
Founded in 1979, the GRASP Laboratory is an interdisciplinary academic and research center, and premiere robotics incubator within Penn Engineering.
Joined September 2009
- Tweets 1,917
- Following 541
- Followers 4,930
- Likes 1,174
667 Photos and videos















Jun 12
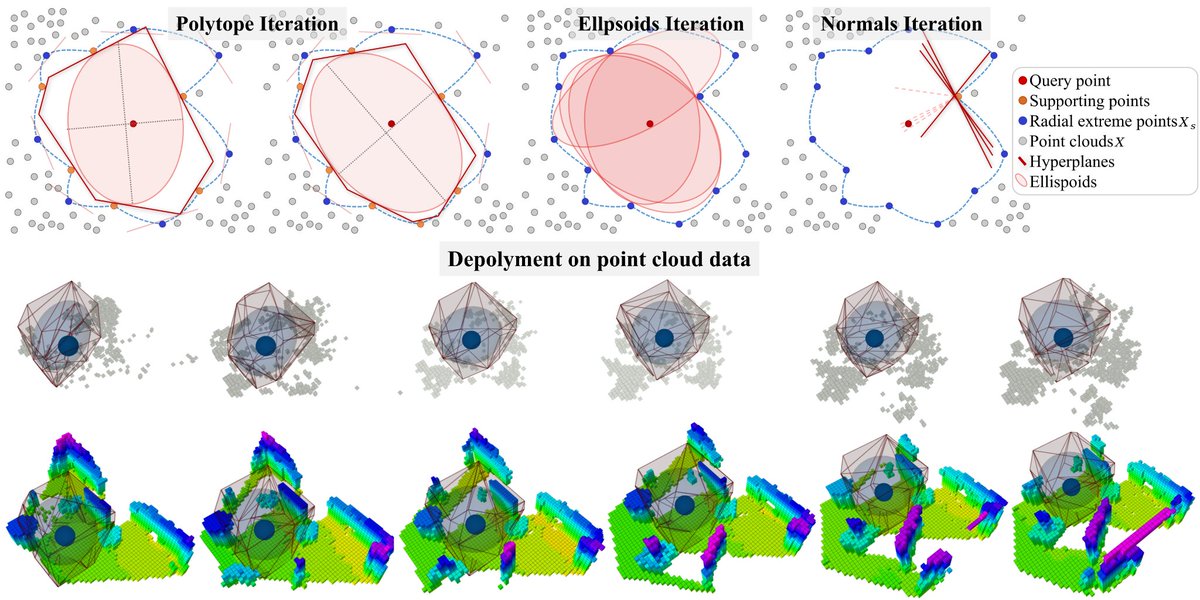
On Monday, GRASP Lab members will be presenting their STAR-Filter paper at WAFR 2026. Read the GRASP Blog Post by co-author Yuwei Wu for more information on the publication!
grasp.upenn.edu/news/geometr…
#GRASP #GRASPLab #WAFR2026
1
2
347
Jun 12
GRASP's Figueroa Lab has created Flow with the Force Field, a framework that generates data from a single human demonstration that can be transferred to real-life robotic tasks.
More info: flow-with-the-force-field.gi…
Video: youtube.com/watch?v=5pOrTL7Q…
#GRASP #GRASPLab #FigueroaLab
4
24
2,006
Jun 11
GRASP's Modlab is developing a steerable needle that can be steered both manually and autonomously, injecting medication directly into the affected tissue. See the link below for more info!
modlabupenn.org/steerable-ta…
#GRASP #GRASPLab #Modlab #SteerableNeedle
1
290

😋From WAM to WPAM: World-Action Models should NOT stop at pixels!
We release PointAction, lifting World Models from RGB to RGB XYZ and using dynamic pointmaps as universal action representations for robot control.
Page: oriontmt.github.io/pointacti…
Paper: arxiv.org/abs/2606.03943
🧐Q: Why not pixels only?
Pixels tell us what changes, but not always how a robot should move in 3D. Learning this mapping from RGB alone often requires massive paired action data, while raw motor commands are embodiment-specific and less transferable across robots.
Our intuition: World-Action Models should model the physical world in the same space where actions take effect — and that space is 3D.
Instead of predicting raw motor commands directly from video, PointAction uses 3D point dynamics as a richer and more robust bridge 🌉:
- they make metric motion, spatial constraints, and contact-relevant geometry explicit;
- they are less tied to a specific robot’s motors;
- they can be extracted from much broader robot video data.
PointAction first learns a general diffusion-based 4D world-action backbone in RGB XYZ space, predicting robot-centric 3D point dynamics, then decodes them into embodiment-specific controls with lightweight action heads.
---
This project is led by @TongMutianTMT (incoming PhD student at @PennCIS @GRASPlab), and @hanjiang00 (talented undergrad who visited my lab last year). Huge congrats to all coauthors @WindStyle1459 and @LingjieLiu1! 🎉
Jun 10

🚀 Excited to share PointAction:
A new Video-Point-Action Model that uses dynamic 3D pointmaps as a universal, geometry-grounded action representation for robot control.
VLA → VAM → ? Lift RGB to RGB XYZ, then decode robot-specific actions.
arxiv.org/abs/2606.03943
[1/6]
2
22
172
79,136
ICRA isn't the only conference GRASP is attending this week. We are also at CVPR 2026!!!
Read this article to see what the GRASP Lab is up to at CVPR!
grasp.upenn.edu/news/grasp-l…
#GRASP #GRASPLab #CVPR2026
1
9
597
CONGRATULATIONS to our GRASP Lab members on receiving BOTH the ICRA 2026 Best Paper Award on Planning and Control AND the Best Conference Paper Award!!!
#GRASP #GRASPLab #ICRA2026 #BestPaper


1
5
48
3,507
Tomorrow afternoon, GRASP Lab members will be presenting Symskill at ICRA 2026 as a finalist for the Best Paper Award on Planning and Control! sites.google.com/view/symski…
#GRASP #GRASPLab #BestPaperAward #ICRA2026
7
55
5,265
GRASP Laboratory retweeted

🏆 A record $50,000 in prizes @MICCAI_Society
The ORena SAVE FOCUS Challenge is one of MICCAI's 2026 lighthouse challenges
Can #AI track foreign objects across an *entire* operation to prevent retained foreign objects?
#MICCAI2026 #SurgicalAI #MedicalImaging #AIforHealth

ALT the OR Arena logo
1
6
10
1,225
Tomorrow, GRASP's DAIR Lab will be presenting Push Anything at ICRA 2026 as a finalist for the Best Paper Award on Robot Manipulation and Locomotion! dairlab.github.io/push-anyth…
#GRASP #GRASPLab #DAIR #DAIRLab
41
4,475
GRASP Laboratory retweeted
Ferrari CEO Benedetto Vigna joins Vijay Kumar in episode 12 of Penn Engineering’s Innovation & Impact podcast to discuss electric vehicles, innovation leadership and balancing new technologies with Ferrari’s legacy of performance and design.
1
3
3
637
May 29
Going to ICRA 2026?
Click here to see where GRASP Lab Members will be on each day of the conference:
grasp.upenn.edu/news/grasp-l…
#GRASP #GRASPLab #GRASPatICRA #ICRA2026
1
2
1,003
May 28
Perception, Action, and Learning (PennPAL) Group researchers developed ZeroMimic, which uses human POV videos to enable zero-shot control across robots in diverse real-world/simulated environments.
Video: youtube.com/watch?v=nFhNSsR7…
Project Page: zeromimic.github.io/
#GRASPLab
1
9
672
May 27
Check out this video project on "Distilling On-device Language Models for Robot Planning with Minimal Human Intervention" from Kumar Lab!
Video: youtu.be/brlBn6-hEpo
Project page: zacravichandran.github.io/PR…
#GRASP #GRASPLab #GRASPProjects
388
GRASP Laboratory retweeted

May 26
Ferrari CEO Benedetto Vigna joins Vijay Kumar on the Penn Engineering podcast to discuss his journey from physicist and semiconductor innovator to leading one of the world’s most iconic automotive brands.
The conversation explores Ferrari’s evolving approach to electrification, digital transformation and high-performance engineering, as well as the importance of pairing deep technical expertise with long-term vision.
youtu.be/XOijfgbLDS0
@PennEngAI
3
1
522
May 22
Check out this article highlighting the exemplary GRASP Lab students recognized by Penn and the Robotics Industry during the 2025-2026 academic year!
grasp.upenn.edu/news/grasp-2…
#GRASP #GRASPLab #GRASPAwards
1
1
324
May 21
Did you know that you can find the GRASP SFI Spring 2026 seminars on the GRASP YouTube Channel? Check out the playlist HERE!
youtube.com/playlist?list=PL…
#GRASP #GRASPLab #GRASPSFI
2
1,378
May 20
Did you miss our GRASP on Robotics 2026 Spring Seminar Series? You can find them in the link below or on our GRASP YouTube page!
youtube.com/playlist?list=PL…
#GRASP #GRASPLab #GRASPYoutube #GRASPSeminars
2
217
May 19
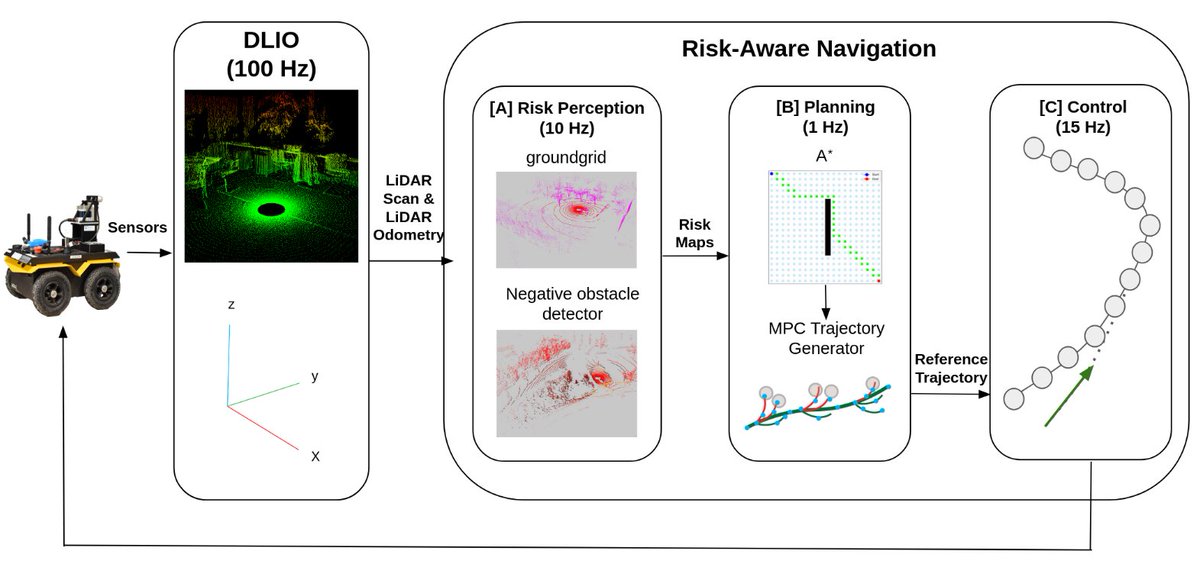
UGVs have been successfully deployed in both academia and industry. Interested? Check out the full project "Risk-Aware MPC Planning for Unmanned Ground Vehicles" from GRASP's Vijay Kumar Lab below!
youtu.be/dU5Egdby3kw
Project Page: frankgon1627.github.io/risk_…
#GRASP #GRASPLab
238
May 18
If you haven't seen it yet, check out the May 2026 ROBOTICS MSE Thesis & Capstone Lightning Talks we recently posted!
youtu.be/ysPYX5aDuu8
More info:
grasp.upenn.edu/events/sprin…
#GRASP #GRASPLab #GRASPLightningTalks
2
316
GRASP Laboratory retweeted
May 17
Congratulations to Penn Engineering's Class of 2026!
In her speech, student speaker Julia Fremberg (ENG’26) drew a parallel between Penn’s interconnected buildings and the vital bonds between students.
"As you move from place to place, from goal to goal, never forget to cherish those in-between moments. The E-Quad tunnels were never just about getting somewhere faster. They were about who you found—and who you became—along the way."
#PennEngineeringProud #PennGrad




1
3
15
901