
Joined February 2020
- Tweets 68
- Following 522
- Followers 129
- Likes 235
15 Photos and videos





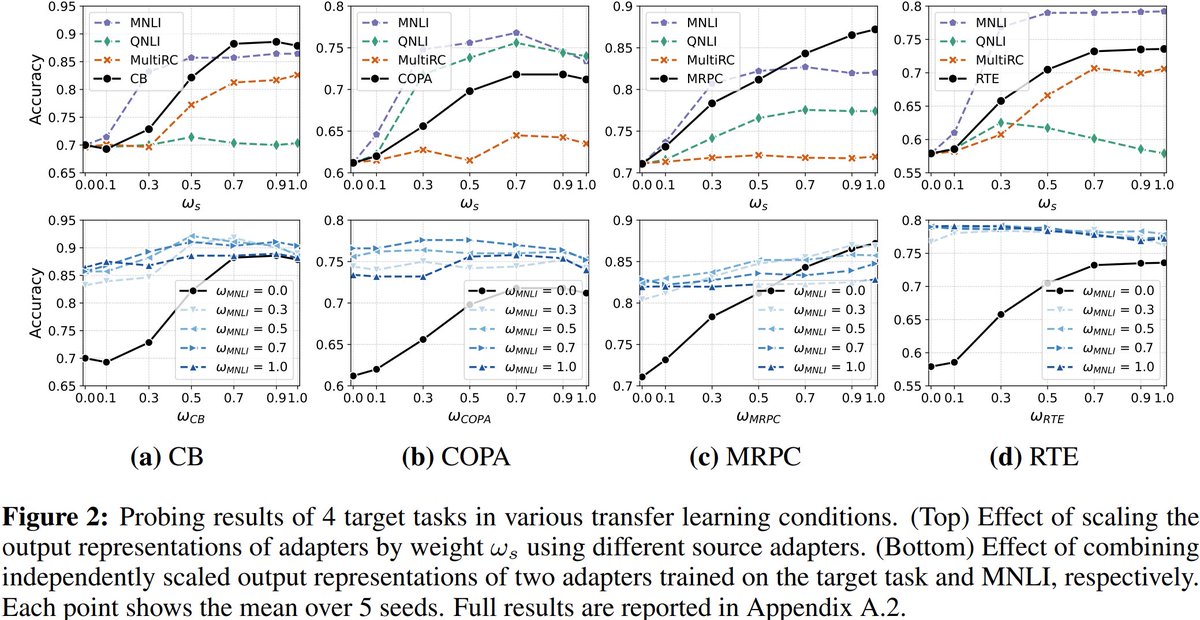
Excited to share that I'll be joining @thomsonreuters Labs in Zug, Switzerland, as an Applied AI Scientist Intern from April to September 2026! 🏔️
A nice bridge between finishing my MSc at JKU Linz and starting my PhD later this year - let me know if you're around!
2
121
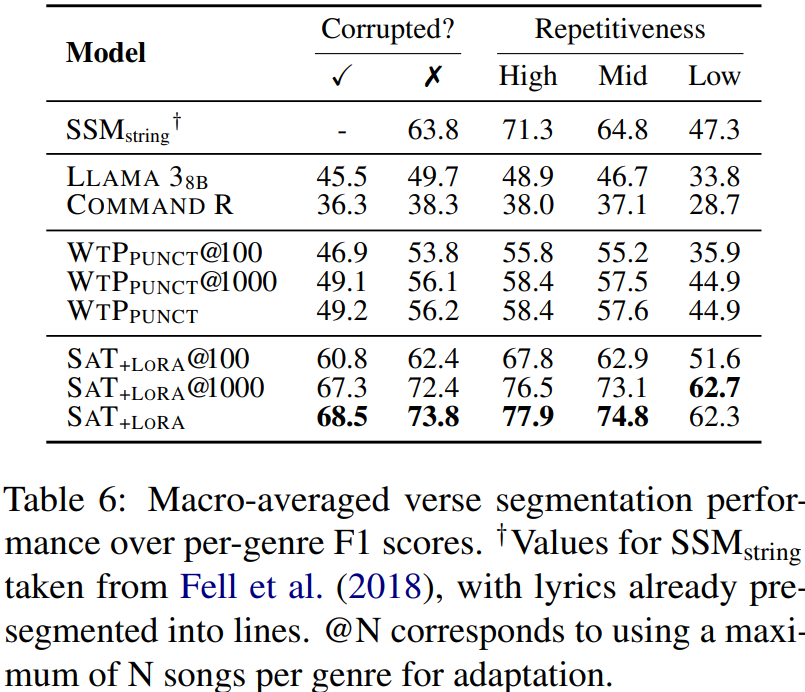
wtpsplit now supports length-constrained segmentation ✂️
min/max chunk length (chars) while preserving semantic chunks - should be great for RAG!
Example (≤30 chars):
[Landing 5pm → Beimen.]
[Let's meet at: Ximen Exit 6.]
[Then: Ningxia Night Market...]
[Late-night snack!']
26 Jun 2024

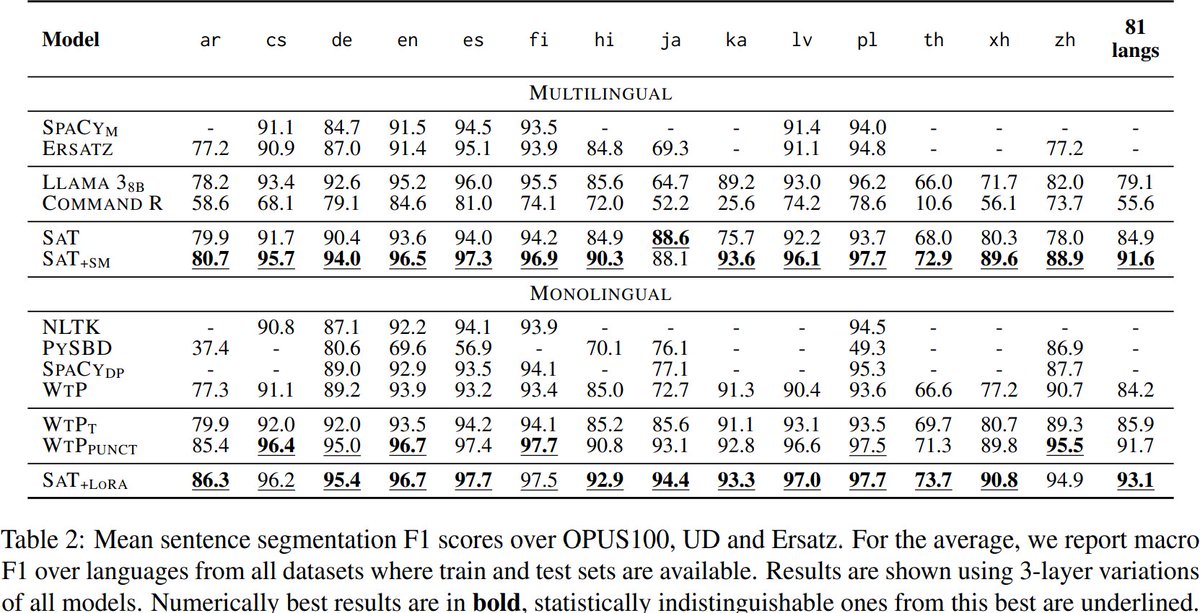
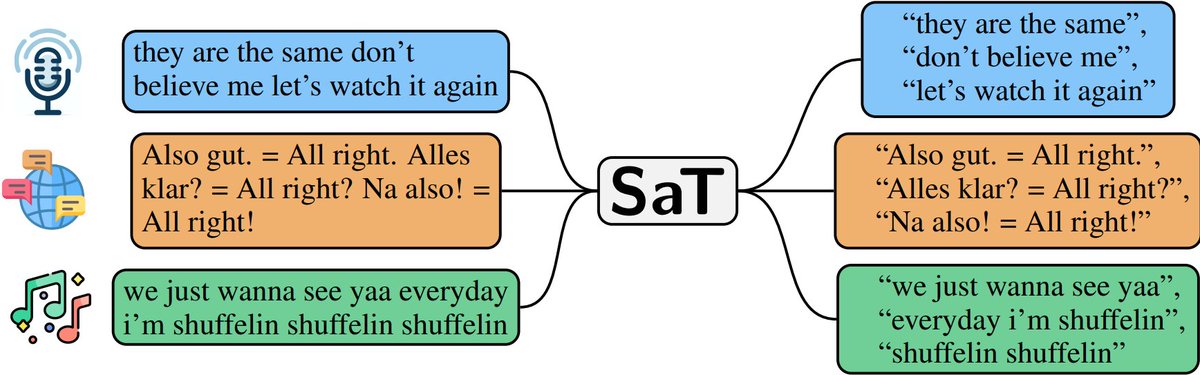
Introducing 🪓Segment any Text! 🪓
A new state-of-the-art sentence segmentation tool!
Compared to existing tools (and strong LLMs!), our models are far more:
1. efficient ⚡
2. performant 🔝
3. robust 🚀
4. adaptable 🎯
5. multilingual 🗺
ALT Examples of our models' predictions.
2
209

3 Nov 2025
I'm at #EMNLP2025 in Suzhou this year!
Looking forward to connecting with the community after a year's break and spending some time abroad。。。再見!
1
16
2,326
28 Jul 2025
🤖🗣️ Double Entendre will be presented today, 18:00-19:30 at Hall 4/5 by @m_schedl! Check it out if you're at #ACL2025!
25 Jul 2025
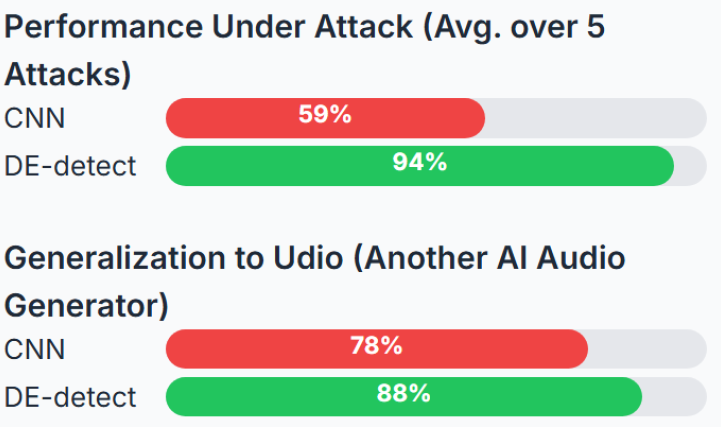
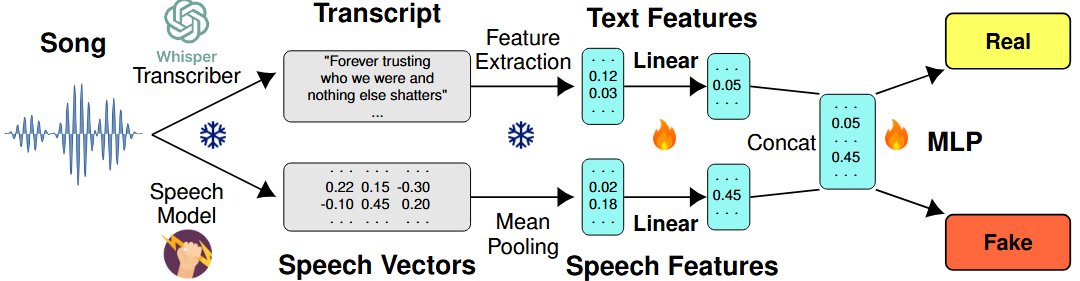
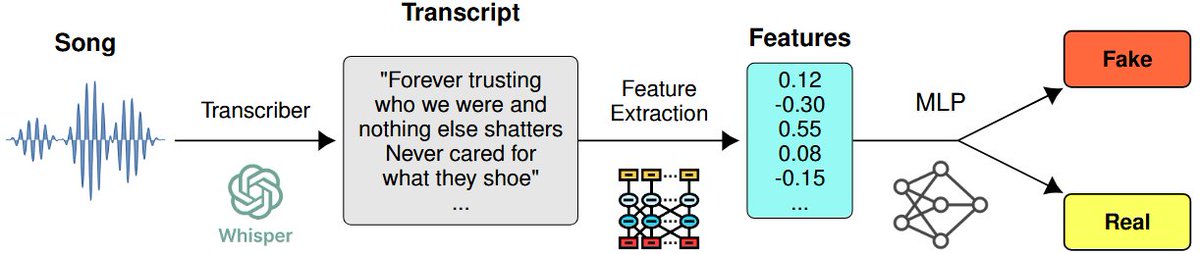
Excited to share two new papers on AI-generated music detection from my research internship at @Deezer, published in @ismir_conf #ISMIR2025 and @aclmeeting #ACL2025 Findings! 🎶🤖
The problem: most AI music detectors are impractical or unreliable in real-world settings.
5
2
255
25 Jul 2025
Excited to share two new papers on AI-generated music detection from my research internship at @Deezer, published in @ismir_conf #ISMIR2025 and @aclmeeting #ACL2025 Findings! 🎶🤖
The problem: most AI music detectors are impractical or unreliable in real-world settings.
5
3
467
25 Jul 2025
I view this work as an important extension of current single-modality detectors while maintaining flexibility and modularity. It's not production-ready, but it highlights key paradigms for detection:
Using all available information from just the audio and a focus on robustness.
1
92
25 Jul 2025
I had a great time working on this with @deezer in Paris! Big thanks to my mentors @evpure, @Gabolsgabs, and @m_schedl!
💻 Code: github.com/deezer/robust-AI-…
📄 ISMIR Paper (foundation): arxiv.org/abs/2506.18488
📄 ACL Paper (Multi-View Double Entendre): aclanthology.org/2025.findin…
1
94
8 May 2025
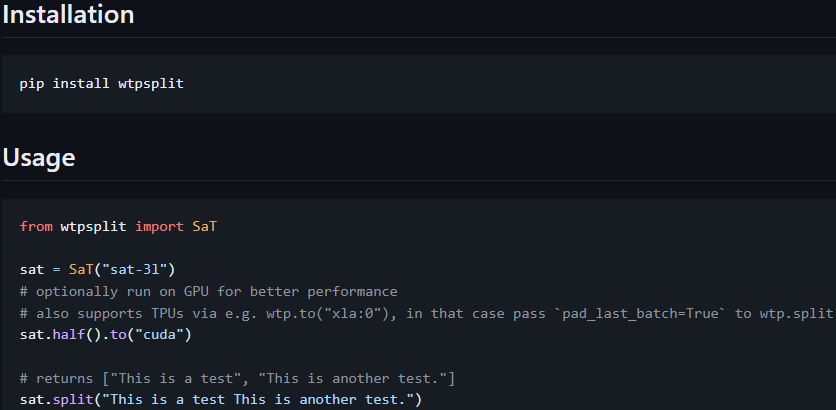
Wtpsplit, our text segmentation tool, just reached ⭐️1000 stars⭐️ on GitHub! Excited to see it is proving useful!
Check it out here: github.com/segment-any-text/… 🎉
26 Jun 2024
Introducing 🪓Segment any Text! 🪓
A new state-of-the-art sentence segmentation tool!
Compared to existing tools (and strong LLMs!), our models are far more:
1. efficient ⚡
2. performant 🔝
3. robust 🚀
4. adaptable 🎯
5. multilingual 🗺
ALT Examples of our models' predictions.
1
7
515
Markus Frohmann retweeted

2 Apr 2025
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵

ALT Image illustrating that ALM can enable Ensembling, Transfer to Bytes, and general Cross-Tokenizer Distillation.
2
26
86
6,533
11 Nov 2024
Curious about our SoTA text segmentation tool? 🪓 It's gonna help you across all kinds of NLP tasks!
Learn more at our poster session: Tuesday, 4pm, Jasmine room at #EMNLP2024! 🗓️
See you there!
I'll be attending the whole conference - happy to connect with everyone! 👋
26 Jun 2024
Introducing 🪓Segment any Text! 🪓
A new state-of-the-art sentence segmentation tool!
Compared to existing tools (and strong LLMs!), our models are far more:
1. efficient ⚡
2. performant 🔝
3. robust 🚀
4. adaptable 🎯
5. multilingual 🗺
ALT Examples of our models' predictions.
5
238
28 Oct 2024
Excited to share that I joined @researchdeezer as a research intern to work with @evpure and @Gabolsgabs on detecting AI-generated lyrics !🎶
The first few weeks have been amazing, and I am excited about what is to come—life in Paris certainly has unparalleled charm!
6
204
2 Oct 2024
This was an awesome summer! I can only recommend ETH's summer research fellowship program 🏔️
Also happy about the project's progress - integrating videos into existing architectures is quite exciting, stay tuned! Super grateful to Ryan Cotterell and @glnmario for supervising me.
29 Jul 2024
Excited to share that I joined @ETH Zürich as a summer research fellow, supervised by Prof. @ryandcotterell, working on ✨Multimodal LLMs! ✨
The first few weeks have been a blast, and I'm looking forward to the weeks ahead! 📽️
1
6
370
Markus Frohmann retweeted

30 Sep 2024
Congratulations to C4AI Research Grant recipient
@FrohmannM and all authors of "Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation" for their EMNLP acceptance!🥳
19 Sep 2024
This got accepted to #EMNLP 24 Main! ✨
Same goes for our paper on unsupervised debiasing 🤓
✈️🇺🇲
1
2
7
1,446
Markus Frohmann retweeted
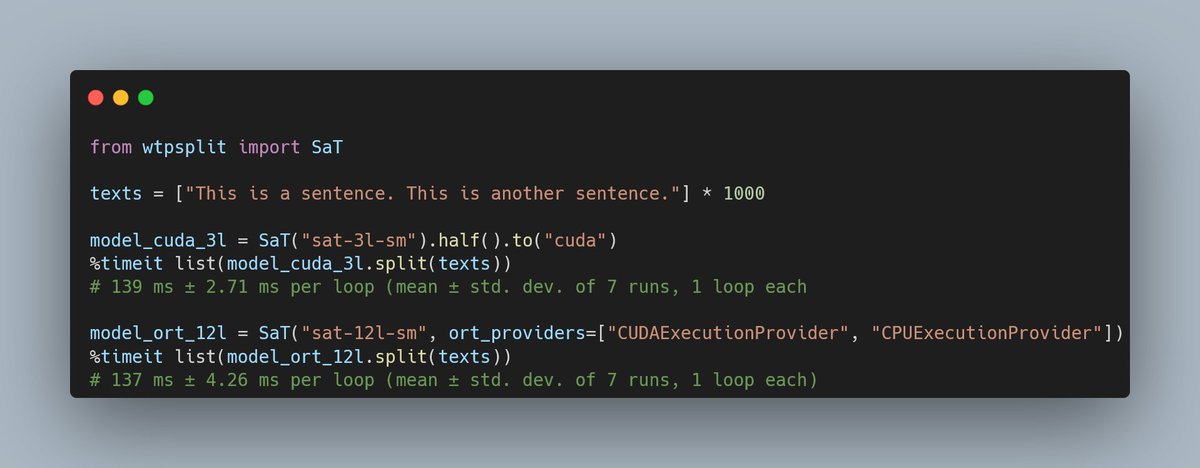
25 Sep 2024
Just in time for acceptance to #EMNLP2024, we added ONNX support to SaT🚀
The 12 layer model can now segment 45k chars in ~137ms. This is faster than the previous 3 layer model implementation.
24 Sep 2024
We just released v2.1.0 of our library! ⚡️
It now supports GPU inference via ONNX, leading to a further ~50% speedup for all models.
Check out our state-of-the-art sentence segmentation tool here: github.com/segment-any-text/…
1
1
12
887