
Scool is a #MachineLearning research team in @Inria & CRIStAL interested in designing algorithms that learn & adapt on-the-go. It is the new avatar of "SequeL".
Joined November 2020
- Tweets 95
- Following 104
- Followers 344
- Likes 175
55 Photos and videos








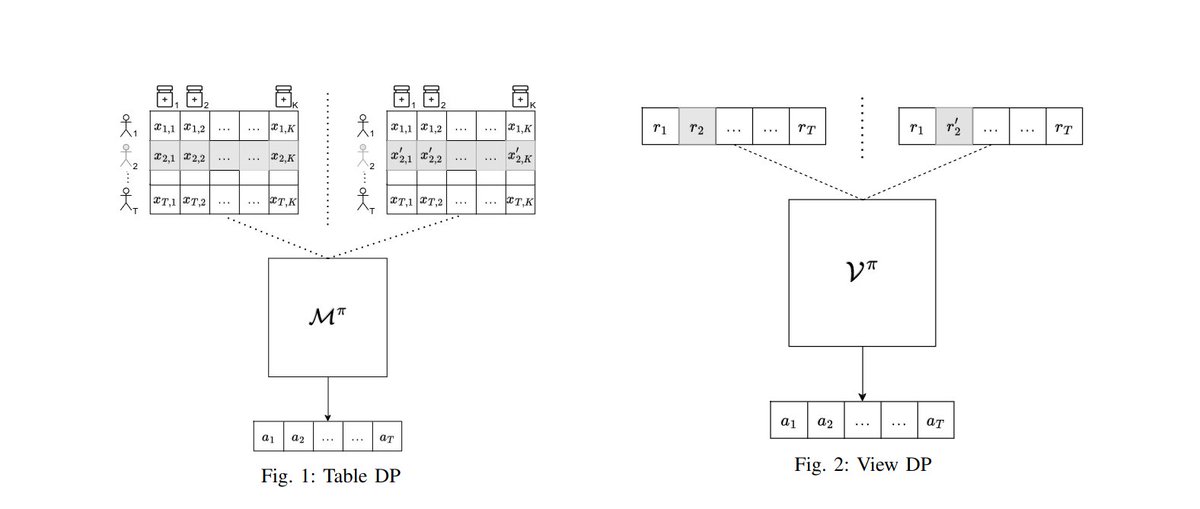






27 Jul 2024
1/n Today, we concluded @icmlconf with 4 presentations at the #FORLAC workshop conjoining RL theory and Control. Following their UAI work, @tuanquangdam, Odalric & Emilie on their work to address biased value function estimation in #MCTS using power means. #ICML2024 @Inria_Lille
1
3
372
27 Jul 2024
3/n MCTS with deep NN shows promising performance in deterministic envs, but fails in stochastic envs. @tuanquangdam, Odarlic & Brahim propose CATS & PATS, leveraging TS to handle selection randomness. They achieve regret guarantees as well as good performance in stochastic envs.
1
2
213
27 Jul 2024
4/n Alena, Thomas, Phillipe & Bruno motivated by uniqueness ambiguity of value func as a solution to HJB eqn in CTRL, propose to approximate the value func by training a PINN through a specific scheduling iterative process that constraints it to converge to the viscosity solution
2
140
17 Jul 2024
Congratulations to @tuanquangdam, Odalric, and Emilie on their work to address biased value function estimation in #MCTS using power means. 🥳 #UAI2024 @Inria_Lille @RechercheUlille
17 Jul 2024

#UAI2024 Interested in how power mean can enhance value function estimation in tree search methods? Learn about our approach to solving biases in MCTS for stochastic settings. Join us tomorrow at 4:30 PM in the Exhibition room, building 20.
Paper: arxiv.org/pdf/2406.02235
3
253
3 Jul 2024
We've derived tight lower and upper bounds for differentially private finite-armed & linear bandits, while we lack the same for contextual bandits. At #COLT2024, @achraf_azize presents open problems in contextual bandits with privacy. @BasuDebabrota @Inria_Lille @RechercheUlille
ALT https://hal.science/hal-04621903v1
1
8
896
Scool retweeted

29 May 2024
It's fun to revisit the sanctum sanctorum: how does a brain learn? Today at Convention on Mathematics of #Neuroscience & #AI, @GuillaumeAP presents our work with @AdityaGilra on how to design a bio-plausible learning rule rather than backprop type methods to learn a time series.

2
6
365
17 May 2024
We are glad to announce the 1st edition of Workshop on Interpretable Policies in Reinforcement Learning (InterpPol) @RL_Conference. Plz submit your original/published papers on Interpretable/Explainable RL, Policy Distillation, Formal Verification & RL.
👉shorturl.at/ebTkX
1
1
1
193
17 May 2024
The submission link is openreview.net/group?id=rl-c….
Contact @kohler_hector and the organisers if you have any query.
1
150
3 May 2024
1/2 Is exploration harder if we've constraints on policies? No, depends on how constraints change the geometry of alternating set. Today @aistats_conf, @BasuDebabrota & collaborators present insights & algorithms for pure exploration with constraints. #AISTATS2024 @chalmersuniv
1
7
182
3 May 2024
2/2 If each arm has multiple objectives, how to identify an arm whose mean vector is not worse than any of the others. Tomorrow @aistats_conf, Emilie & Cyrille will present "first" algo to detect such pareto sets with finite budget & bandit feedback. @RechercheUlille @Inria_Lille
3
72
9 Apr 2024
1/2 To define privacy in bandits, we have to ask what are the input and output of a bandit algorithm? What differs if the adversary is interactive or passive? @achraf_azize & @BasuDebabrota address these in their work openreview.net/forum?id=2366….
1
1
4
456
9 Apr 2024
2/2 Today @satml_conf, @achraf_azize is presenting these nuances of "Concentrated DP for Bandits" along with information-theoretic lower bounds and near-optimal algorithms for linear, contextual, and multi-armed bandits. #privacy #bandits @Inria_Lille @RechercheUlille #SaTML24
1
3
161
26 Feb 2024
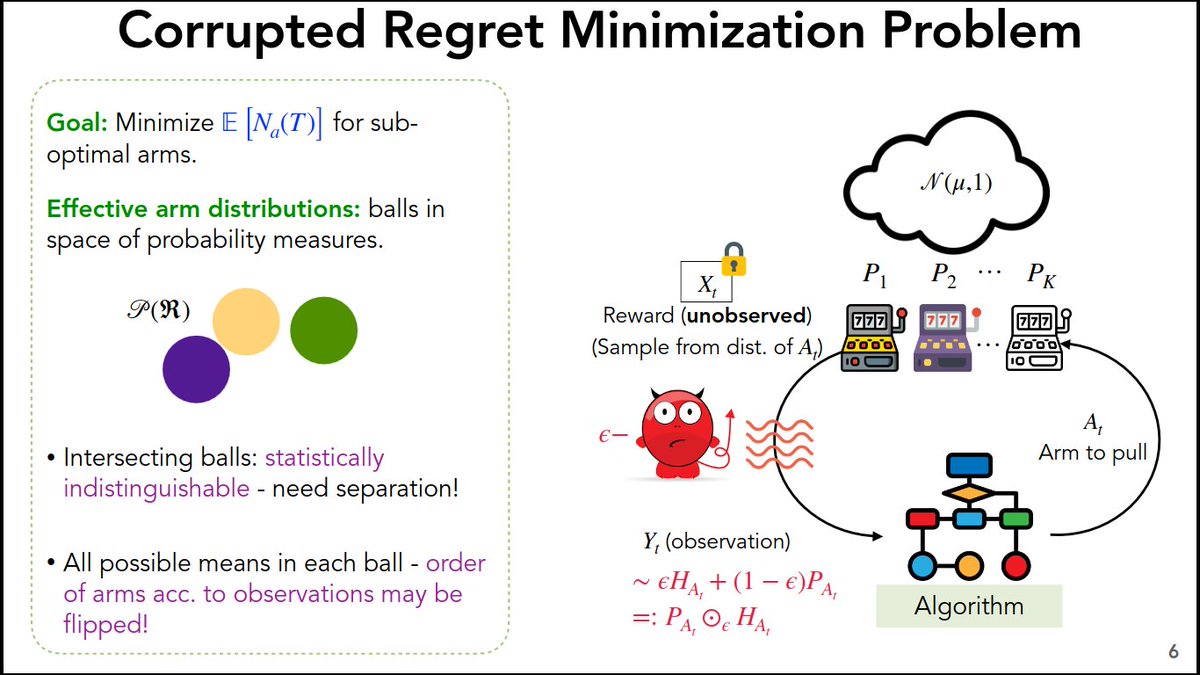
What happens in a bandit problem if epsilon fraction of feedback are arbitrarily corrupt? What are the new lower bounds on the regret? Can we design an optimal algorithm for #Bandits_corrupted_by_nature? We address this question in two parts.
1
4
428
26 Feb 2024
Today at #ALT2024, @ShubhadaAgrawal presents CRIMED: a joint work with Timothée, @BasuDebabrota & Odalric. CRIMED achieves matching regret upper bound for symmetric distributions and unbounded corruption. #bandits #corrupted_observations @univ_lille @Inria_Lille
1
4
102
26 Feb 2024
@TmlrOrg we address the corrupted bandit problem, i.e. a stochastic multi-armed bandit problem with unknown reward distributions, which are heavy-tailed and corrupted by a history-independent adversary or Nature. We provide another set of lower bounds and algorithm. #robustness
3
75
26 Feb 2024
Congratulations to Émilie for the well-deserved achievement! 😊🥳

Toutes nos félicitations 👏 à notre collègue Émilie Kaufmann, membre de l'équipe @InriaScool. Une médaille de bronze bien méritée 🙂
#MachineLearning
7
184
16 Dec 2023
Today @NeurIPSConf, visit the #WANT workshop to know mode about tools and algorithms to make deep network training computationally friendly and resource efficient. #NeurIPS2023
30 Aug 2023

@InriaScool's Alena Shilova with a team from @nvidia @Inria & @ufrj is organising #WANT workshop @NeurIPSConf. If interested in tools & algorithms to make training computationally efficient & scalable with optimal resource utilisation,visit want-ai-hpc.github.io/ #HPC #NeurIPS23
1
3
335
14 Dec 2023
What happens if you've multiple objectives/rewards for each arm? How can you find pareto set with bandits? At 5PM @NeurIPSConf, Cyrille'll present an adaptive & sequential sampling to identify Pareto set (or a relaxed Pareto set) of multivariate distributions #NeurIPS23 #Bandit
3
133
14 Dec 2023
What happens if you've multiple objectives/rewards for each arm? How can you find pareto set with bandits? At 5PM @NeurIPSConf, Cyrille'll present an adaptive & sequential sampling to identify Pareto set (or a relaxed Pareto set) of multivariate distributions. #NeurIPS23 #Bandit
2
144