
Tech chaos? Security threats? IntelliData keeps you up, running, and protected. Rock-solid IT, zero downtime, proven results. Call now—before hackers hit.
Joined October 2015
- Tweets 2,949
- Following 182
- Followers 146
- Likes 1
702 Photos and videos
















Pinned Tweet

21 Oct 2025
Stop downtime. Start momentum with IntelliData Solutions — enterprise-grade IT with a human touch.
#IntelliData #ManagedIT #Cybersecurity #PrivateCloud #DisasterRecovery #vCISO
52
Jun 12
1/ If you've never been pen-tested by someone who didn't build your network, you don't have a security posture. You have a hypothesis.
2/ In-house teams test the systems they designed — blind to their own assumptions. An independent third party tests what an attacker actually sees. That gap is the whole point.
3/ Audits get real here too. A SOC 2 Type 2 examination covers controls across a period — not a one-day snapshot or a self-graded checklist. Ours: IntelliData Hosting Platform, Jan 1–Dec 31, 2024, all five Trust Services Categories (Lunar Compliance).
4/ Compliance by Design means controls built in, not bolted on the week before an audit. And when something flags at 2 a.m., a named U.S.-based engineer answers — not a ticket queue.
5/ Not sure where that gap is for your stack? We run a
20-minute infrastructure review — your exposure, in plain English. Link in the reply.
CTA — Soft bridge: "We run a 20-minute infrastructure review. Link in the reply."
#Cybersecurity



21
Jun 10
Your cloud bill isn't "variable," it's unpredictable — not the same word. Variable, you can forecast. A month-end egress charge is a cost you never saw coming.
Flat-fee infrastructure isn't boring; it's a forecast that holds. Repost if a cloud invoice ever blew your forecast.
CTA — Repost trigger: "Repost if a cloud invoice ever blew your forecast."
1/ The "cloud is always up" assumption took three hits in five weeks last fall. The dates, the causes, the blast radius — then one question for your ops team:
2/ Oct 19–20, 2025: AWS US-East-1 goes down. Cause: a DynamoDB DNS race condition. Recovered ~6 p.m. ET Oct 20.
3/ Oct 29, 2025: Azure, 8 hours. Cause: a faulty tenant configuration deployment. Alaska Airlines reported key systems affected.
4/ Nov 18, 2025: Cloudflare. Blast radius: ~40M live sites, 19M in the U.S.
5/ Different providers, different causes, same lesson: one region or one config push can be one point of failure. The question isn't if it recurs — it's what your team does in hour one. What's your plan?
CTA — Reply prompt: "What's your hour-one plan?"



73
May 30
Disaster Recovery Hosting (FDA/regulated)
Quick question for regulated teams: if your primary site went dark right now, how long until you're back — and could you prove it to an auditor?
If you're not sure, that's the problem. For FDA-regulated and compliance-heavy operations, "we'll figure it out" isn't a recovery plan — it's a finding waiting to happen.
This month, IDS is offering a free DR readiness assessment: we map your current RTO/RPO, flag the gaps, and show you where a single failure turns into a multi-day outage.
No obligation. Just clarity.
DM us to book yours.
#DisasterRecovery #FDA #BusinessContinuity #Compliance #DRplan
18
May 29
Cybersecurity & Pen Testing:
Unpopular opinion: a "clean" pen test report can be a red flag.
If a third party probes your environment for a week and finds nothing, one of two things is true — you're genuinely hardened, or they didn't look hard enough.
Cheap "pen tests" that just run an automated vulnerability scanner produce tidy reports and false confidence. Real testing is manual, adversarial, and a little uncomfortable to read.
Before you hire a tester, ask what they'll try that a scanner can't. The findings should teach you something you didn't already know.
#PenTesting #CyberSecurity #InfoSec #ThirdPartyRisk
13
May 28
Cloud Hosting (infrastructure modernization)
A growing firm we spoke with was paying for a server room they'd outgrown — and a part-time IT person whose main job was rebooting it.
Every storm season, they held their breath. One bad outage meant days of lost work.
They didn't need a bigger server room. They needed to stop running one.
We moved them to managed cloud hosting: no hardware to babysit, predictable monthly cost, and uptime that doesn't hinge on the weather.
Modernizing isn't about chasing trends. It's about not being one power flicker away from a bad week.
#CloudHosting #ITModernization #ManagedCloud #SMB
15
May 27
Compliance & Audit-Readiness — 3 signs your next SOC 2 audit is going to hurt:
1. Your evidence lives in screenshots and a shared drive nobody's touched since the last audit.
2. "Who has access to that system?" takes more than a day to answer.
3. You find out a control failed during the audit — not before.
Audit-readiness isn't a once-a-year fire drill. It's continuous. IDS bakes compliance into the hosting layer: access logs, change tracking, and documented controls that are ready the moment an auditor asks.
Stop dreading the questionnaire.
#SOC2 #Compliance #HIPAA #AuditReady #CloudSecurity
16
May 26
GPU Hosting (AEC/AI):
Your workstation fans shouldn't sound like a jet engine every time you hit "render."
When one Revit model or a CFD simulation pins a local GPU for hours, your engineers aren't designing — they're waiting. That's billable time quietly evaporating.
IDS GPU hosting gives architecture and engineering teams cloud GPU power that scales to the job: spin it up for the heavy simulation, spin it down when it's done.
No $12K workstation refresh cycle to justify.
Faster iterations, same desk.
Want to see what your render times could look like? Let's talk.
#GPUCloud #AEC #Revit #AutoCAD #CloudComputing
18
May 22
Through June 30: free 60-minute infrastructure review for any team running mixed on-prem cloud.
What you get, no commitment:
→ A right-sizing pass on your current cloud spend (most teams find 15-25% they're paying for and not using).
→ A latency map of your workloads — where the round-trips are actually happening, not where you assumed.
→ A short written summary you can take to your CFO, whether or not you ever work with us.
We do this because every modernization project we've ever won started with someone seeing their own infrastructure clearly for the first time.
Reply or DM to grab a slot. Six left this month.
#CloudHosting #InfrastructureModernization #CloudCost #FinOps #ITLeadership
11
May 21
Unpopular take: your SOC 2 report isn't the goal. It's the receipt.
Too many teams treat the audit as the finish line — sprint to controls, pass the test, file the report, exhale. Then nine months later the renewal lands and everyone scrambles again.
Audit-readiness isn't a season. It's an operating model. The orgs that handle SOC 2, HIPAA, and FDA inspections without a fire drill share one trait: their evidence collection runs continuously, not annually.
If your compliance posture only looks good in the two weeks before an auditor arrives, you don't have compliance. You have theater.
Build infrastructure where the audit evidence is a byproduct, not a project.
#SOC2 #HIPAA #Compliance #AuditReadiness #GRC
8
May 20
A 40-person architecture firm came to us last quarter. Their issue:
Revit was crashing on large federated models. AutoCAD sessions stalled during point-cloud imports. Their newest hire — a designer they'd recruited from a top firm — was watching progress bars instead of designing.
Their IT lead thought they needed new workstations. They didn't.
They needed GPU compute that scales when the model gets heavy, and steps down when it doesn't. We moved their rendering and simulation workloads to dedicated GPU hosting. Same laptops. Different ceiling.
Two weeks later their project lead asked us to "do whatever you did" for the structural team.
If your engineers are billing client hours to staring at a loading screen, the bottleneck isn't talent.
#GPUHosting #AEC #Revit #AutoCAD #ArchitectureFirms
22
May 19
3 signs your DR plan won't survive an FDA inspection:
1️⃣ Your last full failover test was "last year sometime." Auditors want dates, durations, and named participants — not vibes.
2️⃣ Your RTO is documented as "as quickly as possible." That's not a recovery objective. That's a wish.
3️⃣ Your DR site shares a power grid, ISP, or weather system with your primary. Geographic diversity is a control, not a preference.
FDA-regulated environments don't grade on effort. They grade on evidence.
IDS runs DR hosting built for 21 CFR Part 11, with documented test cadences, separated regions, and audit trails your QA team can actually hand over.
#DisasterRecovery #FDACompliance #LifeSciences #21CFRPart11 #BusinessContinuity
7
May 18
When was the last time someone actually read your firewall logs?
Not "we have a SIEM." Not "it's in the dashboard." When did a human last look at what's getting in, what's getting blocked, and what's quietly being ignored?
Most breaches we investigate didn't bypass the controls. They walked through a misconfigured rule that nobody had reviewed in 18 months.
A third-party pen test catches what your internal team has stopped seeing. Different eyes, different toolset, different incentive structure.
If your last external test was more than a year ago, you're not measuring your security — you're hoping.
#Cybersecurity #PenTesting #InfoSec #CISO #RiskManagement
11
May 15
Compliance operational burden: If compliance preparation creates chaos every quarter, the issue is probably architectural—not procedural.
Businesses often treat compliance as a recurring scramble instead of an operational standard.
IntelliData’s compliance-minded infrastructure approach helps reduce audit friction through consistency, documentation discipline, and infrastructure alignment.
#ComplianceReady #ComplianceBurden #AuditReadiness #ComplianceOperations #ITCompliance #InfrastructureCompliance #CloudInfrastructure #PrivateCloud
7
May 14
Infrastructure scalability operational readiness: Many businesses discover infrastructure limitations during growth—not during failure.
Scaling teams, larger datasets, more remote users, and compliance demands expose weak infrastructure design long before a major outage occurs.
IntelliData helps organizations scale intentionally with performance-focused, compliance-aware infrastructure.
#InfrastructureScalability #OperationalReadiness #CloudInfrastructure #PrivateCloud #ScalableInfrastructure #ITInfrastructure #InfrastructureDesign
3
May 13
Proactive partnership vs reactive support: The difference between a vendor and a partner shows up in what happens before something breaks.
Highlight proactive monitoring, ongoing optimization, human communication, and strategic guidance as everyday benefits—not just during incidents.
#ProactiveIT #TechnologyPartner #ManagedIT #MSP #ITSupport #CloudInfrastructure #PrivateCloud #InfrastructureManagement #ProactiveMonitoring
6
May 12
Complexity cost beyond pricing: Hidden cloud costs aren’t just financial—they’re operational.
Managing fragmented cloud environments consumes internal resources and slows execution.
IntelliData simplifies infrastructure so teams spend less time managing and more time moving forward.
#CloudCosts #HiddenITCosts #OperationalEfficiency #CloudInfrastructure #PrivateCloud #InfrastructureManagement #ITComplexity #CloudComplexity

2
May 11
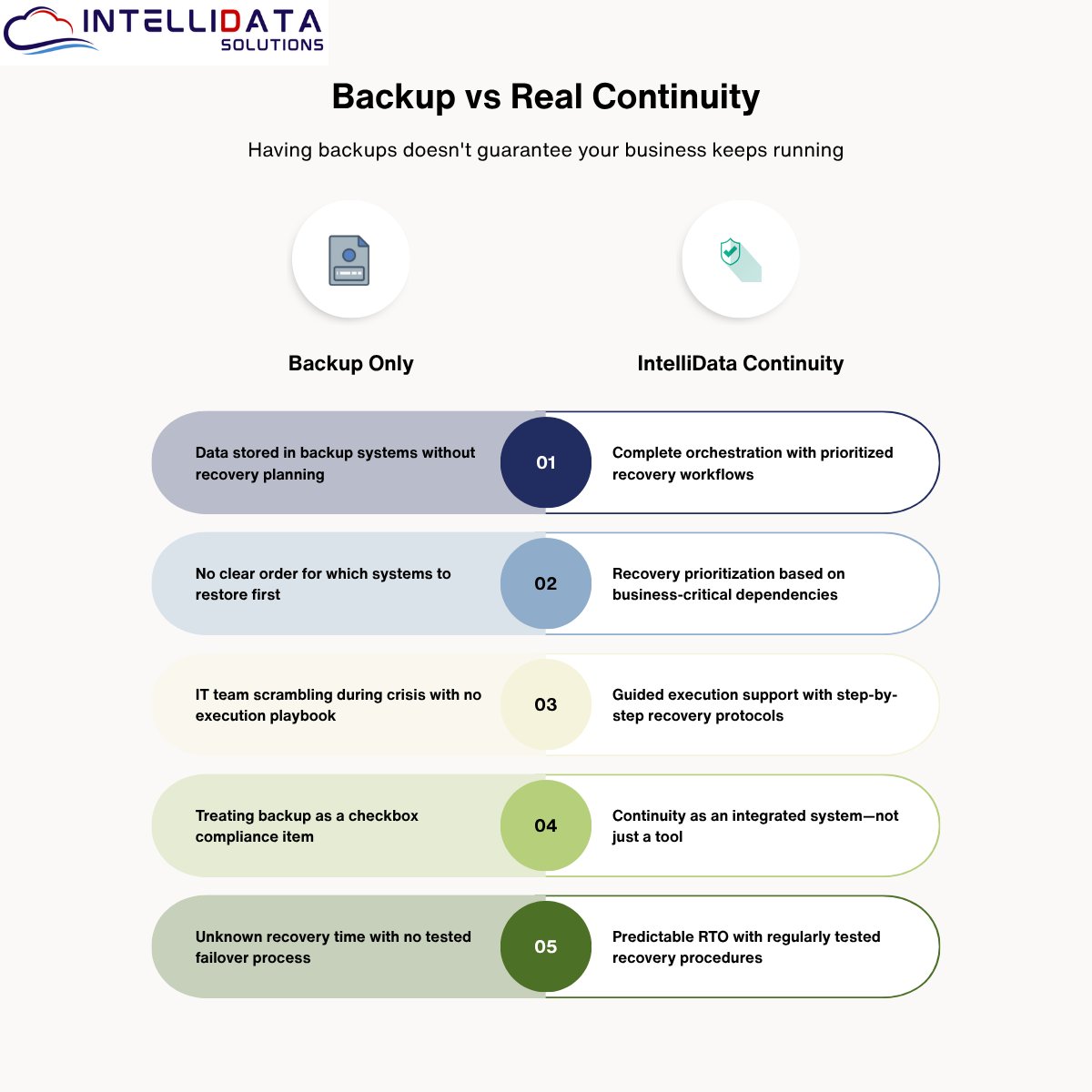
Backup vs real continuity: Having backups doesn’t guarantee your business keeps running.
Many companies invest in backup storage but lack orchestration, recovery prioritization, and execution support.
IntelliData positions continuity as a system—not a tool.
#BackupStrategy #BusinessContinuity #DisasterRecovery #ContinuityPlanning #RecoveryReadiness #RansomwareRecovery
5
Visibility infrastructure control: If you can’t clearly explain your infrastructure, you don’t fully control it.
Many organizations rely on abstracted cloud environments where visibility is limited and understanding is outsourced.
IntelliData restores clarity and control through transparent infrastructure and human support.
#InfrastructureVisibility #InfrastructureControl #ITClarity #CloudInfrastructure #PrivateCloud #TransparentIT #ManagedIT

8
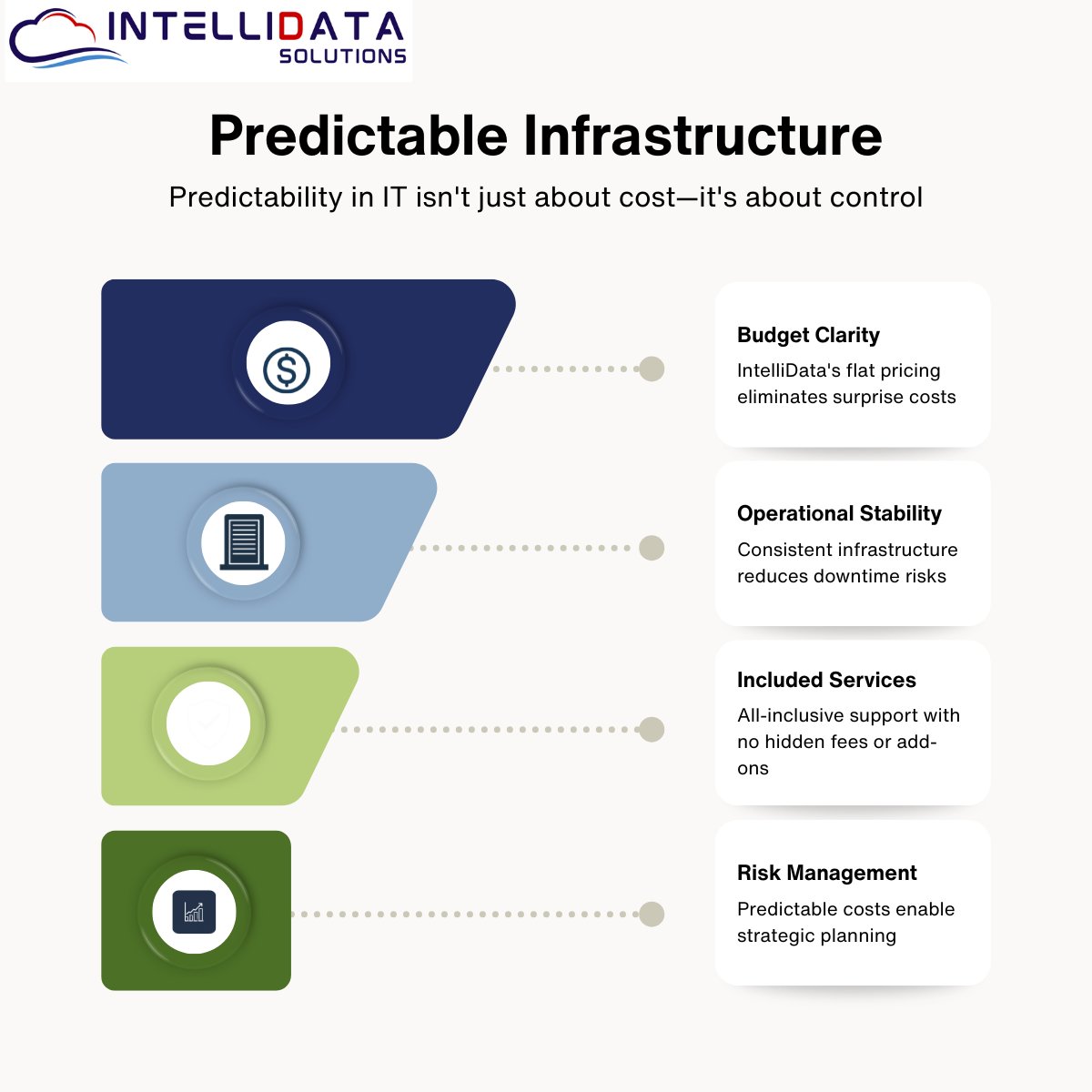
Predictable infrastructure cost clarity: Predictability in IT isn’t just about cost—it’s about control.
Show how predictable infrastructure impacts budgeting, operations, and risk management.
Highlight IntelliData’s flat pricing model and included services as a strategic advantage.
#PredictableIT #CostClarity #ITBudgeting #CloudInfrastructure #PrivateCloud #FlatRateIT #ManagedIT #MSP #InfrastructureManagement
8