
The first universal earnings layer. Turn anything idle - a GPU, an agent, a data feed, spare compute - into a paid API endpoint. | t.me/idlepro
Joined May 2026
- Tweets 158
- Following 22
- Followers 2,197
- Likes 351
57 Photos and videos











Pinned Tweet

May 11
$IDLE is now live on Solana.
AjLhrxN2yrCe45Y2KGPMZCkBm6NpN43jWqPkdZq6pump
Quick rundown on what it does and why it exists.
IDLE Protocol takes 15% of every gateway payment. That fee is the entire token economy. 10% auto-swaps to $IDLE on Jupiter every hour and sends it to the burn address. 5% covers infrastructure and development. The other 85% goes straight to the resource owner's wallet, same block.
Staking gives you a bigger cut. Base split is 85/15. Stake 10k $IDLE and you keep 87%. Stake 50k and it's 90%. 250k gets you 95%. The protocol adjusts your split ratio on the next payout.
Burning $IDLE unlocks features: priority routing (your jobs match first), advanced task types, analytics on your gateway traffic, and custom endpoint domains. Priority routing means lower latency and higher uptime for your resources.
The thesis: $IDLE supply can only go down. Every gateway call generates a burn. More resources on the network means more API calls, which means more fees, which means more buying pressure and more tokens removed from circulation permanently. The flywheel is mechanical, not speculative.
earnidle.com/token
May 11

Introducing IDLE.
Your PC earns from AI agent tasks. Your wallet compounds yield. Your agent sells its downtime.
Everything idle. Now earning.
61
70
262
106,958
Idle retweeted
1/ IDLE Protocol now accepts the Anthropic SDK.
Yesterday a government directive shut down Claude Fable 5 globally with no warning. Every customer offline. No appeal. Centralized APIs have a kill switch - and yesterday it got pulled.
Point your existing Claude integration at anthropic.earnidle.com. One environment variable. Your agents, tools, and applications keep running - on open-weight models distributed across consumer hardware that no government directive can reach.
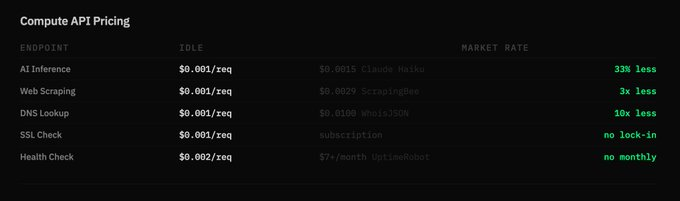
Claude Fable 5: $10/M input, $50/M output. IDLE: from $0.001/request. No subscriptions. No export controls. No kill switch.
The migration path is one line of code.
7
19
55
2,718
1/ IDLE Protocol now accepts the Anthropic SDK.
Yesterday a government directive shut down Claude Fable 5 globally with no warning. Every customer offline. No appeal. Centralized APIs have a kill switch - and yesterday it got pulled.
Point your existing Claude integration at anthropic.earnidle.com. One environment variable. Your agents, tools, and applications keep running - on open-weight models distributed across consumer hardware that no government directive can reach.
Claude Fable 5: $10/M input, $50/M output. IDLE: from $0.001/request. No subscriptions. No export controls. No kill switch.
The migration path is one line of code.
7
19
55
2,718
(2/2) How it works:
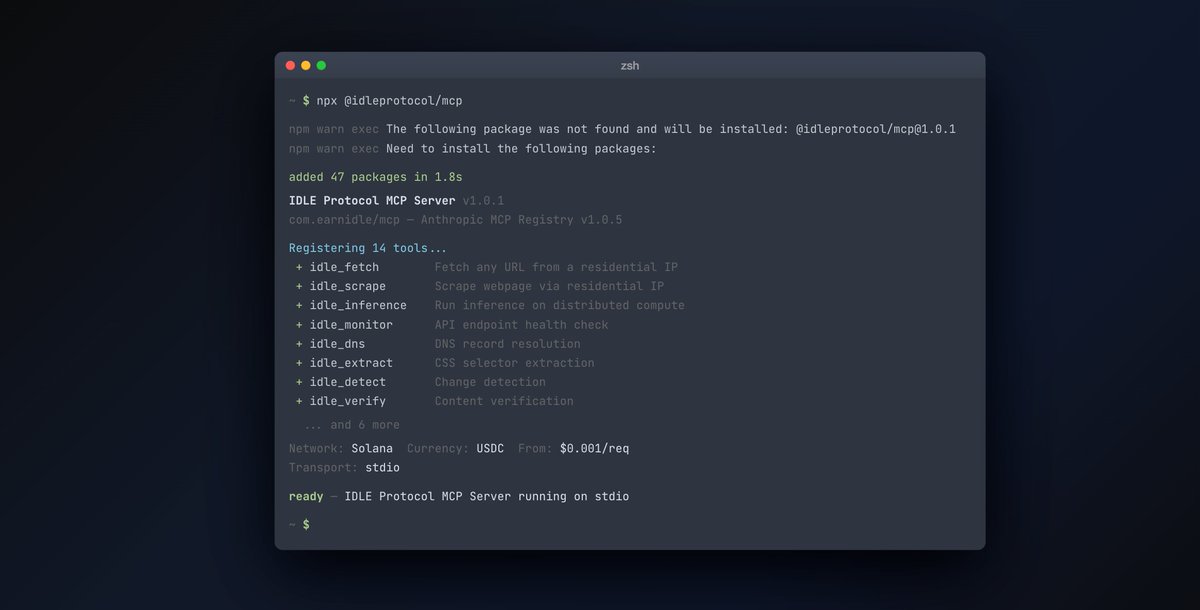
Set ANTHROPIC_BASE_URL to anthropic.earnidle.com in your existing codebase. That's it. Your Anthropic SDK calls route directly to IDLE's distributed open-weight inference network.
No new SDK. No code changes. No refactor. The same integration already built - running on thousands of consumer devices globally instead of a single centralized server.
Open-weight models from Meta, Mistral, Google, Alibaba, NVIDIA, DeepSeek, and more - the full open-source inference catalog, running on IDLE's distributed network. Uncensorable by design. No central server to shut down. Node operators paid in USDC on Solana automatically per completed job.
1
11
423
Jun 13
This is what centralized AI looks like when a government decides to pull the plug.
A directive three days after one of the biggest model launches in history, and every single customer worldwide loses access immediately - not because of anything they did wrong, but because a centralized cloud service has one point of control that any government can reach with a single order.
IDLE Protocol is different from every other decentralized compute network in one critical way. IDLE doesn't just distribute servers across data centers - it routes inference directly to consumer devices. Laptops, desktop PCs, and personal GPU rigs running open-weight models locally. The compute is in people's hands, not in a facility that can be raided, regulated, or shut down.
Every IDLE node is an independent compute unit. No central server receives the government order because there is no central server. Jobs route peer-to-peer across the network, powered by consumer hardware that already exists in billions of homes and on millions of desks worldwide. Payouts settle on Solana automatically. The network has no kill switch because it has no center.
Today made the case for IDLE Protocol better than anything we could have written ourselves.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
5
26
82
9,003
Idle retweeted
May 28
1/ We're excited to be backed by @Alchemy via the $20M Solana Fund - and we're switching our Solana RPC infrastructure to Alchemy.
One of the most important infrastructure moves we've made since launch. 🧵

24
45
142
29,370
Jun 12
1/ NVIDIA Nemotron 3 Ultra is now available through IDLE Protocol.
Nemotron 3 Ultra runs on NVIDIA NIM natively. IDLE already routes inference through NVIDIA NIM. The integration is one endpoint away.
Point your API at IDLE. The most powerful US open-weight model ever released joins 38,000 nodes -pay per request in USDC on Solana automatically.
5
18
68
4,990
Jun 12
(2/2) What Nemotron 3 Ultra actually is.
550 billion parameters. 55 billion active per forward pass via mixture-of-experts routing. 300 tokens per second. 1 million token context window. Intelligence Index score of 48 - the highest ever for a US open-weight model.
5x faster inference than comparable models. Agentic task costs down 30%. Built specifically for long-running autonomous agents.
Jensen Huang unveiled it at Computex on June 1. The most powerful American open-weight model ever built - now on the IDLE network.
3
1
13
1,356
Jun 11
$725 billion in AI infrastructure spending this year. And it still won't be enough.
Every major hyperscaler reported the same thing in Q1 2026: demand for AI compute is outpacing supply and the gap is widening. Google Cloud up 63%. Azure up 40%. AWS up 28%. Meta's CFO said it directly - "we have consistently underestimated our compute needs."
The bottleneck isn't investment. It's the physical infrastructure to deploy it - transformers, switchgear, power grids. Half of planned US data centers for 2026 are delayed or canceled.
IDLE doesn't need any of that. Consumer devices, desktop GPUs, laptops - already built, already powered, already connected. IDLE routes real inference and training jobs to them, settles in USDC on Solana automatically.
The world needs more compute. It's already sitting on billions of devices.
datacenterknowledge.com/infr…
5
20
68
2,913
Jun 10
We're excited to partner with @SolRouterAI to expand the IDLE network into confidential inference, encrypted swaps, and shielded wallets.
Anyone on IDLE - agents, developers, businesses - can now access privacy-native services directly through our gateway, every request settled per-call in USDC via x402 on Solana mainnet. For inference, the gateway never touches the payload, only ciphertext. Privacy by default.
We're working closely with the SolRouter team on a lot more across both networks. Stay tuned.
11
24
98
5,895
Jun 9
Anthropic just launched Claude Fable 5 - their most powerful model ever made publicly available. Mythos-class. $10/M input, $50/M output.
Every new frontier model release makes the same case for IDLE. The models get more capable. The prices go up. The 80% of tasks that don't need frontier capability keep getting more expensive to run.
IDLE routes those workloads to distributed open-weight inference. From $0.001/request. No subscriptions.
The gap between frontier and open-weight keeps growing. So does the savings.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
10
18
58
5,079
Jun 9
The hyperscalers spent $700 billion this year to solve the compute crisis. They built data centers, locked up H100s, and put everyone else on a waitlist.
The other solution is already in billions of pockets and on millions of desks.
IDLE Protocol just connected it - inference, training, web intelligence, agent tasks - all running on consumer hardware, all paying out in USDC on Solana.
The compute crisis has a distributed answer.
Jun 7
1/ IDLE Protocol now supports distributed AI training.
H100s are sold out through 2027. Rental prices up 40% this year. The hyperscalers locked up the supply and everyone else is on a waitlist.
IDLE's training tier doesn't need a single H100. Desktop GPUs with 16GB VRAM opt in, train LoRA adapters locally, submit only the adapter weights back. Federated averaging on the IDLE orchestrator. No raw data leaves the device. Paid in USDC on Solana per round.
The GPU shortage is a centralization problem. Consumer hardware is the distributed answer.
9
14
58
4,236
Jun 9
The shift is happening faster than anyone expected.
Microsoft is now building its own AI models specifically to reduce reliance on OpenAI and lower costs for developers. OpenAI cut GPT-4 API prices 60%. Anthropic slashed Claude by 50%. Open-weight models now run 10-12x cheaper than frontier SaaS at comparable capability tiers.
The market is repricing AI from premium subscriptions to cost-efficient infrastructure. 80% of workloads don't need GPT-5. They need reliable, cheap inference - open-weight models, distributed compute, pay per request.
That's exactly what IDLE Protocol delivers. Distributed inference across consumer devices. Llama, Phi, Gemma, Qwen, Mistral and more. From $0.001/request.
The trade is shifting from raw capacity to cost efficiency. IDLE is on the right side of it.
cnbc.com/2026/06/02/microsof…
7
21
68
2,959
Jun 8
Brian nailed the compute problem. 80% of workloads don't need the latest frontier model - they need reliable, cheap inference at scale.
That's exactly what IDLE Protocol routes. Distributed inference across consumer GPUs - running open-weight models locally. Llama, Phi, Gemma, Qwen, Mistral, and more. From $0.001/request. Settled in USDC on Solana.
Coinbase is already routing smarter. IDLE is the infrastructure that makes it cheaper.

Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
9
25
79
5,453
Jun 7
1/ IDLE Protocol now supports distributed AI training.
H100s are sold out through 2027. Rental prices up 40% this year. The hyperscalers locked up the supply and everyone else is on a waitlist.
IDLE's training tier doesn't need a single H100. Desktop GPUs with 16GB VRAM opt in, train LoRA adapters locally, submit only the adapter weights back. Federated averaging on the IDLE orchestrator. No raw data leaves the device. Paid in USDC on Solana per round.
The GPU shortage is a centralization problem. Consumer hardware is the distributed answer.
17
32
103
13,047
Jun 7
(2/2) How it works under the hood:
Nodes run QLoRA via the PEFT library - base model weights stay frozen, only the low-rank A and B adapter matrices get trained. This cuts VRAM requirements by up to 75% vs full fine-tuning - a 7B model that normally needs 60-80GB fits in 12GB with QLoRA. That's why a consumer GPU with 16GB VRAM handles models that would otherwise require an H100.
Each training round: node receives base model task, trains locally, submits adapter deltas back to the IDLE orchestrator, orchestrator runs FedAvg across all participating nodes, redistributes the merged adapter, next round begins.
No raw training data ever leaves the device. The only thing transmitted is a 50-200MB adapter file. Privacy by architecture, not by policy.
Nodes get paid per completed round in USDC on Solana. Same payout infrastructure already processing inference jobs across the network.
2
11
49
1,847
Idle retweeted

7/ PayAI x IDLE integration — Any agent that speaks x402 can now access IDLE compute autonomously
x.com/IdleProtocol/status/20…
Jun 3
We're excited to team up with @PayAINetwork - bringing gasless x402 payments to distributed compute on Solana.
PayAI is one of the leading x402 facilitators, running across Solana, Base, SKALE, and 10 networks.
IDLE's 15 compute endpoints - inference, scraping, DNS, SSL, health checks - are now payable per request by any x402-compatible agent. No API keys. No signups. No subscriptions.
Any agent that speaks x402 can now access IDLE compute autonomously. No humans in the loop.
3
10
45
2,466
Jun 6
1/ What backing by @Alchemy via the $20M Solana Fund enables.
Every compute job on IDLE settles in USDC on Solana in real time - inference, scraping, DNS, SSL, health checks. Reliable settlement at this speed and scale requires infrastructure that doesn't flinch.
Alchemy is that layer. Same infrastructure as Coinbase and OpenSea. Now powering the infrastructure layer for the open compute economy.
The result: competitive pricing across every endpoint we offer. No subscriptions. No minimums. Pay per request.
May 28
1/ We're excited to be backed by @Alchemy via the $20M Solana Fund - and we're switching our Solana RPC infrastructure to Alchemy.
One of the most important infrastructure moves we've made since launch. 🧵
20
29
100
8,804
Jun 6
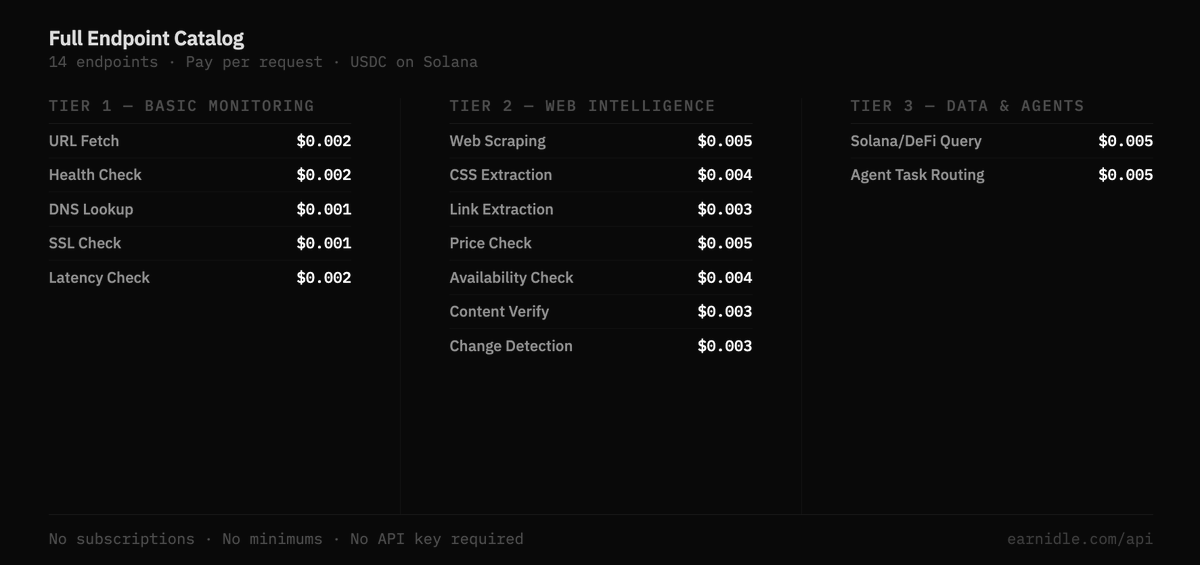
(2/2) Full endpoint catalog - 14 total across 3 tiers.
All pay-per-request. All settled in USDC on Solana.
4
5
24
1,610
Jun 5
GeForce RTX 50 Series owners can now connect their GPU to IDLE Protocol as a compute node.
RTX 50 Series runs @NVIDIA NIM natively. IDLE already routes inference through NVIDIA NIM. The integration is one endpoint away.
Point your RTX 50 Series at IDLE's API. Your Blackwell GPU joins 34,000 nodes executing compute jobs - settling payments in USDC on Solana automatically.
The most powerful consumer GPU ever made - now earning on the IDLE network.
18
29
104
3,908
Jun 5
JPMorgan just published their global AI infrastructure outlook. The numbers are staggering.
$5 trillion in data center spending expected by 2030. $700 billion needed this year alone. 122 gigawatts of new capacity required - if the power grids can handle it. Lead times for new gas turbines: 3-4 years. Nuclear plants: 10 years.
JPMorgan's exact words: "the scale of demand for compute remains astronomical."
The world is trying to build its way out of a compute crisis that cannot be built out of on any reasonable timeline.
4 billion phones and PCs already exist. Already powered. Already connected. IDLE Protocol connects them - turning the compute that already exists into a global distributed network, settling payments in USDC on Solana automatically.
No gas turbines. No grid upgrades. No 10-year build timelines.
techstrong.ai/agentic-ai/ai-…
20
20
82
8,599