
A PhD student in State Key Laboratory of CAD & CG, Zhejiang University.
Joined July 2021
- Tweets 38
- Following 276
- Followers 422
- Likes 262
5 Photos and videos






Haotong Lin retweeted

May 19
Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.
14
143
850
777,088
Haotong Lin retweeted

May 3
Introducing: Long-Tail Internet Photo Reconstruction (CVPR’26)
We go beyond densely captured imagery to train more general 3D foundation models for the long tail of noisy, sparse, incomplete Internet photo collections of 3D scenes. Yet, we face a data bottleneck: models need ground truth for these long-tail scenes, which classical SfM fails to provide. How do we bypass it?
We break this bottleneck with two key contributions. First, we introduce MegaDepth-X, a large new dataset of scenes with high-quality 3D supervision. Second, we propose a new way to simulate difficult image sets for training.
Project page: megadepth-x.github.io/
1
20
105
22,387
Haotong Lin retweeted

May 3
Excited to share our CVPR’26 work! Moving beyond dense captures to long-tail Internet photos, we introduce MegaDepth-X and sparsity-aware sampling for 3D reconstruction.
Great work led by Yuan (@yuanli16342871) and the team.
Project page: megadepth-x.github.io
May 3

Introducing: Long-Tail Internet Photo Reconstruction (CVPR’26)
We go beyond densely captured imagery to train more general 3D foundation models for the long tail of noisy, sparse, incomplete Internet photo collections of 3D scenes. Yet, we face a data bottleneck: models need ground truth for these long-tail scenes, which classical SfM fails to provide. How do we bypass it?
We break this bottleneck with two key contributions. First, we introduce MegaDepth-X, a large new dataset of scenes with high-quality 3D supervision. Second, we propose a new way to simulate difficult image sets for training.
Project page: megadepth-x.github.io/
12
111
12,947

Happy to introduce Habitat-GS, a non-intrusive extension of Habitat-Sim that brings dynamic Gaussian Splatting for photorealistic rendering and comes with hundreds of high-quality 3DGS scene assets, aiming to empowering navigation research.
Code: github.com/zju3dv/habitat-gs
2
19
187
11,991

Apr 24
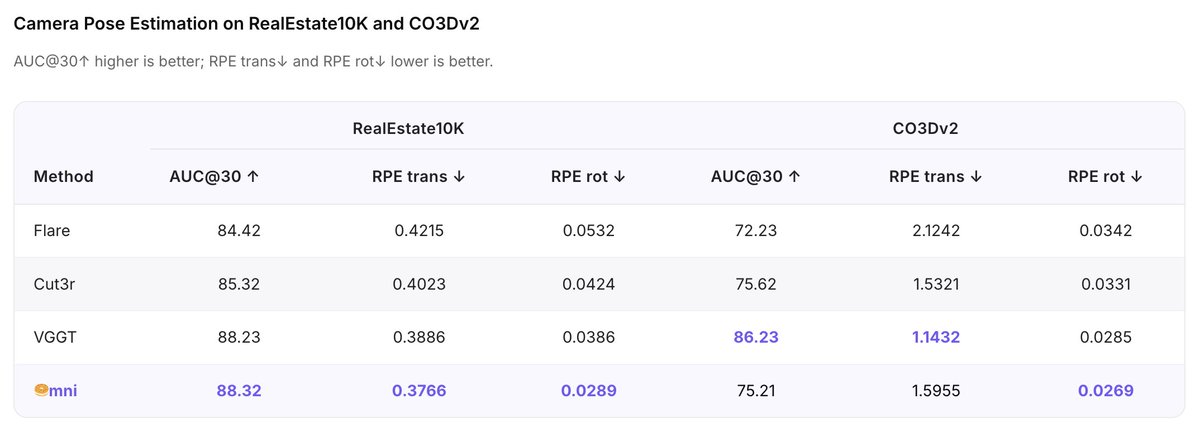
Congrats to the Omni team! 🥯🎉
Camera pose estimation? Just AR text gen 🤯
<campose>1.04 0.00 0.32 -0.20 -0.27 -0.02</campose>
6DoF floats as a string 🪢 no pose head, no bins, no 3D priors. On RealEstate10K: AUC@30 88.32 vs VGGT 88.23 on par with a geometry specialist!
Apr 24

Introducing Omni, one unified model can support any-to-any multimodal modeling, including multimodal understanding, image/video generation and editing, world modeling and 3D reconstruction. All in one that adopts standard mixture-of-experts arch with only 3B activations.
2
5
38
6,085
Apr 24
🍌perception is a subset of generation! Strong work — excited for what comes next on the unified vision front.
Apr 23

Yay, finally! Introducing Vision Banana🍌 from @GoogleDeepMind, our unified model that outperforms SoTA specialist models on various vision tasks!
By treating 2D/3D vision tasks as image generation, we unlock a new foundation for CV.
Project page: vision-banana.github.io
(1/5)
1
6
864
In our comparison on long image sequences, Scal3R consistently outperforms DA3.
In such cases, Scal3R offers a viable alternative.
Feel free to try Scal3R: github.com/zju3dv/Scal3R
5
20
195
10,690
Haotong Lin retweeted

Apr 15
Today, we released Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale, from NVIDIA Research.
Generating large-scale, complex environments is difficult for AI models. Current models often “forget” what spaces look like and lose track of movement over time, causing objects to shift, blur, or appear inconsistent. This prevents them from creating the reliable 3D environments required for downstream simulations. Lyra 2.0 solves these issues by:
✅ Maintaining per-frame 3D geometry to retrieve past frames and establish spatial correspondences
✅ Using self-augmented training to correct its own temporal drifting.
Lyra 2.0 turns an image into a 3D world you can walk through, look back, and drop a robot into for real-time rendering, simulation, and immersive applications.
➡️ Learn more: research.nvidia.com/labs/sil…
📄 Read the paper: arxiv.org/abs/2604.13036
100
462
2,866
433,771
Haotong Lin retweeted

Mar 5
Spatial reconstruction is a long-context problem: real scenes come with hundreds of images. But O(N²) transformer-based models don’t scale efficiently.
Introducing: 🤐ZipMap (CVPR ’26): Linear-Time, Stateful 3D Reconstruction via Test-Time Training (TTT).
ZipMap “zips” a large image collection into an implicit TTT scene state in a single linear-time operation. The state will then be decoded into spatial outputs, and can be queried efficiently for novel-view geometry and appearance (~100 FPS)
ZipMap is not only much faster (>20× faster than VGGT), but also matches or surpasses the accuracy of all SOTA models.
20
102
756
78,119
Haotong Lin retweeted

14 Nov 2025
papers are kind of like movies: the first one is usually the best, and the sequels tend to get more complicated but not really more exciting. But that totally doesn’t apply to the DepthAnything series. @bingyikang's team somehow keeps making things simpler and more scalable each time.
in this new version, they basically show that a strong representation encoder plus a depth-ray prediction objective is enough (you see the RAE vibes too, right?) to get solid, general spatial perception across a bunch of tasks.
people often say they hate computer vision because it’s messy--too many tasks, too many data types, too many moving parts. but that’s exactly why I love it. I think the biggest AI breakthroughs are going to come quietly from vision and then suddenly leapfrog everything else, changing how AI interacts with the real world and with us.
pretty soon we’ll realize vision is not a big list of tasks--it’s a perspective. a perspective about modeling continuous sensory data, building layered representations of the world, and inching toward human-like intelligence. and tbh we’re watching this happen every day, behind all the hype, as all these different '"tasks" slowly start to merge.
14 Nov 2025

After a year of team work, we're thrilled to introduce Depth Anything 3 (DA3)! 🚀
Aiming for human-like spatial perception, DA3 extends monocular depth estimation to any-view scenarios, including single images, multi-view images, and video.
In pursuit of minimal modeling, DA3 reveals two key insights:
💎 A plain transformer (e.g., vanilla DINO) is enough. No specialized architecture.
✨ A single depth-ray representation is enough. No complex 3D tasks.
Three series of models have been released: the main DA3 series, a monocular metric estimation series, and a monocular depth estimation series.
The core team members, aside from me: @HaotongLin, Sili Chen, Jun Hao Liew, @donydchen.
👇(1/n)
#DepthAnything3
5
40
514
76,222
Haotong Lin retweeted

14 Nov 2025
After a year of team work, we're thrilled to introduce Depth Anything 3 (DA3)! 🚀
Aiming for human-like spatial perception, DA3 extends monocular depth estimation to any-view scenarios, including single images, multi-view images, and video.
In pursuit of minimal modeling, DA3 reveals two key insights:
💎 A plain transformer (e.g., vanilla DINO) is enough. No specialized architecture.
✨ A single depth-ray representation is enough. No complex 3D tasks.
Three series of models have been released: the main DA3 series, a monocular metric estimation series, and a monocular depth estimation series.
The core team members, aside from me: @HaotongLin, Sili Chen, Jun Hao Liew, @donydchen.
👇(1/n)
#DepthAnything3
79
492
3,582
514,344
10 Oct 2025
Thank you for sharing our work! Marigold is really cool! However, it’s somewhat limited by the image VAE — many flying points appear just after encoding a perfect ground-truth depth. Pixel-space diffusion to the rescue 🚀
9 Oct 2025

Pixel-Perfect-Depth: the paper aims to fix Marigold's loss of sharpness induced by VAE by using VFMs (VGGT/DAv2) and a DiT-based pixel decoder to refine the predictions and achieve clean depth discontinuities. Video by authors.
2
3
55
5,804
Haotong Lin retweeted

9 Oct 2025
Pixel-Perfect-Depth: the paper aims to fix Marigold's loss of sharpness induced by VAE by using VFMs (VGGT/DAv2) and a DiT-based pixel decoder to refine the predictions and achieve clean depth discontinuities. Video by authors.
2
53
417
29,504
Haotong Lin retweeted

8 Jul 2025
🚀 We release SpatialTrackerV2: the first feedforward model for dynamic 3D reconstruction and 3D point tracking — all at once!
Reconstruct dynamic scenes and predict pixel-wise 3D motion in seconds.
🔗 Webpage: spatialtracker.github.io/
🔍 Online Demo: huggingface.co/spaces/Yuxihe…
5
87
462
41,383
Haotong Lin retweeted

16 Jul 2025
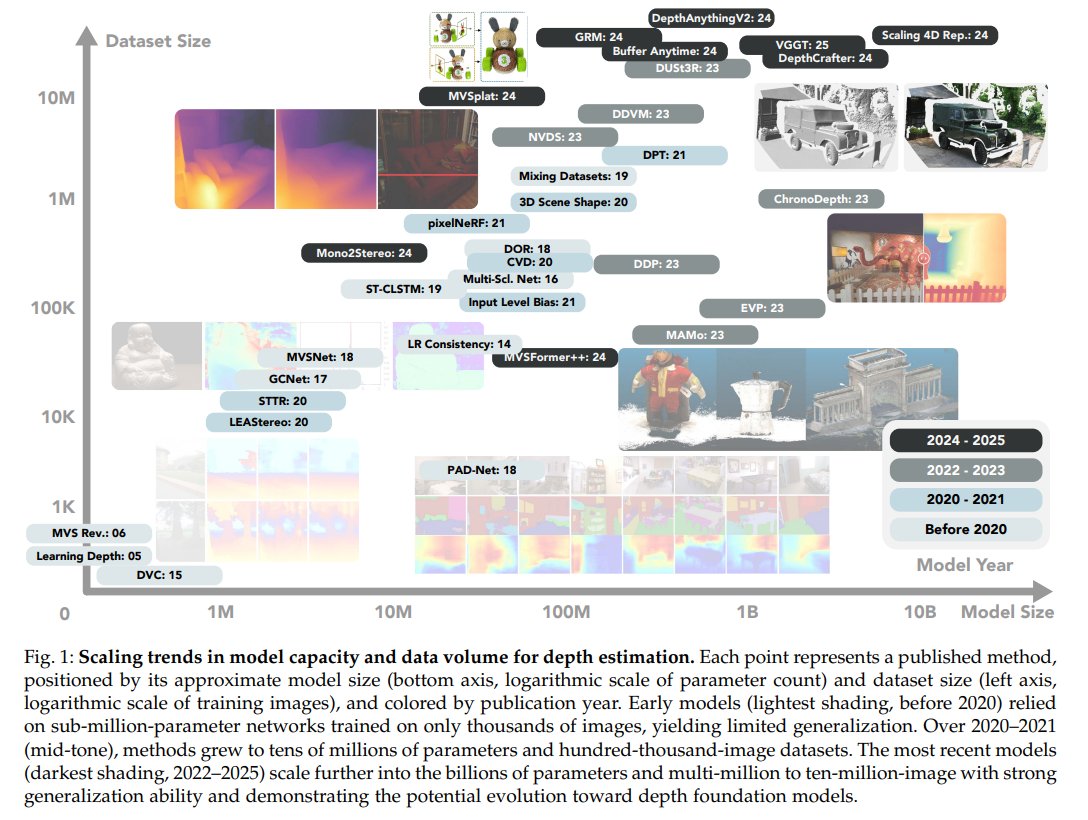
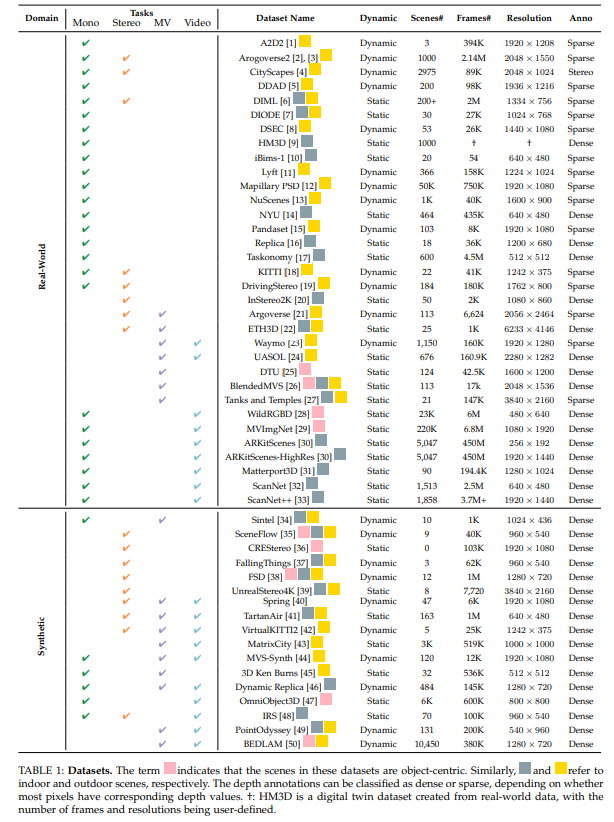
Towards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
@realzhenxu, Hongyu Zhou, @pengsida, @HaotongLin, @ghy990324, @jiahaoshao1, Peishan Yang, Qinglin Yang, Sheng Miao, @XingyiHe1, Yifan Wang, Yue Wang, @ruizhen_hu, @yiyi_liao_, @XiaoweiZhou5, Hujun Bao
tl;dr: survey
arxiv.org/abs/2507.11540


12
60
2,768
29 Apr 2025
Wow, thank you for crediting our work! Thrilled to see our project PromptDepthAnything being used in your latest release. This is awesome! Best of luck with the new version! !
29 Apr 2025

Are you tired of the low quality of iPhone lidar scans? I am! And that is why we are bringing this cutting-edge iPhone lidar scan enhancement function into production! With the guidance of normal and depth, the geometry can now reach the next level! Showcases: kiri-innovation.github.io/Li…. Please try our KIRI Engine 3.14 iOS version. Thanks to Xuqian and her AGSMesh paper (github.com/XuqianRen/AGS_Mes…), which inspired us a lot, and also thanks to Haotong, Sida, and Jiaming for their stunning paper PromptDA (github.com/DepthAnything/Pro…), which makes the depths way better. Of course, thanks to CJ and our intern team, Quanxiang and Ziteng, for helping with the development. #CVPR2025 #3DV2025 #GaussianSplatting #LiDAR
2
1
33
2,016
Haotong Lin retweeted

3 Feb 2025
Recently, I've been playing with my iPhone ToF sensor, but the problem has always been the abysmal resolution (256x192). The team behind DepthAnything released PromptDepthAnything that fixes this. Using @Polycam3D to collect the raw data, @Gradio to generate a UI, and @rerundotio to visualize. Links at the end of the thread
29
212
2,141
244,669
Haotong Lin retweeted

14 Jan 2025
Excited to share our work MatchAnything:
We pre-train strong universal image matching models that exhibit remarkable generalizability on unseen multi-modality matching and registration tasks.
Project page: zju3dv.github.io/MatchAnythi…
Huggingface Demo: huggingface.co/spaces/Little…
19
155
807
72,081