
103 Photos and videos












Ibis offers an API similar to @pandas_dev to connect to SQL databases and big data systems.
More info: ibis-project.org/
3
21
86
Ibis 10.0.0 is out!
pip install ibis-framework==10.0.0
Lots of new features, bug fixes and two new backends: Amazon Athena and Databricks!
Check out the release notes here: ibis-project.org/release_not…
7
18
1,285
New blog posts 2/2: Dynamic UDF Rewriting with Predicate Pushdowns
ibis-project.org/posts/udf-r…
Check 'em out!
1
7
441
New blog posts 1/2: Does Ibis Understand SQL?
ibis-project.org/posts/does-…
1
2
365
With the latest version of @pyodide (0.27.1), you can run
%pip install ibis-framework[duckdb]
to get an expressive, lightning-fast, and *entirely-in-browser* dataframe API!
Give it a try at ibis-project.org/tutorials/b…
1
12
504
Ibis retweeted

2 Dec 2024
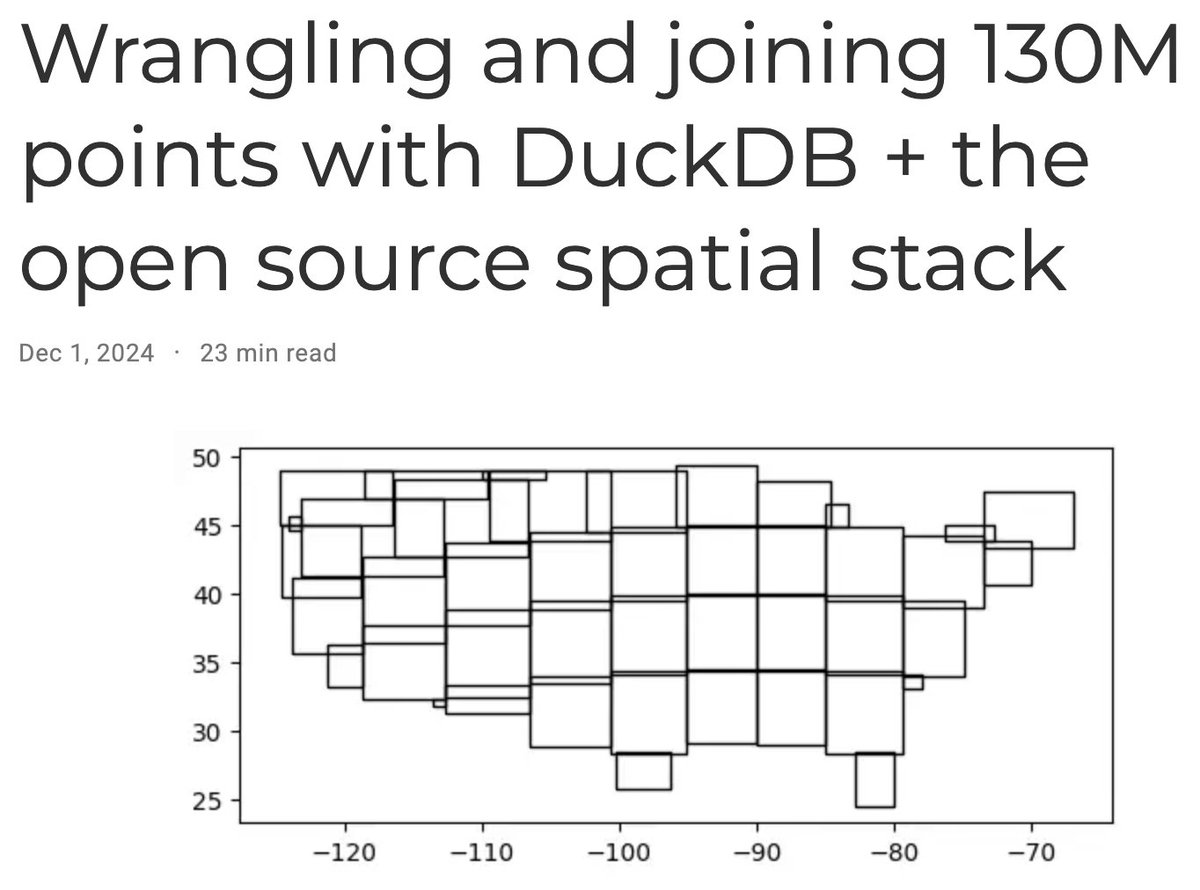
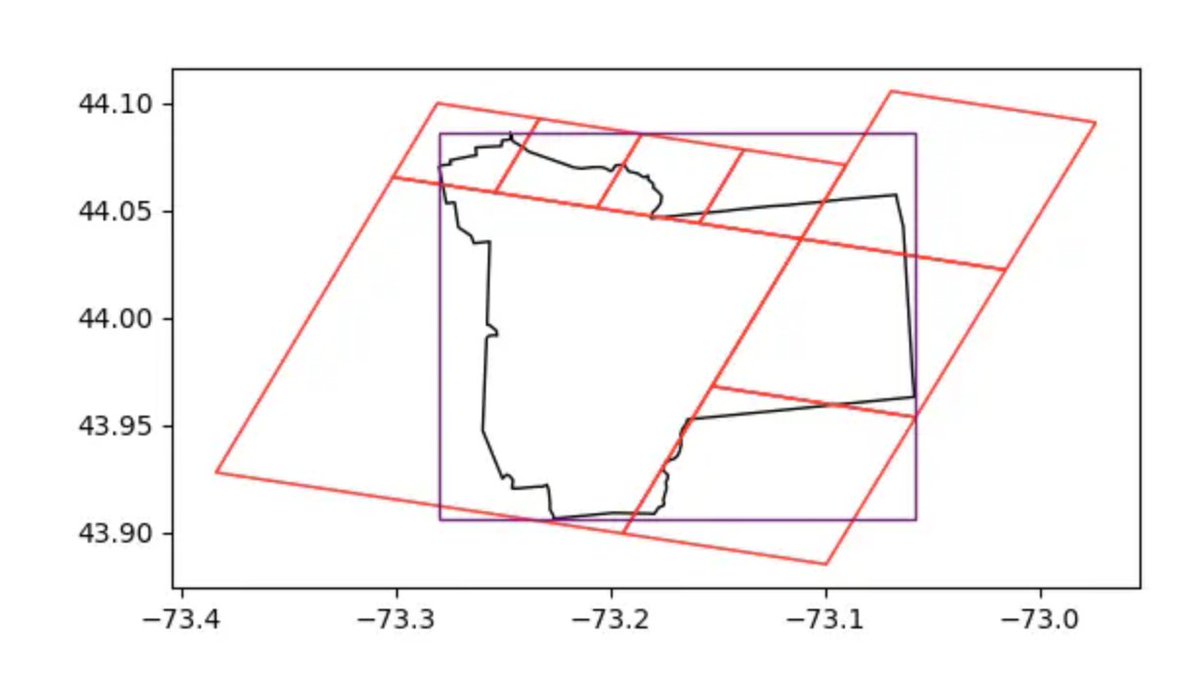
First blog post in a long time! I started writing a post ~2 years ago on adventures counting 130M U.S. buildings by zipcode and finally circled back to write it up. Everybody is a winner really, but @duckdb @IbisData , @ApacheArrow, and @GeoParquet were essential throughout!
2
11
53
3,733
Ibis retweeted

4 Dec 2024
Hi y'all, I'll be talking at #DuckCon on January 2025.
I'll be sharing how to leverage the power of @duckdb's geospatial capabilities while staying within the Python ecosystem using @IbisData . I’ll show you how to work with GeoParquet data and create nice maps in your laptop.

1
5
27
2,244
Ibis retweeted

9 Sep 2024
no code transformations using marimo's mo.ui.dataframe and @IbisData!
Pass in any Ibis dataframe to mo.ui.dataframe to display a UI for different filters/transformations and get the filtered result back in Python. Plus, you can see the SQL statement generated by Ibis!
3
16
1,423
It's never been a better time to get involved with Ibis! If you need Python dataframes that work on the best local engines (@duckdb, @ApacheDataFusio, @DataPolars) and distributed/cloud platforms (@ApacheSpark, @SnowflakeDB, @ClickHouseDB, @trinodb), give us a try!
5
40
5,279

The "Tools don't matter" argument falls flat in Data Engineering and ML.
- Working with large datasets on a Spark cluster can quickly shift your focus from business problems to infrastructure challenges.
- Using Pandas for 10GB data demands huge RAM, but switching to @duckdb or Polars can handle it with much less.
- Orchestrating 50 jobs with Airflow is great, but for a few offline tasks, cron can do the job without the overhead.
- Assuming all SQL is the same was a major mistake for me: different databases aren't always interchangeable, and I now appreciate @IbisData .
Don't underestimate the learning curve of new technologies. Choosing the right tools requires careful consideration of your team's stack and needs. Let the team explore before deciding, but never assume switching tools is easy—it’s not.
3
3
73
6,397
Want to work with Python dataframes on a trillion rows of data in someone else's high-performane OLAP database? Check out our latest blog using Ibis, @ClickHouseDB , and Shiny for Python to build an interactive dashboard on the PyPI downloads dataset: ibis-project.org/posts/bette…
3
34
4,122
Ibis retweeted

1 Sep 2024
2
11
885

end of an era, for new project think seriously of using a new Dataframe Engine, there are plenty of choices, ibis will drop support for Pandas
ibis-project.org/posts/farew…
7
14
103
12,602
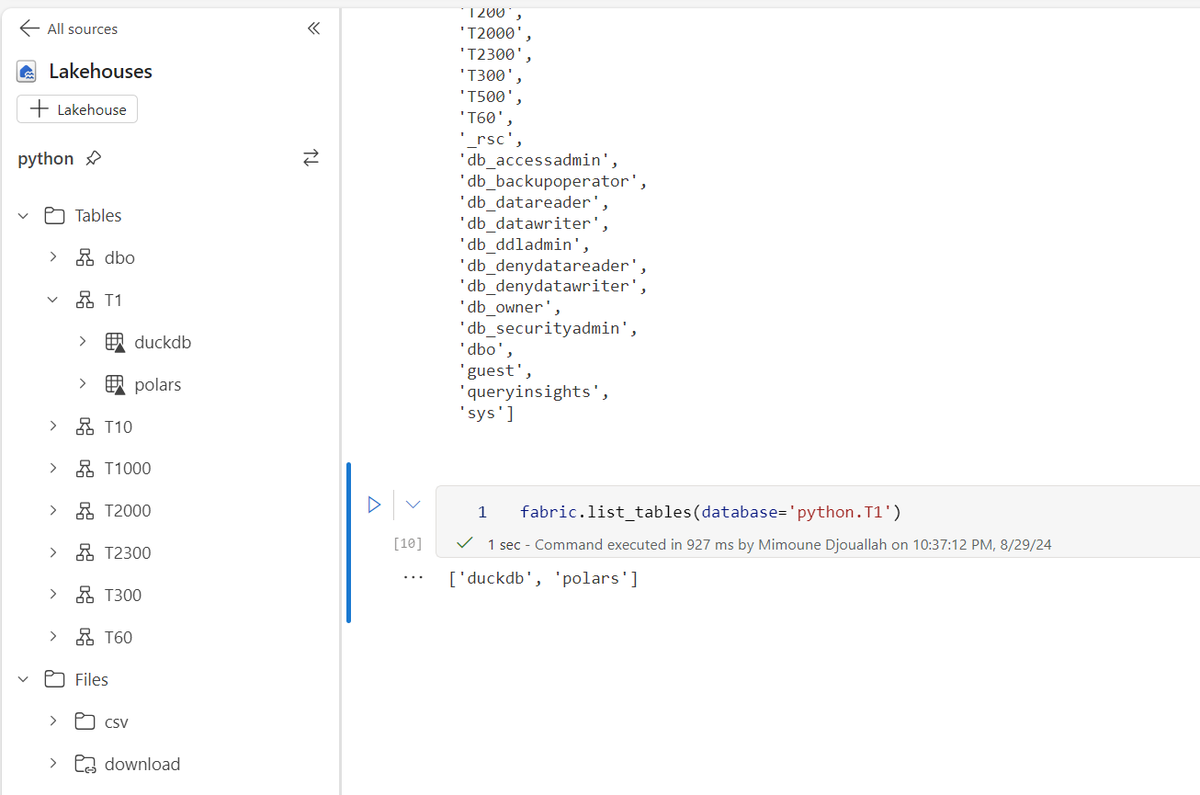
@IbisData support is very rudimentary but you can connect to #microsoftfabric DWH, list catalog, run sql etc
1
3
6
1,050
Ibis retweeted
27 Aug 2024
My @SciPyConf talk: @IbisData and @duckdb geospatial: a match made on Earth! is on youtube. (there was a problem with the recording, apologies about the yellow background)
#geospatial
youtu.be/xQnHhPMgWdM
1
7
17
2,450
Here are a few reasons why I prefer using Ibis over Pandas/@DataPolars ( bdw I still use Polars or Data Fusion as the engine )
- @IbisData is lightweight and directly executes queries on the underlying databases, functioning more as a result transporter than a heavy framework.
- While Ibis may be relatively new, the code it generates is notably cleaner compared to SQLAlchemy.
- If you've ever encountered debates about switching databases or complaints about database costs, Ibis renders these discussions irrelevant. You can switch databases without needing to change your code, everything stays exactly the same.
- As for concerns about Ibis falling behind or its open-source model changing, I'm focused on the present. Right now, Ibis offers a fantastic, lightweight interface. And who knows? In the future, AI might take over everything anyway! 😁
1
3
14
1,382
Ibis retweeted

21 Aug 2024
The other popular choices are Confidence and Ambrosia. They slightly differ in features: tea-tasting covers some methods not covered in these packages, and vice versa. Ultimately, tea-tasting aims to cover all the essential methods.
But the biggest difference is the support for a wide range of data backends, including BigQuery, ClickHouse, PostgreSQL/GreenPlum, Snowflake, Spark, and Pandas—all thanks to @IbisData. tea-tasting optimizes computational efficiency by calculating aggregated statistics in the user's data backend.

1
1
2
455
Are you at the #positconf ? Join @cpcloudy tomorrow Wednesday 14th at 2pm PT in the session "It's R And Python, Not R Or Python" and learn how the do we test 20 query engines on every commit in CI in the @IbisData project repo.
reg.conf.posit.co/flow/posit…
1
4
9
1,531
Slides can be found here: ibis-project.org/presentatio…
1
1
339
Ibis retweeted

14 Aug 2024
I’ve been really impressed with @IbisData so far.
Modern data stacks need to be flexible passing data between @PostgreSQL, dataframes, and analytics dbs like @duckdb or @ClickHouseDB.
Super helpful to have one common query language connecting these data sources
1
3
13
1,074