
Bringing Institutional Market Efficiency to Crypto. Worlds first AI powered Hedgefund. #MicroGenesis
Joined December 2017
- Tweets 16
- Following 14
- Followers 2,177
- Likes 21
1 Photos and videos



$MAI seems to be recovering nicely, team is commited and working
we should expect more of leg up as we approach epoch 1 on dec10
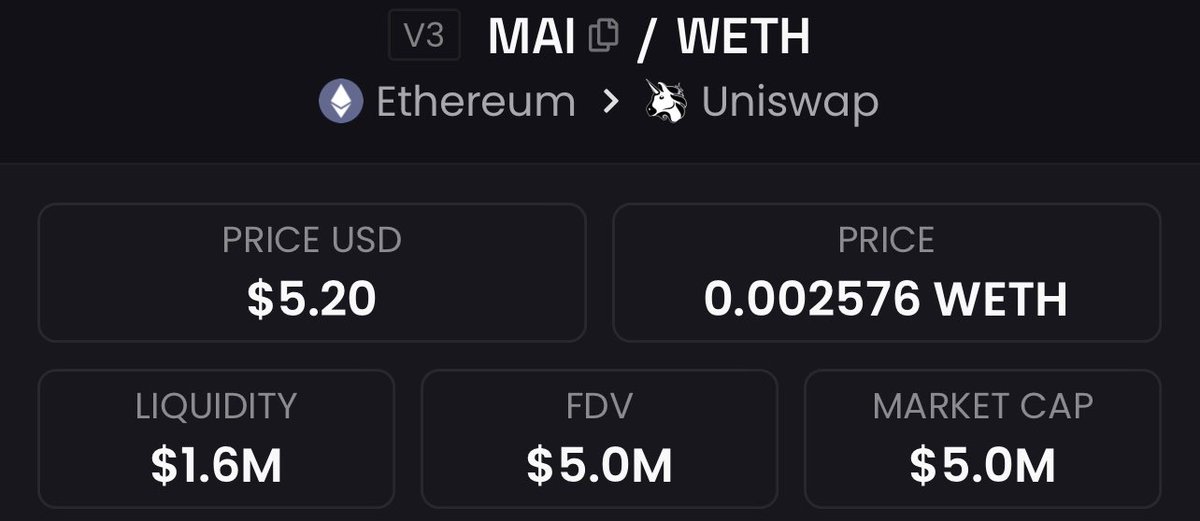

to me, this looks like a golden opportunity, chart bottomed, liq thick af, fud is insignificant and just dumb
at the end of the day, price is usually driven by speculation, use some rational thinking and make your own judgments
community tg;
t.me/ DqHa4McFV-81YmU0
1
5
23
5,188
Micro AI retweeted

12 Nov 2023
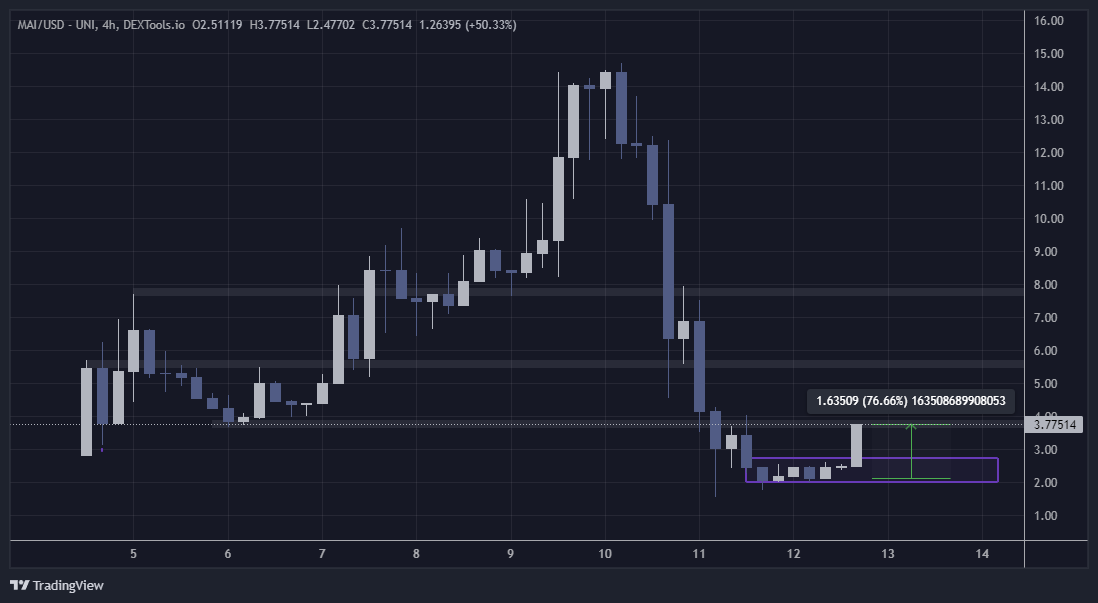
$MAI | We bought blood.
After $MAI run without us we patiently waited for entries around 2-3$.
During last 2 days we did range around my ideal entry, so I managed to spot a beautfiul entry at 2.10$.
Currently running 70% in profit.
Project // @GoMicroAI
#altcoin #lowcap #eth
2
5
2,907

Company Talk #2 ☀️
While we‘re eagerly awaiting MicroGenesis Epoch 1, we have to clear up some misunderstandings in front of our community & $MAI.
A) MicroGenesis: The MLT-HFT algorithm is not a part of MicroGenesis. It‘s in building until May 2024. MicroGenesis will consist of ScreenerAI, OCMF, FuturesFuture.
B) We use non-KYC exchanges based on our location, this will continue through the entire operation in the coming years since we‘re not planning on leaving this beautiful country. Some algorithms are as well hard coded to get profits through a non-KYC exchange or/and mixer before sending it to the index-ing algorithm.
C) There are no public advisors for Micro AI, all claims that have been made my fraudulent roles in the past are wrong.
D) Yes, we used LBP capital in order to maintain solvency. This was always an option and was communicated during the raise.
E) Yes, we voluntarily decided to give up on $4M in fees. This was no „accident“. It‘s easier to run the index-ing attribute and train all models on similiar data.
F) Yes we have been „Market Making“ our own token as a test with small capital. All profits have been used to buy-back tokens.
G) We are not dependent on retail investors, while we happily enjoy a great community with inspirational talents inside, we don‘t target retail. Racist slurs & personal attacks inside our Telegram Community Group also highlighted the accuracy of this decision. From now on we don‘t want to be affiliated with the „community“ that built itself anymore. All Telegram Links to Community Chats will be removed, since we don‘t support fake news regarding individuals inside the team or the CCP.
H) Any „influencer“ claiming to work with us, is lying. We don‘t work with western influencers, we never will.
Thanks for the time.
Remember that this is an open market and we don‘t control the speculation of retail investors.
We are happily taking a lower valuation in order to boost the index-ing algorithm.
53
23
116
53,747
Company Talk #1: 🔆
We're happy to share that the official ETA for MicroGenesis Epoch 1 will be December 10th 2023.
MicroGenesis is the first open autonomously AI-powered hedgefund with the target of 100% ROI.
Achieving this ROI in under 180 days will not only pave the way for showcasing Micro AI to a large audience, it will also prove institutional investors that the crypto-market is still very much attractive for safe but profitable investment strategies.
MicroGenesis Epoch 1 will include the following (AI) algorithms:
- FuturesFuture
- On-Chain-Money-Flow (OCMF)
- Screener
With that we simultaneously provide options for MicroGenesis to invest in large established projects with leverage, to invest in medium sized projects by spot-buying the LPs and to invest in newly founded projects with a lot of upside possibilities.
______________
While these are all good news, we still have to provide full transparency on everything going on in the company. It's no secret that Micro AI is operating inside a crypto unfriendly environment. We are currently facing the first issues because of that. We are forced to change European server-infrastructure in the coming working-week. We will comply with all jurisdictional orders. We are still awaiting an 北京-MSS allowance on MicroGenesis. While we are of course not involved in the recent Chongqing Drama, we are definitely affected on stricter regulations. The recent social-media explosion around Micro AI and MAI, is the reason why we're having some troubles on providing exact ETAs. The fee-model was changed in order to protect investors, no matter how these recent developments play out. We don't want to collect fees, we want to stay and help this space.
We are awaiting a successful Epoch 1.
More details including the MicroGenesis Dashboard for investors will follow shortly.
______________
虽然这些都是好消息, 但我们仍然必须对公司发生的一切提供充分的透明度. Micro AI 在一个诸如比特币一类的加密电子货币不友好的环境中运营,这已经不是什么秘密了. 因此, 我们目前正面临着第一个问题. 我们不得不在接下来的一周内更换欧洲服务器基础设施. 我们将遵守所有司法命令. 我们仍在等待北京-国家安全部对 MicroGenesis 的补贴. 虽然我们没有卷入最近的重庆事件, 但我们肯定会受到更严格法规的影响. 由于最近社交媒体对 Micro AI 和 $MAI 的热炒, 我们在提供准确的预计到达时间方面遇到了一些麻烦. 收费模式的改变是为了保护投资者, 无论最近的事态如何发展. 我们不想收取费用, 我们想留下来帮助这个领域.
我们正在等待一个成功的第一纪元. 🔆⚡️
更多详情, 包括为投资者提供的 MicroGenesis Dashboard, 将很快公布.
35
24
104
57,285
Data Aggregation and Solana Integration are going to be the core points of operation in the coming 3 months.
While we build boring, but important infrastructural attributes for On-Chain-Money-Flow, we will simultaneously finalise the legal challenges surrounding MicroGenesis, and pave the way for a successful Epoch 1.
We already have to highlight here that MicroGenesis will be the first run, thus it will all be time-consuming and carefully managed. Expect slower but necessary operational speed. All algorithms will trade with artificially smaller sized orders, to protect user assets for the first 3 months.
☀️
19
15
96
50,469
Micro AI Tech-Talk #1: 🧵
The next 3 months will have an intensive focus on Data-Aggregation and Data-Interconnectivity. 🔆
While this might sound boring it's the essential reason Micro AI will emerge as more capital-efficient, faster in execution and more scalable than competition.
Imagine the following scenario:
You are reading a book about tigers with over 100,000 pages, examining every detail in-depth, but you only want the broad overview on what tigers are, what they eat. That is an example of inefficient data-aggregation.
You are getting too much data as an input, while only needing a small amount of data.
So what to do now? You could tear out the first page of the book and hope that it shows all necessary data, that you'll need. But that's not efficient as well.
This exact issue is also the core problem of AI-powered High Frequency Trading algorithms. The models have to evaluate a lot of data in order to even open a trade.
The Problem? HFT Algorithms need to execute market-orders in lightning-speed. Microseconds, soon even nanosecond. It's getting faster and faster with every year. And traditional ones are just more time efficient than AI-powered ones until today.
Micro AI is already executing orders with a reduced speed of 97.8% in comparison to academical, theoretical MLT-HFT algorithms. We are not only day-dreaming in the academical utopian world but are in the live-market.
The coming 3 months will lay even more focus on data-aggregation. We are certain that this is what will make the difference between AI-powered HFT algorithms which are doomed to fail, and Micro AI.
We know this will be immensely boring to observe, since it's a very technical topic, which is why we're working hard to get MicroGenesis Epoch 1 ready.
Expect more information on it the coming few days.
4
12
44
27,177
Our Ai-powered HFT Algorithms are running and improving everyday. $MAI
Daily Stats: 🔆
Accuracy: 93.87% ( 0.2% better than yesterday)
Daily Volume: $29,063,077
Daily Profit: $4,190
We are ready to expand this volume to over $100,000,000/day now.
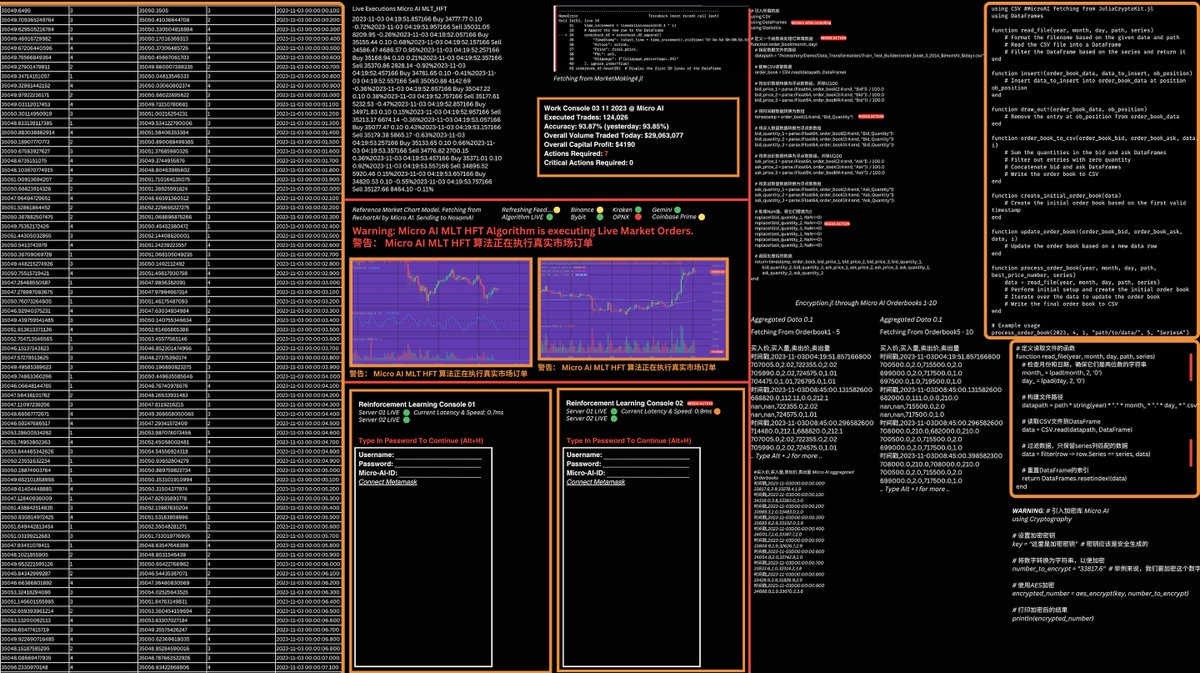
ALT Micro AIs Ai-powered High Frequency Trading Terminal
1
17
71
30,061
How MicroAI plans to make $500m/year in revenue by 2030: 🧵
High Frequency Trading algorithms are one of the largest actors in traditional finance. Our biggest competitor made over $2bn in revenue this year.
But we're already two steps ahead.
1) Developing with Julia:
Julia is a new high-performance programming-language designed for technical computing. It was specifically developed to address the need for high-performance numerical and scientific computing without sacrificing ease of use.
HFT is a form of algorithmic trading where securities or tokens are bought and sold in extremely short time frames, often microseconds.
The sector DEMANDS high-performance computing resources, low-latency systems, and efficient algorithms to execute trades at the FASTEST possible speeds.
Julia’s high-performance capabilities make it well-suited for the rapid execution of trading algorithms. Its type declarations and multiple dispatch are being used to optimize Micro AIs algorithms for even higher performance. Julia has built-in support for parallel and distributed computing, which is essential for handling the massive data sets and computational needs of HFT.
Julia is PERFECT for High Frequency Trading.
Since it's so new basically no one is using it yet.
We are first movers.
---
2) Combining Deep Learning (AI) with HFT
We are NOT first-movers in this sector. While this is gate-kept to the public, most HFT houses are already using AI-powered HFT algos, which are profitable.
We take this on a new level though. Since we don't operate in TradFi but within the crypto market, we have unlimited access to data.
How you might ask... Etherscan. Every single order that has ever been placed on Ethereum can be used to train Micro AIs MLT-HFT algorithms.
We are already over 5,000,000,000 data-points deep in training.
With our Clustering Algorithm, which prevents HFT overfitting and at the same time allows for more data-points we expect the following amount of trained data-points:
2023 Q4: 11,000,000,000
2024 Q4: 50,000,000,000
2025 Q4: 180,000,000,000
2026 Q4: 2,000,000,000,000
This is possible through data-clustering.
2,000,000,000,000 data-points is EXPENSIVE.
Really expensive. While solutions like @rendernetwork & @ionet_official will ease the developmental costs, it will still be costly.
Which is why we spent over $50,000 this month on a new data-aggregation system, which aggregates the data-points and makes it cheaper to train models on.
We expect data-aggregation to be the centre of our MLT-HFT developments in 2023 Q4.
Thus while models continue to train in the coming months, they will continuously get cheaper.
This is not a sprint but a marathon. We're ready to dominate this $50bn market-sector by 2035.
Welcome to history.
Welcome on this journey.

1
6
21
10,183
NOW LIVE ⚠️
Earn up to 2 ETH/Day with IRA by MicroAI 🔆
How? By providing valuable information to our AIs.
Be it a ticker that you think will perform well, a insider information you want to share,..... $MAI
gomicroai.com/ira

2
8
13
6,134
Virtu Financial Inc. the HFT Market Making Firm that only had 1 loosing day in 1000 trading days made a total revenue of 2.36 billion USD in 2022.
Micro AI's MLT-HFT Algorithms put Virtu in the shadows in the on-chain-world.
We are coming for your monopoly.
1
6
11
4,749
Regulations are coming to crypto.
How long will it take until the whole Stock Market is woven within the DeFi ecosystem?
Who will market-make the institutional liquidity, who will already have trained their algorithms on Ethereum, while others were too lazy to adapt?
#MicroAI

6
15
3,960
Progress the past week: 🔆
- Over 23,000 new Cluster-Trades Taken
( --> 372,144 individual trades )
- First Autonomous Intelligent Short Position Taken
- Screener AI V0.99 development finished and integrated into EtherScan, SolScan, ArbiScan (more to follow)
#BuildInPublic
2
6
10
3,436


