
PhD @ MIT CSAIL. Finding/exploiting patterns in data, especially symmetries. AI4Science. hannahlawrence.github.io. Cofounder @bostonsymmetry.
Joined April 2021
- Tweets 107
- Following 768
- Followers 951
- Likes 420
12 Photos and videos


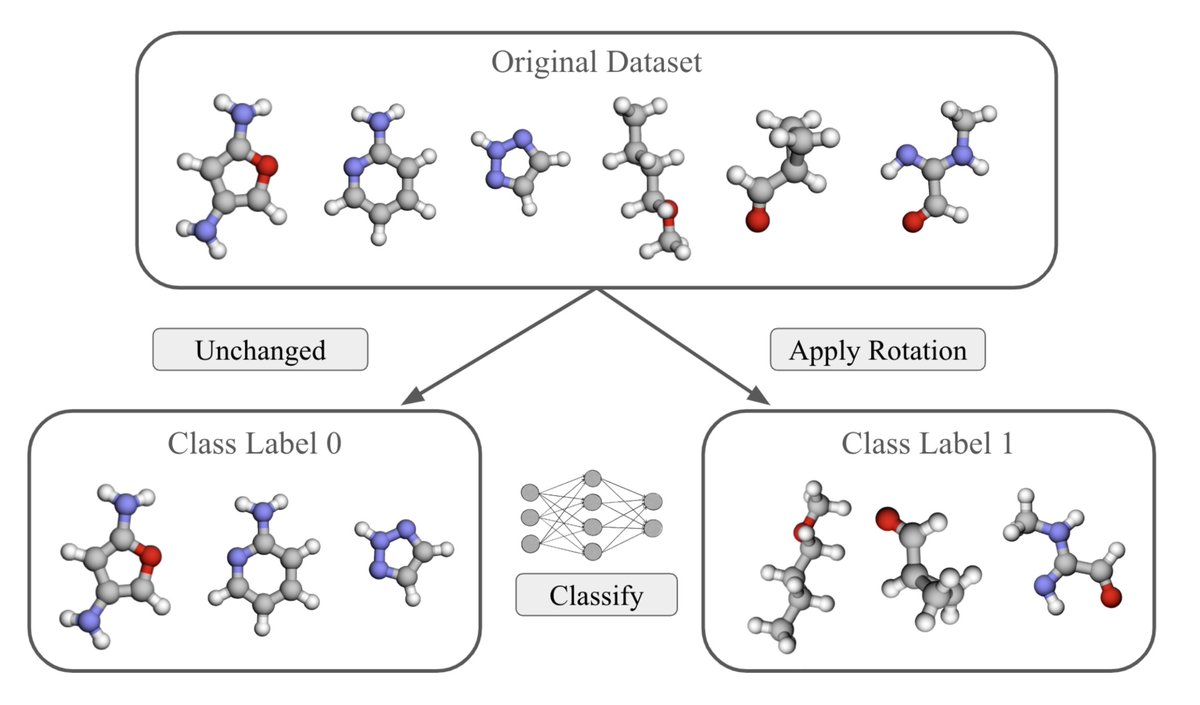



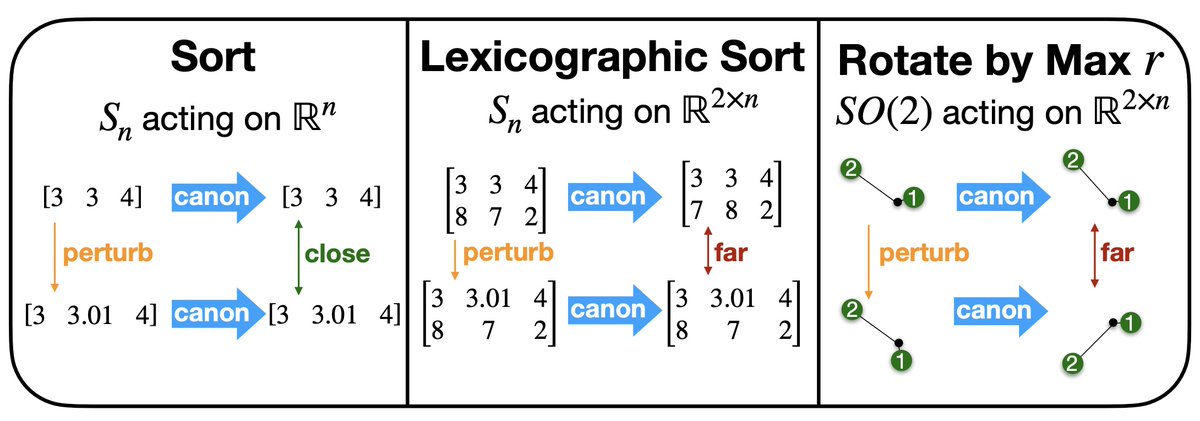
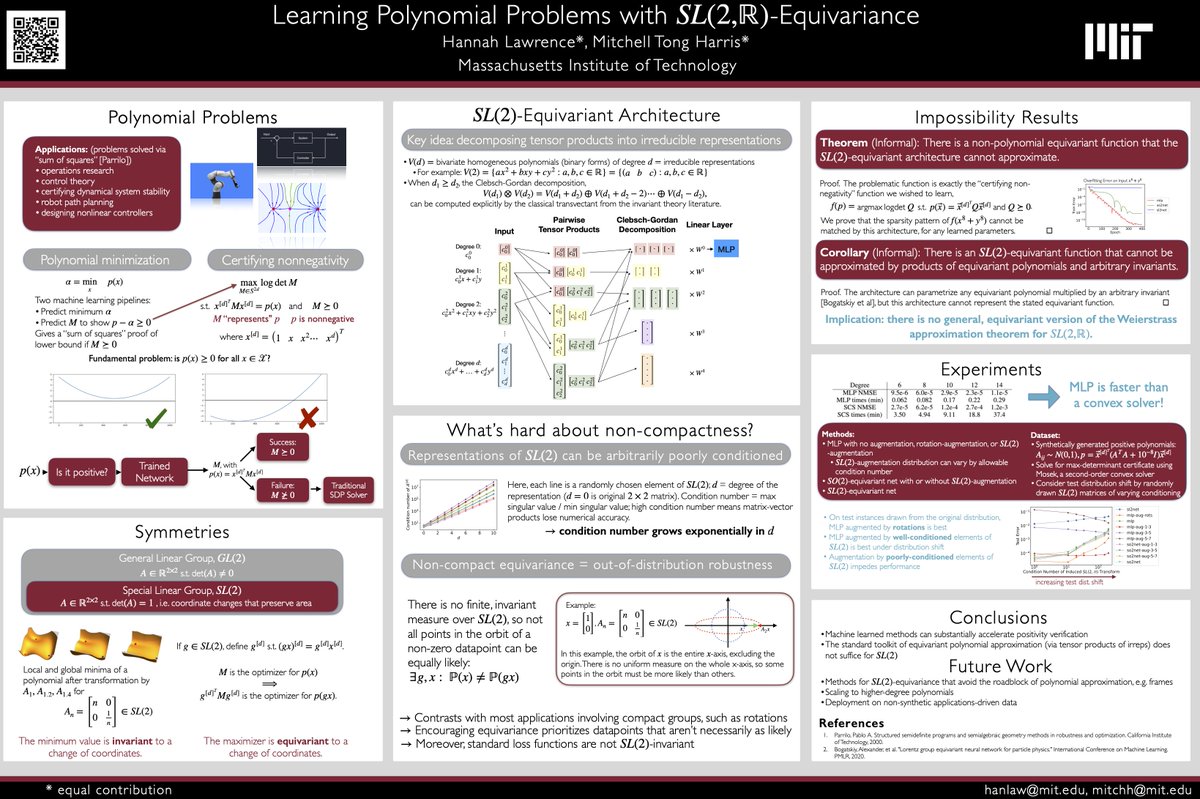
Pinned Tweet
@bostonsymmetry is hosting a poster session (4-5:30pm) social on Tuesday, June 9th, at Northeastern! All are welcome to come chat about geometry, symmetries, AI!
Location: Raytheon Amphitheater, maps.app.goo.gl/oDZc3Rw7iN4q…
Register here: neu.co1.qualtrics.com/jfe/fo…
6
14
934

Just under two weeks until the submission deadline for the Boston TAG Party 2026– a joint conference organized collaboratively by the Boston Symmetry Group and TAG-DS! Papers are due June 12th— full archival papers, extended abstracts, and open problem tracks!
1
6
5
824
Hannah Lawrence retweeted

Apr 27
Results for the GRaM Competition are online. Congratulations to the winner and runners-up 🎉
🥇 github.com/julka01 with SmoothSplatNet
🥈 github.com/jorgesarrato with CDFDoubleGridNet
🥉 github.com/v3ctr0id with VRTEnsemble
gram-competition.github.io
1
6
17
1,074
Hannah Lawrence retweeted

A memorable final quote from @AlexanderTong7 (echoed by several of the panelists): "geometry is about understanding the world, and it is here to stay."
6
18
2,817
Hannah Lawrence retweeted
Next up: @mayabechlerspei is sharing her insights on billion-parameter graph foundation models!


6
58
10,036
Hannah Lawrence retweeted
Unmissable panel starting now! @wellingmax, @mmbronstein, Kathlén Kohn, Gabriel Loaiza-Ganem, and @AlexanderTong7 discuss "scale, simplicity, and geometry", moderated by @erikjbekkers
The first question: is scale really all you need? What is the role of inductive bias? 🌶️

4
10
85
10,314
Hannah Lawrence retweeted

Will be speaking today at the GRaM workshop at ICLR @iclr_conf (gram-workshop.Github.io/ ) about how we are building efficient and effective billion-scale Graph Foundation Models at Meta!!! 🤩
(GraphBFF 👉 lnkd.in/dB67TZN6).
Anddddd we also have an awesome paper at the workshop! "Improving LLM Predictions via Inter-Layer Structural Encoders", poster session A :) (lnkd.in/dZCnztY5)
#iclr2026

5
8
40
2,937
Hannah Lawrence retweeted
Gabriel Loaiza-Ganem is speaking NOW on "A Geometric View of Deep Generative Models"!
The claim: generative models can be divided into (data) manifold-aware and manifold-unaware methods. Manifold-aware methods work better!


1
10
64
4,541
Hannah Lawrence retweeted
GRaM 2026 is kicking off NOW in 101A with @erikjbekkers!
Full schedule at gram-workshop.github.io/ #doitfortheGRaM

8
26
1,602
Hannah Lawrence retweeted
We're excited to kick off the GRaM Workshop tomorrow (Sunday) at 9am in Room 101A! Check out the paper search tool on our website, where you can find posters at the intersection of your interests :)
Full schedule speakers at gram-workshop.github.io
#doitfortheGRaM
8
18
2,081

Apr 25
Was the whole blogpost an excuse to make this meme? Perhaps.
Apr 25

We must choose both the tokens AND their order.
A joint distribution can be factored into a product of conditionals in any order, but this choice determines the available context at each step. Thus, some orders are easier to model in practice (arxiv.org/abs/2502.06768)
(2/7)
1
5
1,170
Apr 25
Come chat about tokenization and trends in the treatment of non-sequential data!
P4-5313
Apr 25
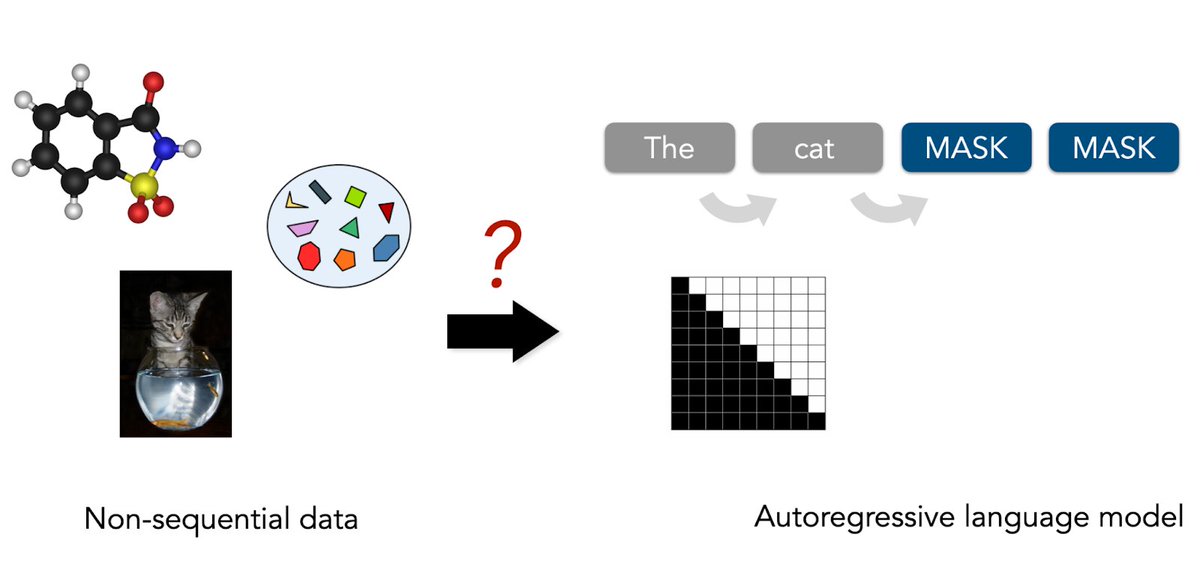
New blogpost on tokenizing non-sequential data!
Language has sequential structure, which gave rise to the next-token prediction paradigm of LLMs. But we increasingly use LLMs for data without inherent order (e.g. images, molecules, sets). What does “next token” mean here?
(1/7)
5
37
3,901
Hannah Lawrence retweeted

Apr 22
You have a safe model you've tested, and you have a new post-trained model. How far can you trust a new model before it becomes unsafe? The answer goes to the heart of statistical decision-making. To be safe, the agent must be self-aware. Read @DrewPrinster's thread for more.

Apr 22

Can we ensure AI agents respect our safety constraints, even as they explore & improve?
- Medical LLMs that are helpful, & avoid false claims?
- Bioscience agents that generate effective molecule designs, & ensure they’re safe?
📄🧵w/ @samuel_stanton_ @clara_fannjiang @jiwoncpark @kchonyc @anqi_liu33 @suchisaria
Excited to share “Conformal Policy Control” ⬇️
1/12
4
15
3,757
Apr 23
TL;DR: poster today at 3:15pm, P3-#1109!
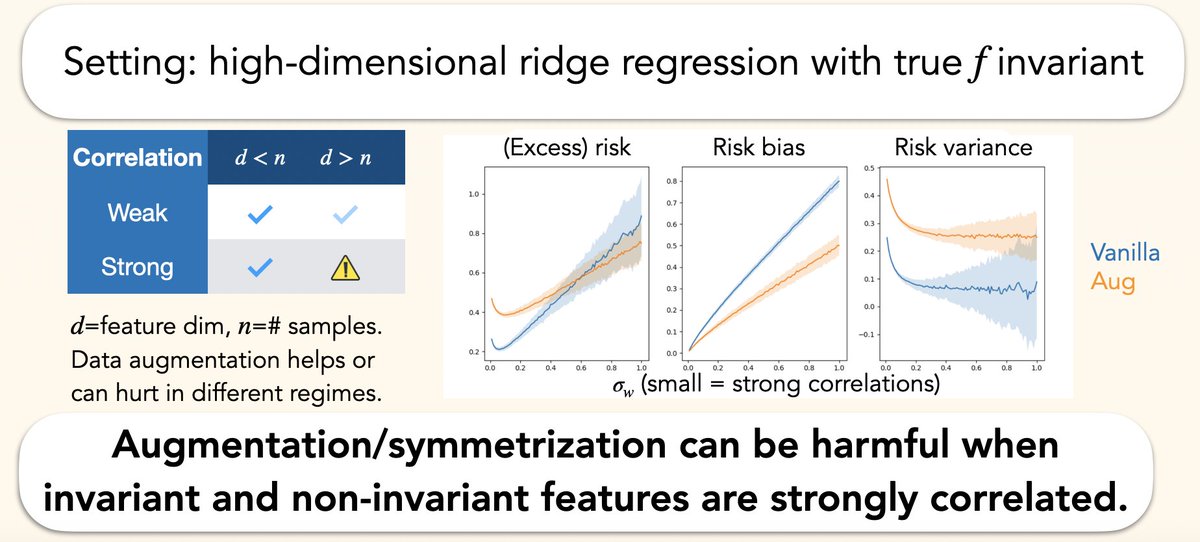
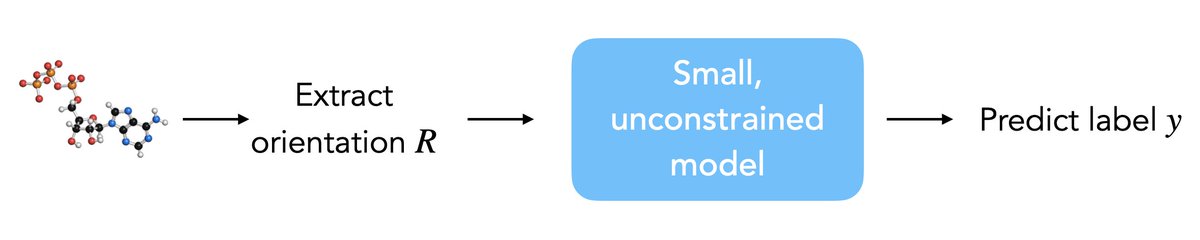
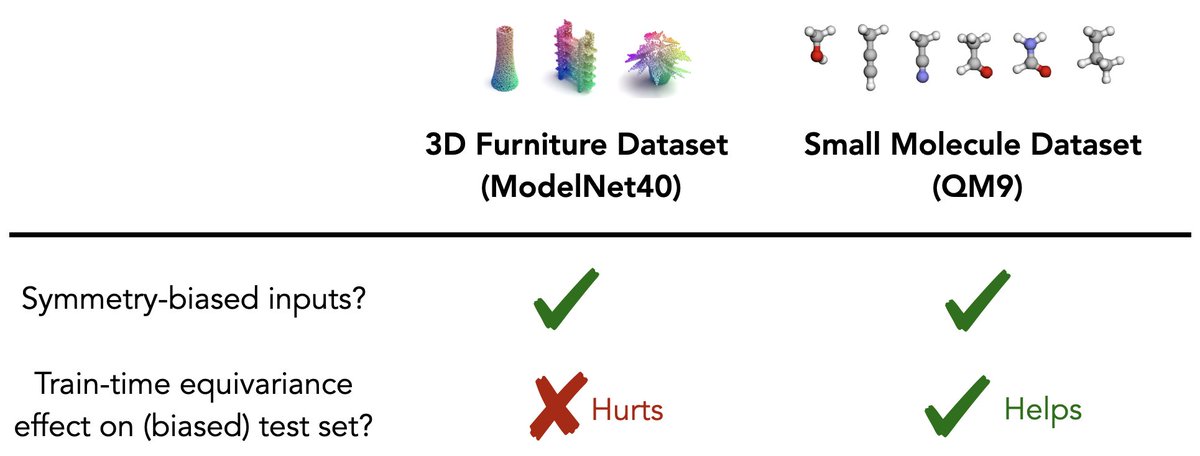
Have you ever benchmarked your method on QM9, MD17, OC20, or ModelNet? It turns out that the 3D orientations of point clouds in commonly used datasets are highly non-random. How did we prove this and why should you care? 🧵
1
12
40
3,190
Apr 23
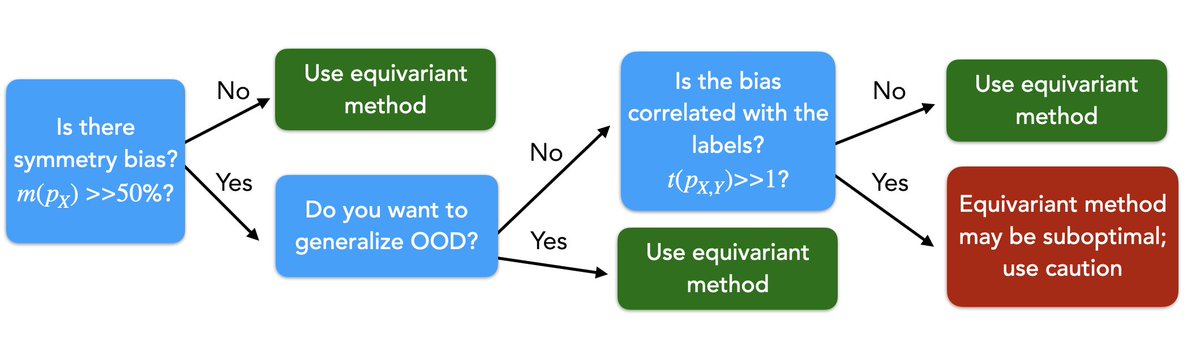
So: where does this leave equivariant methods? Here’s a handy flowchart :)
(N.B. we’re lumping together equivariant architectures and augmentation here. They are of course different, and our experiments used both. But both provably discard input-level rotational biases!)
1
1
4
175
Apr 23
It was a pleasure working on this with co-first author @ElyssaHofgard and great collaborators @vportilheiro, Yuxuan Chen, @tesssmidt, and @RobinSFWalters. Come chat with Elyssa, Vasco, and I this afternoon!
Paper: arxiv.org/pdf/2510.01349
Blog post: ehofgard.github.io/blog/2026…
2
5
198