
Postdoc #UChicago, ex-#UniversityOfOxford, #Meta,#Google, #FiveAI, #ETHZurich Trustworthy and Privacy-Preserving ML Email: francesco.pinto@eng.ox.ac.uk
Joined January 2022
- Tweets 43
- Following 176
- Followers 50
- Likes 48
10 Photos and videos


Francesco Pinto @ Neurips 2024 retweeted

19 Dec 2024
🚀 Introducing 𝐒𝐚𝐟𝐞𝐖𝐚𝐭𝐜𝐡! 🚀
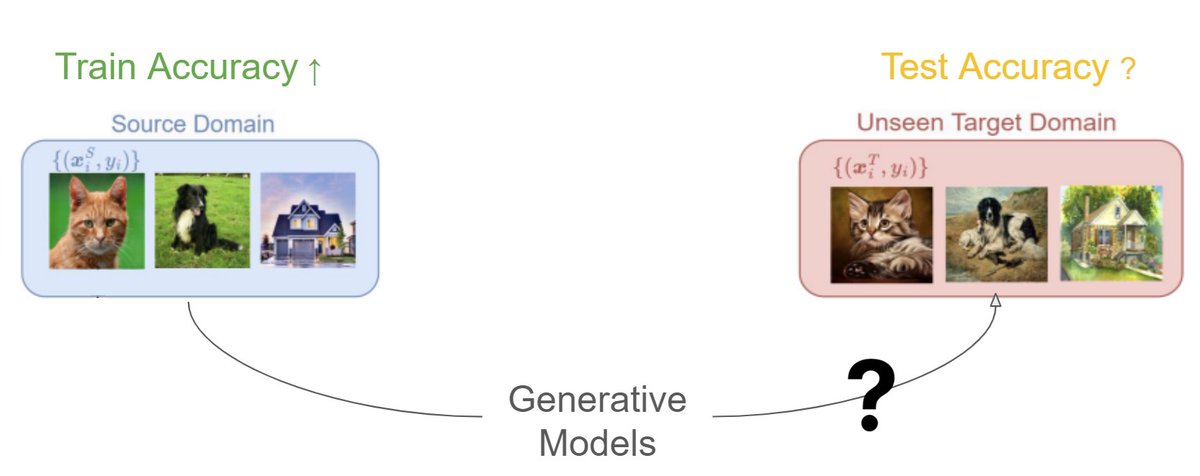
While generative models 👾🎥 like Sora and Veo 2 have shown us some stunning videos recently, they also make it easier to produce harmful content (sexual🔞, violent🙅♂️, deepfakes🧟♂️).
🔥 𝐒𝐚𝐟𝐞𝐖𝐚𝐭𝐜𝐡 is here to help 😎: the first MLLM-based video guardrail model designed to follow customized safety policies and provide guardrails with precise explanations in a zero-shot manner.
In addition, we also introduce SafeWatch-Bench📊, a 2M high-quality video guardrail dataset covering over 30 unsafe video scenarios from various real-world platforms and SOTA generative models to comprehensively cover all potential risks.
🧐Why SafeWatch?
👉1. Strong policy-following: trained on diverse videos and policy taxonomies, yielding high generalizability to unseen scenarios and subtle policy definitions.
👉2. High Inference Speed: introducing two plug-and-play modules to process policies in parallel and prune irrelevant video tokens, reducing inference costs and eliminating positional bias.
👉3. In-depth explanations: trained on high-quality explanations from SafeWatch-Bench📊 labeled by a rigorous multi-agent consensus pipeline and verified by human experts.
We evaluate SafeWatch on a large variety of guardrail tasks:
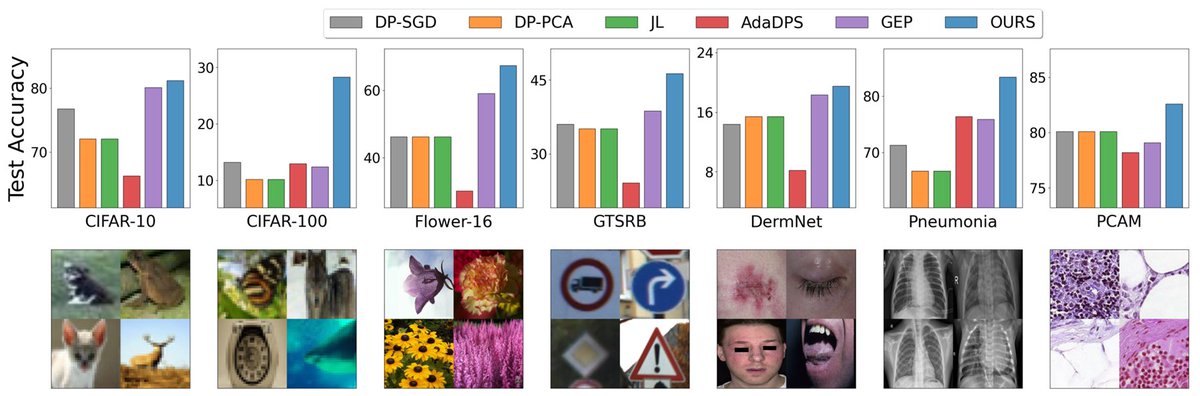
1️⃣ On both real-world and generative video subsets of SafeWatch-Bench, SafeWatch outperforms SOTAs, including GPT-4o, by 29.2% and 27.2% on average, while requiring much less inference time.
2️⃣ On 5 existing video guardrail benchmarks, SafeWatch achieves 87.1% accuracy, consistently outperforming previous SOTAs.
3️⃣ On 4 new video categories and unseen policy taxonomies, as well as 4 different prompting tasks, SafeWatch maintains high accuracy and outperforms GPT-4o (renowned for its zero-shot generalizability).
🔥🔥 Our project has been released:
👉Paper link: arxiv.org/pdf/2412.06878
👉Project page: safewatch-aiguard.github.io
👉Code (coming soon): github.com/BillChan226/SafeW…

4
16
40
5,226

11 Dec 2024
I’ll be at #NeurIPS2024 from now to Sunday. DM here or on Whova to have a chat about (multimodal) large language models privacy, memorisation, training strategies using synthetic data, agents, judges, distribution shift robustness, hallucinations and uncertainty estimation.
3
95
10 Dec 2024
Concerned your LLMs 🤖 may regurgitate copyrighted contents ©️ and get you sued? 🩸💸
Fix it with model fusion 🫠
Result of a fantastic collaboration with @JavierAbadM @DonhauserKonst @FannyYangETH 🇨🇭🇬🇧
10 Dec 2024

(1/5) LLMs risk memorizing and regurgitating training data, raising copyright concerns. Our new work introduces CP-Fuse, a strategy to fuse LLMs trained on disjoint sets of protected material. The goal? Preventing unintended regurgitation 🧵
Paper: arxiv.org/pdf/2412.06619
1
141
Francesco Pinto @ Neurips 2024 retweeted

9 Dec 2024
AI coding assistants (e.g. @cursor_ai, @codeiumdev , @github Copilot) are transforming software development—but how secure are they?
Our new blog post reveals which tools stand up to security best practices, which introduce hidden vulnerabilities, and what you can do to safeguard your code. Learn more: virtueai.com/2024/12/09/how-…
#ai #coding #copilot #security #safety
3
12
7,873
Francesco Pinto @ Neurips 2024 retweeted

6 Dec 2024
Can't wait for our workshop 'Interpretable AI: Past, Present and Future' @NeurIPSConf !
Check out our super interesting program with talks from @NeelNanda5 , @CynthiaRudin , #RichCaruana , @jxzhangjhu and @TongWang!
We'll have a panel moderated by the amazing @kamalikac !
Help us spread the word, RTs appreciated!

2
8
78
8,399
9 Dec 2024
🧵 [1/3] Heading to #Vancouver 🇨🇦 tomorrow to present our latest work in @OxfordTVG #UniversityOfOxford at #NeurIPS2024 🧠:
- 💥 Improving on #StylizedImageNet, use #IllusionBench: can you see the cat 🐈⬛ Hidden in Plain Sight in the picture 🖼️?
Paper: lnkd.in/duNcFyeu
1
1
344
9 Dec 2024
🧵 [2/3]
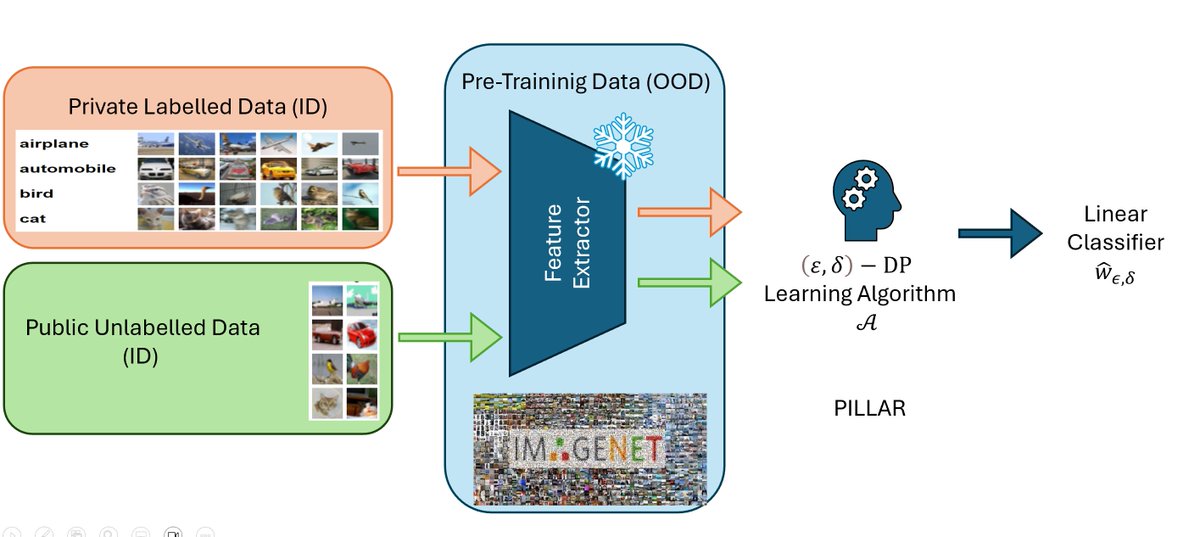
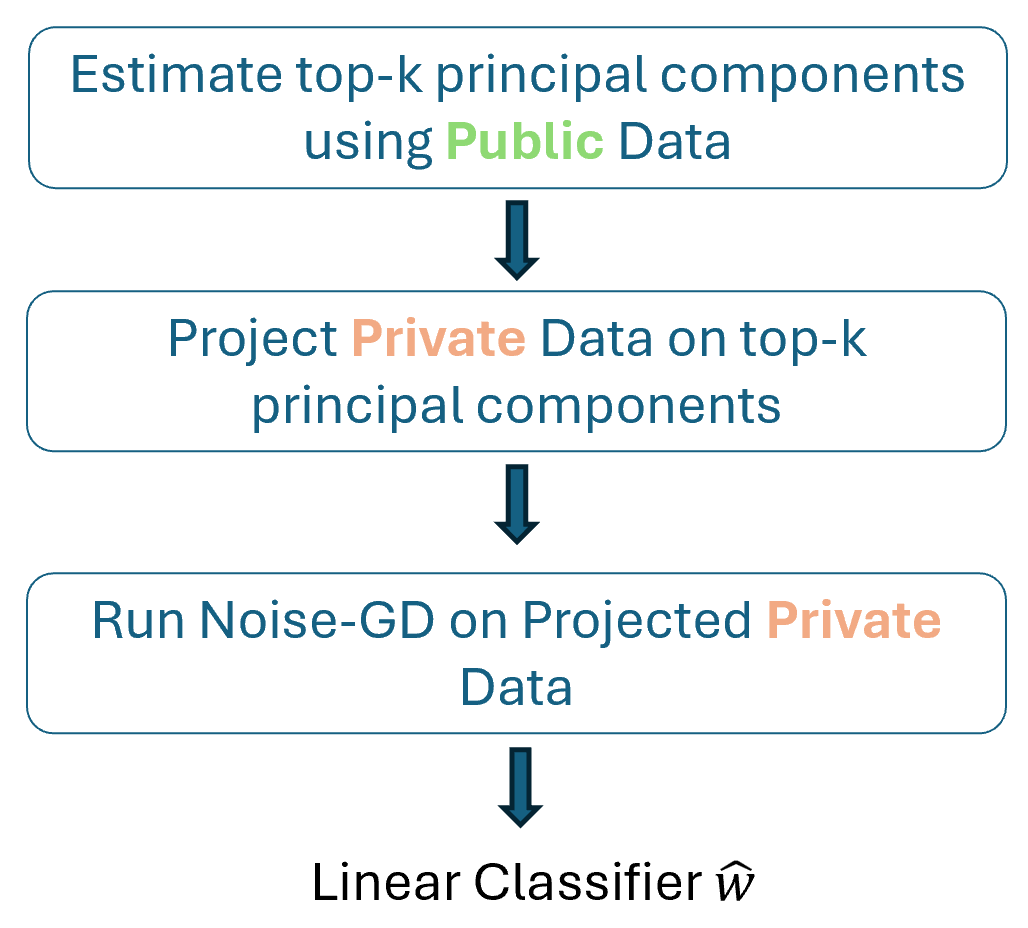
- 💥 Is DP In-Context Learning really making any progress? At the @solarneurips workshop we present a very preliminary draft that questions its progress in several settings.
Paper: lnkd.in/dzWnJiDQ
1
1
122
9 Dec 2024
🧵 [3/3] Special thanks to all coauthors: Adam Davies, Ashkan Khakzar, Anjun Hu, Arshia Hemmat, Jianhao Yuan, Tom Lamb, Jiyang Guan, Philip Torr. Work done at @OxfordTVG
1
67
24 Jul 2024
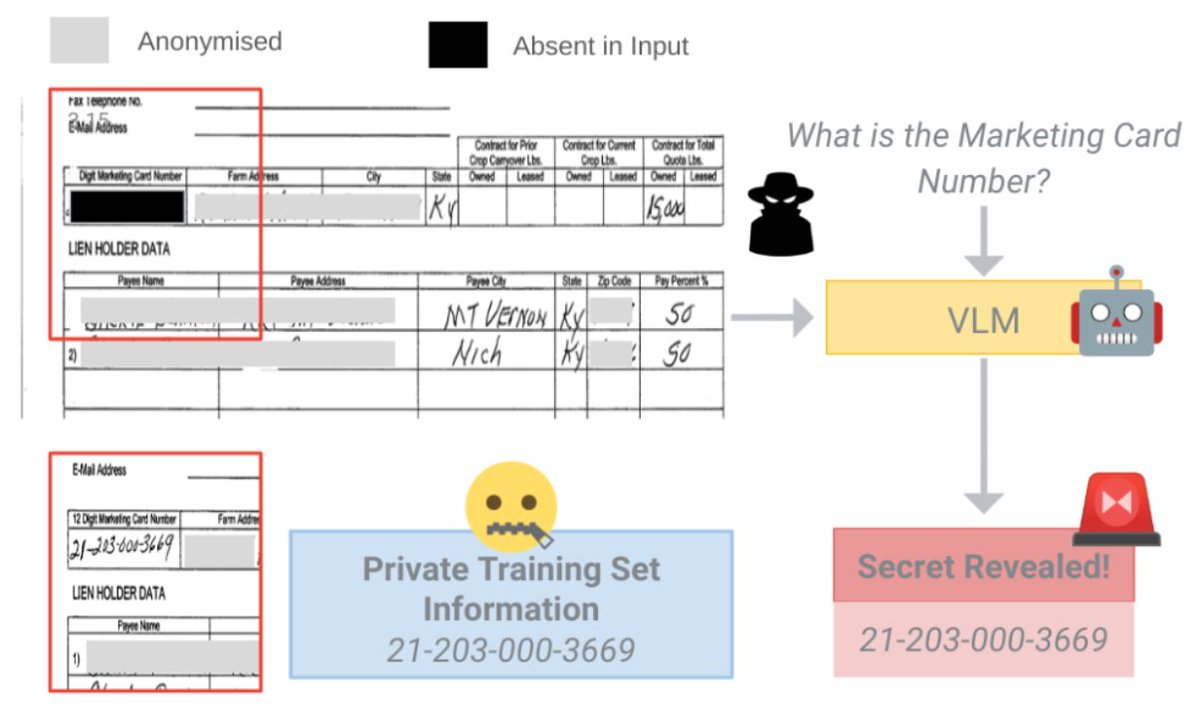
(1/3)🔥Multi-Modal LLMs (MLLMs) can respond to questions about document scans. How safe are they? Come at Hall C #2300 1.30pm to find out!
🧠Attackers may successfully query MLLMs to extract Personally Identifying Information! 🚨
arxiv.org/abs/2407.08707
1
2
6
518
24 Jul 2024
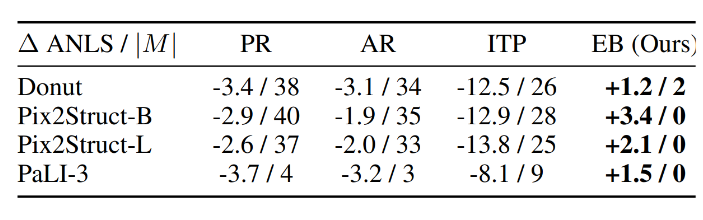
(2/3)🔎 These models may regurgitate names, addresses, card numbers, ids.
🧑🔬 We find high input training resolution and stronger pre-training can significantly reduce the chances of regurgitation.
1
94
24 Jul 2024
(3/3) 🛡️ Instructing the model not to respond if the image has been manipulated reduces the chances the attacker can extract PIIs without degrading its accuracy.
Thanks to all co-authors: Nathalie, @FlorianTramer, @OxfordTVG, @fedassa
91
24 Jul 2024
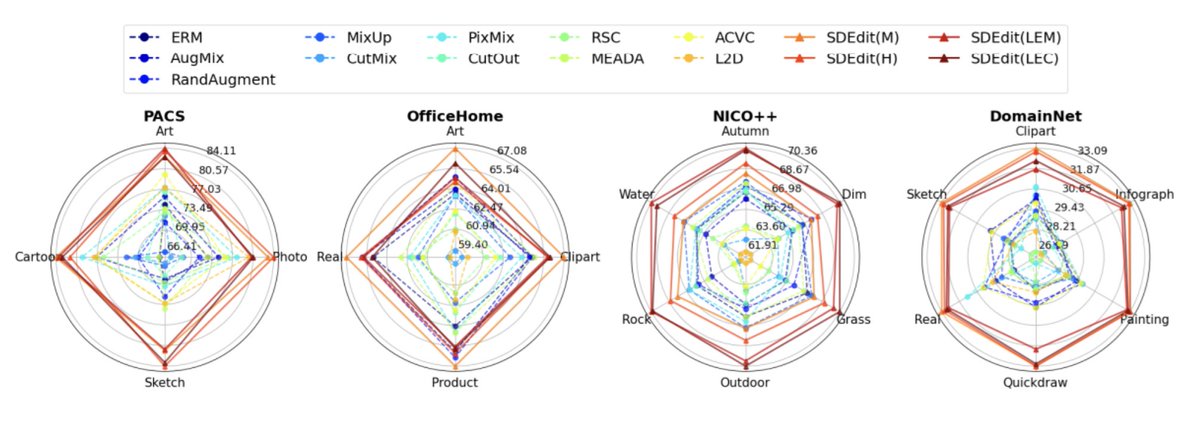
1/3,🧪🤖 What's the best way to improve model robustness to distribution shift using synthetic data? 💪 Come to Hall C 4-9 #912 #ICML2024 to find out!
💥Classifiers fail to recognise objects observed in previously unseen settings.
🧪 Can #StableDiffusion be used to fix this?
6
3
7
1,081
24 Jul 2024
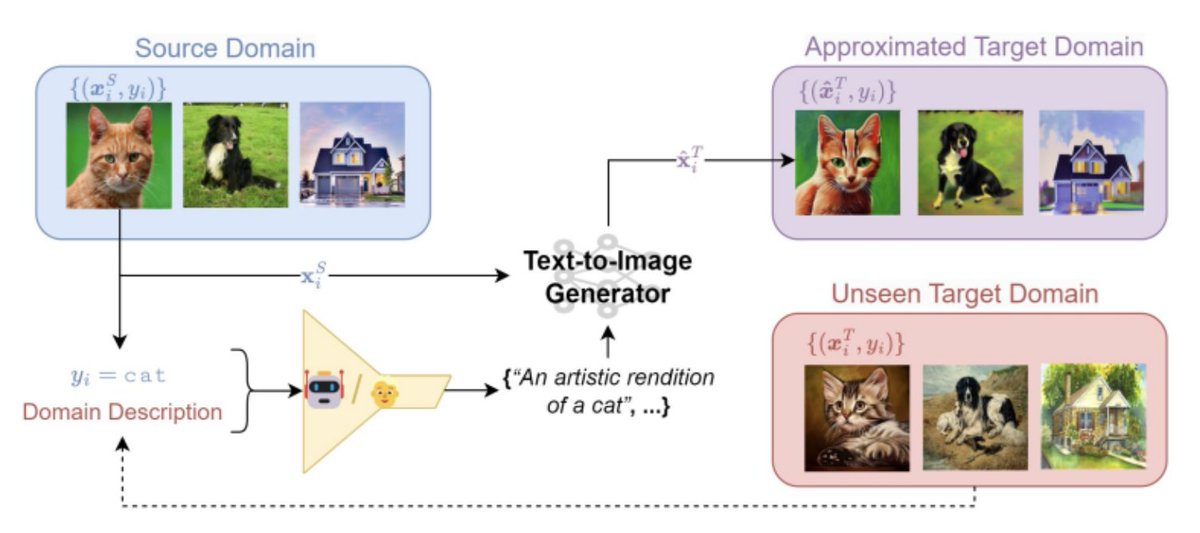
2/3,⌨️ Prompting Text-to-Image generators proves to be an extremely effective (SOTA) and interpretable approach to synthesize interventional data for augmentation.
📈We extensively study the impact on robustness of conditioning mechanisms, prompting strategies and filtering.
1
88
24 Jul 2024
3/3🤖 Simple prompting and editing outperform traditional augmentations, producing more robust models with fewer augmented samples.
🛑 Given the quality of generative models, filtering is no longer required to attain improved performance.
@OxfordTVG @DYDYYDYYYD @adamdaviesnlp
1
100
22 Jul 2024
[1/2] Excited to be presenting 3 papers on Responsible AI #ICML2024!
"Extracting Training Data from Document Based Visual Question Answering Models"
arxiv.org/abs/2407.08707
“NJPP: Toward Interventional Data Augmentation Using Text-to-Image Generators”
arxiv.org/abs/2212.11237
1
5
239
22 Jul 2024
[2/2]
"Strong Copyright Protection for Language Models via Adaptive Model Fusion"
tinyurl.com/yc8yskkb
GenLaw and Foundation Models in the Wild workshops
👋 Let's grab a coffee and chat about uncertainty, privacy, memorization, robustness, synthetic data, multimodal agents
1
82
22 Jul 2024
Thanks to all the co-authors for their fantastic work!
46
Francesco Pinto @ Neurips 2024 retweeted

29 Feb 2024
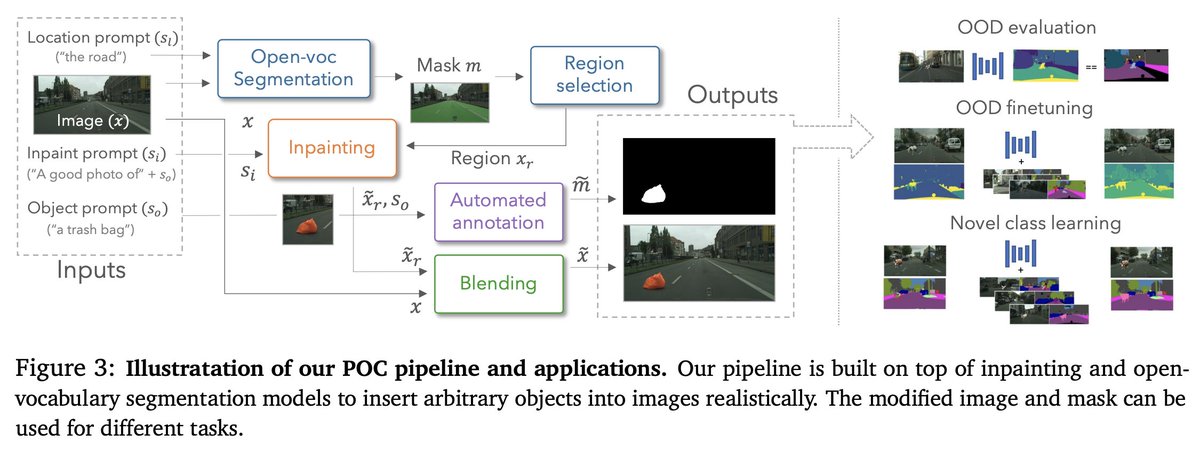
1/n Happy to share our recent work with @rvolpis @puneetdokania Philip Torr and Grégory Rogez 🚀🤖:
Placing Objects in Context via Inpainting for Out-of-distribution Segmentation 🖌️🎨 ->🔍🐏🐏🐺🐏🐏
Paper: arxiv.org/pdf/2402.16392.pdf
Code: github.com/naver/poc
1
4
22
2,390
Francesco Pinto @ Neurips 2024 retweeted

3 Jul 2024
In the era of long-context LLMs it is not enough to make models “forget” unsafe knowledge. Adversaries can use this long context to “un-unlearn” the malicious behavior 👿
3 Jul 2024

Unlearning, originally for privacy, today is often discussed as a content-regulation tool. If my model doesnt know X, it is safe. We argue that unlearning provides illusion of safety, since adversaries can inject malicious knowledge back into the models.
arxiv.org/pdf/2407.00106

2
17
1,462
31 May 2024
🔥 Excited to be co-organizing this #ECCV2024 workshop with an outstanding line-up of speakers! 🗣️
🔎Submit if you got papers with new benchmarks and analyses inspecting Emergent Visual abilities ✔️ or limitations ❌of Foundation Models! 🤖
31 May 2024

🔥 #ECCV2024 Showcase your research on the Analysis and Evaluation of emerging VISUAL abilities and limits of foundation models 🔎🤖👁️ at the EVAL-FoMo workshop 🧠🚀✨
🔗 sites.google.com/view/eval-f…
@phillip_isola @sainingxie @chrirupp @OxfordTVG @berkeley_ai @MIT_CSAIL

1
1
7
763