
La liberté, c'est comme l’intelligence, on croit en avoir tant qu’on n’a pas reconnu l’étendue de sa propre connerie.
Joined March 2019
- Tweets 61,885
- Following 1,224
- Followers 885
- Likes 92,101
10,485 Photos and videos















Pinned Tweet

16 Sep 2025
5
2,847
Jun 13
Le en même temps de la macronie quoiqu'il en coûte :
Jun 13

🇵🇸🇮🇱🇫🇷FLASH INFO - « Il y a désormais un cessez-le-feu à Gaza, certes imparfait, certes violé constamment, mais qui existe. » lance Jean Noel Barrot
C’est le premier homme de l’histoire à annoncer une bonne nouvelle et à la démentir dans la même phrase..
2
1
4
41
GUIGUI retweeted

Jun 12
le fait que tous les médias nous cassent les couilles h24 avec les "frères musulmans" mais n'ont rien à dire là dessus

Donc c’est confirmé par Viginum. BlackCore, société israélienne, a manipulé l'information contre la France insoumise lors des municipales.
Ceux qui donnent en permanence des leçons de “république” devraient commencer par défendre la souveraineté démocratique.
29
3,187
11,642
163,070
Jun 11
Aujourd'hui, Tristan écrit a Spielberg pour lui expliquer que son film est complotiste.
Comment je suis content d'être moi quand je vois ça..


5
11
200
GUIGUI retweeted

Le débat scientifique est verrouillé. Acculé sur la méthodologie de son papier, Lonni Besançon a délégué sa défense à une IA. Résultat ?
x.com/lonnibesancon/status/2…

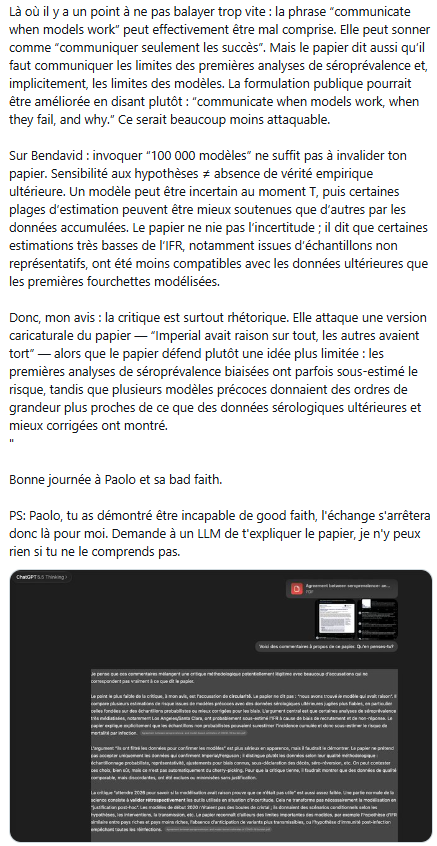

Parce que j'ai la flemme d'éduquer des gens qui font du bad faith, j'ai donné le papier (doi.org/10.1080/16549716.202…) et le thread de Paolo Bad-Faith El pulpo (que j'avais qualifié de mauvaise représentation de l'article avant) à ChatGPT 5.5 Thinking avec la question suivante: "Voici des commentaires à propos de ce papier. Qu'en penses-tu?"
Pourquoi j'ai fait ça? Parce que je ne peux pas perdre du temps à répondre à tous les bad-faith actors qui défendent l'IHU et toutes ses dérivent depuis des années. J'ai un boulot... j'ai expliqué à Paolo qu'il faisait dire au papier ce qu'il ne dit pas. Il m'a dit de le démontrer alors que c'est à lui de démontrer au départ ce qu'il avance sur le papier... bref la flemme de débattre avec une personne incapable d'être good-faith et de lire un article. Je joins après la réponse de ChatGPT un screen de ma query pour prouver que je n'ai pas prompt plus que ça.
Voici la réponse:
"
Je pense que ces commentaires mélangent une critique méthodologique potentiellement légitime avec beaucoup d’accusations qui ne correspondent pas vraiment à ce que dit le papier.
Le point le plus faible de la critique, à mon avis, est l’accusation de circularité. Le papier ne dit pas : “nous avons trouvé le modèle qui avait raison”. Il compare plusieurs estimations de risque issues de modèles précoces avec des données sérologiques ultérieures jugées plus fiables, en particulier celles fondées sur des échantillons probabilistes ou mieux corrigées pour les biais. L’argument central est que certaines analyses de séroprévalence très médiatisées, notamment Los Angeles/Santa Clara, ont probablement sous-estimé l’IFR à cause de biais de recrutement et de non-réponse. Le papier explique explicitement que les échantillons non probabilistes pouvaient surestimer l’incidence cumulée et donc sous-estimer le risque de mortalité par infection.
L’argument “ils ont filtré les données pour confirmer les modèles” est plus sérieux en apparence, mais il faudrait le démontrer. Le papier ne prétend pas accepter uniquement les données qui confirment Imperial/Ferguson ; il distingue plutôt les données selon leur qualité méthodologique : échantillonnage probabiliste, représentativité, ajustements pour biais connus, sous-déclaration des décès, séro-réversion, etc. On peut contester ces choix, bien sûr, mais ce n’est pas automatiquement du cherry-picking. Pour que la critique tienne, il faudrait montrer que des données de qualité comparable, mais discordantes, ont été exclues ou minimisées sans justification.
La critique “attendre 2026 pour savoir si la modélisation avait raison prouve que ce n’était pas utile” est aussi assez faible. Une partie normale de la science consiste à valider rétrospectivement les outils utilisés en situation d’incertitude. Cela ne transforme pas nécessairement la modélisation en “justification post-hoc”. Les modèles de début 2020 n’étaient pas des boules de cristal ; ils donnaient des scénarios conditionnels selon les hypothèses, les interventions, la transmission, etc. Le papier reconnaît d’ailleurs des limites importantes des modèles, par exemple l’hypothèse d’IFR similaire entre pays riches et pays moins riches, l’absence d’anticipation de variants plus transmissibles, ou l’hypothèse d’immunité post-infection empêchant toutes les réinfections.
Là où il y a un point à ne pas balayer trop vite : la phrase “communicate when models work” peut effectivement être mal comprise. Elle peut sonner comme “communiquer seulement les succès”. Mais le papier dit aussi qu’il faut communiquer les limites des premières analyses de séroprévalence et, implicitement, les limites des modèles. La formulation publique pourrait être améliorée en disant plutôt : “communicate when models work, when they fail, and why.” Ce serait beaucoup moins attaquable.
Sur Bendavid : invoquer “100 000 modèles” ne suffit pas à invalider ton papier. Sensibilité aux hypothèses ≠ absence de vérité empirique ultérieure. Un modèle peut être incertain au moment T, puis certaines plages d’estimation peuvent être mieux soutenues que d’autres par les données accumulées. Le papier ne nie pas l’incertitude ; il dit que certaines estimations très basses de l’IFR, notamment issues d’échantillons non représentatifs, ont été moins compatibles avec les données ultérieures que les premières fourchettes modélisées.
Donc, mon avis : la critique est surtout rhétorique. Elle attaque une version caricaturale du papier — “Imperial avait raison sur tout, les autres avaient tort” — alors que le papier défend plutôt une idée plus limitée : les premières analyses de séroprévalence biaisées ont parfois sous-estimé le risque, tandis que plusieurs modèles précoces donnaient des ordres de grandeur plus proches de ce que des données sérologiques ultérieures et mieux corrigées ont montré.
"
Bonne journée à Paolo et sa bad faith.
PS: Paolo, tu as démontré être incapable de good faith, l'échange s'arrêtera donc là pour moi. Demande à un LLM de t'expliquer le papier, je n'y peux rien si tu ne le comprends pas.

2
3
9
923
Jun 10
Le but est de contenir la masse, pas de la protéger, mais de s'en proteger.. Comme pour la santé, le pouvoir met les moyens dans son maintient.
Avec votre pognon, et ça 'est beau. Tiens!? Quel est le parti de l'ordre qui réclame la reconnaissance faciale ?
Jun 10

"policière spécialisée dans les violences sur mineurs"
C'est pas les mêmes flics.
1800 flics pour tout le pays sur 250 000 gendarmes et policiers.
6
53
Jun 10
RT @Manouck44: "L’impunité dont Israël bénéficie de la part de la communauté internationale a conduit à une réalité où, sous la domination…
123
GUIGUI retweeted

Jun 9
Ce n'est pas lui qui a fait fuiter des éléments de la garde à vue de Rima Hassan ? Il est toujours en poste et ose parler d'impunité ?

"Les gens ont l'impression qu'il y a une forme d'impunité des magistrats", regrette Sacha Straub-Kahn, magistrat et porte-parole du ministère de la Justice
#ForumBFMTV
25
1,658
7,051
95,511

Jun 8
C'est une blague?

⚡️🇫🇷FLASH -L’ex-préfet Didier #Lallement est invité ce soir au lancement du nouveau think tank du #PS, provoquant de vives critiques internes. Dans une lettre, des militants dénoncent la venue de celui qu’ils considèrent comme le symbole de «la dérive autoritaire de la macronie».

1
2
4
70
Jun 8
Depuis la " crise Covid" les vignerons ne s'en sortent plus, pour les aider, on leur donne 4000€ par hectare de vigne arraché. Pourquoi ne pas leur donner directement l'argent pour conserver leur production?
Si quelqu'un comprend cette logique, je veux bien qu'on m'explique.
2
2
38
Jun 8
X ce matin, le smic à 1700, nan mais ça va pas!? Jordan tro bo Avé la gourdasse milliardaire🤩

🚨La princesse et le président du Rassemblement ont officialisé leur relation dans les tribunes VIP du Grand Prix de Monaco. Là même où ils se sont rencontrés il y a un an.

4
1
6
203
Jun 7
C'est rétroactif ?

Jun 7

N’en déplaise à M. Mélenchon, nous assumons de supprimer le droit du sol, qui n’a aucune justification à l’heure des grandes pressions migratoires.
Ce sera l’une des mesures principales contenues dans notre référendum pour que le peuple français reprenne le contrôle de sa politique migratoire.
1
118
GUIGUI retweeted
Jun 6
En somme, ce texte applique à Edgar Morin tout ce qu'il a combattu toute sa vie : le réductionnisme, la polarisation et le refus de la nuance. La caricature de Caroline Fourest ne prouve qu'une chose : la pensée complexe de Morin reste plus que jamais nécessaire.
7
26
147
2,826
Jun 6
Est ce que le double c'est mieux? Les hypocrites droitardés qui veulent payer les stagiaires au smic mais sont contre l'augmentation de celui-ci, ça va la mauvaise foi?

Jun 6
Un stagiaire c'est 4,50€/ hr fais ton calcul et compare.
1
2
169
GUIGUI retweeted

Jun 4
🔴 Less than a week after Israel burned several preteen children to death in their tents, four more residential apartments were set ablaze overnight, with Israel’s military burning entire families to death as they slept.
The strikes hit homes in Al-Shati refugee camp, the Karama neighborhood, Tel al-Hawa, and Sheikh Radwan in Gaza City.
Jun 4

🚨 Shortly after midnight, Israeli helicopter gunships launched coordinated strikes on residential buildings across Gaza City, killing at least 8–9 Palestinians and wounding several others, according to journalists on the ground.
Five people were reported killed when an apartment belonging to the Labad family on Intelligence Street in northwest Gaza City was struck. Additional attacks hit Al-Salam Tower in Tel al-Hawa, the Mahna family home near Al-Qouqa Roundabout in Al-Shati refugee camp, and a residential apartment in the Abu al-Amin and Abu Iskandar area of Sheikh Radwan.
Local reporters say many of the targeted buildings were sheltering displaced families, with rescue crews continuing to search the rubble for survivors.
150
3,524
4,998
627,382
GUIGUI retweeted

Jun 5
Je me répète mais lisez ça : Darmanin est responsable et doit démissionner !!! #Lyhanna
Un député avait alerté Darmanin en 2025 sur les défaillances du Parquet du Gers en raison de moyens insuffisants et les conséquences graves sur la protection des enfants!!!
Partagez !!


96
5,218
9,423
113,616
GUIGUI retweeted

Jun 5
L’ambassadeur d’Israël en France ment systématiquement aux Français et Françaises dans le seul but de couvrir les crimes israéliens. Il avait nié toute implication d’Israël dans la destruction du couvent de Yaroun au Liban, il est même allé jusqu’à cibler des journalistes qui avaient relayé cette information.
177
1,468
4,114
60,601