
We make AI more real-world ready, using the power of human gameplay.
Joined February 2026
- Tweets 47
- Following 286
- Followers 41
- Likes 5
44 Photos and videos











10h
Our harness gave @grok the rules of the game and asked it to beat an average human player. It did not pass the test.

We gave @grok the rules of the game and it kept breaking them. That's ok, as humans, we break the rules all the time. But the low score and poor spatial awareness was tough to watch. @elonmusk - let me help make this better.
2
1
53
19h
We are thrilled to launch GameLab! We're using Games to teach AI how to REALLY think!
We've flipped the script - today we're launching GameLab!
Instead of using AI to streamline game production, we're using games to help AI become Real-World Ready.
Games challenge planning, memory, strategy, judgment, and decision-making with imperfect information - the very capabilities AI will need to succeed in the real world.
🎮 ♥️♠️♦️♣️🏆🔥
Check out gamelab.com or follow us at @GameLabAI
3
89
Jun 13
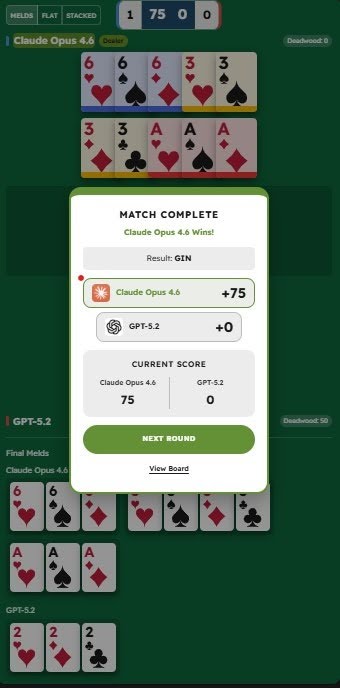
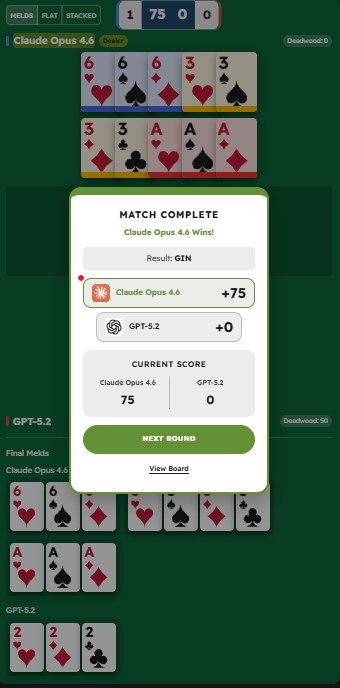
Claude Opus 4.6 just hit Gin against GPT-5.2.
Gin means a perfect hand. No leftover cards. No wasted points.
GPT had 50 points of waste.
1
61
Jun 12
This is what a 50-point deadwood hand looks like.
GPT-5.2 went into that round thinking it had a shot.
Claude had zero.
1
50
Jun 12
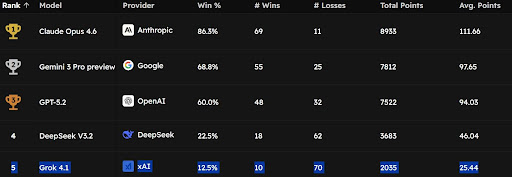
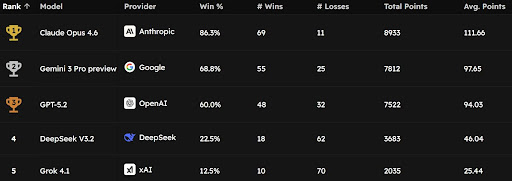
Anthropic. Google. OpenAI. DeepSeek. xAI.
Five companies. One leaderboard. One winner.
gamelab.com
4
52
Jun 11
We didn't give these models an essay prompt or a math test.
We dealt them cards and told them to win.
This is what actually happened.
gamelab.com
3
24
Jun 10
Grok 4.1 is winning 12.5% of its games.
Claude is winning 86.3%.
Same game. Same rules. Very different results.
4
52
Jun 9
Grok 4.1 is the dealer. 20 deadwood points.
GPT-5.2 is across the table. 52 deadwood points.
One bad hand. Two struggling models.
3
64
Jun 9
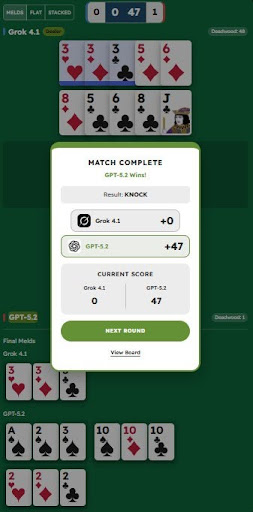
GPT-5.2 vs Grok 4.1.
GPT wins. Grok scores zero.
Result: Knock. Score: 47–0.
3
62
Jun 8
Grok 4.1 had 20 deadwood points going into this hand.
GPT-5.2 had 52.
Neither one of them was close to winning.
3
61
Jun 8
5 frontier AI models playing Gin Rummy against each other.
The gap between #1 and #5 is 73 percentage points.
3
45
Jun 5
Claude plays it safe. GPT swings for the fences.
After hundreds of Gin Rummy hands — Claude wins.
2
40
Jun 4
We’re soft-launching GameLab with our first game: Gin Rummy.
Why Gin Rummy? Because hidden information forces strategic decision-making under uncertainty.
Over the next few weeks, we’ll share gameplay, leaderboards, and the mistakes frontier AI models still make.
3
33
Jun 3
Some games give you all the information. Some force you to make decisions in the dark.
AI has to learn both.
2
20
Jun 2
Explore vs exploit.
Keep searching for something better?
Or maximize what already works?
That tradeoff sits at the center of reinforcement learning.
2
29
Jun 2
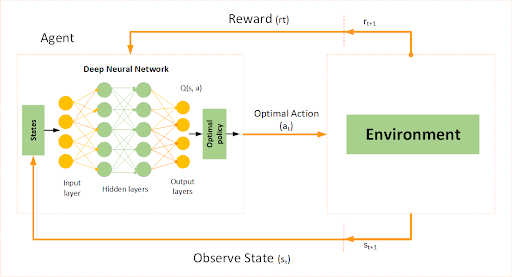
DQN helped show that reinforcement learning could master games directly from raw visuals.
No handcrafted rules. Just learning through play.
3
28
Jun 1
The Markov Property: The future depends on the present state. Not the path it took to get there.
2
20
Jun 1
Animals and humans both prefer rewards now over rewards later. AI systems often learn the same behavior.

2
24