
PhD @ University of Toronto soon graduating. I work on controllable video generation & world models inspired by Bayesian Brain Theory. Open to AI/ML roles!
Joined March 2018
- Tweets 143
- Following 1,600
- Followers 347
- Likes 1,857
5 Photos and videos






Dropping an exciting new demo of MosaicMem! 👀🔥
A friend brought up a great question:
why not combine long-horizon navigation video generation, promptable world events, and scene concatenation?
Fair point — so we gave it a shot. 🎬✨
For more technical details, check this thread 🧵👇
x.com/GnosisYu/status/203502…
#WorldModel #GenerativeAI #VideoGeneration #InteractiveAI #Genie3 #EmbodiedAI #GameAI

World models have made impressive progress in video generation, yet they still struggle with a fundamental challenge: memory. In long rollouts, the camera trajectory gradually drifts from the user-specified motion and revisited scenes no longer align with earlier observations. These errors accumulate over time, causing the generated world to steadily lose coherence.
🚀Excited to share our solution MosaicMem 🌍🧠 — our new hybrid spatial memory for video world models.
Project Page: mosaicmem.github.io/mosaicme…
Paper: huggingface.co/papers/2603.1…
21
107
8,599
Wei Yu retweeted

Jun 2
I’m very excited to share that my very first Ph.D project, Policy-based Foveated Imaging and Perception, will be presented at #SIGGRAPH2026!
Intelligent sensing transcends passive capture. Our framework allows ultra-high-resolution sensors to intelligently allocate acquisition bandwidth, perceiving the blooming present and awakening the vivid past. We further demo our framework on a physical 200MP sensor prototype real-time with only laptop CPU!
I’m extremely grateful for the advice and support from my Ph.D advisor @GordonWetzstein, and for the wonderful collaboration with @jan_on_x and @boyang_deng!
Please check out our paper and our website 📷 👁️: howardxiao.ca/foveated/.

The era of ultra-high-resolution imaging has arrived. Modern image sensors exceeding 200 MP resolution are common in smartphones, with over 400 MP sensors under development. However, the large number of pixels poses significant challenges for acquisition and processing, especially on edge devices.
Which pixels should be acquired, and when, for bandwidth-efficient imaging and perception?
We introduce Policy-based Foveated Imaging and Perception, an on-device, real-time, predictive, and task-aware framework that dynamically allocates sensor resolution to prioritize important regions under specific perception objectives. This paper will be presented at #SIGGRAPH2026!
[1/6]
6
4
33
3,750
Wei Yu retweeted

May 26
Exciting to share our work "Good Token Hunting" 🔍 (Yes, the name is inspired by the classic movie "Good Will Hunting" 🎬!), which focuses on accelerating visual geometry transformers 🚀 by limiting the number of keys/values each query can attend in global attention layers. [1/6]
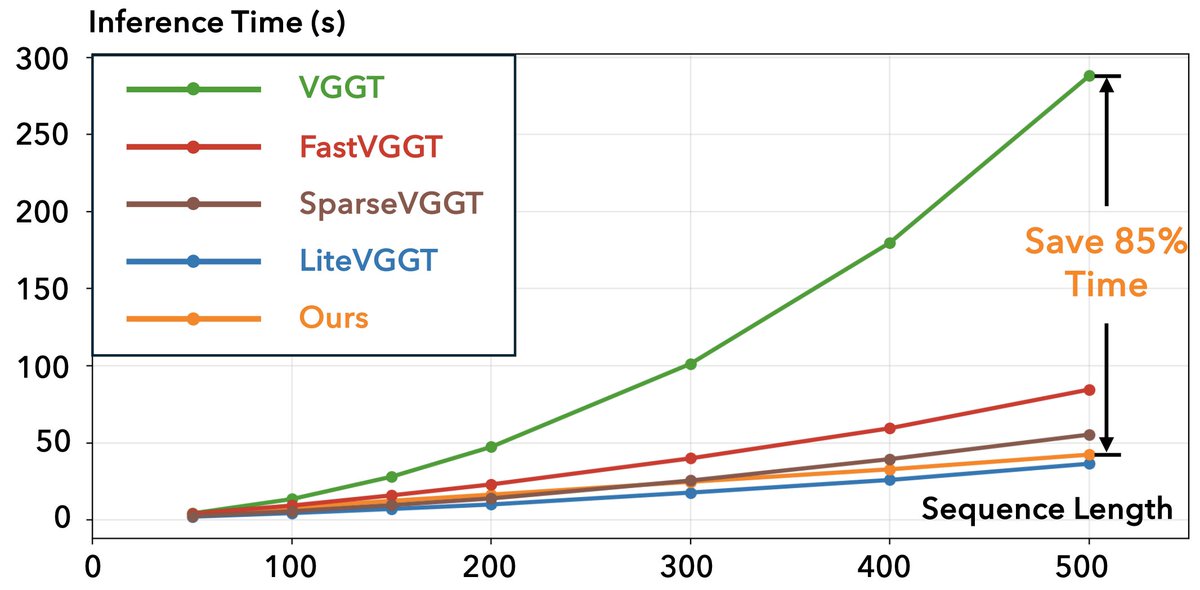
1
8
27
16,738
Wei Yu retweeted

May 26
The latent-vs-pixel debate misses the point.
GPT Image 2 shows what users notice: pixel-level fidelity.
Latent models show what scales: compact semantic structure.
We connect them by replacing VAE/RAE decoders with a Pixel Diffusion Decoder.
Code and Model available: research.nvidia.com/labs/sil…
🧵(1/N)
16
69
411
668,473
Wei Yu retweeted

May 22
🚀 🚀 🚀 Excited to share our new paper:
Remember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
What does it take for an agent to stay curious in a 3D world?
The answer is memory.
🌐 Project: recuriosity.github.io/
📄 Paper: arxiv.org/abs/2605.22814
💻 Code: github.com/recuriosity/recur…
2
41
220
70,165

Wei Yu retweeted

May 18
Meet our new friend, Starchild-1 ❤️
Starchild-1 is the first ever real-time multimodal world model.
A world model understands and simulates the world. Starchild-1 has learned to generate not just the visuals of the world, but the sounds of it too!
63
73
780
120,717
Wei Yu retweeted

May 15
New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers
65
285
2,707
687,330

🤩Excited to share SANA-WM: a 2.6B open-source world model for minute-scale 720p video generation.
Given one image text a 6-DoF camera trajectory, it synthesizes action-controllable 60s worlds on a single GPU.
Project: nvlabs.github.io/Sana/WM/
Paper: huggingface.co/papers/2605.1…
27
143
1,038
121,933

Meet LA-Pose. Our latest model taking Wayve another step towards generalization at scale.
LA-Pose employs large-scale self-supervised learning, building strong motion representations for 3D perception from 10.2 million unlabeled driving video snippets, unlike today's strongest approaches that often depend on expensive, carefully curated 3D supervision.
With only a lightweight pose head and limited labelled data, LA-Pose achieves:
📷 State-of-the-art camera pose estimation
🌎 Strong zero-shot generalization across diverse driving scenarios
🏷️ Orders of magnitude less labelled data than fully supervised 3D approaches
Our full blog post: wayve.ai/thinking/la-pose/
Explore the full paper here: la-pose.github.io/
1
37
146
36,438

We're taking our first step towards democratizing World Models, so that everyone can build on this incredible technology.
We have more to share, but enjoy a glimpse of what's to come, today.
Try it here: reactor.inc
42
62
797
1,407,608
Wei Yu retweeted

Apr 30
Excited to share that this work has been accepted to #ICML and the code is now publicly available at github.com/nv-tlabs/tttla!
Feb 25

Continual learning and online adaptation are often framed as the next frontier of AI. 🚀
Modern architectures use Test-Time Training (TTT) to memorize key-value pairs on the fly via gradient descent, or so we thought.
To test this memorization hypothesis, we replaced gradient descent with gradient ASCENT. It should destroy memorization.
Instead... performance was preserved, or even slightly improved. 😱
It turns out, TTT with KV Binding is secretly linear attention!
Site: research.nvidia.com/labs/sil…

1
2
43
7,059
Wei Yu retweeted

What if your robot could understand any object you describe, just from a phone camera?
RADIO-ViPE builds a 3D map from raw monocular video that you can query with natural language.
(1/4)
11
49
423
61,128
Wei Yu retweeted

Jan 20
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 research.nvidia.com/labs/sil…
1/10
11
120
584
110,610

Introducing Moonlake's 3D Agent.
Our agent acts like a technical artist that can build and reconstruct articulated assets and large-scale editable scenes with hundreds of objects from a single image and can improve its generations continuously.
Learn more in the thread below.
39
179
1,380
1,158,447
Wei Yu retweeted

Apr 24
Presenting Yunpeng’s paper on positional encoding field. I am at P3-1908!

7
105
8,804
Wei Yu retweeted

Apr 19
In Beijing's 2026 humanoid robot half-marathon, HONOR's Lightning completed the 21 km course in 50:26 minute.
Beat current human men's half-marathon world record of 57:20.
Last year's winner took over 2 hours 40 minutes.
Massive progress in 12 month
4
25
91
12,858
Wei Yu retweeted

Apr 20
Introducing Skywork 3.0 —— A 24/7 Autonomous Cloud Workforce.
Available to all Skywork subscribers.
11
6
70
7,614
Wei Yu retweeted
Apr 19
This robot took home the “Best Design” award, in today's Beijing humanoid robot half-marathon. recognition that its motion looks closer to natural human running than most competitors.
TienKung Ultra completed the full 21.1 km in 1 hour 15 minutes.
28
88
571
43,870

We open-sourced the code and model for UniRelight! 🎉
Given an input video and a target lighting configuration, our method jointly predicts a relit video and its corresponding albedo.
Code: github.com/nv-tlabs/UniRelig…
Model: huggingface.co/nvidia/UniRel…

🚀 Introducing UniRelight, a general-purpose relighting framework powered by video diffusion models.
🌟UniRelight jointly models the distribution of scene intrinsics and illumination, enabling high-quality relighting and intrinsic decomposition from a single image or video.
7
45
277
32,179
Wei Yu retweeted

Apr 17
I’ve decided to leave OpenAI. Below is the note I shared with my team.
Building Sora zero-to-one with you all has been the honor and adventure of a lifetime.
As this team knows well, one of the best parts of working on video is that you can see the scaling behavior with your own eyes, and there have been a lot of oh-shit moments over the years. About a month into Sora, way back when this was just a tiny two-man effort, we saw a sample where a land shark swam by a bunch of intricate cacti in a desert (it was a weird prompt), and the details of each cactus were perfectly preserved once the shark passed. We had never seen object permanence like this in any video model. That’s when we knew we were onto something.
It’s amazing how much the Overton window has shifted on video models. OpenAI has a high tolerance for crazy moonshots, but even back in July 2023 there was a ton of skepticism that high-fidelity 1080p multi-shot generation was achievable within a year given the state of video in the broader industry. We managed to get there 7 months later.
While the original Sora ignited a huge amount of investment in video across the industry, it took the next generation of models with Sora 2 for the broader public to understand the transformation happening. I’m proud of all the sleepless nights before and after the launch this team endured in order to deploy the technology in a responsible way and help steer societal norms.
I am immensely grateful to Sam, Mark, Aditya and Jakub for fostering a research environment that allowed us to pursue ideas off-the-beaten path from the company’s mainline roadmap. It’s tempting in life to mode collapse to the most important thing, but cultivating entropy is the only way for a research lab to thrive long-term, and Sam deeply understands this. Sora was a project that could not have happened anywhere but OpenAI, and I will always deeply love this place for that.
I’m going to miss this team a lot, but there are great things on the horizon for all of you. I will always be in your guys’ corner cheering you on.
Love,
Bill

219
204
3,860
530,674