
11 Photos and videos





Pinned Tweet

19 Aug 2025
After testing GPT-5 (Pro subscription) since launch on real work (coding, research, prod reviews), here’s a straight, no-fluff take.
TL;DR
GPT-5 Thinking is the best “facts web synthesis” model I’ve used so far. GPT-5 Pro feels like a staff/principal engineer doing risk reviews. Codex CLI is now the default implementer; Claude Code is the reviewer. Hallucinations are near-zero when used correctly. Not a silver bullet; still needs tests and discipline.
Precision & Web
•Retrieves, verifies, and compresses web info with very low hallucination rate.
•Better than “Deep Research”-style flows tried before: faster to the point, more signal per token, fewer detours.
•o3 was already elite at reasoning; GPT-5 Thinking is o3 , with deeper nuance and tighter sourcing.
Model Routing
•The picker/router was confusing early on, so GPT-5 Thinking is the default for anything non-trivial.
•The non-thinking variant is only used for universally known facts (“Who was Marcus Aurelius?”).
•Non-thinking struggled on math/physics stress prompts (5 fails on a standard test prompt used across models). It’s not the right tool for formal derivations.
GPT-5 Pro = Production Guardian
•Workflow: build an implementation plan with Claude Code GPT-5 via Codex CLI (after giving repo context) → hand the plan to GPT-5 Pro.
•What happens: GPT-5 Pro spots production-grade failures before they happen: race conditions, idempotency gaps, edge-case input handling, flaky retries, concurrency pitfalls, security regressions.
•The difference: not generic “lint”; it flags the exact line of failure and the real-world blast radius (e.g., webhook replay partial DB commit = phantom charges). That’s principal-engineer-level scrutiny.
•Hallucinations were effectively zero in these reviews; citations and reasoning held up under adversarial checks.
Codex CLI vs Claude Code
•Codex CLI is slower than Claude Code at times and can feel conservative, but it’s more solid and avoids nonsensical diffs.
•Best pattern found: Codex CLI as the implementer, Claude Code as the second-opinion reviewer focused on clarity and refactors. Net effect: fewer regressions, cleaner merges.
Props to @embirico for keeping in touch with the community and @OpenAI for giving subscription usage instead of just api. This product has improved significantly in such a short period of time.
Where GPT-5 Thinking Shines
•Web-backed briefs, competitive scans, RFC-style design notes, failure-mode analysis, and “compress the internet into what matters” tasks.
•It consistently catches the subtle stuff o3 sometimes missed and keeps the write-ups crisp.
Limitations & Caveats
•Non-thinking ≠ math engine; use Thinking/Pro for formal reasoning or back it with a CAS/test harness.
•Speed can vary; don’t block delivery on a single long run but stage work and keep tests green.
•Never outsource judgment: enforce idempotency, add invariants, run chaos/replay tests, and treat outputs as proposals until the CI proves them.
Verdict
This is the first time an LLM actually felt like a staff/principal engineer on call 24/7. For this use case, shipping reliable software with real stakes, GPT-5 is an upgrade over o3 in depth, subtlety, and truthfulness. Expectations exceeded.
1
2
241
14 Sep 2025
ok great, claude code was working very well today and suddenly i feel like it switched to gpt 3. it’s unusable right now and nothing on the anthropic page about it.
51
16 Aug 2025
REMEMBER.
The biggest unlock building with AI its not “one perfect prompt.”
It is switching between models and comparing outputs until you got the right fit.
Each model has strengths. Use them like tools, not magic.
1
59
16 Aug 2025
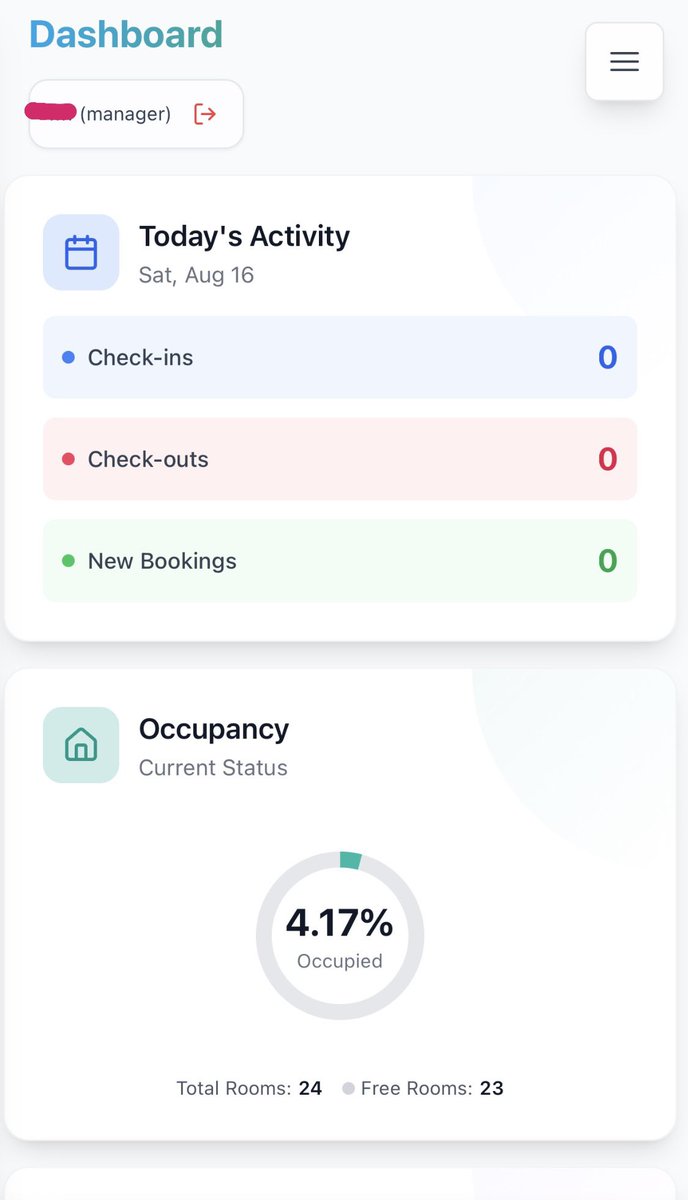
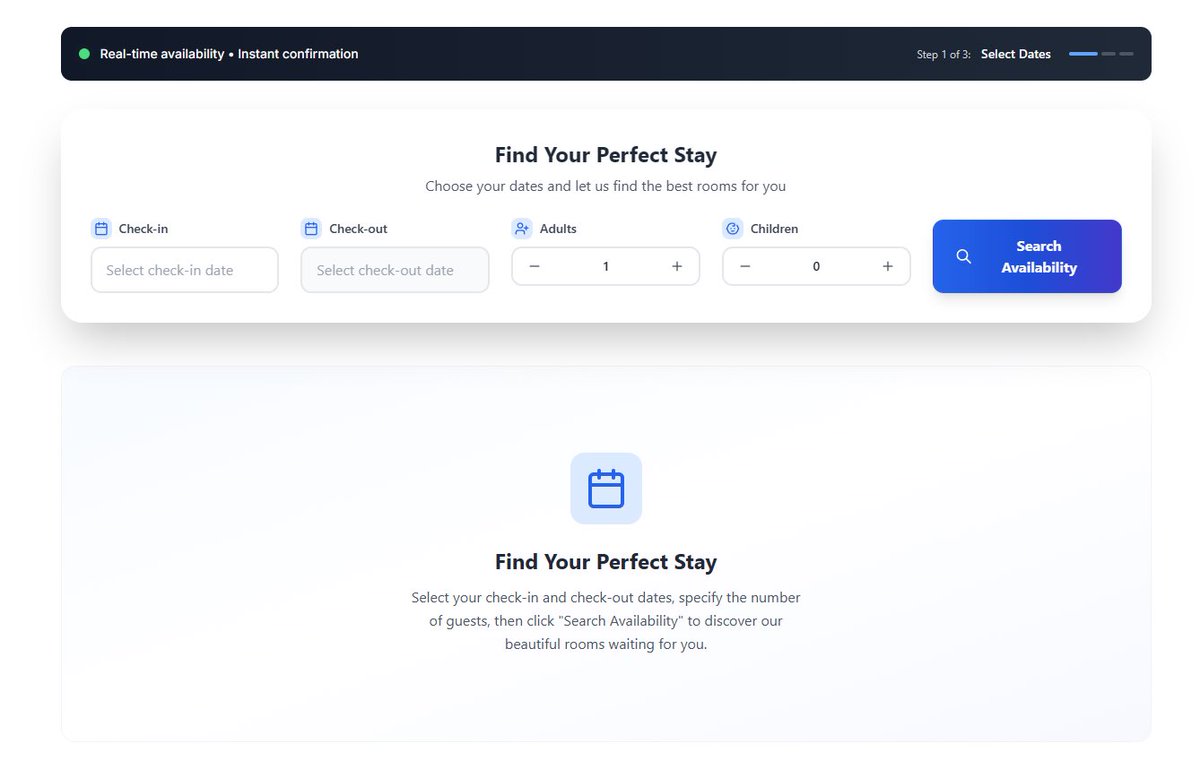
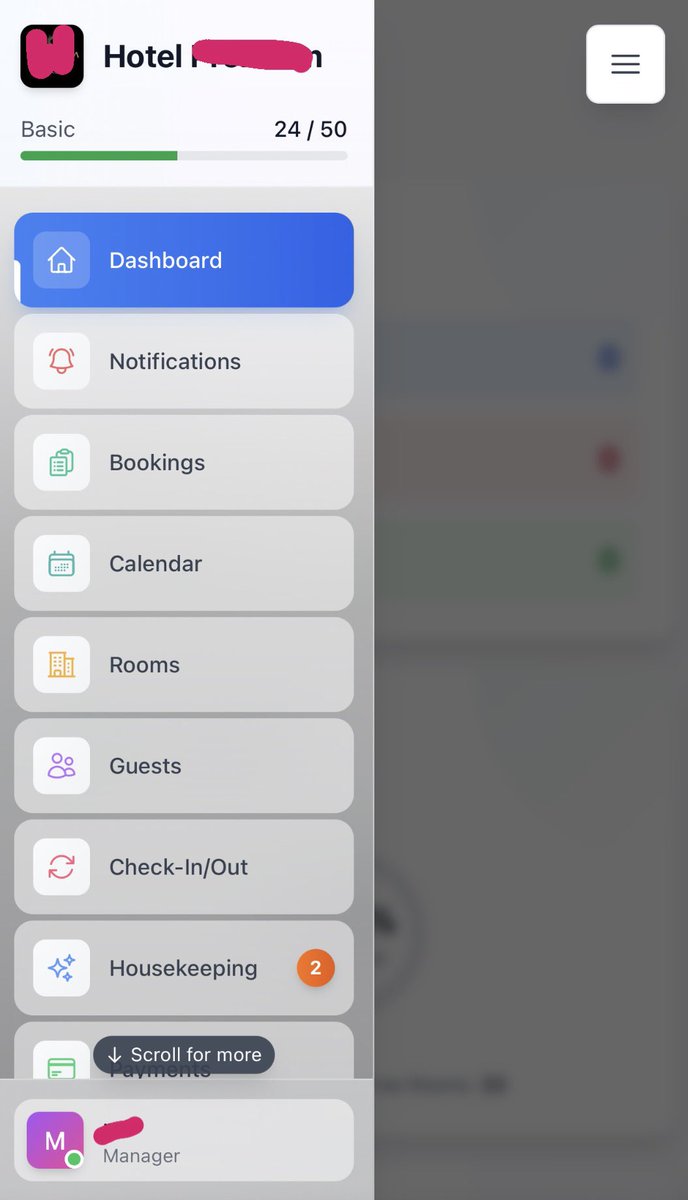
Shipped full mobile browser support.
The entire PMS dashboard, bookings, calendar, check-in/out, housekeeping. Now works 1:1 on phone.
No native app. No installs. Same features, same speed.
Built with AI as my only co dev. Screens below.
#BuildInPublic
1
2
62
13 Aug 2025
Why I chained models instead of sticking to one:
I began with o1. When o3 launched, I moved to o3.
In parallel I used Claude models, starting with Sonnet 3.7, then Sonnet/Opus 4.
I switch between o3 / Sonnet/Opus 4 per task and compare outputs. No single model wins every time.
Chaining kept me moving fast and raised the quality of what shipped.
3
46
12 Aug 2025
From basic tables to a complete guest management hub.
Here’s how the Guest Page and Guest Profile evolved in my hotel management SaaS. 👇
1
2
87
12 Aug 2025
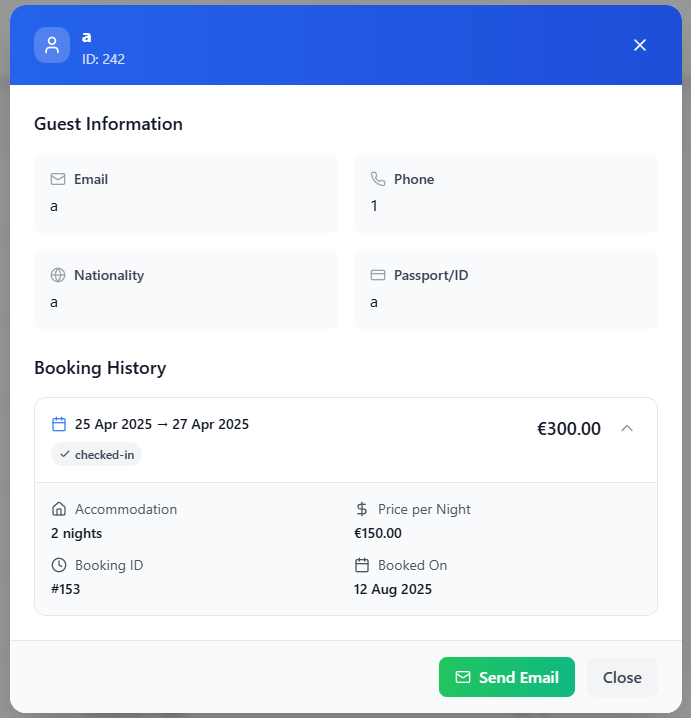
The new Guest Profile
All guest details in a clean card layout.
Full booking history with dates, price/night, total cost, and booking ID.
Quick email button for instant communication.
1
32
12 Aug 2025
Guest management is now faster, cleaner, and more insightful for hotel staff.
19
11 Aug 2025
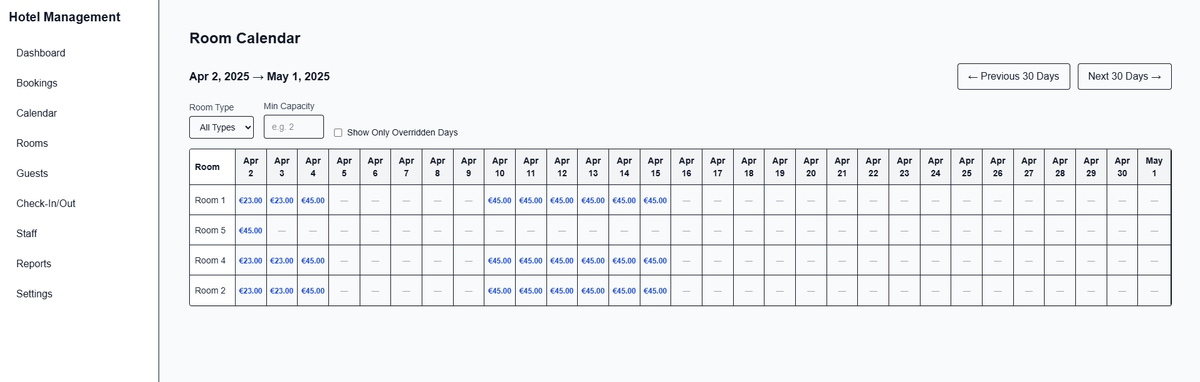
When I started building my hotel management system, the calendar was just a static view.
No syncing, no price overrides, no bulk actions.
Here’s how it evolved into a powerful, fully synced calendar hotels now run their business on.
1
2
30
11 Aug 2025
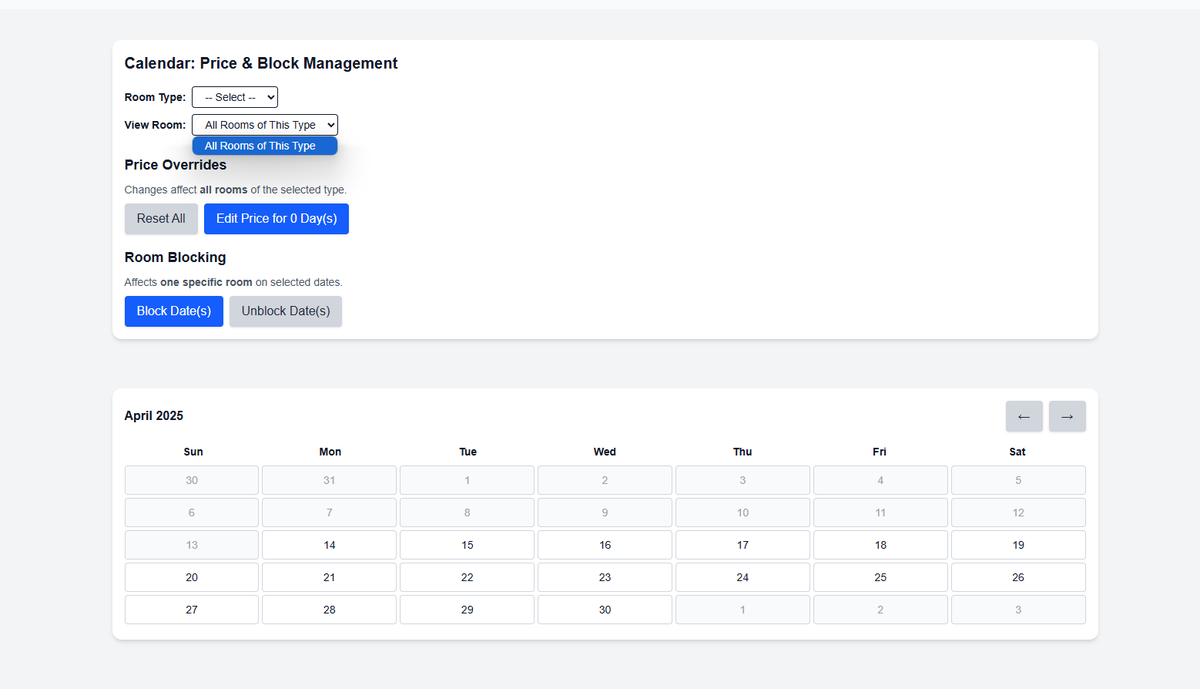
Second version
Added ability to edit prices directly on the calendar
Block/unblock rooms instantly
Highlight ongoing stays & future reservations
This already saved hotels hours per week.
1
2
20
11 Aug 2025
Today
Real time sync with all major booking platforms (Booking, Airbnb, Expedia, and more)
Bulk price overrides for any date range
Maintenance day blocking
Color-coded reservations by status
Instant availability updates across all channels

2
18
10 Aug 2025
5 months ago → just a static frontend shell.
No backend. No API. No functionality.
Today → 180 API endpoints powering a full scale, multi hotel SaaS.
Here’s what happened:
2
19
10 Aug 2025
Security, speed, and scalability were priorities from day one.
The API supports multiple hotels, managers, and staff. All with granular permissions.
1
11
10 Aug 2025
It’s already fully equipped with:
- Public booking pages
- POS system
- Advanced channel manager
- Payment integrations
- Detailed analytics
- Automation everywhere
Built from the ground up in months with the help of AI.
10