
The Full Stack AI Cloud. Secure Private Cloud, on-demand NVIDIA VMs, and AI Studio - built for teams that don't compromise.
Joined June 2023
- Tweets 3,112
- Following 96
- Followers 643
- Likes 2,827
648 Photos and videos












Pinned Tweet

Mar 4
Today, Hyperstack EU1 (Sweden) comes online with NVIDIA RTX PRO™ 6000 Blackwell Server Edition capacity available on demand and via reservation.
EU1 expands Hyperstack’s European footprint with infrastructure optimised for high-end visualisation, GPU virtualisation, and large-scale inference workloads.
EU1 has been designed with future private deployments in mind. The region is designed with the power, cooling, and data centre capacity required for next‑generation NVIDIA platforms, with reserved space to scale NVIDIA B300 deployments as Hyperstack Secure Private Cloud comes online.
More details on Secure Private Cloud will follow.
EU1 (Sweden) Now Live.
👉 Enquire about EU1 capacity and early Secure Private Cloud discussions: bit.ly/4rSeYsK

2
8
188
Jun 11
We're taking the stage at @RaiseSummit. Our CPTO, Cory Hawkvelt, joins the panel:
Sovereign Stacks: Building Trusted AI on National Terms
July 8th | 2:00 PM | Ada Lovelace Stage
As AI adoption accelerates across Europe, the question of where your infrastructure lives - and who has access to it - has never been more consequential. Cory joins leaders from Lenovo, Together AI, Digital Realty, and DDN to explore how organisations are making infrastructure decisions that determine not just performance, but sovereignty and long-term AI competitiveness.
Pre-book a meeting with us: bit.ly/3RQBq8y
#Hyperstack #RAISE2026 #RAISESummit #EnterpriseAI
1
3
24
Jun 10
Same model. Same SLA. Same code.
So why was only one team answering to their regulator?
Read the full case study:
hyperstack.cloud/blog/case-s…
1
2
23
Jun 4
We're heading to #RAISE2026 in Paris.
Enterprise AI is shifting from experimentation to execution. @Hyperstack is the full-stack AI cloud helping organisations move from PoC to production on NVIDIA Blackwell & Blackwell Ultra GPUs.
Find us at Booth 14A, 8–9 July. Book a meeting 👇
bit.ly/3PTBt2J
#Hyperstack #EnterpriseAI #NVIDIA
2
4
78
Jun 2
We're attending The AI Summit London, 10–11 June, Tobacco Dock.
If you're working in AI, you already know the gap between ambition and infrastructure is growing. Workloads are scaling faster than planned and access to compute at the right cost is becoming one of the defining questions right now.
If you're attending and want to talk about how we can support with compute, come find us.
#TheAISummit #Hyperstack
1
3
4
58
May 26
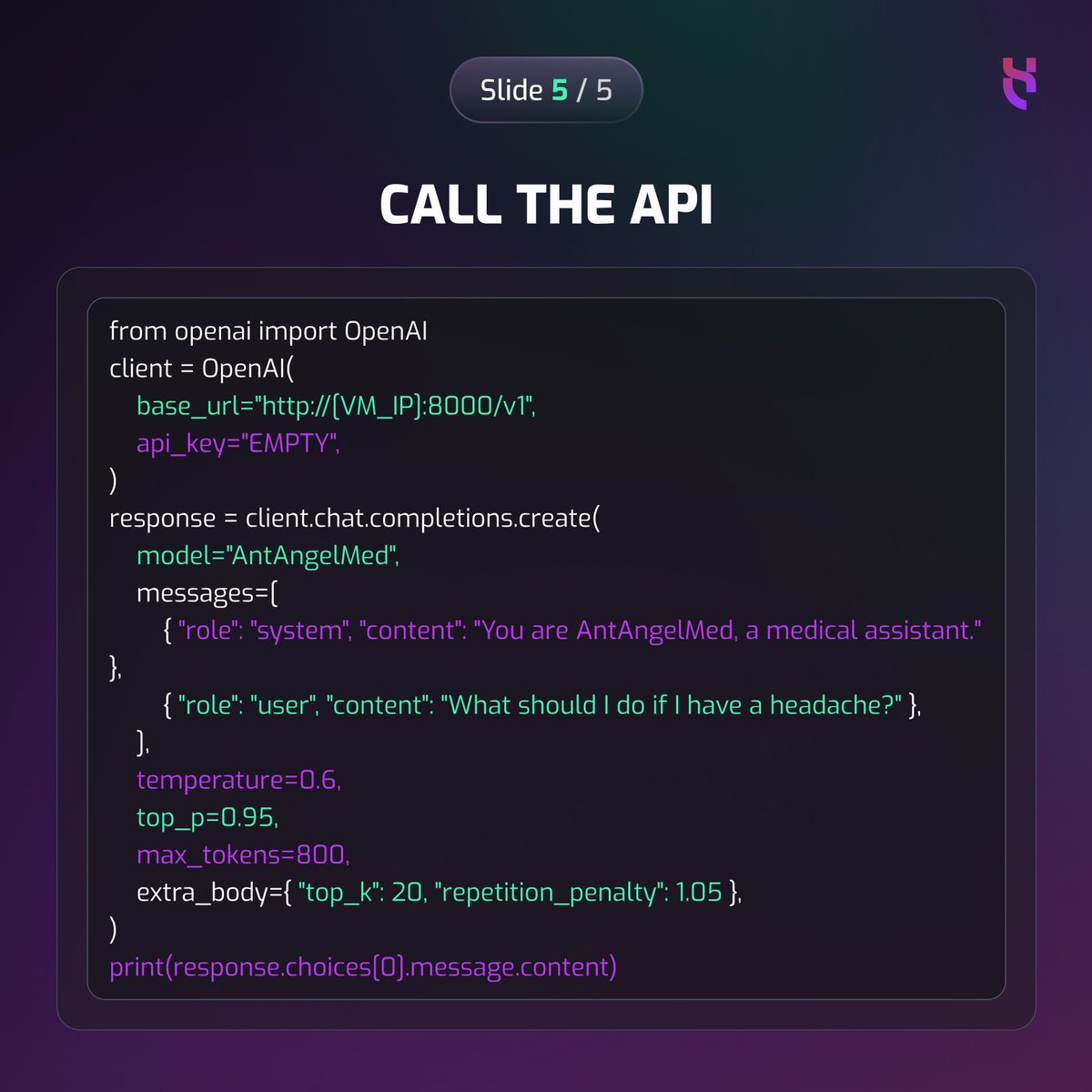
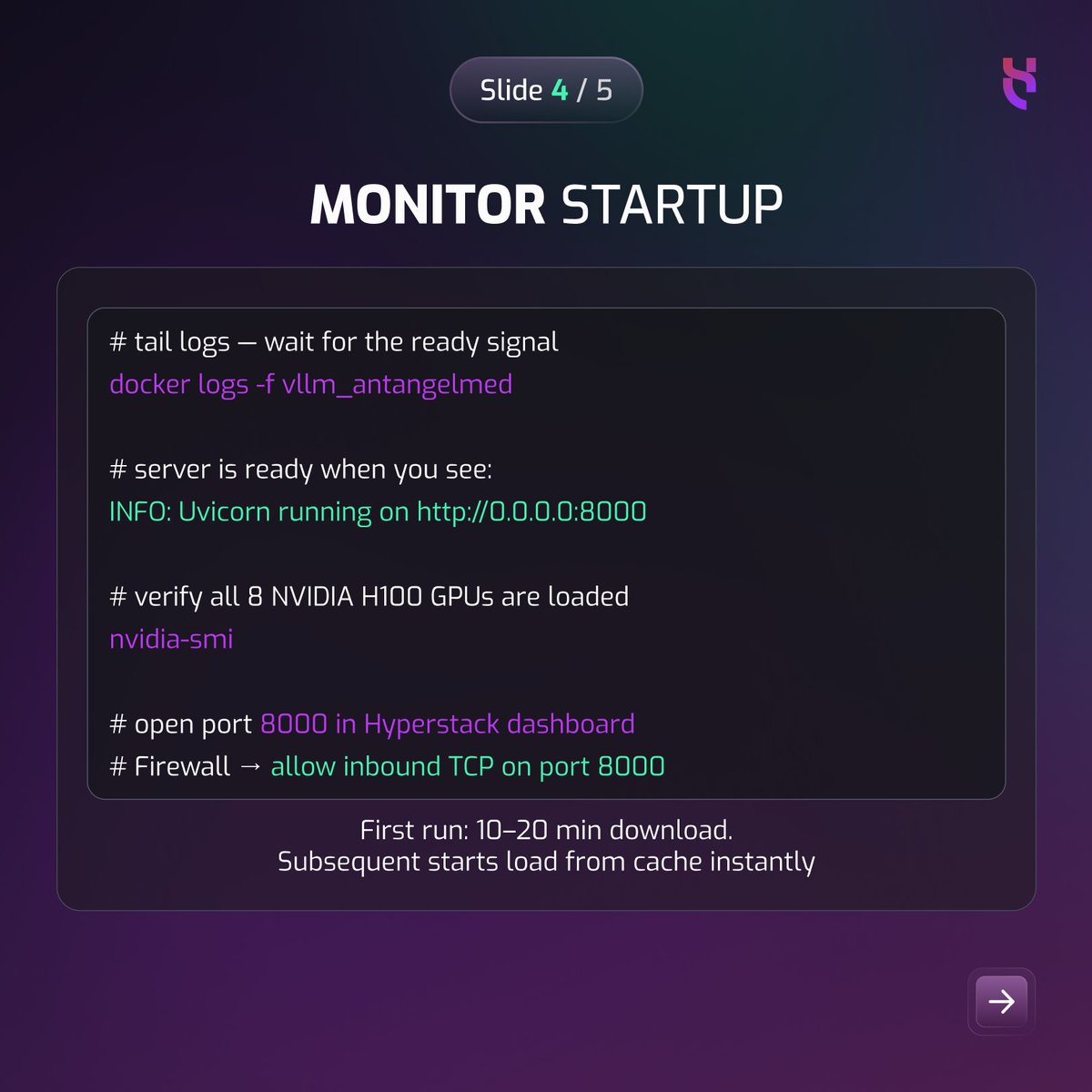
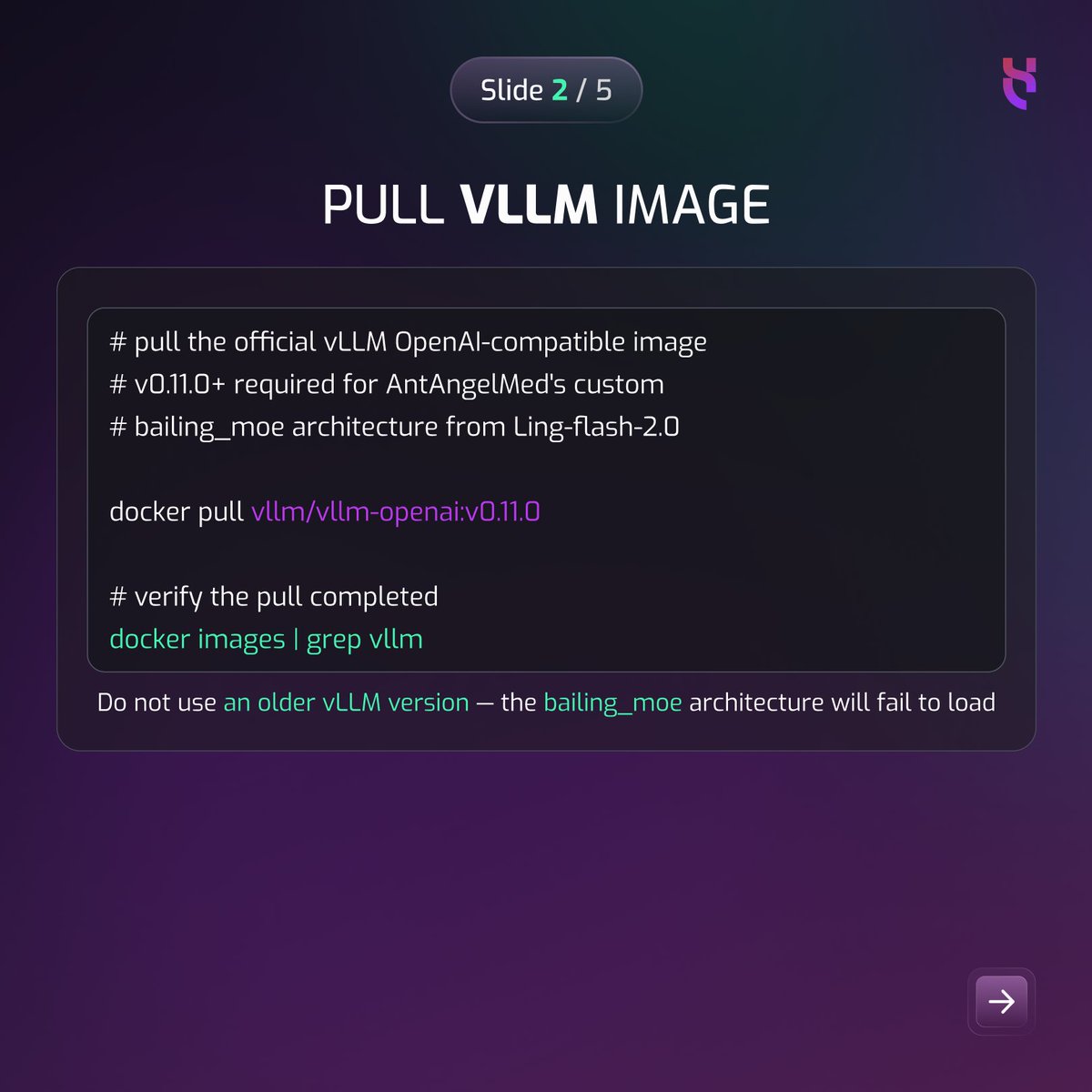
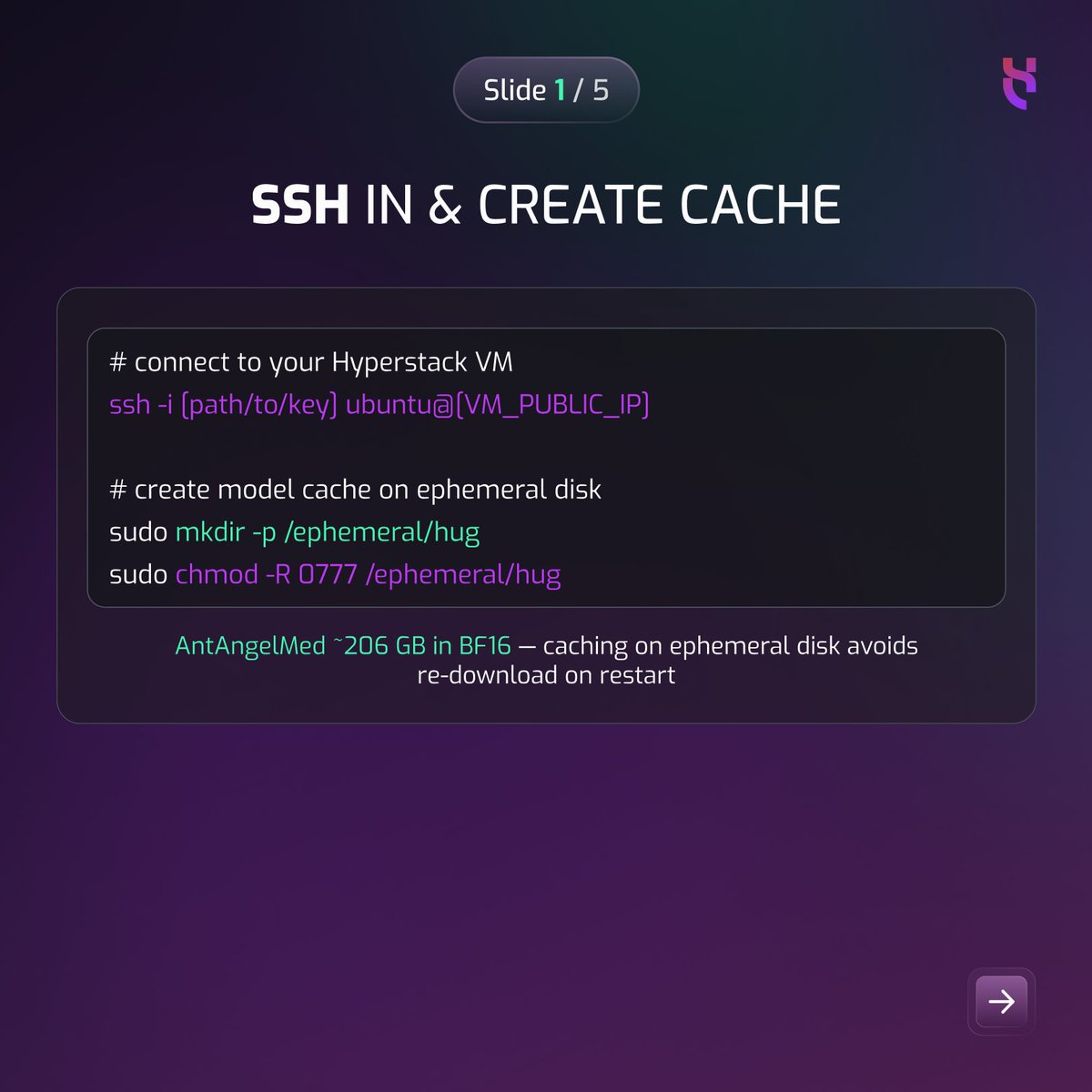
World's first open-source 100B medical LLM just dropped.
AntAngelMed: #1 on OpenAI HealthBench. Here's how to run it on 8× NVIDIA H100s in 5 commands.
Full tutorial: bit.ly/42T8sHi
#MedicalAI #Hyperstack
2
2
6
105
May 25
ISC is where the teams running the world's most demanding workloads show up.
And that’s where we fit in.
Secure Private Cloud and Managed Clusters powered by NVIDIA GPUs provide the backbone for workloads that can't compromise.
Genomics. Drug discovery. Climate modelling. Energy simulation. Large-scale AI training. If that's you, catch us at Booth A39, 22nd–26th June.
Book a meeting now: bit.ly/3RrUw4C
#Hyperstack #ISC26
1
4
61
May 22
Shared infrastructure works. Until InfoSec asks:
“Can you prove no one else touches this?”
One answer closes the deal. The other delays (or worse, derails) it.
See how a single-tenant Secure Private Cloud gets you the right answer: bit.ly/3PYS70N
6
59
May 21
Our Head of Partnerships, Ashley Williams, is heading to the Qwen Conference in Singapore this Monday.
If you're attending and want to talk AI infrastructure, token economics or building out your AI stack, get in touch.
#QwenConference2026
3
49
May 19
Hamburg is about to get a lot more accelerated.
Catch Hyperstack at ISC High Performance 2026 — Booth A39 | 22–26 June.
Blackwell-powered infrastructure for HPC, genomics, AI training and production inference — from single-tenant SPC to managed Kubernetes & Slurm clusters.
Book a meeting: hyperstack.cloud/events/isc-…
#Hyperstack #ISC26 #ISCHPC
1
3
5
136
May 8
295 billion parameters. 21B active per token. 600 GB BF16 checkpoint, too large for a single node.
We deployed Hy3-preview on Hyperstack using multi-node Kubernetes with 16 NVIDIA H100s across two worker nodes, hybrid Tensor Expert Parallelism and a 600 GB BF16 checkpoint loaded from local NVMe.
In this tutorial:
→ Multi-node Kubernetes cluster on Hyperstack (two 8x H100-80G PCIe-NVLink)
→ LeaderWorkerSet API for coordinated 2-node inference
→ vLLM with native multi-node tensor parallelism and MTP speculative decoding
→ 256K token context window with three reasoning tiers (no_think / low / high)
→ Multi-agent code review pipeline with parallel specialist agents and tool calling
→ Plugging into Claude Code, OpenClaw, and OpenCode as a local backend
80.6 on SWE-Bench Verified. 34.86 on LiveCodeBench v6.
Full tutorial on the blog: Deploy Hy3-preview on Hyperstack: A Multi-Node Kubernetes Guide
#Hyperstack #Hy3preview
3
110
May 7
One model. Video, audio, images, and documents - from a single endpoint.
We deployed NVIDIA Nemotron 3 Nano Omni on Hyperstack and put its multimodal pipeline to work.
In this tutorial:
→ vLLM serving on a single NVIDIA H100 80GB (62 GB BF16 checkpoint)
→ 256K token context window with native reasoning mode
→ PDF extraction - structured JSON from complex financial documents
→ Hour-long audio transcription with word-level timestamps and action-item extraction
→ Video summarisation and temporal Q&A from a single prompt
→ Disabling thinking mode for latency-sensitive tasks
67.04 on OCRBenchV2. 89.39 on VoiceBench. 72.2 on Video-MME. One deployment.
Full tutorial on the blog: bit.ly/4duBhjd
#Nemotron #MultimodalAI
1
7
119
May 6
1.6 trillion parameters. 49B active per token. Too large for a single node.
We deployed DeepSeek-V4-Pro on Hyperstack using multi-node Kubernetes - 16 NVIDIA H100s across two worker nodes, hybrid Data Expert Parallelism, and a 960 GB FP4 FP8 checkpoint loaded from local NVMe.
In this tutorial:
→ Multi-node Kubernetes cluster on Hyperstack (2x 8x NVIDIA H100-80G PCIe-NVLink)
→ LeaderWorkerSet API for coordinated 2-node inference
→ vLLM with hybrid DEP topology and MTP speculative decoding
→ 1M token context window with three reasoning tiers
→ Long-horizon autonomous code refactoring with self-correction
→ Plugging into Claude Code, OpenClaw, and OpenCode as a local backend
80.6 on SWE-Bench Verified. 93.5 on LiveCodeBench v6.
Full tutorial on the blog: bit.ly/4f1jamb
#DeepSeek #AgenticAI
2
9
128
May 5
Running Kubernetes or SLURM in-house is a full-time job.
Hyperstack Managed Cluster Platform hands you a fully managed cluster environment - delivered at the orchestrator layer, so your team focuses on models, not maintenance.
GPU infrastructure. Fully managed. Ready to scale.
Enquire now 👉 bit.ly/3QPhHp8
#ManagedKubernetes #SLURM

2
5
63
Apr 29
1 trillion parameters on 8 GPUs. Here's what that looks like.
We deployed Kimi K2.6 on Hyperstack - @Kimi_Moonshot's open-weight agentic model. In this video:
→ vLLM serving on 8x NVIDIA H100-80G PCIe
→ 595 GB of INT4 weights loaded from ephemeral NVMe in ~6 minutes
→ Autonomous multi-step refactoring with self-correction
→ Coding-driven design - single prompt to working website
→ Local backend for Claude Code, OpenClaw and Kimi Code CLI
32B active parameters per token. 256K context window. 300 sub-agents in a single run.
Full tutorial on our blog: bit.ly/4cFJVLF
#KimiK2 #MoonshotAI
1
9
245
Apr 29
Most inference bottlenecks aren't model problems. They're engineering problems - and they have well-understood solutions.
We broke down the 5 techniques that close the gap between a validated model and a production-ready deployment.
The difference between a model that works and one that runs efficiently at scale is in the implementation details. Scroll down for the specifics 👇
#MLOps #Inference
(🧵1 of 7)

1
1
8
77

