
Social Intelligence for AI
Joined November 2025
- Tweets 39
- Following 12
- Followers 161
- Likes 6
18 Photos and videos















May 26
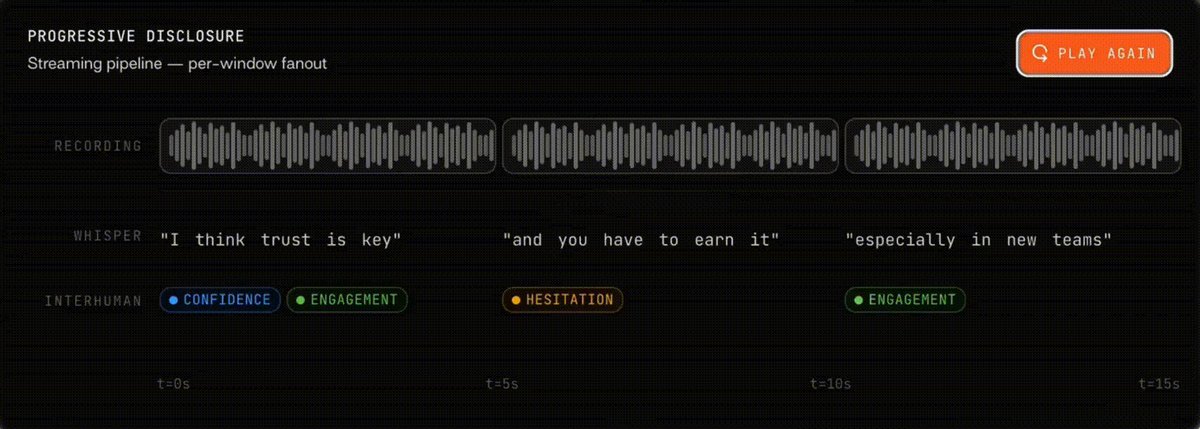
Last week we introduced the Streaming API along with a live demo so you can see it in action.
By popular request, we've now written a blog post explaining how the demo works.
Full blog post: interhuman.ai/blog/stream-de…
Demo: interhuman.ai/stream-demo?ut…
1
1
625
May 21
When we launched Inter-1 a month ago, we said streaming inference was next.
Today it's live!
The Streaming API brings the full set of Inter-1 capabilities to live video, delivering events as the conversation unfolds.
Read the full write up: interhuman.ai/blog/inter-1-s…
2
3
999
Apr 28
We’re excited to see what people build with the Interhuman API.
Mac Mini up for grabs — winner announced June 1.
👉 platform.interhuman.ai
Apr 28

Gave a talk at @clawcon on how we use Noodle (our OpenClaw coworker) at @InterhumanAI
Side quest from the talk: We are giving away a MacMini
Build something with the Interhuman API, post it on X, tag @InterhumanAI.
Winner announced June 1.
👉 platform.interhuman.ai



1
3
495

⇨ @InterhumanAI is a social intelligence API that enables AI products to understand human behavior by analyzing signals like hesitation, engagement, and confusion across voice, facial expressions, body language, and text.
1
3
4
642
Apr 21
“Social signal” and non-verbal social intelligence can be abstract.
Real Talk Studio uses Interhuman AI to evaluate not just what people say, but how they show up empathy, composure, and real engagement under pressure.
In this video, Toby from Real Talk Studio is demoing how non-verbal feedback works in practice.
Try it yourself: realtalkstudio.com/start-pra…
Full case study: interhuman.ai/customer-stori…
2
5
886
Apr 20
Most AI still reduces people to a few “emotions.”
Real interaction is a stream of social signals: hesitation, confusion, engagement, skepticism, stress, expressed through words, voice, and body.
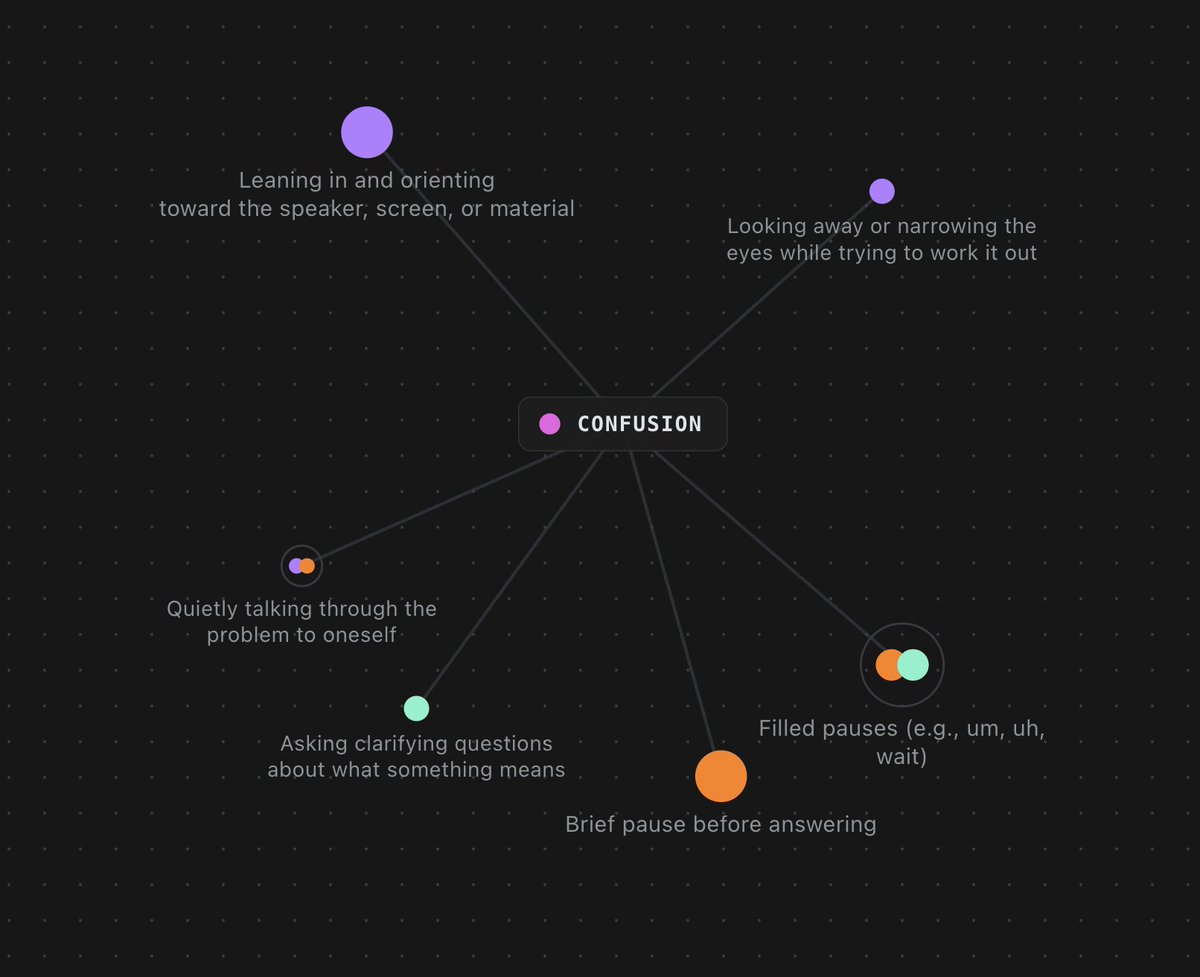
Inter‑1 doesn’t guess a single label. It reads 12 social signals grounded in concrete cues across video, audio & text (gaze shifts, pauses, prosody, wording, posture, etc).
We built a formal ontology of these signals hundreds of cues, and trained Inter‑1 to reason over that structure.
From “emotion detection” to evidence‑grounded social signal understanding.
Full write‑up: interhuman.ai/blog/introduci…
1
479
Apr 16
When you show an AI model a video of someone speaking and ask what's going on, most outputs look like a summary of what was said.
But in many cases, they miss a very important part:
Someone pauses before answering.
Looks away mid-sentence.
Changes tone slightly on a key point.
Those signals shape how the message is received.
They often carry more meaning than the words themselves.
Inter-1 is built to capture that layer.
It processes video, audio, and text together, in temporal alignment, and detects social signals like hesitation, confusion, engagement, and uncertainty.
1
1
2
1,179
Interhuman AI retweeted

Apr 16
Having seen the effort behind this project, huge milestone for @InterhumanAI on their first release 😻
Apr 15
Today at @InterhumanAI we are releasing Inter-1. A multimodal model for understanding how people actually communicate.
1
6
2,186
Apr 15
Inter-1 is live.
An multimodal model built for understanding how people actually communicate.
11
3
12
1,124
Apr 15
Inter-1 was trained on a dataset that combines in-the-wild video with targeted synthetic data to cover a wider range of signals, modalities, and interaction settings.
214
Apr 15
One challenge with this work is data. A lot of datasets in affective computing are organized around basic emotion labels, which wasn’t a good fit for the interaction signals we wanted to model. So we built our own to train inter-1.
208
Apr 15
For each social signal, it also returns a structured rationale showing which cues it used across modalities and how they contributed to the result. So instead of just getting an label, you can see how the model arrived at it.
162
Apr 15
The model is built around observable behavior such as what people say, how they say it, what their body communicates while they say it.
141
Apr 15
Inter-1 is built on a different ontology: 12 social signals, derived from behavioral science research on how humans communicate intent, engagement, affect, and relational dynamics through verbal, paraverbal and nonverbal channels.
143
Apr 15
A lot of current systems work mainly from transcripts. That captures the words, but it misses a lot of the signal: pauses, timing, tone, gaze, posture, and how behavior changes over the course of an interaction.
137
Apr 15
Today, we’re releasing Inter-1.
An multimodal model that processes video, audio, and text together.
132
Apr 9
Most AI describe what was said.
But in many cases, that’s not where the signal is.
4
1
104