
Joined August 2025
- Tweets 198
- Following 80
- Followers 5,125
- Likes 17
131 Photos and videos








Pinned Tweet

Jan 14
Didn’t expect ALE to spark this much attention — thanks for the interest !
It feels like we’re past the “prompt it and hope” phase.
The next leap is infrastructure for agents in real task environments!
Here’s the problem: Because of the lack of end-to-end infrastructure and scalable feedback loops, models can’t learn effectively from complex, multi-step interactions.
So we built ALE: an open Agentic Learning Ecosystem that closes the loopexecution → feedback → learning in executable environments.
Under the hood, ALE is powered by
ROCK:A sandbox environment manager that orchestrates complex trajectories at scale.
ROLL:A post-training framework dedicated to weight optimization.
iFlow CLI: An agent framework for efficient, configurable context engineering.
The Secret Sauce: IPA Algorithm
Standard LLM training fails on long tasks. Our IPA algorithm fixes this by optimizing for semantic interaction blocks—not just tokens—giving agents the stability to handle hundreds of steps.
The Capstone: ROME(ROME is Obviously an Agentic ModEl) was born naturally. Trained on 1M real trajectories.
ROME is a 30B-scale model, achieves 57.40% on SWE-bench Verified, outperforming similarly sized models and rivaling 100B giants.
30B is also the ‘sweet spot’ to get started — build your own “super ROME” from here.
We’ll keep sharing what we’re building next — agents, multimodal systems, and AI-native applications, powered by strong infrastructure like ALE.
If you’re building agents too, stay tuned!
18
33
265
145,959
Jun 10
Once AI agents move into production, the first issue to solve may not be capability.
It is identity.
When people talk about agents today, the first questions are usually:
Can it call tools?
Can it complete tasks automatically?
Can it keep going on its own?
But once it enters an enterprise environment, the question becomes much more practical:
Who is actually taking the action?
Is it the user?
Is it a system proxy?
Is it a temporary authorization?
Or is it a long-lived machine identity?
If this boundary is unclear, it becomes hard to assign accountability for every step the agent takes.
Who granted the permission?
What data did it access?
Which tool did it call?
If something goes wrong, whose access should be revoked?
It is like bringing a very capable new teammate into a company.
Capability matters, of course.
But before that teammate touches real systems,
you need to know their role, permissions, and scope of responsibility.
As agents begin entering real business environments, identity, authorization,and permission boundaries will become part of the discussion.
Future agents that can operate reliably in production environments will need to do more than just complete tasks.
They will also need to understand who they are acting on behalf of and which actions fall within their authorized scope.
3
1
70
Autonomous driving is not usually tested hardest by the easy miles.
Clear weather.
Straight roads.
Stable traffic.
Pedestrians crossing normally.
These scenes matter.
But they are not where the real pressure shows up.
The harder cases are the ones that happen rarely,
but become dangerous the moment they appear.
Rain at night.
Temporary construction.
A car braking suddenly.
A pedestrian stepping out from a blind spot.
A complex intersection where another vehicle does something unusual.
These situations are not always easy to collect at scale in the real world.
But an autonomous driving system cannot wait until the first real encounter
to learn how to handle them.
That is where world models become especially valuable for self-driving.
They are not just about generating realistic road videos.
They can turn rare, risky, and hard-to-collect scenarios
into environments the system can practice before deployment.
It is a lot like pilot training.
The important part is not only normal takeoff and landing.
It is also engine failure,
bad weather,
emergency avoidance,
and all the situations that rarely happen,
but still have to be handled correctly.
So the next stage of world models in autonomous driving may not be about making ordinary roads look more realistic.
It may be about turning dangerous long-tail scenarios
into repeatable training grounds.
Because self-driving systems do not only need to perform well when the road is easy.
They need to have seen enough trouble
before that trouble appears in the real world.
102
While showbiz bickers over AI video continuity glitches and educators remain stuck debating AI-generated PPTs, World Models are quietly disrupting non-tech sectors, igniting a radical paradigm shift in clinical medicine and surgical simulation.
Why healthcare and not Hollywood?
Because Hollywood demands visual perfection, but healthcare mandates absolute physical causality.
Traditional medical AI could only act as a static periscope—pinpointing a lesion on an existing scan.
Yet disease is inherently dynamic. When a physician prescribes a treatment, they historically lacked a patient-specific, long-term window into the exact downstream changes after the patient ingests the drug.
Recent breakthroughs showcased at elite computing summits like ICCV have elevated medical AI from passive visual recognition to a predictive, generative "World Simulator" tailored for prognosis and treatment optimization.
In validated clinical applications, this technology leverages potent counterfactual reasoning.
Take transarterial chemoembolization (TACE) for liver cancer and advanced radiotherapy as prime examples: before finalizing an intervention, a Medical World Model (MeWM) ingests a patient’s current CT imagery to simulate months of dynamic disease progression within its latent space.
It cross-aligns multimodal parameters to synthesize high-fidelity visual representations of post-treatment tumor trajectories. Simultaneously, its inverse dynamics model quantifies how varying embolic agents or drug cocktails shift long-term survival curves. Empirically, this "future-simulation" paradigm has propelled clinical decision success rates (F1-score) by 13%, cementing its role as an indispensable AI co-pilot.
Today, multimodal medical models are rapidly embedding into hospital HIS/EMR nervous systems, as specialized prognosis simulators push past theoretical boundaries into raw performance validation.
The ultimate utility of a World Model isn't coding text or animating fantasy; it is evolving into a rigorous, low-cost simulation infrastructure—serving as a high-stakes safeguard for human decision-making.
【The Grand Forecast】
The successful clinical deployment of Medical World Models proves their unique capacity to "simulate future outcomes before executing current actions." This technical paradigm—trading pure aesthetic appeal for rigid physical and biological causality—is sprawling beyond tech ecosystems at a breakneck speed.
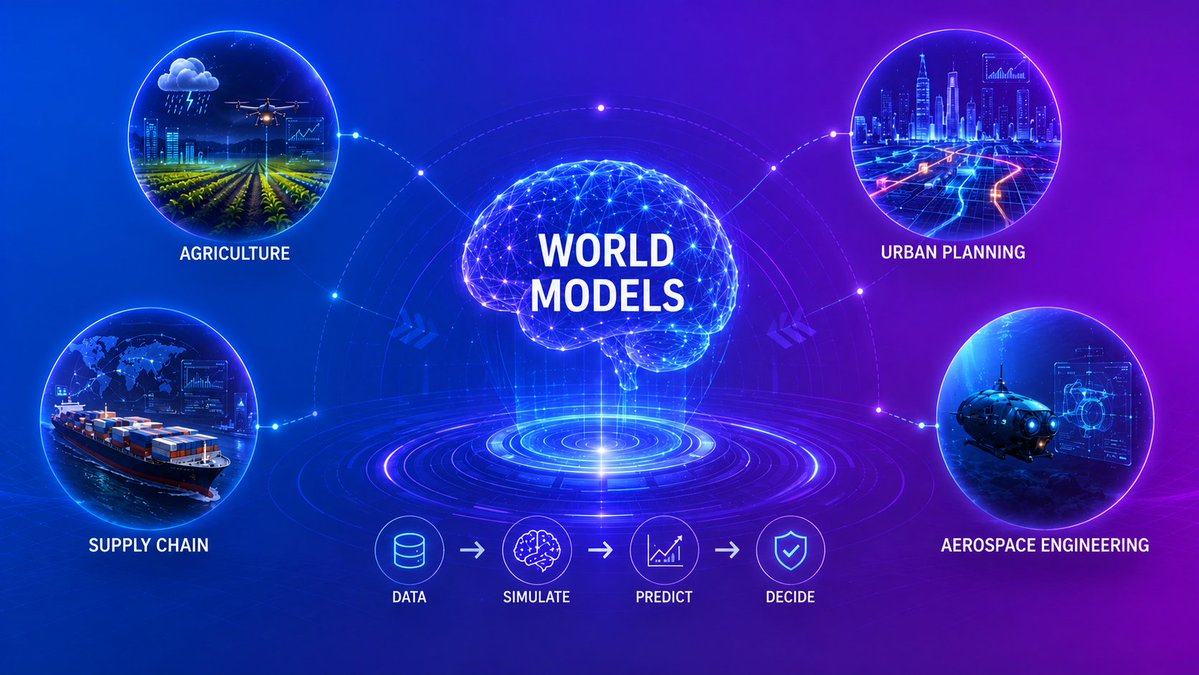
Stripping away healthcare, autonomous driving, and media entertainment, which trial-and-error heavy traditional industry do you predict World Models will infiltrate and disrupt next?
Will it be macro-climate disaster modeling in modern agriculture, dynamic supply-chain evolution in urban planning, extreme stress-testing in deep-sea aerospace engineering, or an entirely unmapped frontier?
Drop your sharpest thesis and reasoning in the comments below. Let’s chart the hidden industrial landscape of the next generation of World Models!
19
9
27
306,725
May 26
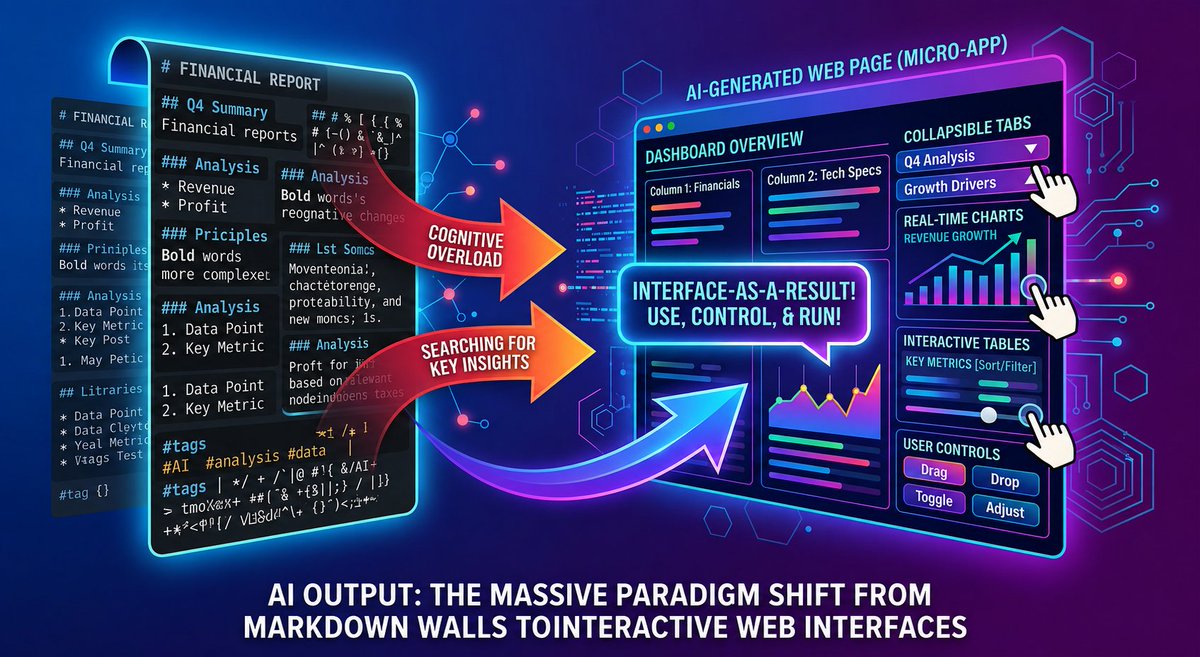
Something big is quietly happening in the AI world: we’re seeing a massive paradigm shift. The default output for multimodal models and agents is making a huge leap—moving away from those endless walls of Markdown and straight into fully live web pages.
Think about it: why is Markdown just not cutting it anymore? Because when outputs get long, a screen packed with hashtags, bold words, and bullet points is just a total headache to read. It used to be that when an AI dumped a thousand-line financial report or technical plan on you, finding the key insights was like looking for a needle in a haystack.
But delivering results via Web completely changes the game. Instead of staring at a massive wall of text, you get a dynamic webpage with multi-column layouts, collapsible tabs, interactive tables, and live charts. What used to be a dry, boring long-form doc is now a clean, interactive micro-app.
This shift to "interface-as-a-result" means that if you don't like what you see, you don't have to sit there arguing with the AI back and forth in a chat box. You can just drag, drop, click, and tweak everything in real-time right on the screen. This kind of frictionless, "use-and-discard" web experience is where the future is heading. It completely wipes out the line between documents and software. AI-generated content isn’t just something you read anymore—it’s something you actually run and control.
1
2
4,321
May 23
Are the AI avatars in your videos like opening a blind box? Here's how to nail character consistency once and for all!
1
2
7
5,094
May 20
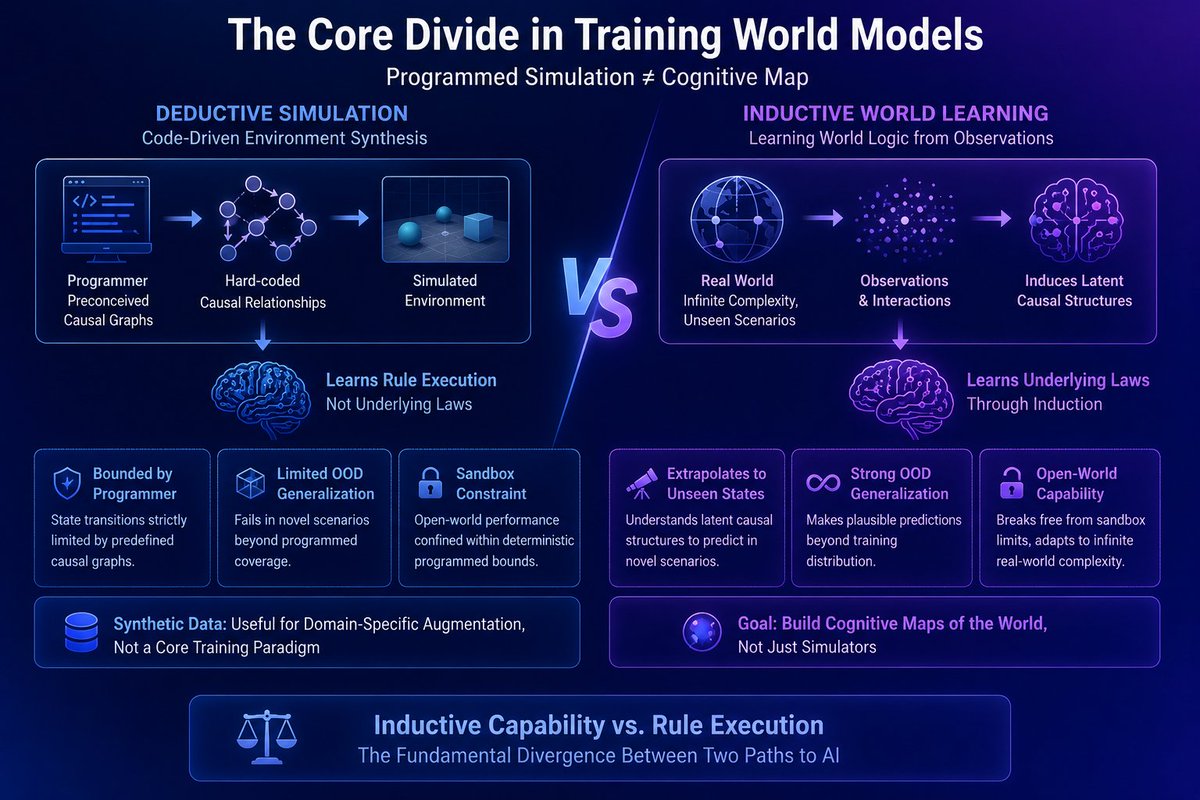
The most profound misconception in training world models lies in the assumption that programmatically simulating an environment equates to enabling the model to learn a cognitive map of the world.
Code-driven environment synthesis, by its very nature, explicitly enumerates causal relationships. The state transitions hard-coded into the simulation are strictly bounded by the programmer's preconceived causal graphs. Consequently, the model merely learns rule execution rather than inducing underlying lawsfrom observational data.
The divergence between these two paradigms is fundamental: the former relies on deductive simulation, whereas the latter demands the inductive learning of world logic.
The intrinsic value of a world model hinges on its capacity for out-of-distribution (OOD) generalization—making plausible predictions in novel scenarios. This necessitates extrapolating to unseen states through an understanding of latent causal structures, rather than memorizing an exhaustive set of predefined rules.
In contrast, the complexity of the real world is infinite, perpetually yielding scenarios that elude programmatic coverage.
While synthetic data is valuable for domain-specific data augmentation, it cannot serve as the core training paradigm. Over-reliance on it inevitably confines the model’s open-world performance within the deterministic bounds of the programmed sandbox.
Inductive capability versus rule execution—this constitutes the fundamental divergence between two entirely distinct trajectories toward artificial intelligence.
1
1
6
6,242
May 19
AI Insights Series: What exactly is a 'World Model'?
1
7
2,971
May 16
1/5 Accepted to ACL as Oral!
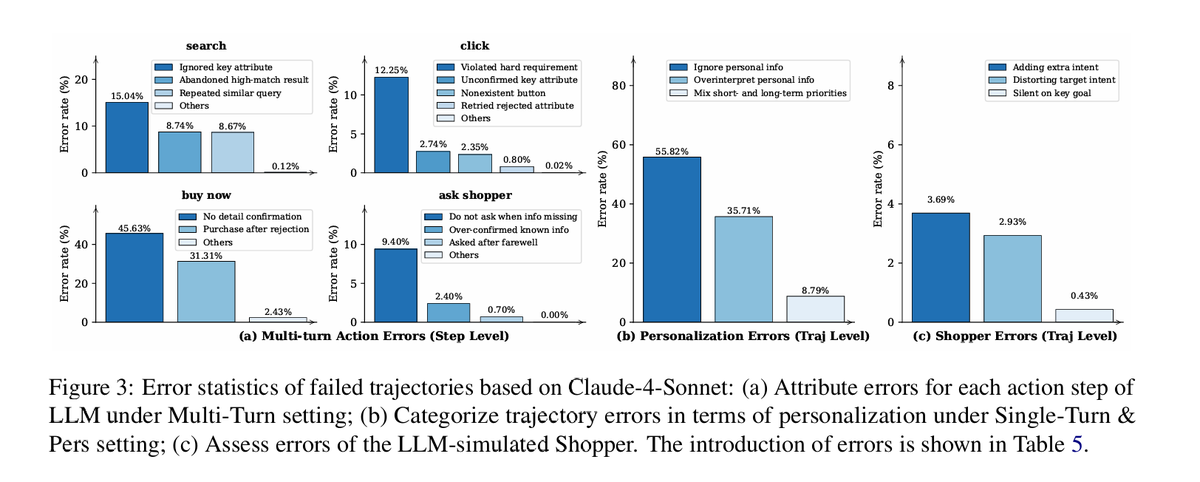
Do we really have qualified "AI Shopping Assistants"?
Today's e-commerce platforms all want large language models to act as personal shopping assistants, but the reality is that AI often fails to understand personalized needs, will not proactively communicate, and is even less able to precisely pick out the right item from a sea of highly similar products.
Previous research (such as WebShop) is mostly based on all-English product data, which does not conform to real Chinese online shopping habits.
More critically, previous simulation environments were mostly one-way evaluation benchmarks used just for testing, lacking fully realistic simulations that include multi-turn dialogues, long-term preferences, and extremely fine-grained product differentiation, nor did they provide training materials or multi-dimensional reward feedback mechanisms to help AI improve its capabilities.

1
6
16,249
May 16
5/5 Rather than just pointing out problems, we have completely open-sourced this sandbox environment along with its code and data.
In this work, we have completed the full loop from environment setup and model capability evaluation to strategy optimization, providing the entire industry with an infrastructure to deeply explore the decision-making capabilities of large models.
A true "personal shopping assistant" can never just be a mechanical search tool. Letting AI learn to understand personalized needs, proactively communicate like a real person, and accurately pick out the correct item for you among a sea of similar products remains a huge chasm that the entire e-commerce AI industry must cross.
And ShopSimulator is exactly the training platform we have paved for everyone; we welcome you all to explore and build truly intelligent shopping assistants together.
1
4
150
May 15
How to maximize AI model performance without changing the architecture?
The core strategy lies in Engineering Efficiency and Numerical Precision Control. Here are the five most dominant optimization schemes in the industry:
1. Quantization: Lowering bit-width precision (e.g., 16-bit to 4-bit) without altering parameter count. This drastically reduces memory footprint and boosts computational throughput.
2. Mixed Precision: Utilizing BF16’s wider dynamic range to prevent numerical overflow while fully leveraging the hardware acceleration (Tensor Cores) on modern GPUs like the H100 or RTX 4090.
3. KV Cache Optimization: Mitigating memory fragmentation through virtual memory management (e.g., PagedAttention) or optimizing memory access patterns (e.g., FlashAttention) to break throughput bottlenecks in long-context processing.
4. Inference Engines (Optimization Runtimes): Utilizing tools like TensorRT for operator fusion and layer merging. This achieves a 2–5x speedup without altering the underlying algorithmic logic.
5. Parallelism & Scheduling: Implementing Continuous Batching to bypass the constraints of static batching. By enabling iteration-level dynamic scheduling, it minimizes idle compute cycles and significantly boosts concurrent throughput.
In Essence:Model optimization is no longer just a mathematical contest; it's a battle for hardware utilization. Mastering these techniques transforms LLMs from costly lab experiments into high-performance, cost-effective production tools.
1
2
6
8,184
May 13
Multimodal AI may not be stuck on training.
It may be stuck on something more basic:
how do we evaluate it with one standard?
Right now, everyone is building models that can both understand and generate.
That sounds great in theory.
But once you try to compare, optimize, or align these models, a hard question shows up:
Can all these abilities be measured with the same ruler?
Understanding and generation both belong to multimodal AI.
But they do not follow the same evaluation logic.
Understanding is usually about recognition, reasoning, and semantic judgment.
Generation is more about quality, detail, consistency, and preference.
The abilities are moving into one system.
But the evaluation standards have not fully merged yet.
And that matters.
Because if we cannot clearly define what “better” means, then training, alignment, filtering, and iteration can easily move in different directions.
It is like running a company with no shared performance system.
One team is judged by analysis.
Another is judged by delivery quality.
The bigger the organization gets, the easier the standards drift apart.
So the next hard problem for multimodal AI may not be simply making the model bigger.
It may be turning evaluation into one shared language.
What do you think matters more next:
stronger multimodal models, or better evaluation systems?
1
7
7,240
May 12
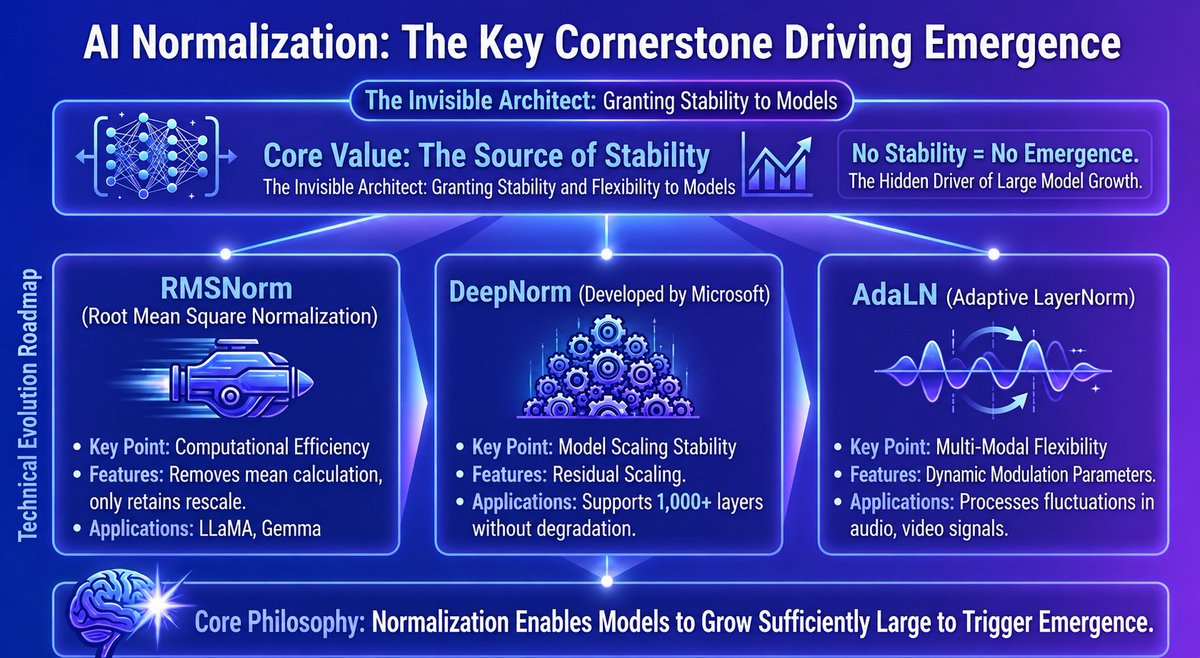
Everyone knows about Attention, but few talk about Normalization.
It is the unsung infrastructure of AI. Like the foundation of a skyscraper: no one notices it, but without it, the building collapses.
In the Transformer era, LayerNorm is the core scheme. It constrains activations to a stable distribution to mitigate training instability. To understand LLM evolution, you must understand this.
In recent years, several more efficient alternatives have emerged:
RMSNorm: A simplified version of LayerNorm. It ditches the complex mean calculation and keeps only the re-scaling. It is significantly faster with no loss in performance. It is currently used in LLaMA, Falcon, and Gemma.
DeepNorm: Proposed by Microsoft to solve the stability issue when scaling Transformers. It acts as a residual scaling mechanism between layers, preventing signal degradation even at 1,000 layers. It pushed the limits of model depth.
Adaptive LayerNorm (AdaLN): Instead of a rigid formula, it dynamically modulates parameters based on input (like audio fluctuations or video flickers). This flexibility makes it much more effective for multimodal tasks.
The takeaway: The "Emergent Abilities" of LLMs are likely tied to the steady training provided by Normalization. It allows models to grow deep and large enough to trigger emergence.
It isn’t the hero, but it makes the hero possible.
5
7,991
May 11
MoE looks great in offline evaluations.
Large total parameters, sparse activation, and on paper, it seems to offer both capability and efficiency at the same time.
But once MoE moves into real online production, the problem is usually not that simple.
In many cases, the bottleneck is not whether there are enough experts.
It is whether the routing is selective enough.
When requests increase and batch sizes get larger, experts that are supposed to be sparsely activated can easily start getting pulled in too broadly.
On the surface, it still looks like MoE.
But in actual inference, it may become less like true on-demand activation and more like a traffic jam.
That is why the hard part of MoE is often not just capacity.
It is whether the system can assign requests to experts intelligently enough.
More experts do not automatically solve the problem.
If each decoding step routes requests too widely, the cost is not only compute.
It also affects bandwidth, latency, and the overall rhythm of inference.
This is a lot like traffic routing during rush hour.
More lanes do not always mean shorter lines.
The key is not simply having more lanes.
The key is sending the right cars to the right lanes.
So the next real competition in MoE may not be about adding more and more experts.
It may be about making routing behave more like true on-demand activation, instead of letting every incoming request pull too many experts into the system.
This is also part of what our lab’s accepted top-conference paper tries to address.
It does not only look at the MoE architecture itself, but further studies routing efficiency during inference, making expert activation more concentrated and more stable, so batch decoding can run more smoothly.
So the real gap in MoE may not come from who has more experts.
It may come from who can route them more accurately, use them more efficiently, and run them faster.
What do you think matters more for the next stage of MoE:
adding more experts, or making routing smarter?
4
1,632
May 10
Alignment may not get better just because we use more data.
Sometimes, more data can actually make the model less stable.
That sounds a bit counterintuitive.
Because the default assumption is simple:
more preference data means the model understands people better.
But preference data is not normal data.
It often comes with noise, conflict, and mixed standards.
The same answer can look good under one preference, and bad under another.
So if we keep adding everything in, we may not be strengthening alignment.
We may just be teaching the model to swing between different signals.
That is why data selection is becoming more important.
The real question may not be:
How much preference data do we have?
It may be:
Which preference data is actually worth keeping?
For alignment, the signal matters more than the pile.
You want data with stronger agreement,less conflict,and cleaner feedback.
It is a bit like a meeting.
More people in the room does not always make the decision clearer.
Sometimes it only makes the room louder.
What helps is not more voices.
It is finding the signals that actually point in the same direction.
So the next alignment race may not be about who has more preference data.
It may be about who is better at choosing the right data.

3
1,739