
Neuroscientist. We aim to understd brain networks and brain wiring, using lasers & neuro AI. Prev: policy for @democracypolicy. Personal views. Not a lab acct.
- Tweets 4,504
- Following 824
- Followers 2,664
- Likes 5,416


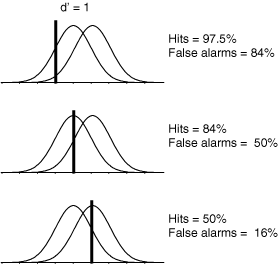











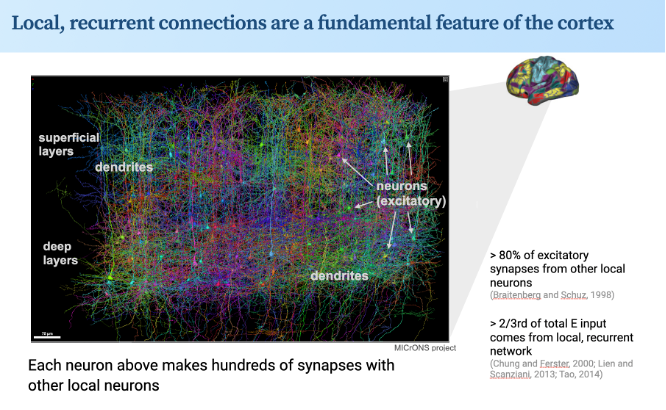
ALT slide format: local, recurrent connections are a fundamental feature of the cerebral cortex
ALT ACKNOWLEDGEMENT OF CONDITIONS OF CONTINUED EMPLOYMENT FO EMPLOYEE MOVED TO SCHEDULE POLICY/CAREER This letter serves as notice that I received information concerning the requirements for continued employment as follows: Agency Name: Position Title: Pay Plan-Series-Grade: . I understand I will serve in an excepted service, Schedule Policy/Career position beginning June 3, 2026. I understand that movement into Schedule Policy/Career will result in me occupying an excepted service position. I understand that my service in this position will be at-will. I understand that my position does not confer appeal rights to the Merit System Protections Board (MSPB) concerning performance, discipline, or any other matter arising under chapters 23, 43, and 75 of title 5, United States Code. I understand that prohibitions on prohibited personnel practices will be enforced by the Office of General Counsel [or agency equivalent position] and not the Office of Special Counsel. I understand that the above


ALT ARTICLE | EDITOR'S COMMENTARY Pharma CEO silence is complicity in the destruction of U.S. science Why leaders of the U.S.’s biggest drug companies should use their influence to stop a ruinous proposal