
exploring latent space
Joined September 2011
- Tweets 258
- Following 1,066
- Followers 75
- Likes 1,905
Photos and videos

May 9
استخدم هذه الطريقة جدا بالفترة الأخيرة وكما قال @karpathy سابقا
"UI is 10-lane highway into the brain"
- داشبورد للخط الاسبوعية (ملف حي)
- لقراءة الخطط والملفات الطولية
- تنسيق التقارير وتحويلها الPDF
- فعليا اي ملف مهم اريد التركيز بقراءته
استخدم كلود لتوليد والتعديل على HTML. حتى اني نزلت اضافة html reader ل obsidian
بالنسبة لي هذه الطريقة هي اول تطبيق حقيقي لل Generative UI

1
93

Ghaith retweeted

Mar 31
⚠️ Supply chain attack in progress: someone is squatting Anthropic-internal npm package names targeting people trying to compile the leaked Claude Code source.
`color-diff-napi` and `modifiers-napi` — both registered today, same person, disposable email. Do NOT install them. 🧵
38
375
2,190
306,806
Mar 13
I figured out how to fix X algo when it stops showing related posts and starts showing trash.
Just scroll, and when you see a related post, hit share then copy link (this will signal high interest in this post to the ago). Do this for ~5 posts and it’s fixed.
1
1
74
16 May 2025
This high quality content will make you subscribe to his courses, highly recommended

Reasoning LLMs Guide [Full Video - Unedited]
1 hr talk on reasoning LLMs and how to best use them for different applications.
Share with your devs & students.
I discuss lots of fun ideas like meta-prompting, LLM-as-a-Judge, use cases, prompting tips, and much more.
164
Ghaith retweeted

12 Sep 2024
First summary about OpenAI-01
After reading the publications of OpenAI, I first summarize the essential aspects, followed by a summary
- immensely better reasoning about complex problems
- the model will become "regular updates and improvements"
- Through training, they learn to refine their thinking process, try different strategies, and recognize their mistakes
- performs similarly to PhD students on challenging benchmark tasks in physics, chemistry, and biology
- excels in math and coding
- International Mathematics Olympiad (IMO)83% (I'll have to look up the results of AlphaGeometry2 and AlphaProof again to compare them)
- they are resetting the counter back to 1 and naming this series OpenAI o1 (apparently no more ChatGPT, but with OpenAI 01 the new beginning of a model)
- Very well developed against jailbreaks
- Close cooperation with the authorities (we’ve bolstered our safety work, internal governance, and federal government collaboration)
- it uses Chain of Thought (CoT)
- performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute).
---
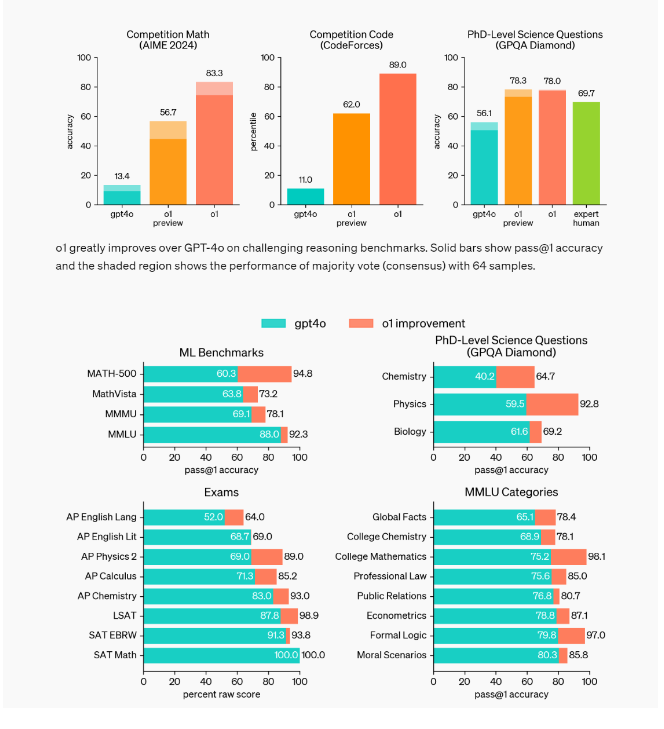
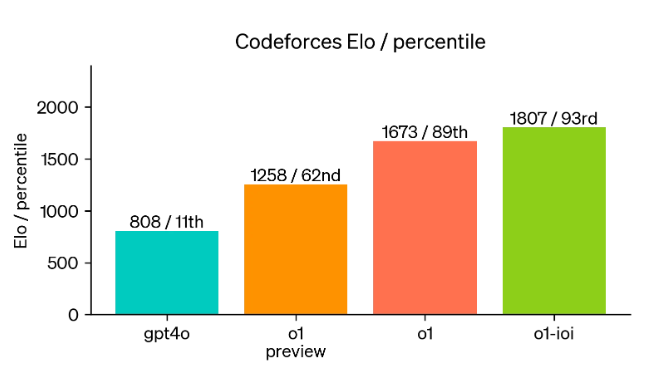
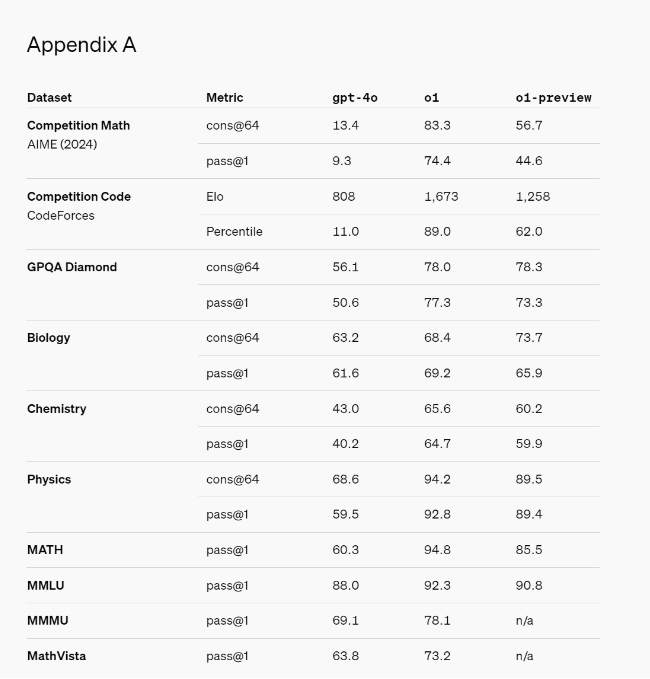
OpenAI has actually made it. Below you can see the benchmark results. It is exactly as hoped: OpenAI-01 excels especially in the areas where regular LLMs basically reach their limits. Especially logical tasks. Through the use of CoT and presumably aspects of self-learning, the model is able to achieve outstanding results through constant self-correction. The benchmarks show a quantum leap compared to ChatGPT-4o. It is not a small improvement but a milestone. You can't overstate how groundbreaking the results are. We actually have a model that has reached the level of PhD experts in STEM subjects. In coding Olympiads, it reaches an unprecedented ELO of 1807 and also the 93 percentile:
"Finally, we simulated competitive programming contests hosted by Codeforces to demonstrate this model’s coding skill. Our evaluations closely matched competition rules and allowed for 10 submissions. GPT-4o achieved an Elo rating[3] of 808, which is in the 11th percentile of human competitors. This model far exceeded both GPT-4o and o1—it achieved an Elo rating of 1807, performing better than 93% of competitors."
The models are constantly being improved and further developed. At this rate, we can assume that we will perhaps really reach AGI by 2025. Certainly not available to everyone, but probably possible as an application. The impact on the economy and fields of work is not foreseeable.
"o1 significantly advances the state-of-the-art in AI reasoning. We plan to release improved versions of this model as we continue iterating. We expect these new reasoning capabilities will improve our ability to align models to human values and principles. We believe o1 – and its successors – will unlock many new use cases for AI in science, coding, math, and related fields. We are excited for users and API developers to discover how it can improve their daily work. (...) We also evaluated o1 on GPQA diamond, a difficult intelligence benchmark which tests for expertise in chemistry, physics and biology. In order to compare models to humans, we recruited experts with PhDs to answer GPQA-diamond questions. We found that o1 surpassed the performance of those human experts, becoming the first model to do so on this benchmark. These results do not imply that o1 is more capable than a PhD in all respects — only that the model is more proficient in solving some problems that a PhD would be expected to solve. On several other ML benchmarks, o1 improved over the state-of-the-art. With its vision perception capabilities enabled, o1 scored 78.2% on MMMU, making it the first model to be competitive with human experts. It also outperformed GPT-4o on 54 out of 57 MMLU subcategories."
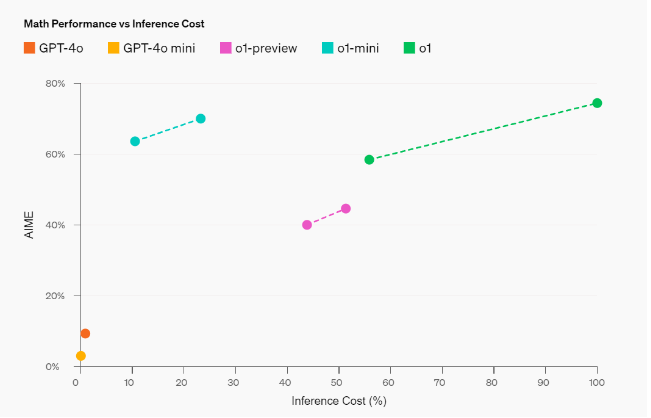
But what is at least as significant is the fact that OpenAI has directly released a mini version of 01 that is about 80% cheaper but still significantly better than GPT-4o and only slightly worse than the regular OpenAI-01! This should not be underestimated, as it means that this outstanding model can be used everywhere at low cost (benchmark results also below).
"OpenAI o1-mini, a cost-efficient reasoning model. o1-mini excels at STEM, especially math and coding—nearly matching the performance of [OpenAI o1] on evaluation benchmarks such as AIME and Codeforces.
Today, we are launching o1-mini to [tier 5 API users(opens in a new window)] at a cost that is 80% cheaper than OpenAI o1-preview."
I think there will be a time before OpenAI-01 and a time after OpenAI-01. What we have seen today is nothing less than a break in history. Numbers don't lie and OpenAI-01 shows how good it already is. It will change the world. OpenAI has delivered. It's a day to celebrate.
51
129
681
71,842
Ghaith retweeted

5 Sep 2024
AI is incredible at writing code.
But that's not enough to create software. You need to set up a dev environment, install packages, configure DB, and, if lucky, deploy.
It's time to automate all this.
Announcing Replit Agent in early access—available today for subscribers:
608
1,181
8,986
3,335,182
Ghaith retweeted

19 Aug 2024
What can an 8-year-old build in 45 minutes with the assistance of AI?
My daughter has been learning to code with @cursor_ai and it's mind-blowing🤯
Here are highlights from her second coding session. In 45 minutes she built a chatbot powered by @CloudflareDev Workers AI 👀
440
1,539
10,270
2,768,373
Ghaith retweeted

13 Aug 2024
محمد أبو القمصان ذهب لاستخراج شهادتي ميلاد لابناءه التوأم (أسير وأيسل) وعندما رجع وجدهما قد استشهدا مع أمّهما وجدتهما بعد قصف الكيان للمنزل، فذهب واستخرج شهادتي وفاة لهما.
يا الله…من يقوى على تحمل ذلك؟!
#علم_نافع


52
370
1,138
19,796
Ghaith retweeted

31 Jul 2024
#استشهاد_اسماعيل_هنية ليلتحق بأكثر من ٦٠ شخصا من أقاربه، رحمه الله وتقبله في الصالحين.
قبله قتلت إسرائيل قادة كثر ؛ أحمد يسن والرنتيسي وفتحي الشقاقي واغتالت بالسم ياسر عرفات وكثير من قادة المقاومة وعشرات الآلاف من أبناء الشعب الفلسطيني ، لكن المقاومة لم تتوقف بل انتقلت الشعلة عبر الأجيال. يزداد الاحتلال غطرسة وجنونا ويضرب في كل اتجاه، لكن حقيقة واحدة ستبقى : لا مستقبل لهذا الاحتلال مهما فعل إلا أن يرحل.
115
886
3,885
248,437
Ghaith retweeted

13 May 2024
This demo is insane.
A student shares their iPad screen with the new ChatGPT GPT-4o, and the AI speaks with them and helps them learn in *realtime*.
Imagine giving this to every student in the world.
The future is so, so bright.
1,417
7,964
43,824
10,927,704
Ghaith retweeted

30 Dec 2023
كان عامنا في نماء الشرق مليئاً بالتحديات والمسؤوليات والصعوبات، ومليئاً أيضاً بالضحكات والذكريات التي لا تٌنسى. لقد كان عاماً مليئاً بالإنجازات!
من أسرة نماء الشرق، كل عام وأنتم بألف خير. 💫
- رابط المدونة : bit.ly/3NPzXdB

2
6
166
Ghaith retweeted

1 Nov 2023
My new course, Generative AI for Everyone, is now available!
Learn how Generative AI works, how to use it in professional or personal settings, and how it will affect jobs, businesses and society. This course is accessible to everyone, and assumes no prior coding or AI experience.
Please access it here: deeplearning.ai/courses/gene…
275
1,488
7,169
1,903,160
18 Oct 2023
"A wide range of AI tasks that used to take 5 years and a research team to accomplish in 2013, now just require API docs and a spare afternoon in 2023." @swyx
The Rise of the AI Engineer
latent.space/p/ai-engineer
1
46

The Dawn of LMMs
Analysis of GPT-4V to deepen the understanding of large multimodal models (LMMs).
It focuses on probing GPT-4V across various application scenarios.
150 pages of examples ranging from code capabilities with vision to retrieval-augmented LMMs.
"The findings reveal its remarkable capabilities, some of which have not been investigated or demonstrated in existing approaches."
arxiv.org/abs/2309.17421

5
117
515
89,320
15 Sep 2023
A dream becoming true

v0 by Vercel Labs
Generate UI with simple text prompts. Copy, paste, ship.
Explore the prompt library and join the waitlist today.
v0.dev
3
75

This is the way to unlock the next trillion high-quality tokens, currently frozen in textbook pixels that are not LLM-ready.
Nougat: an open-source OCR model that accurately scans books with heavy math/scientific notations. It's ages ahead of other open OCR options. Meta is doing extraordinary open-source AI, sometimes without as much fanfare as Llama.
My first serious AI research project (back @Columbia, 2012) was to convert chemical engineering PDFs into NLP-ready corpus. I still remember the immense pain of Tesseract, a much older OCR system (github.com/tesseract-ocr/tes…).
Now Nougat runs a powerful Swin Transformer backbone and blows the benchmarks out of the water. We're talking about double-digit improvements across all metrics.
Now, textbooks are all we need for the next GPT!
Website: facebookresearch.github.io/n…
Open-source code: github.com/facebookresearch/…
Paper "Nougat: Neural Optical Understanding for Academic Documents": arxiv.org/abs/2308.13418

117
738
3,875
1,088,831