
Chief Digital & Information Officer @MFTnhs | Fellow @BCS | Honorary Chair Informatics, Imaging and Data Science @OfficialUoM | #datasaveslives |
Joined January 2013
- Tweets 2,881
- Following 394
- Followers 3,050
- Likes 3,031
325 Photos and videos













David Walliker retweeted

27 Dec 2024
Let’s Talk Data 🗣️ Help shape how health data transforms care by becoming a patient public voice partner! 💼 Share diverse views & keep conversations patient-centric.
Paid opportunities available:🔗 england.nhs.uk/get-involved/…

ALT Three young people gathered around a laptop all looking and discussing. Wording on image states: "Lets talk data: your voice matters. Become a patient public voice partner!"
3
4
4
1,499

Our Group Chief Executive, @MCubbonNHS recently spoke to @health1tech about the vital role digital has to play in our new five year strategy
He also spoke about how Hive, our EPR system, is delivering value for our patients
Read more: htn.co.uk/2024/08/06/blog-un…
1
12
21
3,961
David Walliker retweeted

What a week! Anyone else possibly discover signs of microbial life from billions of years ago on a planet 140 million miles from Earth?
No? Just me?
153
881
5,712
698,451

In response to today’s IT outage which has caused significant global disruption, we have published this statement, including advice on how to defend against phishing attempts 👇
ncsc.gov.uk/news/major-it-ou…
10
66
63
35,511
David Walliker retweeted

19 Jul 2024
A study with @OUHospitals has found that an automated AI voice system enhances patient care after cataract surgery ➡️ imperial.nhs.uk/about-us/new…
The AI-powered system calls patients to ask questions, understands their answers and identifies patients who may need review by doctors.

ALT Close up photo of a woman on her phone.
2
2
855
David Walliker retweeted

18 Jul 2024
MyMFT is our patient healthcare app. 📱 💙💻
It connects you to your medical information at Manchester University NHS Foundation Trust hospitals.
Learn more, and sign up today, at: mft.nhs.uk/the-trust/mymft
#HealthcareinYourHands
5
3
8
4,139
David Walliker retweeted

2 Jul 2024

1
1
14
1,386
David Walliker retweeted

28 Jun 2024
New AI Snake Oil essay: AI scaling myths
Scaling will run out. The question is when.
Full essay: aisnakeoil.com/p/ai-scaling-…
Summary:
Scaling laws only quantify improvements in next-word prediction, not emergent abilities. What matters is emergence, and it is not governed by any law-like behavior.
There's a reasonable view that LLMs can't extrapolate too far beyond their training data. If so, at some point, having more data no longer helps because all the tasks that are ever going to be represented in it are already represented.
Besides, there are limits to how much data companies can get. It's not that they'll "run out" of training data — there’s always more data, but it will cost more and more.
Seemingly exponential tech trends have a tendency to suddenly flatline. Scaling is ultimately a business decision and fundamentally hard to predict in advance.
Synthetic data is not magic. It has many great uses but increasing the volume of training data is not one of them.
Self-play has been spectacularly successful in self-contained environments like Go but won't work everywhere.
Based on current market trends, building bigger models is hard to justify because the barrier to adoption of current models isn't capability, it's cost and other factors.
OpenAI, Anthropic, and Google have all made their frontier models much smaller recently, if we use API pricing as a rough proxy for size.
Unlike dataset size and model size, training compute continues to scale (smaller models require more training to reach the same level of performance). The earlier crop of models were under-trained and the current generation is being trained for dramatically longer, which is better when accounting for inference cost.
In the AGI chapter of the AI Snake Oil book (amazon.com/Snake-Oil-Artific…) we conceptualize the history of AI as a punctuated equilibrium, which we call the ladder of generality. Instruction-tuned LLMs are the latest step; an unknown number of steps lie ahead.
Historically, standing on each step of the ladder, AI researchers been terrible at predicting how far you can go with the current paradigm, what the next one will be, when it will arrive, what new applications it will enable, and what the implications for safety are. That is a trend we think will continue.
With @sayashk.
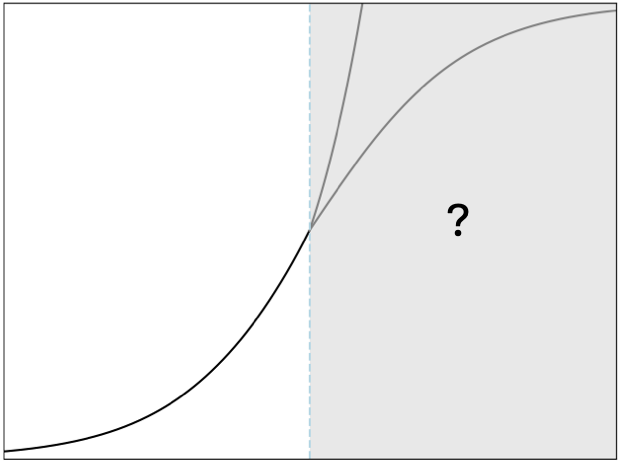
ALT Every exponential is a sigmoid in disguise.
15
75
277
46,749

29 Jun 2024
Finally admitted that age has defeated me and purchased varifocals. I do worry that I will be like the ED-209 from Robocop the first time I attempt stairs though.
3
15
1,163
🏆✨Congratulations to our Hive team!
We're delighted our fantastic @MFT_Hive team have won the HSJ 'Digital Team of the Year' award!
What a fantastic achievement! ✨🥇👏
6 Jun 2024

The final award of the evening! For their transformative project, the Digital Team of the Year is awarded to @mft_hive Amazing work! #HSJDigitalAwards
9
38
6,203
David Walliker retweeted

4 Jun 2024
I'M DOING A TALK TONIGHT
Bad Science, data science, privacy, data infrastructure... and talking with generalists (policymakers and "the public")... about tricky technical issues and unwelcome truths.
TELL YOUR FRIENDS
eventbrite.co.uk/e/from-bad-…
5
9
26
17,209
David Walliker retweeted

2 Jun 2024
We’re deeply saddened to learn of the death of our patron Rob Burrow CBE.
Since his MND diagnosis in 2019, Rob has played a vital role in raising awareness and money to support our work. We will be forever grateful.
Our thoughts are with Rob’s family, friends and fans.
2 Jun 2024

It is with deep sadness that the club can confirm that former player Rob Burrow CBE has passed away, aged 41.
More here therhinos.co.uk/article/2042…

106
468
5,834
392,618
We would like to wish Professor Jane Eddleston, Joint Group Medical Officer, a wonderful retirement after a dedicated career with MFT.
Professor Jane Eddleston was the first female doctor to receive a prestigious national intensive care award.
Happy retirement! 💙 👏




6
12
132
9,117
👑 💜 Royal News!
We're delighted to share that Manchester Royal Infirmary has retained its royal patronage from the Royal Family as part of a celebration marking the anniversary of the Coronation of King Charles III and Queen Camilla.
Read the story ➡️ bit.ly/4bGK2Dd

5
16
113
7,431
David Walliker retweeted

22 May 2024
NEWS: New Maternity Early Warning Score to be implemented across the NHS
@UniofOxford researchers develop a new system to identify signs of deterioration in pregnant women.
medsci.ox.ac.uk/news/new-mat…
4
8
1,236
David Walliker retweeted

20 May 2024
JOB: Director of Research, Institute for Ethics in AI, University of Oxford.
Deadline: June 10th
minervasearch.com/current-op…
29
49
16,014
17 May 2024
My first experience of Epic at their inaugural European Group Meeting in beautiful Bristol, has been a fantastic learning and networking experience for me. So many exciting possibilities, and some brillaint presentations by the @drpetermark @hrmorriss @se01th Vikki and James 👏



2
4
17
1,816
17 May 2024
What a team I’m lucky enough to work with @STF_NHS @Richardthenurse Ellin and Ceyda


2
9
1,120
David Walliker retweeted

14 May 2024
🗞️ Groundbreaking cancer research at @MFTnhs is successfully identifying younger women at increased risk of breast cancer, after one year of opening 👏
The study launched in memory of late Girls Aloud singer, Sarah Harding and is led by @DrSachaHowell 👇
research.cmft.nhs.uk/news-ev…

1
10
25
3,220
10 May 2024
After an amazing first two weeks in Manchester, this weekends plans are sitting outside in sunshine:
while(gardenmusic)
{
wine.drink();
nexttrack.execute();
if(wine == “empty”)
{
if(wineglass == “empty”
wineglass.topup();
wine.refill();
}
}
2
15
1,383