
Joined March 2025
- Tweets 5,761
- Following 4
- Followers 18,691
- Likes 35
2,641 Photos and videos
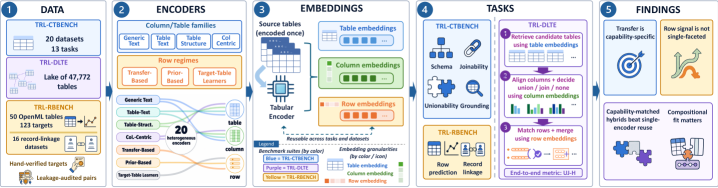








TRL-Bench: finally comparing tabular encoders fairly
A unified benchmark that turns 20 heterogeneous encoders into directly comparable embedding models through one shared interface.
16 tasks.
87 datasets.
No universal winner.
1
3
14
1,017
Paper: huggingface.co/papers/2606.0…
Datasets:
huggingface.co/collections/l…
Code:
github.com/LOGO-CUHKSZ/TRL-B…
2
397
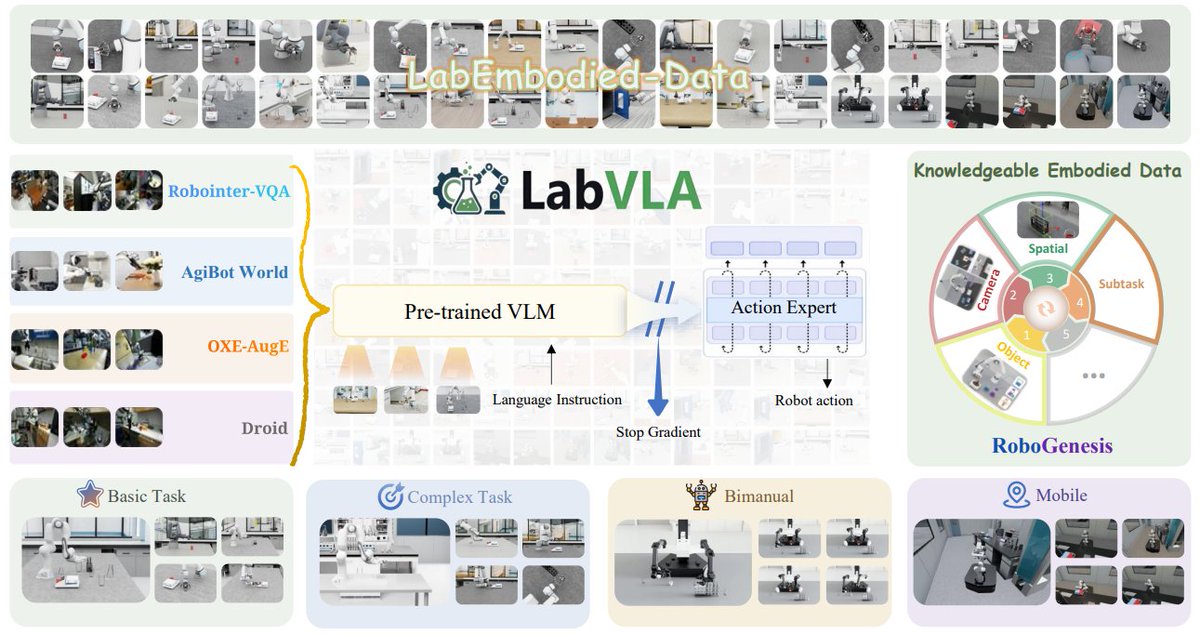
LabVLA: Grounding VLA models in scientific laboratories
RoboGenesis builds 10K lab scenes across 16 robot types. LabVLA pairs a Qwen3-VL backbone with a DiT flow-matching expert, reaching 71.1% success on LabUtopia and transferring to real Franka robots.
1
6
23
1,031
FlashMemory-DeepSeek-V4
Lookahead Sparse Attention cuts the KV cache by over 90% at 500K context, compressing it to just 13.5% of full size while maintaining or improving accuracy on RULER, LongBench-v2, and LongMemEval.
3
4
46
1,678
This lightweight retriever is on Hugging Face, sparsifying DeepSeek-V4's CSA KV-cache on the fly to keep only ~10–15% resident on GPU.
Paper: huggingface.co/papers/2606.0…
Model: huggingface.co/libertywing/F…
2
3
631
FORT-Searcher
A new framework for training deep search agents that resist shortcuts.
By controlling four key risks during data synthesis, it forces models to search longer before answering.
SFT-only training yields top performance among comparable open-source agents.
3
7
31
1,857
Paper: paperswithcode.co/paper/2606…
Code: github.com/RUCAIBox/FORT-Sea…
Datasets and checkpoints coming soon to Hugging Face.
3
905
WeaveBench
Microsoft Research Asia introduces
114 long-horizon tasks that force agents
to interleave GUI and CLI in one trajectory.
The same frontier models
that score over 78% on OSWorld-Verified
collapse to 41.2% on WeaveBench.
2
10
21
1,700
Outcome-only grading
overestimates agent performance
by 10-20 percentage points.
WeaveBench uses a trajectory-aware judge
that audits every step.
Project: weavebench.github.io
Paper: paperswithcode.co/paper/2606…
Dataset: huggingface.co/datasets/wanl…
2
4
717
MiniMax MaxProof exceeds human gold-medal threshold on math olympiads
A population-level test-time scaling framework that searches over candidate proofs through tournament selection. Scores 35/42 on IMO 2025 and 36/42 on USAMO 2026.
1
8
34
1,744

Jun 13
ResearchClawBench
A benchmark for end-to-end autonomous research.
40 real tasks across 10 domains test if AI agents can rediscover published science from raw data alone.
Top agents average just 21.5 out of 100.
The frontier for automated discovery is wide open.
3
11
32
2,356
Jun 13
Paper: paperswithcode.co/paper/2606…
Dataset: huggingface.co/datasets/Inte…
Community: huggingface.co/spaces/Intern…
Can your agent beat the 21.5 frontier?
1
3
899
Jun 13
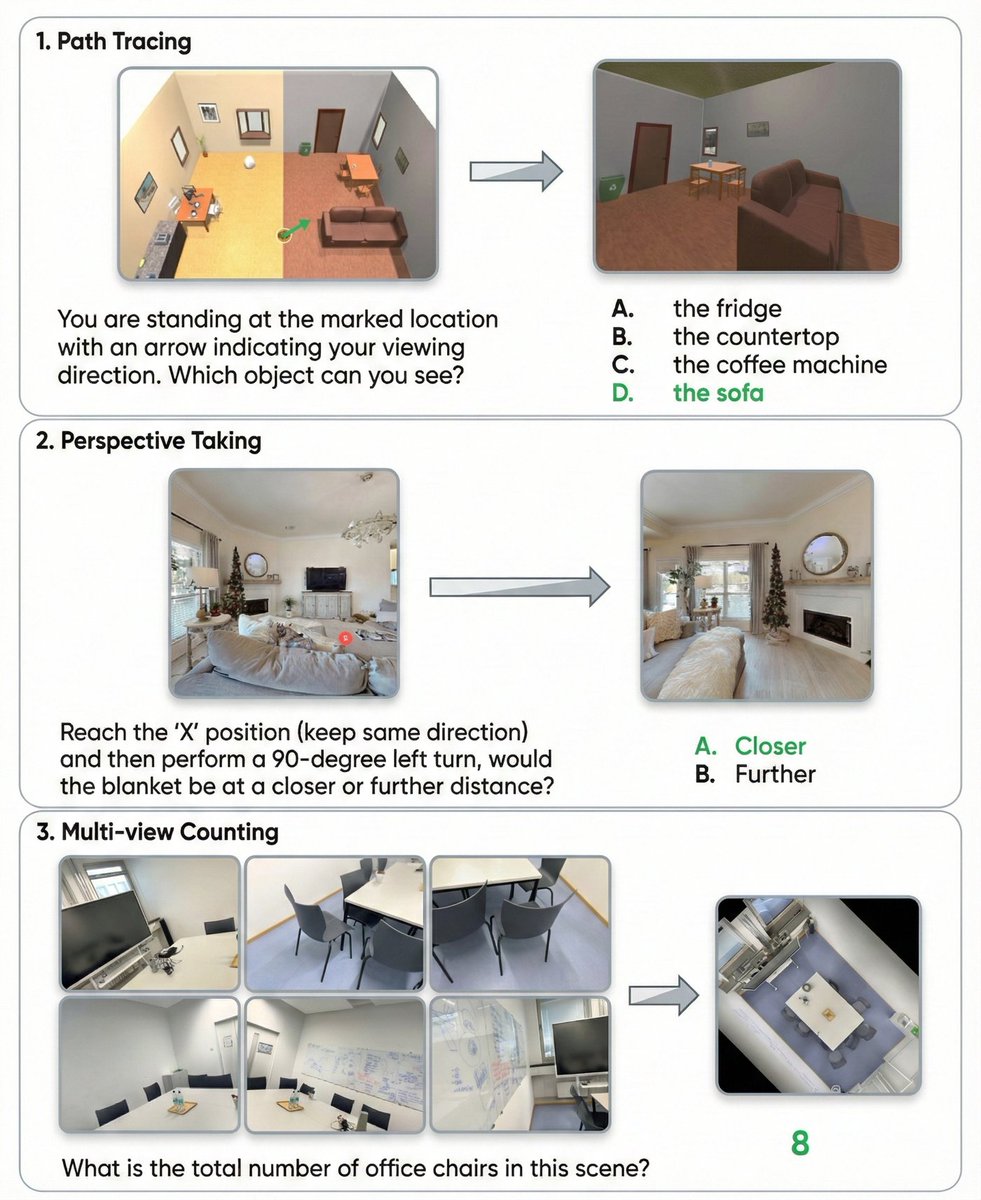
Imaginative Perception Tokens
UW, OpenAI, Microsoft, and AI2 teach VLMs to imagine unseen visual perspectives.
These tokens boost spatial reasoning over text chain-of-thought across perspective taking, path tracing, and multiview counting.
No images are generated at inference time.
2
8
48
2,595
Jun 13
Explore the paper, data, and benchmarks
paperswithcode.co/paper/2606…
huggingface.co/collections/w…
huggingface.co/collections/w…
1
6
965
Jun 12
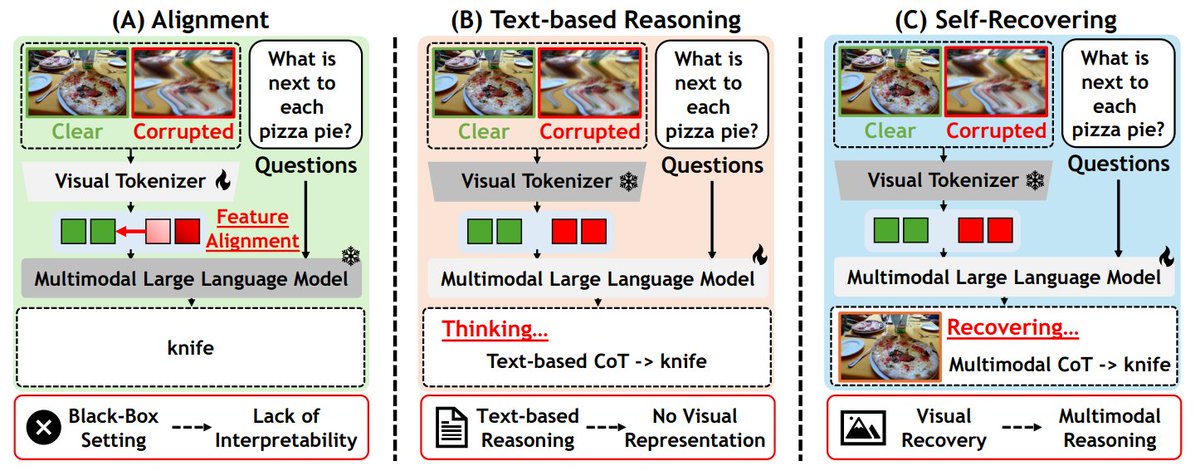
Robust-U1 equips multimodal LLMs with visual self-recovery
Corrupted images break understanding.
This ICML work trains models to self-restore pixels.
Recovery uses supervised training, RL with pixel and semantic rewards, and joint reasoning over both views.
1
5
22
2,239
Jun 12
Discuss: huggingface.co/papers/2606.0…
Demo: huggingface.co/spaces/Jiaqi-…
Models: huggingface.co/Jiaqi-hkust/R…
3
1,341
Jun 12
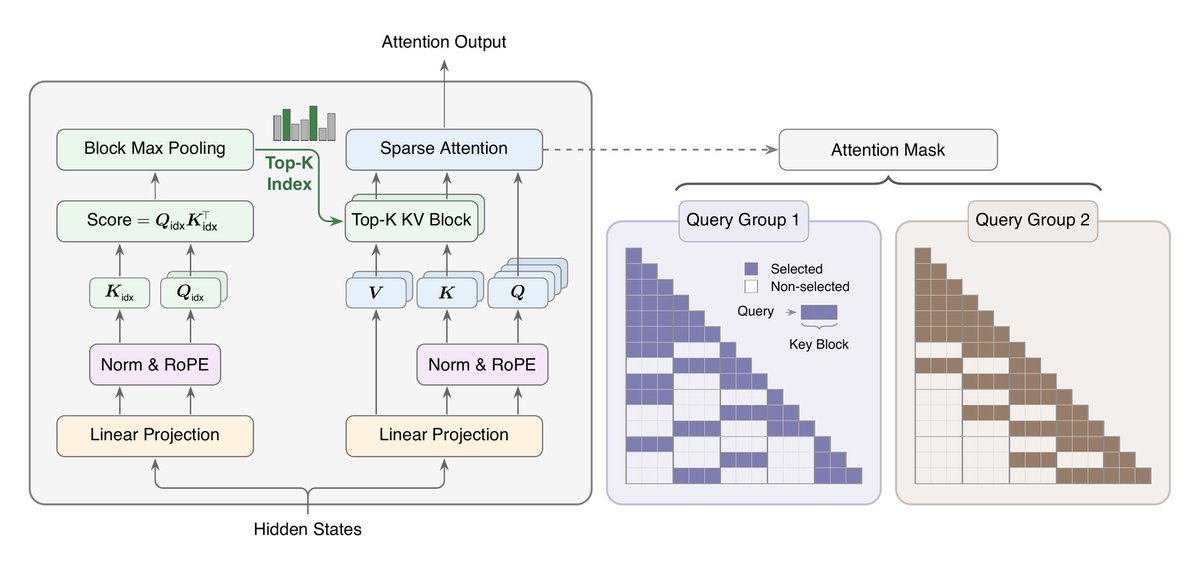
MiniMax released MSA for million-token contexts
Blockwise sparse attention with an Index Branch that scores and selects Top-k KV blocks per GQA group, and a Main Branch that attends only to those blocks. At 1M tokens on a 109B model, it cuts per-token attention compute by 28x and delivers 14x prefill speedups on H800 GPUs.
2
9
51
2,278
Jun 12
Get the 109B MiniMax-M3 model powered by MSA on Hugging Face
huggingface.co/MiniMaxAI/Min…
The open-source CUDA kernels for dense and sparse attention on NVIDIA SM100 are also available
paperswithcode.co/paper/2606…
1
3
686