
Joined August 2023
- Tweets 695
- Following 52
- Followers 2,120
- Likes 645
260 Photos and videos






Pinned Tweet

19 Dec 2025
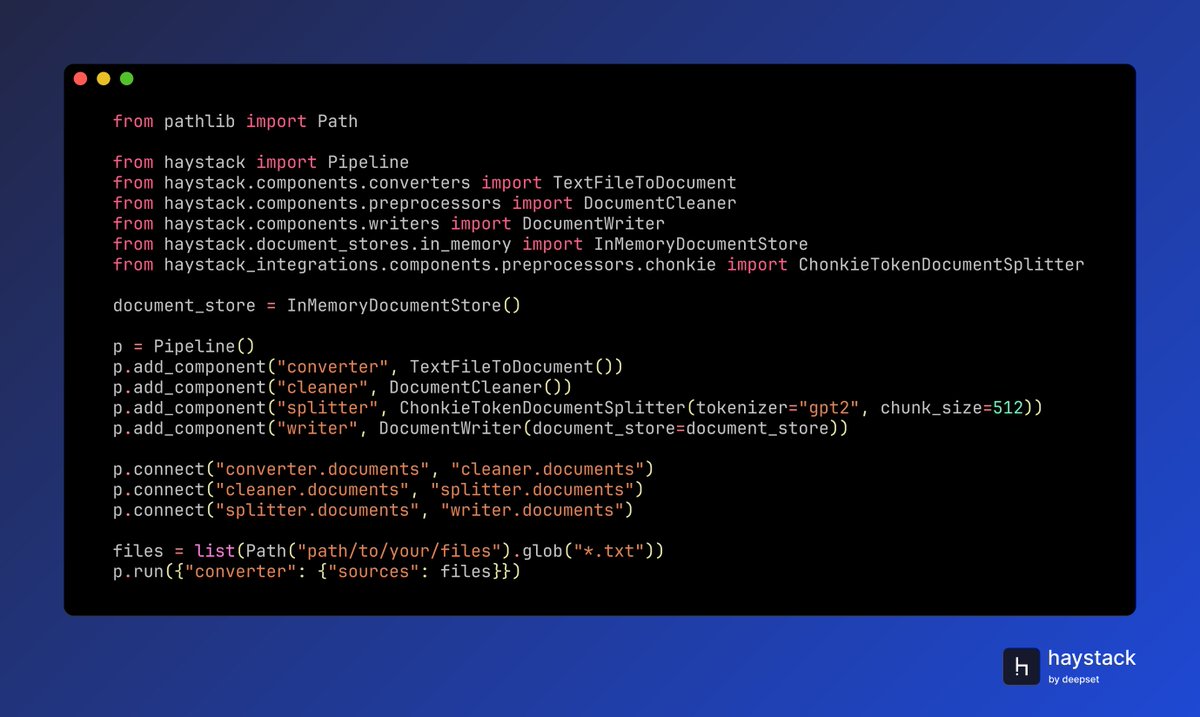
One Name. One Product Family. One Look 💙
We’re unifying the Haystack ecosystem at @deepset_ai under one name and a new logo, reflecting its role as a framework, a community, and the foundation of our enterprise platform.
👉 Read the announcement: haystack.deepset.ai/blog/ann…

3
10
1,986
Jun 12
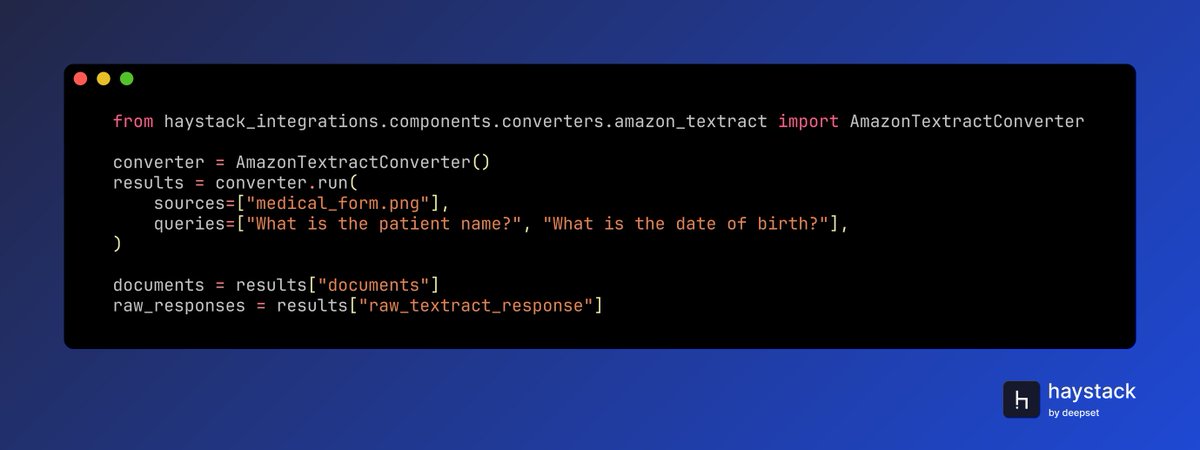
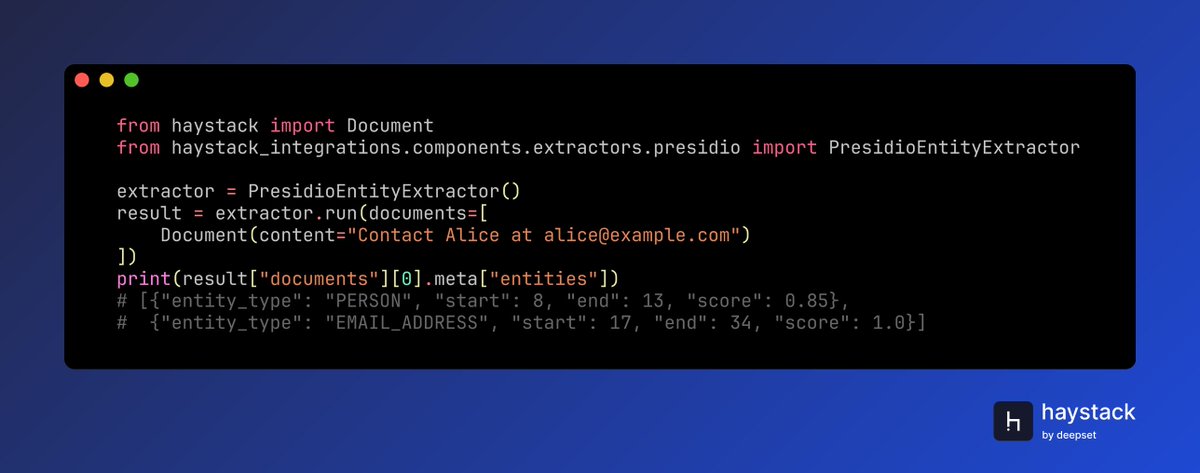
Extract text, tables, and forms from images and PDFs with Amazon Textract in Haystack. AmazonTextractConverter brings @awscloud's OCR capabilities directly into your document processing pipelines. Just pass an image or single-page PDF and ask natural-language questions to extract structured data automatically.
🐍 pip install amazon-textract-haystack 🔗 haystack.deepset.ai/integrat…
5
104
Jun 9
👋 @LiteLLM is now available as a Chat Generator in Haystack. Access 100 LLM providers from a single interface - OpenAI, Anthropic, Groq, Cohere, and more. Switch models and providers without rewriting code.
🐍 pip install litellm-haystack
🔗 haystack.deepset.ai/integrat…
1
2
11
353
Jun 4
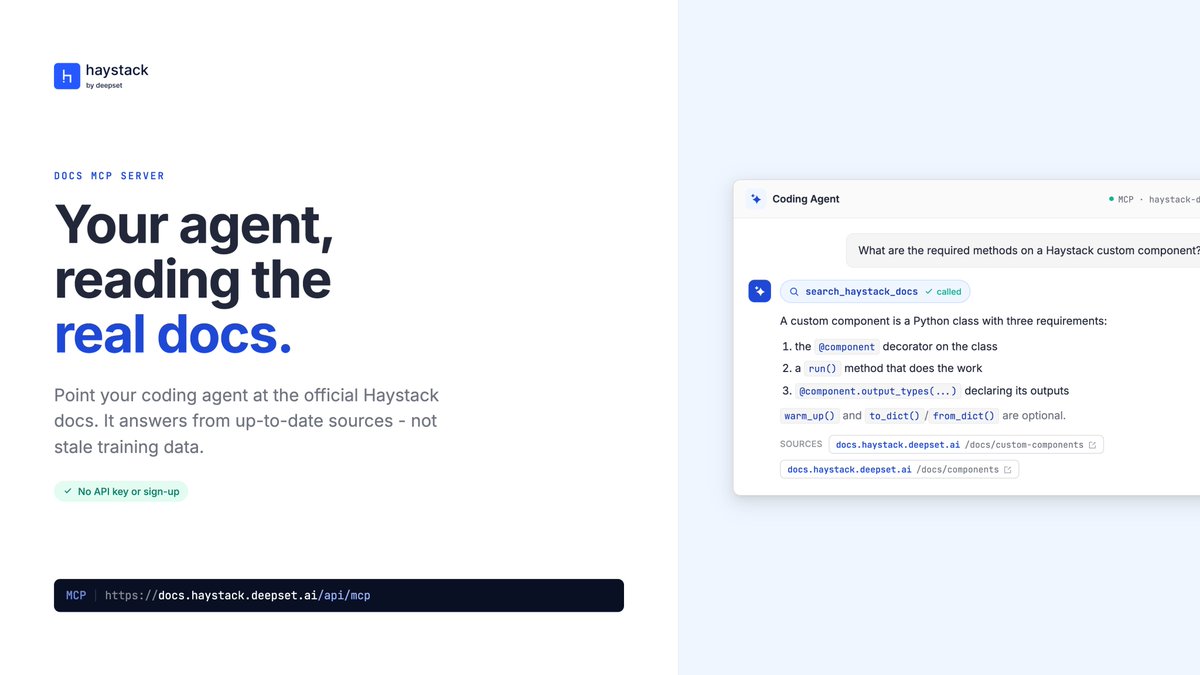
Haystack now publishes a public Model Context Protocol server. Point Claude Code, Cursor, or any MCP-compatible coding agent at it and get real-time access to the latest Haystack docs - no API keys or sign-ups needed.
🖇️ docs.haystack.deepset.ai/doc…
2
2
11
380
Jun 3
Haystack 2.30 is here 📷
Smarter code processing and simpler APIs. Two highlights this time.
1
2
11
395
Jun 3
💬 Simpler ChatGenerator API
All Haystack ChatGenerator components now accept a plain string for the messages parameter, automatically wrapping it in a ChatMessage with the user role. This one-line change eliminates boilerplate and makes switching from Generator to ChatGenerator seamless - no more manual ChatMessage construction. Applies to AzureOpenAIChatGenerator, HuggingFaceAPIChatGenerator, OpenAIChatGenerator, and others, with more rolling out in Haystack Core Integrations soon.
1
3
71
Jun 3
💙 Big thanks to our contributors to this release!
👇 Full release notes haystack.deepset.ai/release-…
3
45
Jun 1
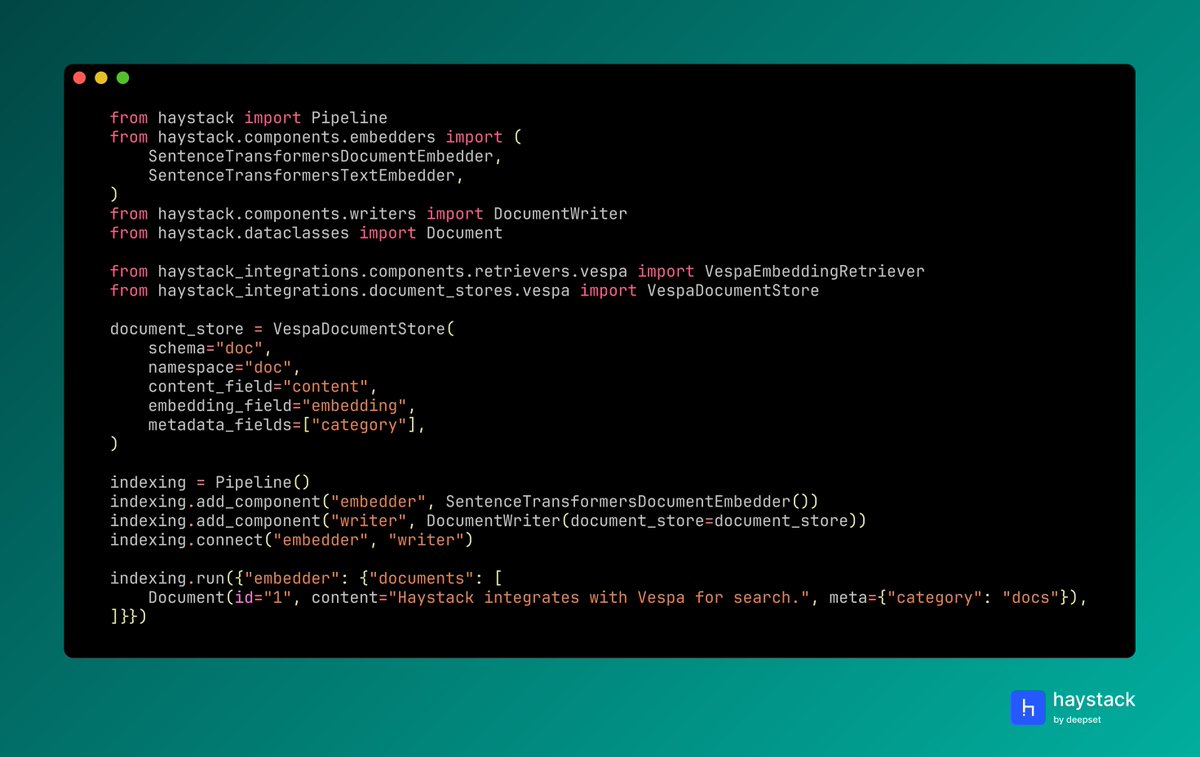
Vespa is now available as a Document Store in Haystack. Use VespaDocumentStore for hybrid and semantic search with a powerful, production-ready engine, and pair it with VespaEmbeddingRetriever to index and retrieve documents directly in your pipelines. Metadata filtering included.
@vespaengine excels at large-scale information retrieval with advanced features like real-time indexing, multi-modal search, and distributed document management - ideal for applications that demand both speed and sophistication.
🐍 pip install vespa-haystack
🔗 haystack.deepset.ai/integrat…
1
9
341
May 29
We're launching the Haystack Ambassador Program 🎉
It's for the people already building, teaching, contributing to the Haystack ecosystem and who want to go further.
🧵 Here's what it is, who it's for, and how to apply
6
3
34
1,724
May 29
What you get 🫱
→ Direct access to the Haystack core team
→ Early previews and feedback on what you're building
→ Support for talks, workshops, and meetups
→ Travel support when community growth is on the line
→ Amplification of your content through our channels
1
5
424
May 29
Applications are open now. We review quarterly, so the sooner you apply the better! ✅
You've been showing up. We want to show up for you.
haystack.deepset.ai/ambassad…
7
347

Can't wait to be back in Bologna for @pyconit this week!
I'm talking about why agents fail and how to fix them, with a live demo of our itinerary agent built using context-engineering patterns and @Haystack_AI!
See you all there 🙌

4
23
1,430
May 26
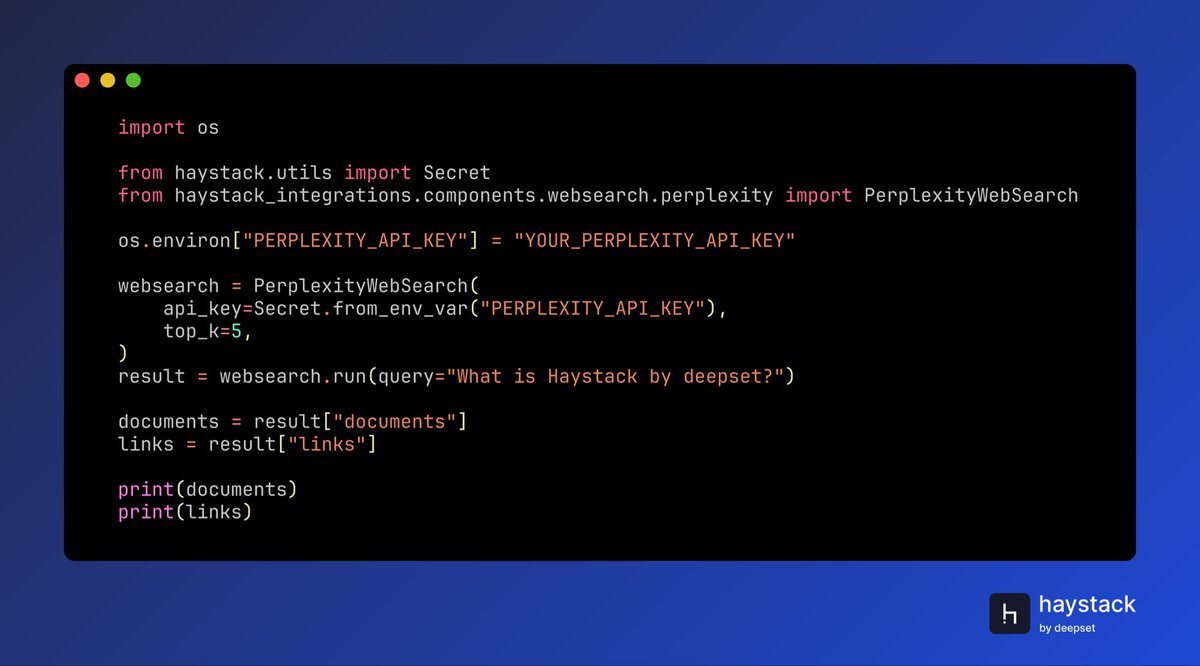
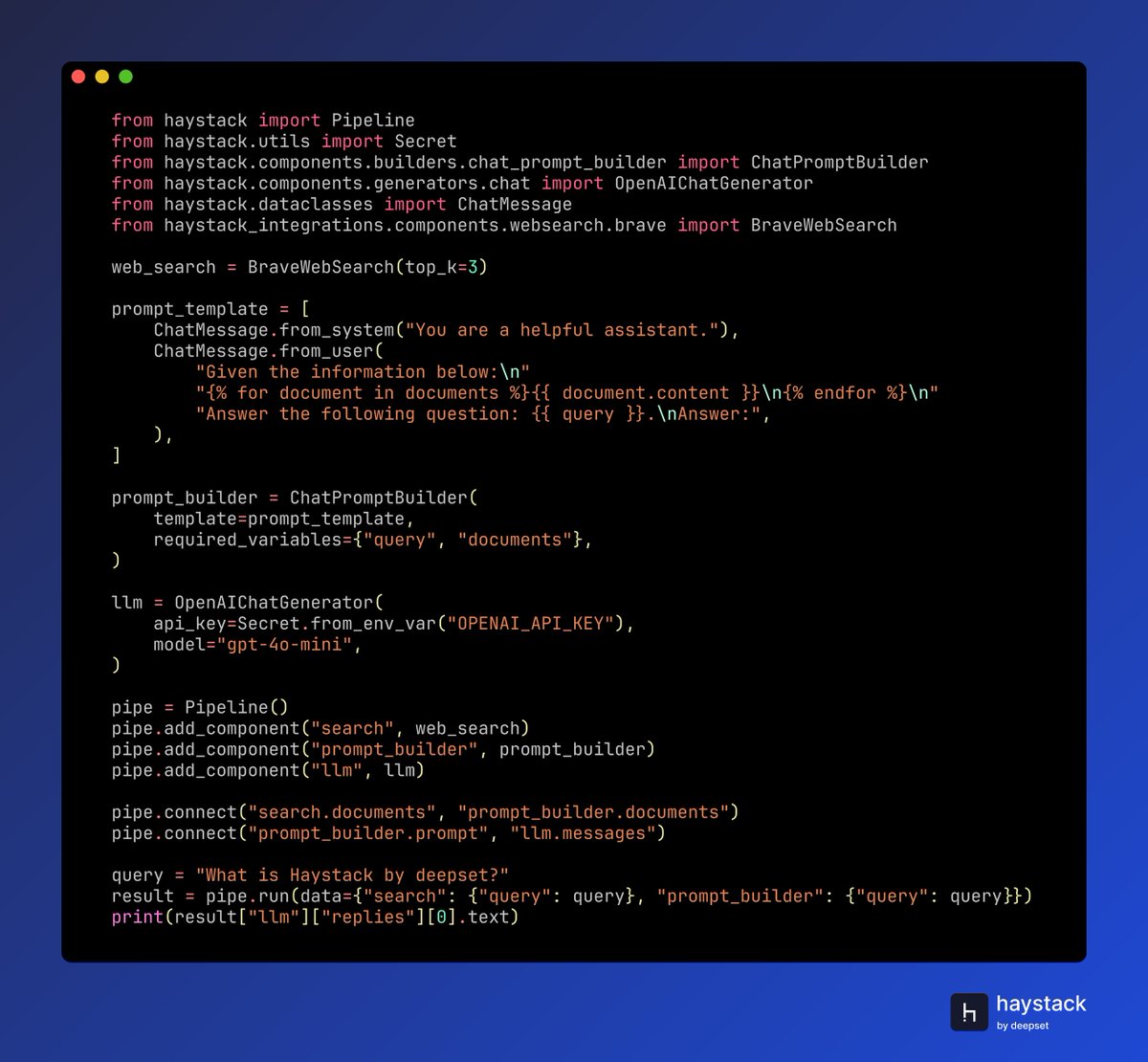
🌐 @perplexity_ai is now integrated with @Haystack_AI!
- `PerplexityWebSearch` to fetch fresh web results directly into your pipelines
- `PerplexityChatGenerator` to power agent conversations with Perplexity's OpenAI-compatible LLM API
- `PerplexityTextEmbedder` and `PerplexityDocumentEmbedder` for semantic embeddings
The web search component is especially useful when your agents need real-time information beyond their training data. Just instantiate it with your API key, set `top_k` results, and pass your query. You get back both documents and source links in a single call. Perplexity's API combines language models with live web access, making it a strong choice for building knowledge-intensive applications that need current information.
🐍 pip install perplexity-haystack
🧩 haystack.deepset.ai/integrat……
📖 docs.perplexity.ai
5
11
1,904
May 25
We're so happy that @e2b is now available as a tool integration in Haystack. Give your agents direct access to isolated Linux sandboxes for code execution, file operations, and command-line interactions - all without leaving your pipeline.
E2BToolset lets agents write scripts, run code, and explore filesystems inside secure, ephemeral environments. Perfect for coding assistants, data processing tasks, or any agent that needs to execute code safely.
🐍 pip install e2b-haystack
🔗 haystack.deepset.ai/integrat…
2
13
990
May 22
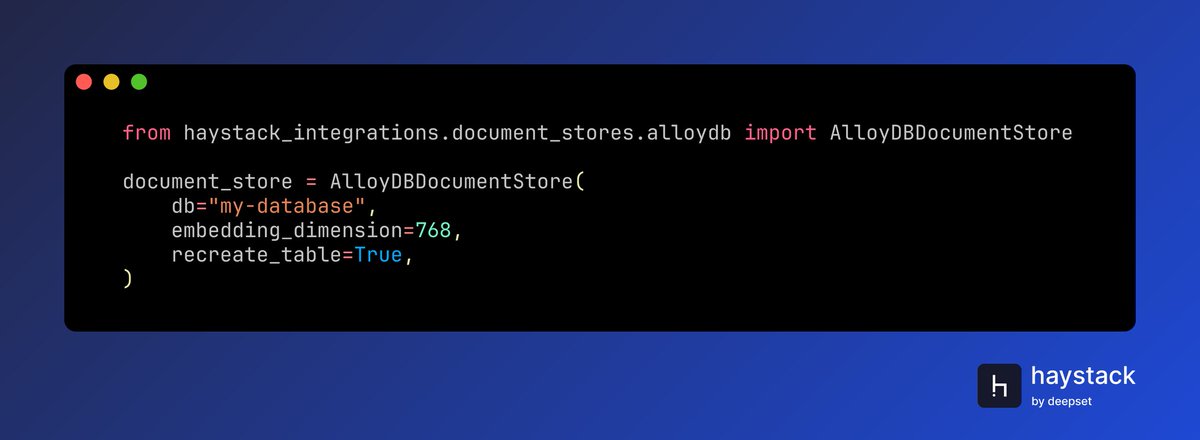
Use AlloyDBDocumentStore to build RAG applications backed by Google Cloud's PostgreSQL-compatible database, with native vector search and full Haystack pipeline integration. Perfect for enterprises running workloads on @googlecloud who need scalable, managed vector storage alongside relational data.
🐍 pip install alloydb-haystack
🔗 Documentation: haystack.deepset.ai/integrat…
6
203
🥳 My talk from @aiDotEngineer Europe is live on YT!!
this was my first ever talk on sovereignty so I'm quite excited to share 💗
I broke down AI sovereignty into 4 pillars to make it clearer and I shared a sovereign @Haystack_AI architecture a checklist for AI systems

8
12
84
6,178
May 21
DoclingServeConverter integrates docling-serve into Haystack pipelines via HTTP, eliminating the need to embed Docling's dependencies in your application. Configure the converter with a docling-serve endpoint, send documents through your pipeline, and receive structured output with Layout and Structure information. This architecture decouples document processing from your main service, enabling independent scaling and reducing deployment overhead.
🐍 pip install docling-serve-haystack
🔗 haystack.deepset.ai/integrat…
@LFAIDataFdn
2
7
305
Haystack retweeted
May 19
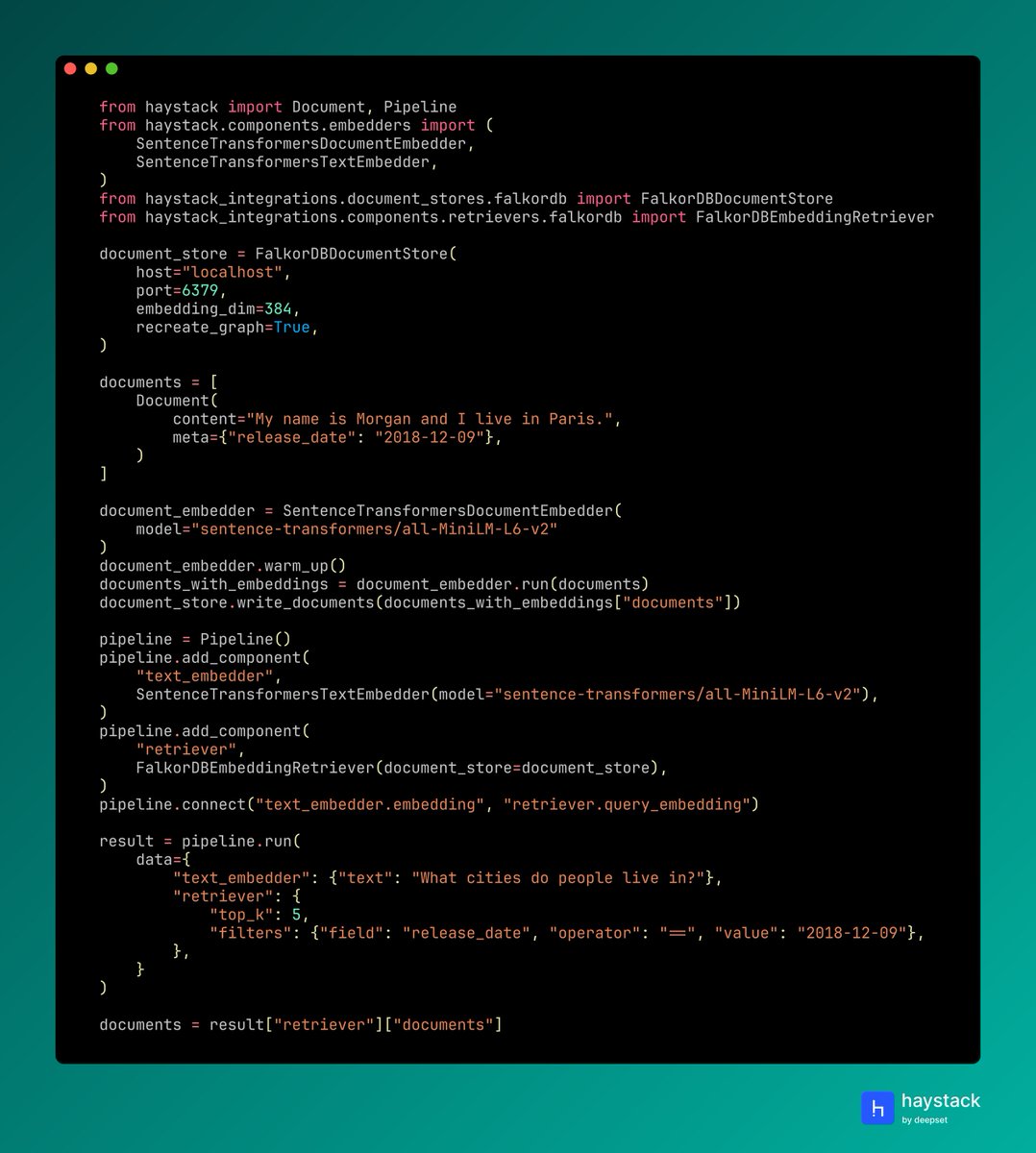
FalkorDB is now available as a Document Store in Haystack. Use FalkorDBDocumentStore to store documents and vectors in a graph format, pair it with FalkorDBEmbeddingRetriever to retrieve documents by semantic similarity, and use FalkorDBCypherRetriever for graph-based queries.
This makes it easy to build retrieval pipelines that leverage both vector search and graph relationships. @falkordb is built as an extension of Redis, making it lightweight and efficient for applications that need real-time graph and vector capabilities.
🐍 pip install falkordb-haystack 🔗 haystack.deepset.ai/integrat…
1
3
8
336