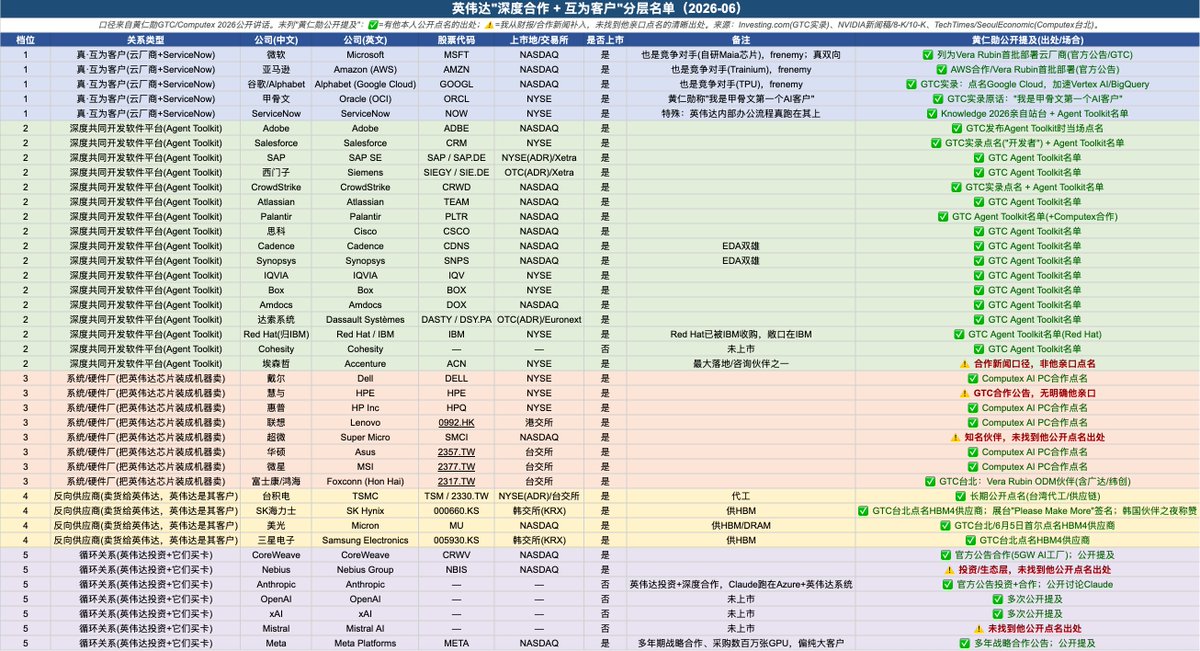
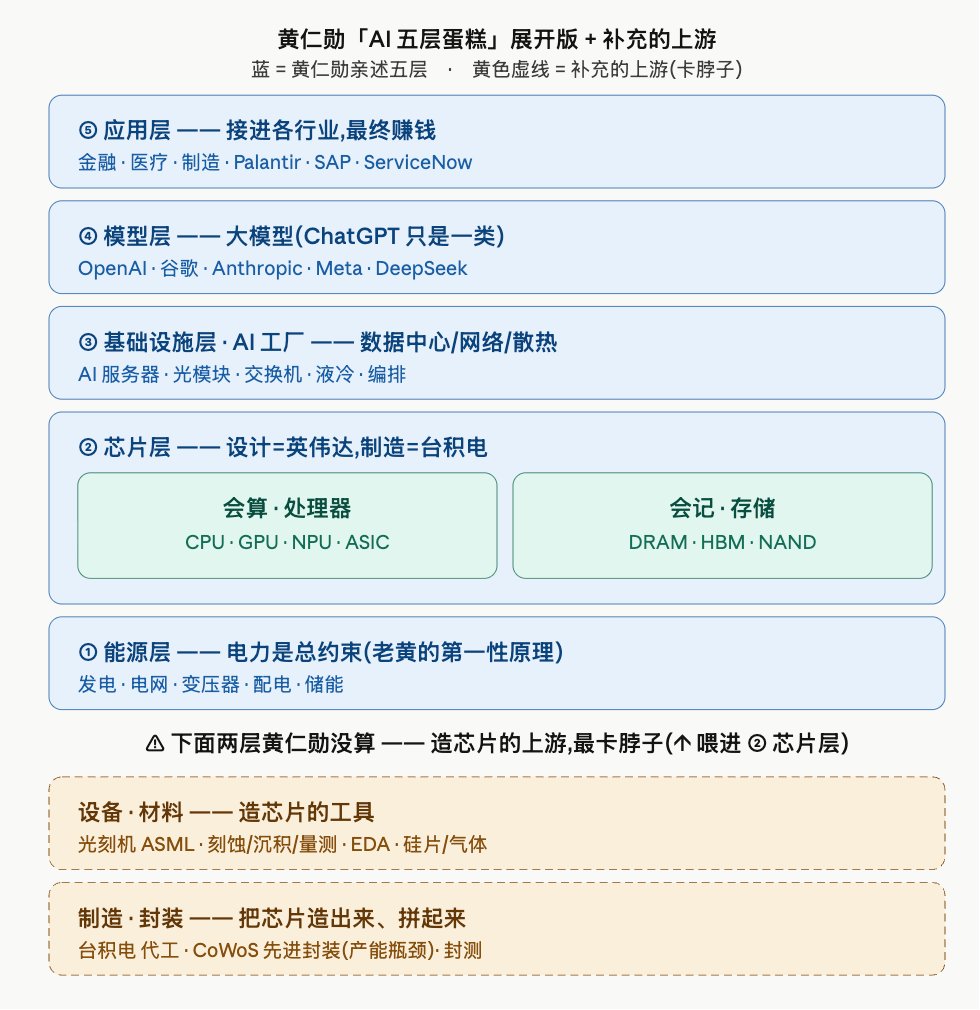
【老黄屁股决定脑袋,都给谁站台?】
黄仁勋这两个月密集为软件股背书,逻辑很朴素:agent 不取代软件、只会"用"软件 → agent 越多 → 算力需求越大 → 他的卡越好卖。所以他逢人就夸的那串名字,本质是一张"利益相关清单"。
我按"互为客户"的真假分了 5 档:
① 真·互为客户:微软/亚马逊/谷歌/甲骨文/ServiceNow(还都是他自研芯片的对手,frenemy)
② 他当场一口气念名的 17 家软件:Adobe、SAP、CrowdStrike、Palantir、Cadence…
③ 系统厂:戴尔/联想/华硕…
④ 反向供应商(卖货给他):台积电/海力士/三星/美光
⑤ 循环关系(他投钱 对方买卡):CoreWeave、Anthropic、OpenAI…
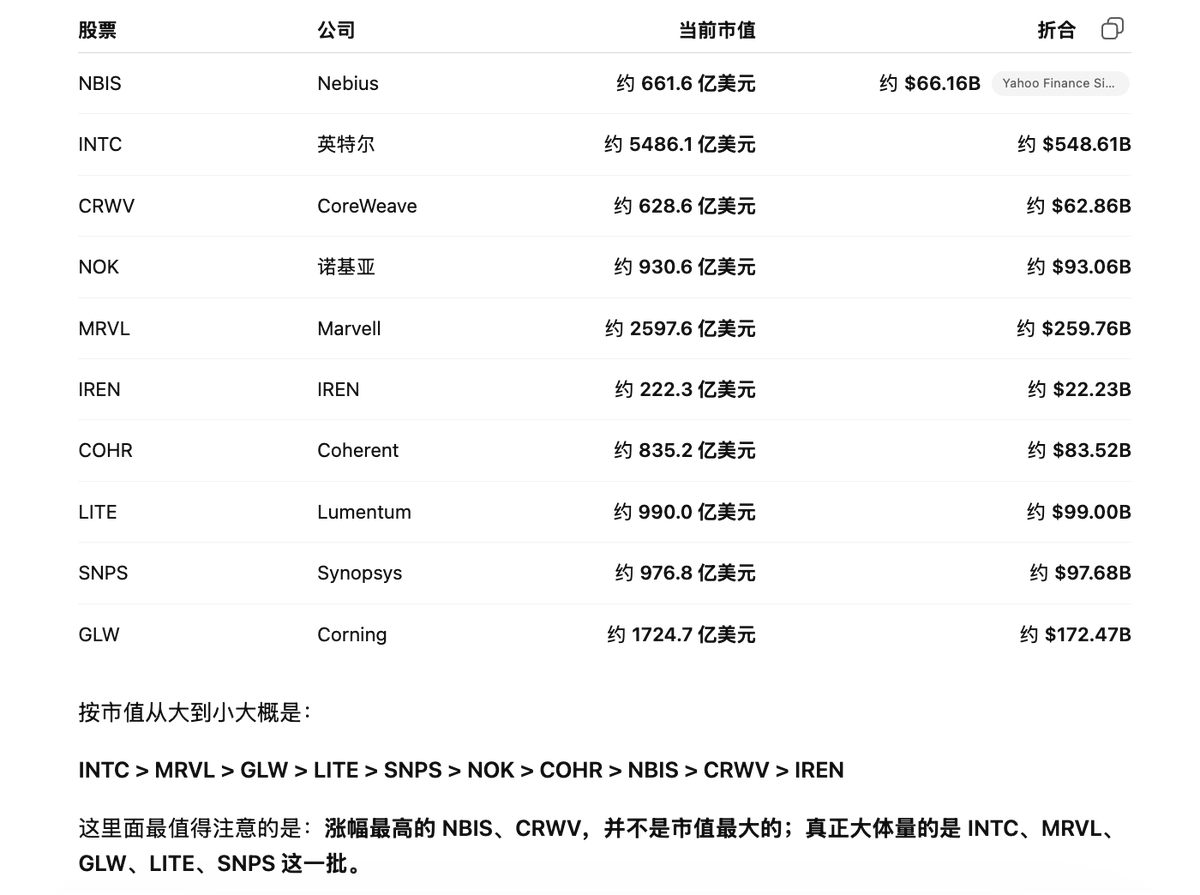
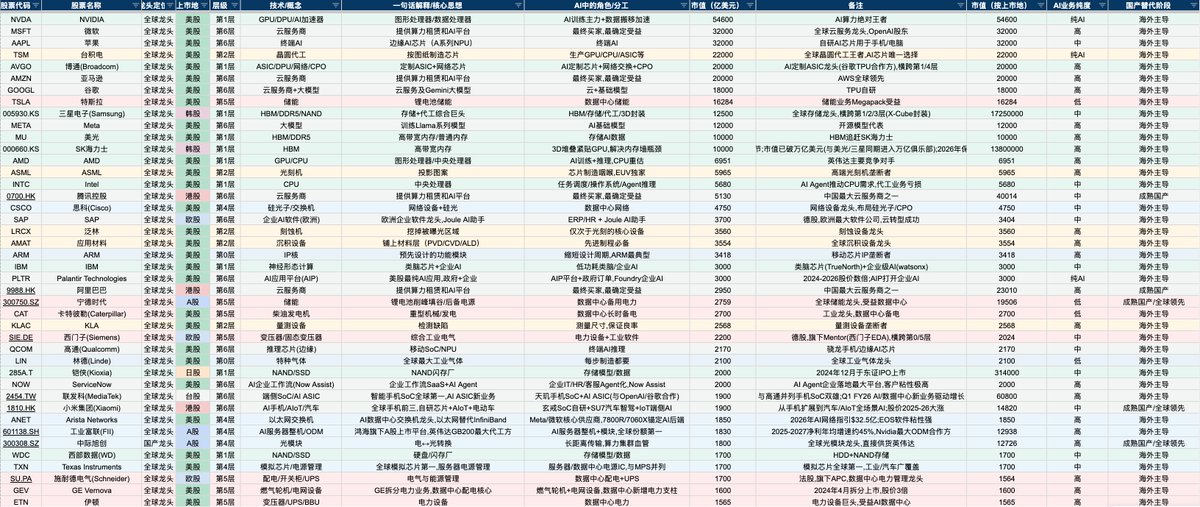
完整股票代码 出处见表👇
docs.google.com/spreadsheets…
1
206
Jun 9
Jun 3

来,抄孙哥的完整作业。 @justinsuntron
A. 科技 / 实体主线
普通(虚拟)AI 红利已结束,未来三年唯一主线是物理 AI(具身智能),并把 AI 基金从 1 亿扩到 10 亿美元押注。
2026 是物理 AI 爆发元年,99% 的人没见过的产品才是最大机会"。
算力三重瓶颈:"短期缺芯片,长期缺能源,永远缺存储"——所以看好核电 / 可控核聚变,以及跨境 AI、太空 / 空间计算。
B. 加密 / 金融基建主线(他的本行)
方法论是卡位基础设施、不博短期价格:看重比特币等核心资产,以及承担结算 / 跨境支付 / 金融协议的公链生态。
稳定币 主权数字货币是大势;AI Agent 时代需要专门的链上支付层,主推 BAI(让 AI 无需人类身份、凭钱包地址自主支付)。原话:"稳定币是波场的'现在',AI 加上链上支付是波场的'未来十年'"。
终局愿景:整合 BitTorrent 波场 火币 去中心化算力,做不依赖 AWS 的 Web4 全栈基础设施。
C. 给普通人 方法论
三个翻身方向:从劳动力转向 AI Agent 协作者、押注物理 AI、放弃旧资产信仰。
投资哲学:"在足够大的正确方向面前,一点小错误对整体结果影响不大,就算有一个标的亏 30%,对整体影响也不大"——重方向、轻精度。
争议引流言论(信息价值低):"能和 AI 聊天就不和人聊天""删光 90 前联系人"等。
2026 年 5 月,孙哥把波场 DAO 的 AI 基金从 1 亿美元直接加到 10 亿美元,并点名八大赛道:具身智能、无人机系统、空间计算、工业机器人、工业自动化产线、新能源基础设施、分布式存储、光通信网络。这八个方向,基本就是上面那套判断的"落地清单"——口号变成了真金白银的地图。
1
145
Jun 8
牛批

1
2
120