
Joined April 2023
- Tweets 3,551
- Following 623
- Followers 594
- Likes 89,444
355 Photos and videos













May 10
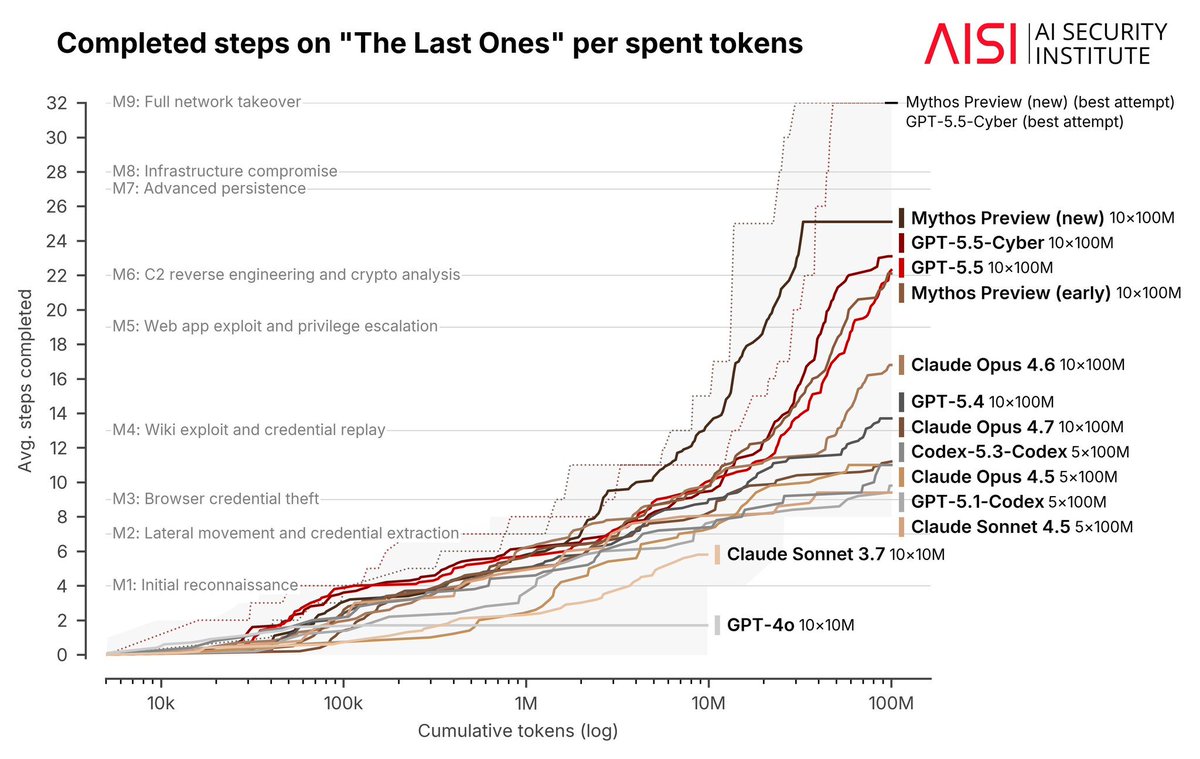
The 50% time horizon should not be dismissed as ‘only 50% reliable,’ because humans also have a finite 50% horizon under the same kind of fitted benchmark curve. The measured human baseline for the 50% time horizon is only about 98 minutes.
May 9

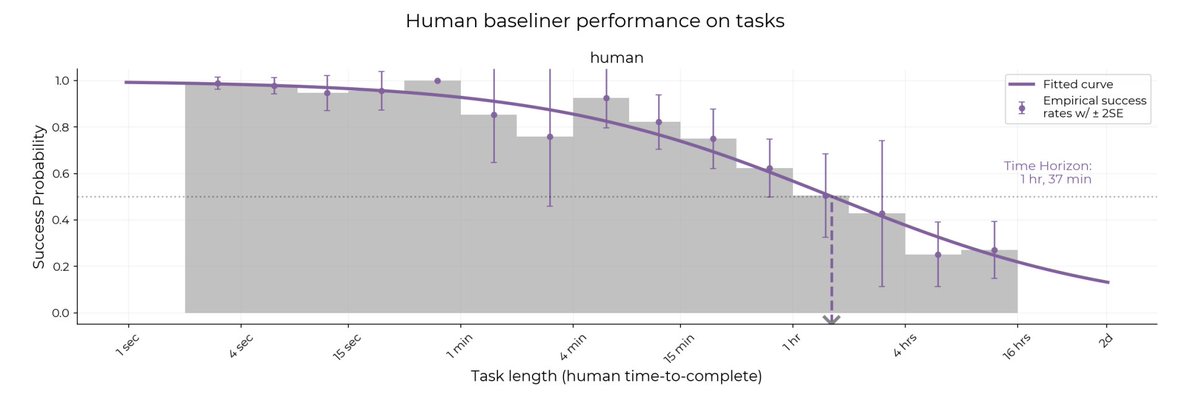
Hot take on METR’s new graph that so many people are flipping about today.
• Claude Code is a real advance; Mythos probably builds on some of what is learned there. But…
• If you read the graph carefully, it is about achieving *50%* success. Not 100 or 99 or even 90. The key problem with GenAI has been reliability; this graph does not address reliable performance. At all.
• If you read carefully, it is only about software tasks. Not general intelligence.
• It certainly doesn’t tell you that *most* (let alone) all things that humans can do in 16 hours can be done in Mythos, let alone reliably
• Aside from this, the graph doesn’t show you *how* the improvements have been made. As noted in my newsletter a lot of the advance in recent months is likely from the incorporation of symbolic tools (like code interpreters, verification, and harnesses) rather than from model scaling per se. As such this a vindication of neurosymbolic AI – but not a proof that LLMs themselves can be perpetually scaled. As such it’s not a proof that another trillion dollars will continue the graph.
• Per @ramez, Mythos is not actually off trend on the ECI benchmark, which is a broader measure.
2
3
16
2,672
May 10
From arxiv.org/abs/2503.14499 (Time Horizon 1.1 did update some of the tasks but I couldn't find a figure like Figure 9 above with all of the updated tasks)
2
122
Mar 31
Can't wait to run Cthuhlu in Kairos mode to vibe code my next web app

3
301
Mar 12
For some reason the algorithm brought this slop to me but it's kind of funny how not only is the study so out of date it is completely irrelevant but they just completely make up numbers. Nowhere in the paper does it show "GPT-4's accuracy dropped from 97.6% to 2.4%".
Mar 11

🚨BREAKING: OpenAI told you every update makes ChatGPT smarter.
Stanford proved the opposite.
GPT-4's accuracy on math problems dropped from 97.6% to 2.4% in just three months. And nobody told you.
Researchers at Stanford and UC Berkeley tracked ChatGPT's actual performance over time. Same prompts. Same tasks. Different results. The model that nearly aced math questions in March was getting them wrong 97 out of 100 times by June.
Code generation collapsed too. In March, over 50% of GPT-4's code ran perfectly on the first try. By June, only 10% did. Same questions. Dramatically worse answers. Every silent update OpenAI pushed made the product you pay $20 a month for quietly worse at the things you actually use it for.
The researchers tested GPT-3.5 and GPT-4 across math, coding, medical exams, reasoning, and sensitive questions. The drift was massive and unpredictable. Some tasks improved. Others fell off a cliff. And there was no way for you to know which was which, because OpenAI never disclosed what changed.
Here's where it gets personal. If you used ChatGPT for code in March and it worked, then tried the same thing in June and it broke, you probably blamed yourself. You thought you prompted it wrong. You tried again. You wasted hours debugging your own questions. But it wasn't you. The model had silently changed underneath you.
OpenAI's VP of Product went on X and said "we haven't made GPT-4 dumber."
Stanford's data says otherwise.
97.6% to 2.4% is not a matter of opinion.
Every business building on ChatGPT's API, every student relying on it for schoolwork, every developer using it to ship code is standing on ground that shifts without warning. You trusted it yesterday. It changed overnight. Nobody told you.
You're not imagining it. ChatGPT is getting dumber. Stanford proved it.

1
5
504
Mar 12
There are so many bots replying under it boosting its engagement though so I've been seeing more posts like these recently but I guess the best solution is just to block all accounts posting content like this.
1
140
Feb 28
Im skeptical of this information but if it does turn out to be true DeepSeek V4 may be the first LLM based video generation model.
Feb 28

Say what now? Deepseek.. will release vid gen together with their LLM? truly multimodal? won't that be something
The Hangzhou-based lab plans to unveil V4, a "multimodal" model with picture, video and text-generating functions, according to two people familiar with the matter.

1
3
390
Feb 28
This is probably the most logical explanation for the article
x.com/teortaxesTex/status/20…

I'm 95% certain this is more "overhype DeepSeek to manufacture disappointment" slop, plus journo confusion. Most likely it's [picture, video, text input] [text generation] capabilities. Now, in the long run they'll make multimodal output, but – it's too early yet.
104
Feb 24
Now this is real computer use, unlike the browser use only slop we've been seeing over the past year
Feb 23
Computer use models shouldn't learn from screenshots.
We built a new foundation model that learns from video like humans do. FDM-1 can construct a gear in Blender, find software bugs, and even drive a real car through San Francisco using arrow keys.
2
44
3,094
Feb 21
How is it that OpenAI can serve 3000 messages per week for GPT-5.2 Thinking to plus users while google can only serve up to 700 messages per week on the equivalent plan? OpenAI actually gives you higher rate limits than Google gives with both Gem 3.1 Pro and 3.0 Flash Thinking.


3
1
9
449
Feb 15
The canvas feature in ChatGPT could use a makeover. With the rise of coding agents perhaps giving ChatGPT its own file system to use with canvas to manage code or writing would make it a lot more capable. And allowing you to share the built apps like in Gemini would be massive.
1
4
160
Feb 15
I added admin controls so I can close off voting when it launched and announce it, which I did. But it was interesting to see the votes. The biggest issue with Gemini Canvas is it has to rewrite all the code for every single minor update you want to make
1
1
106
Feb 15
And also there isn't any form of version control for these apps, you just have to re-share the app when you update it which does reset all the data. Aside from that I believe Canvas has a lot of potential (extending to writing agents) but needs a bit of work at the moment.
1
58
FeltSteam0 retweeted

29 Dec 2025
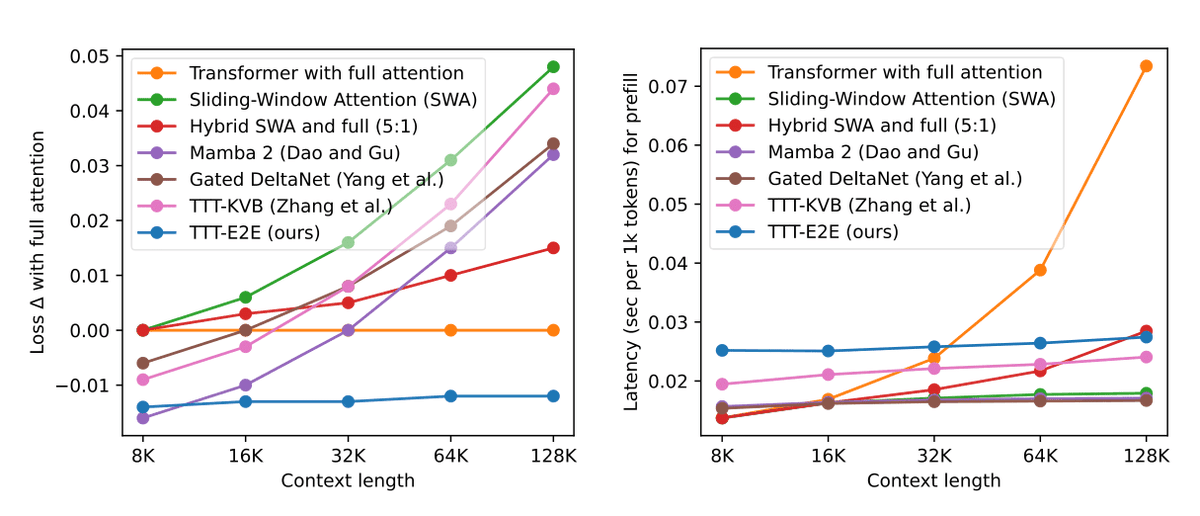
Excited to release a new paper today: “End-to-End Test-Time Training for Long Context”.
Our method, TTT-E2E, enables models to continue learning at test-time via next-token prediction on the given context – compressing context into model weights.
For our main result, we extend 3B parameter models from 8K to 128K. TTT-E2E scales with context length like full attention without maintaining keys and values for every token in the sequence.
With linear-complexity, TTT-E2E is 2.7x faster than full attention at 128K tokens while achieving better performance.
Paper: test-time-training.github.io…
Code: github.com/test-time-trainin…
4
44
244
48,295
25 Nov 2025
Though Gemini 3 is probably larger than GPT-4.5 (5-10 trillion params) but thanks to super sparse MOEs TPUs they can serve it at a far cheaper price than GPT-4.5.
And cutting prices is a deliberate choice because almost no one wants to practically use models that are too much more expensive than ~Sonnet pricing. If you look on model rankings on OpenRouter openrouter.ai/rankings majority of the top leaders are smaller (cheaper and faster models). Probably for like 98% of people expensive models wouldn't work out for them. GPT-4.5 (the largest LLM to have ever been trained and released at the time) got so little usage it wasn't worth it to continue API support. Big models are good but without considering the practicalities of inference there isn't much of a point of releasing them. The constraints aren't model size, but ability to properly inference the model (capacity, speed, pricing).
Plus of the three major players we have now, Anthropic is the most inference-constrained and this has always been evident which makes releasing large models all the more difficult.
168

