
2 Photos and videos



28 Nov 2025
Insert a video into a video with motion and identity awareness. Proud of this work! Split-then-Merge is a cool step forward for video composition. Great teamwork Ozgur!
28 Nov 2025

🎥 Introducing Split-then-Merge: A new video composition framework!
This approach enables the composition of any foreground video with any background video.
Unlike conventional methods that rely on annotated datasets or handcrafted rules, Split-then-Merge (StM) splits a large unlabeled corpus of videos into dynamic foreground and background layers, then merges them to learn how dynamic subjects interact with diverse scenes.
Work done in collaboration with team members at @Google: Du Tran (@dutran) , Yujia Chen (@IssacCyj) , Prof. Ming-Hsuan Yang (@MingHsuanYang), Vincent Chu: and my advisor at UIUC (@siebelschool): Prof. James M. Rehg (@RehgJim).
I will be attending NeurIPS, San Diego and would be happy to chat more!
🔗Project Webpage: split-then-merge.github.io/
📄Paper: arxiv.org/abs/2511.20809
4
451
Yujia Chen retweeted

26 Nov 2025
today we are releasing new research at Google. we tackle the previously unsolved task of editing motion in an existing video. it's called MotionV2V. with it you can move objects in videos, move the camera, and other unprecedented edits in user-provided video
11
43
179
17,984
7 Oct 2025
Great work!
6 Oct 2025

Continuous diffusion had a good run—now it’s time for Discrete diffusion!
Introducing Anchored Posterior Sampling (APS)
APS outperforms discrete and continuous baselines in terms of performance & scaling on inverse problems, stylization, and text-guided editing.
1
1
194
26 May 2025
Wow

Veo 3 is pretty wild.
People just dropped some new insane videos
100% AI
1. What if Jurassic Park was real?
95
27 Mar 2025
This is crazy
26 Mar 2025

ChatGPT's new Image Generation dropped less than 24 hours ago
Here are 15 great examples of what you can do now, some limitations—and a hidden trick to get instant access if you're still waiting!
1. Life-like photos:

ALT Prompt: A lifelike gym photo showing Albert Einstein lifting dumbbells, wearing a tank top and gym shorts. Sweat glistens naturally on his forehead. The lighting comes from overhead fluorescents, casting real shadows. The background includes blurred gym equipment. The photo has a raw and authentic vibe, like a candid shot during a real workout session.
1
109
23 Mar 2025
Like the idea
22 Mar 2025

📍 𝗖𝗮𝗻 𝗔𝗜 𝗡𝗮𝘃𝗶𝗴𝗮𝘁𝗲 𝗠𝗮𝗽𝘀 𝗟𝗶𝗸𝗲 𝗛𝘂𝗺𝗮𝗻𝘀 𝗗𝗼? 𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗠𝗮𝗽𝗕𝗲𝗻𝗰𝗵! 🗺️🤖
𝘙𝘦𝘢𝘥𝘪𝘯𝘨 𝘮𝘢𝘱𝘴, like Google Maps and Theme Park Maps, is second nature for humans. It is a highly challenging task that requires visual understanding, spatial reasoning, and long-horizon planning. We're curious - 𝗖𝗮𝗻 𝗟𝗮𝗿𝗴𝗲 𝗩𝗶𝘀𝗶𝗼𝗻-𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗟𝗩𝗟𝗠𝘀) 𝗱𝗼 𝗶𝘁 𝘁𝗼𝗼? 🤔
We’re excited to share 𝗠𝗮𝗽𝗕𝗲𝗻𝗰𝗵, the first-ever dataset and benchmark specifically designed for evaluating how well LVLMs perform on pixel-based map navigation tasks! 🚀
🔑 𝗪𝗵𝘆 𝗠𝗮𝗽𝗕𝗲𝗻𝗰𝗵 𝗶𝘀 𝗮 𝗚𝗮𝗺𝗲-𝗖𝗵𝗮𝗻𝗴𝗲𝗿:
• 📌 1600 Complex Pathfinding Queries from 100 uniquely challenging map scenarios (urban areas, theme parks, universities, malls, and more).
• 📌 Introduces Map Space Scene Graph (MSSG): a novel data structure for mapping visual landmarks and spatial relationships to structured navigation tasks.
• 📌 Evaluates state-of-the-art LVLMs like GPT-4o, Llama-3.2, and Qwen-2-VL under zero-shot and Chain-of-Thought (CoT) reasoning methods, revealing key insights into their spatial reasoning and navigation abilities.
🚩 𝗞𝗲𝘆 𝗜𝗻𝘀𝗶𝗴𝗵𝘁𝘀:
• Despite their impressive capabilities, current LVLMs struggle significantly with spatial reasoning and structured decision-making.
• CoT prompting boosts spatial reasoning performance but sometimes introduces redundant details.
👀 𝗖𝗵𝗲𝗰𝗸 𝗼𝘂𝘁 𝗼𝘂𝗿 𝗳𝗶𝗻𝗱𝗶𝗻𝗴𝘀, 𝗱𝗮𝘁𝗮𝘀𝗲𝘁, 𝗮𝗻𝗱 𝗰𝗼𝗱𝗲 𝗵𝗲𝗿𝗲:
🔗 Arxiv: lnkd.in/gBv-sFJ3
Huge thanks to our incredible collaborators for making this happen, from @TAMU, @UCBerkeley, @mbzuai, @UMich, and @UCRiverside! 🎉
Let’s continue to bridge the gap between human intuition and AI navigation! 🗺️💡

1
113
Yujia Chen retweeted

28 Feb 2025
Some papers rejected due to "incremental novelty" 🫠
We as a community should emphasize less on being novel and more on being simple, interesting, and useful.
9
41
416
32,118
Yujia Chen retweeted

27 Feb 2025
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream.
Most of the image / video generation AI tools actually work this way and use Diffusion, not Autoregression. It's only text (and sometimes audio!) that have resisted. So it's been a bit of a mystery to me and many others why, for some reason, text prefers Autoregression, but images/videos prefer Diffusion. This turns out to be a fairly deep rabbit hole that has to do with the distribution of information and noise and our own perception of them, in these domains. If you look close enough, a lot of interesting connections emerge between the two as well.
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
26 Feb 2025

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.
373
1,508
11,444
943,843
Yujia Chen retweeted

4 Feb 2025
It’s live! After some final tweaks ASCII converter is officially ready. Turn any image into ASCII art instantly
codepen.io/Mikhail-Bespalov/…
195
729
8,036
661,609
Yujia Chen retweeted

31 Jan 2025
o3-mini might be the best LLM for real-world physics.
Prompt: "write a python script of a ball bouncing inside a tesseract"
120
233
2,519
1,222,018
Yujia Chen retweeted

16 Dec 2024
Today, we’re announcing Veo 2: our state-of-the-art video generation model which produces realistic, high-quality clips from text or image prompts. 🎥
We’re also releasing an improved version of our text-to-image model, Imagen 3 - available to use in ImageFX through @LabsDotGoogle. → goo.gle/veo-2-imagen-3

ALT Prompt: An extreme close-up of a craftsperson's hands shaping a glowing piece of pottery on a wheel. Threads of golden, luminous energy connect the potter’s hands to the clay, swirling dynamically with their movements.

ALT Prompt: A portrait of an Asian woman with neon green lights in the background, shallow depth of field.
263
1,313
6,895
2,291,270
25 Oct 2024
And now video games!
25 Oct 2024

I'm sharing something unique we've been making at Google (w/ UNC). We are releasing our work on a new class of interactive experiences that we call generative infinite games, essentially video games where the game mechanics and graphics are fully subsumed by generative models 🧵

3
549
25 Oct 2024
Now you can RF-Inversion your personalized GIF in any way you want! 🔥
github.com/LituRout/RF-Inver…
1
780
Yujia Chen retweeted

17 Oct 2024
Using @logtdx implementation of RF-Inversion by @Google and @litu_rout_ and @natanielruizg I think there may be a method here for consistent stylized animation frames.
If we could somehow just align these grids it would be very powerful
Grid in the second tweet
6
3
44
6,866
17 Oct 2024
Thanks for the superrr quick reproduction!

I'll be posting more of my implementations and experiments on here from now on
For now, implementation of RF-Inversion for unsampling and editing images using Flux
github.com/logtd/ComfyUI-Flu…

1
1
462
17 Oct 2024
!
16 Oct 2024
RF Inversion reimplemented in <24 hours with some super nice results - I love this community
github.com/logtd/ComfyUI-Flu…
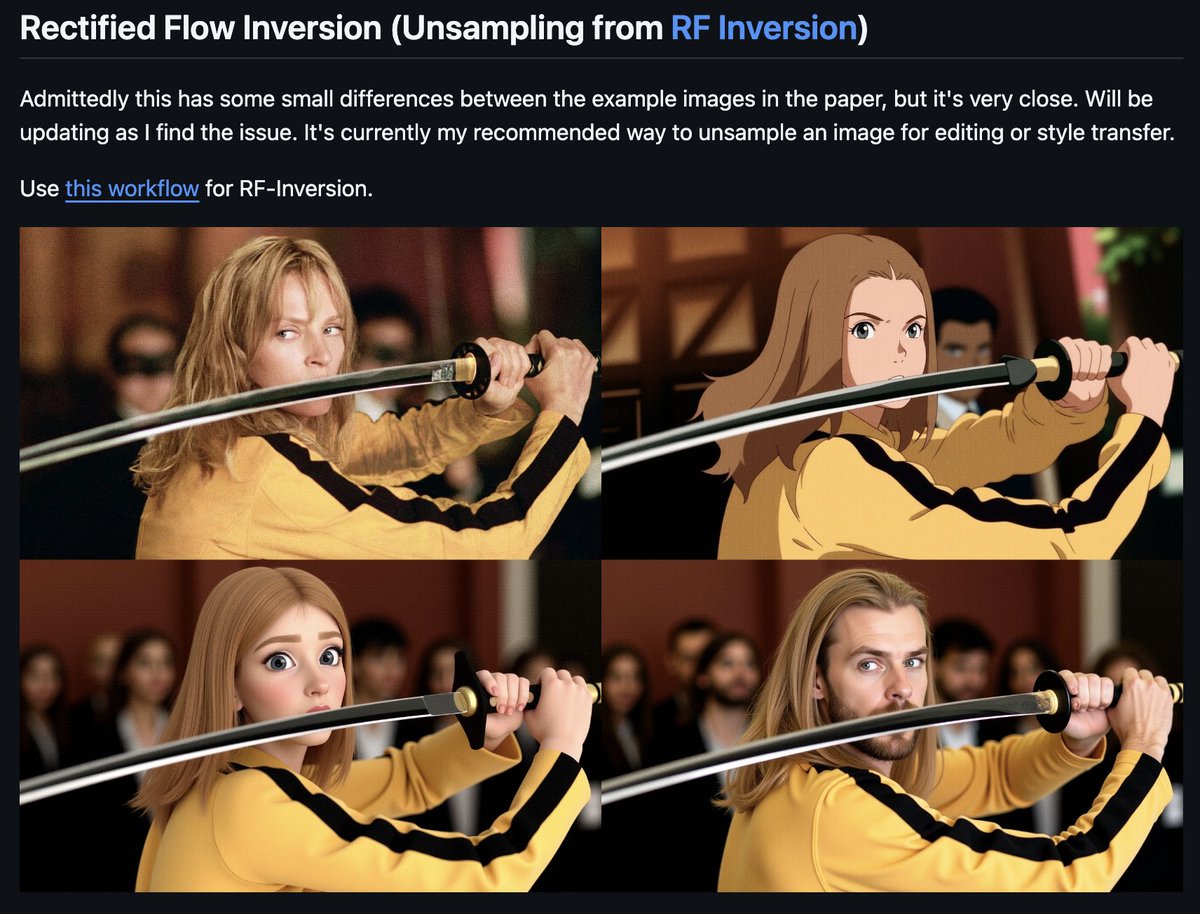
87
15 Oct 2024
Look how much we can do with such simple yet efficient techniques! Sometimes you just need a clean theory with solid proofs! Great work team!
15 Oct 2024
Diffusion based image editing and personalization methods are expensive💰due to training, latent optimization or prompt-tuning🤷♂️.
Introducing RF-Inversion🎯,the first efficient zero-shot inversion and editing framework for Flux🚀without training,optimization or prompt-tuning🧵⬇️

1
1
8
725

Open-MAGVIT2
An Open-Source Project Toward Democratizing Auto-regressive Visual Generation
paper page: huggingface.co/papers/2409.0…
We present Open-MAGVIT2, a family of auto-regressive image generation models ranging from 300M to 1.5B. The Open-MAGVIT2 project produces an open-source replication of Google's MAGVIT-v2 tokenizer, a tokenizer with a super-large codebook (i.e., 2^{18} codes), and achieves the state-of-the-art reconstruction performance (1.17 rFID) on ImageNet 256 times 256. Furthermore, we explore its application in plain auto-regressive models and validate scalability properties. To assist auto-regressive models in predicting with a super-large vocabulary, we factorize it into two sub-vocabulary of different sizes by asymmetric token factorization, and further introduce "next sub-token prediction" to enhance sub-token interaction for better generation quality. We release all models and codes to foster innovation and creativity in the field of auto-regressive visual generation.

1
45
260
40,704
6 Sep 2024
This is so cool

Loopy
Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
paper page: huggingface.co/papers/2409.0…
With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
112
Yujia Chen retweeted
26 Aug 2024
BIG news. @Google just released official code for RB-Modulation! Want to condition your diffusion model on a subject or style image without using IP-Adapters, then try our method. (works on StableCascade and is adaptable to SDXL and Flux)
github.com/google/RB-Modulat…
9
74
383
85,873