
PhD Student, Applied Machine Learning, University of Cambridge
Joined December 2022
- Tweets 177
- Following 402
- Followers 602
- Likes 372
50 Photos and videos








Pinned Tweet

17 Feb 2025
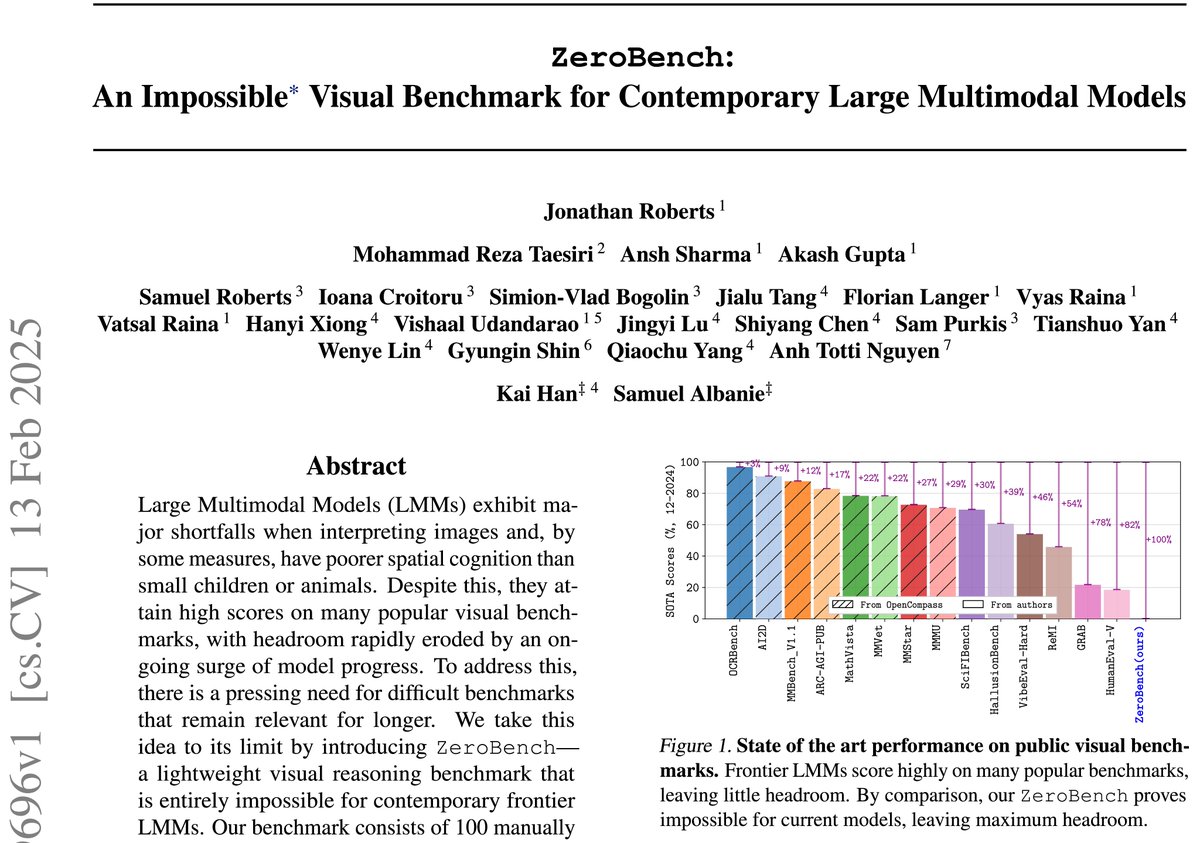
Is computer vision “solved”?
Not yet
Current models score 0% on ZeroBench
🧵1/6
57
246
2,580
1,449,341
Jun 11
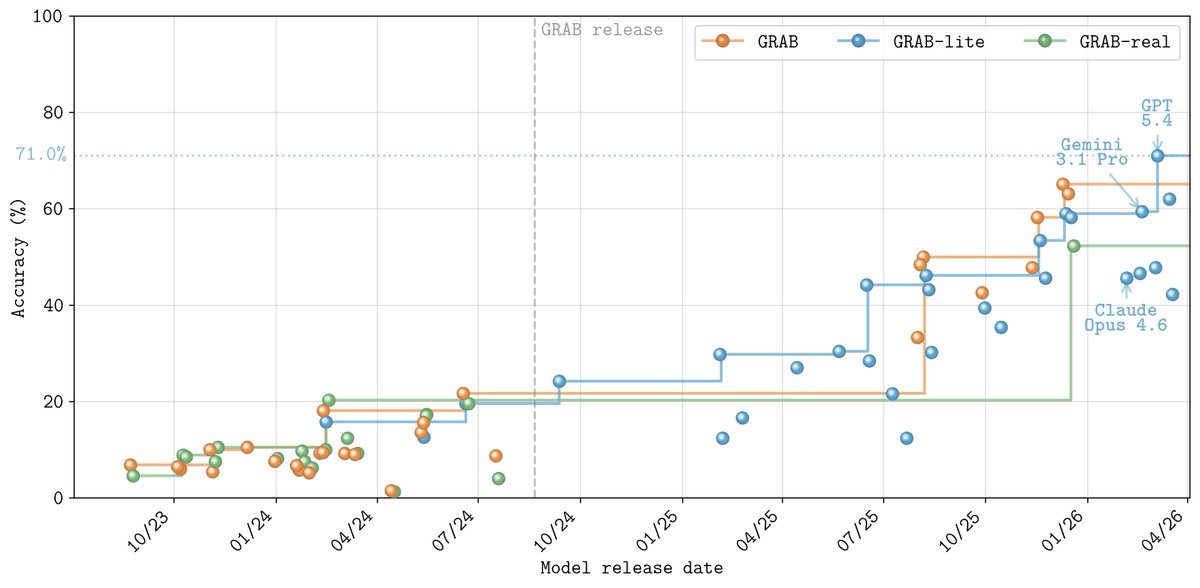
Claude Fable 5 sets a new SOTA on GRAB-lite: 74%
@ClaudeDevs are pushing the frontier
The best models scored around 20% when GRAB was released
On the current trajectory, GRAB-lite is projected to be ~100% by mid-2027
A reminder that tracking the frontier needs hard evals
2
5
477
Jun 11
Revisiting transport networks after ~3 years
In 2023, we evaluated whether GPT-4 could recreate the Hong Kong MTR, and the result felt remarkable at the time
Now, Claude Fable 5 can one-shot a live, interactive MTR map with real-time train positions

How An LLM Sees The World’s Geography
-Experiments on
factual tasks (location, distance, elevation)
more complex ones (generating country outlines, travel networks, supply chain analysis)
-GPT-4 (w/ out plugins or Internet) knows a lot about the world
arxiv.org/abs/2306.00020

2
8
1,870
Jun 11
2023 paper: arxiv.org/abs/2306.00020
Train data: MTR's real-time Next Train API on DATA.GOV.HK
Map: OpenStreetMap track geometry over a CARTO basemap
55
Jun 10
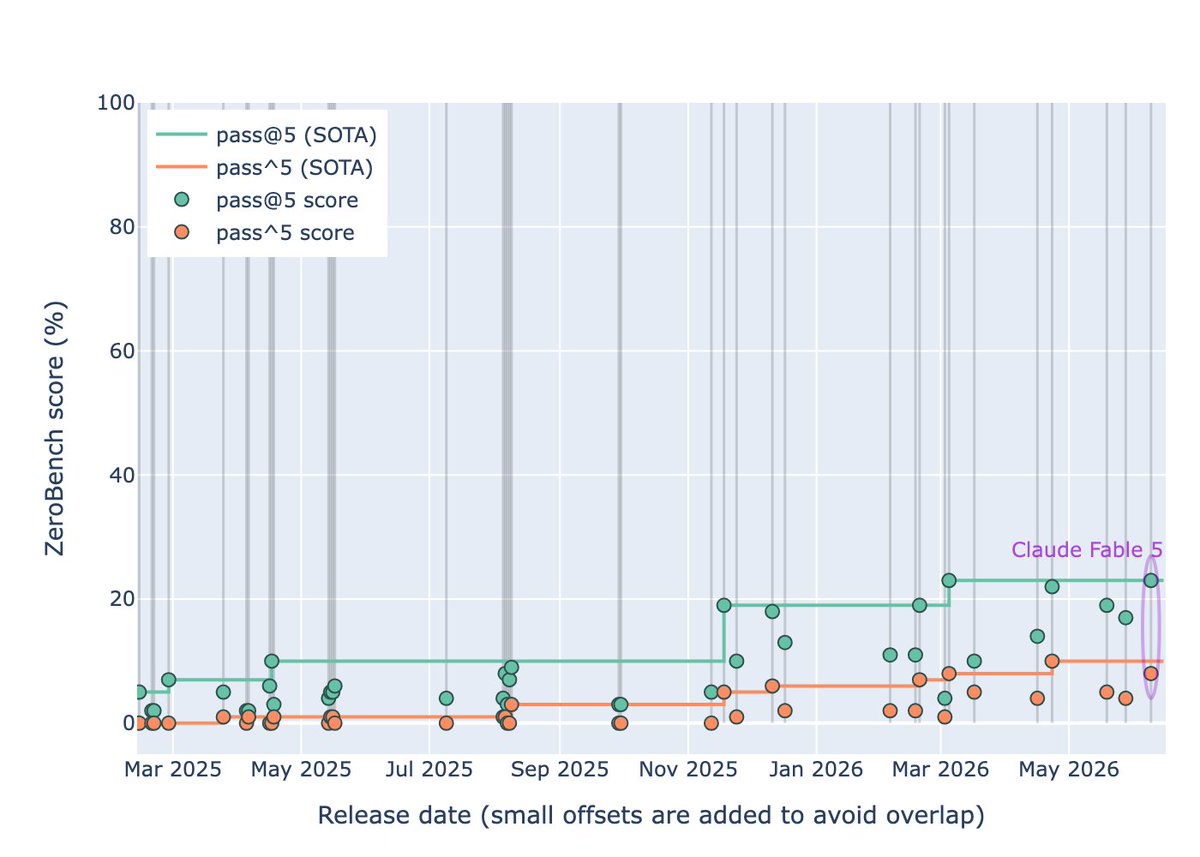
Claude Fable 5 is strong on ZeroBench, but not a clear breakthrough
23% pass@5 (tied SOTA)
8% pass^5 (SOTA 10%)
3.6% refusal rate
For comparison, other recent releases (pass@5 / pass^5):
Opus 4.8: 17 / 4
Gemini 3.5 Flash: 19 / 5
A good result, but still plenty of headroom
2
1
8
2,418
Jun 10
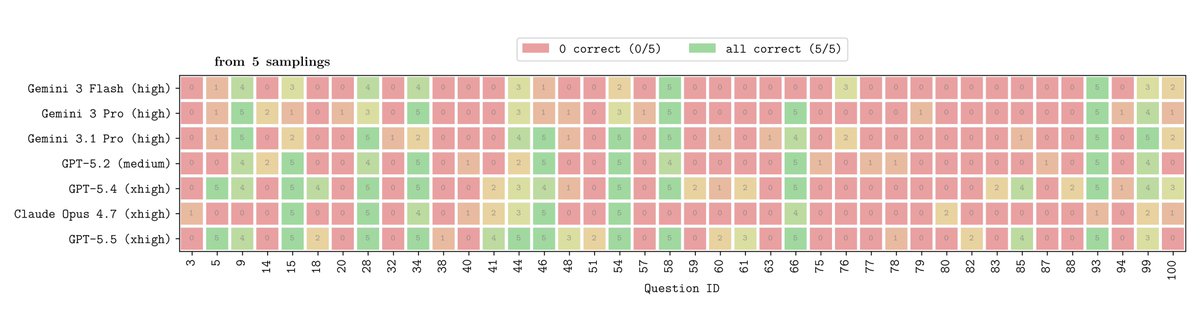
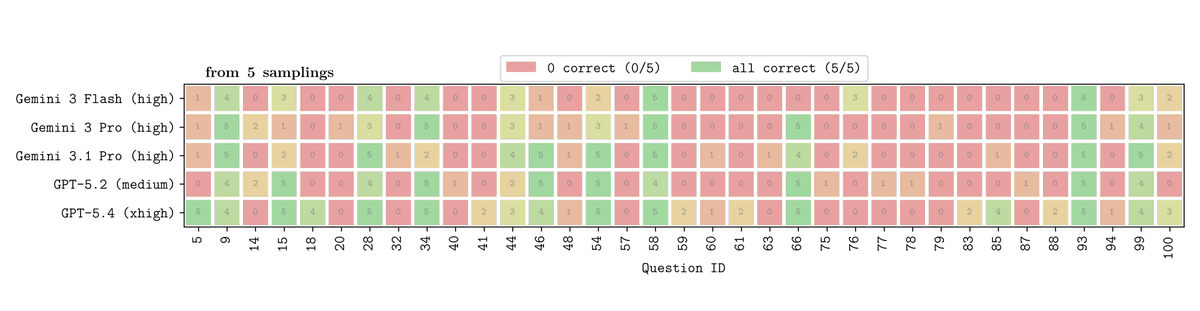
Answer distributions for top models across 5 samples
Similar aggregate scores but different reliability profiles
ZeroBench still has substantial headroom in both reliability and peak performance
Leaderboard: zerobench.github.io
Data: huggingface.co/datasets/jona…
131
Apr 26
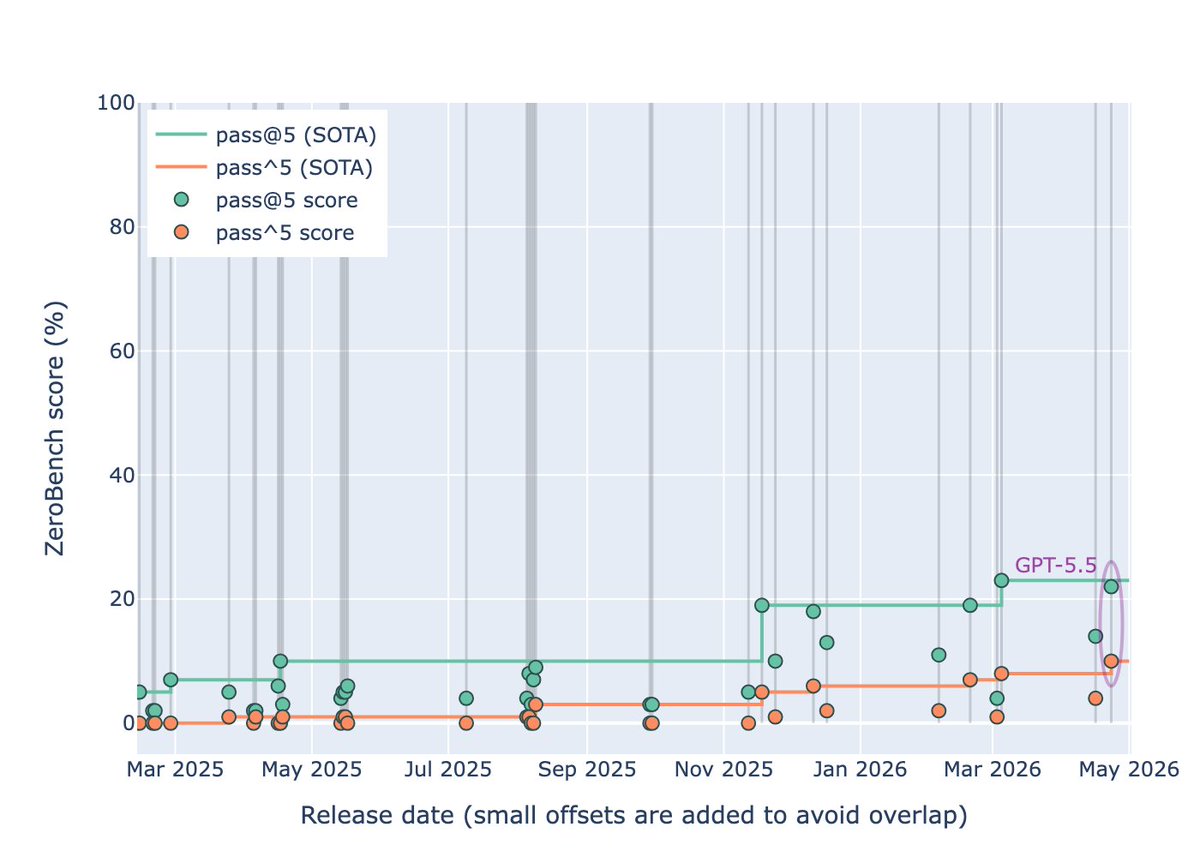
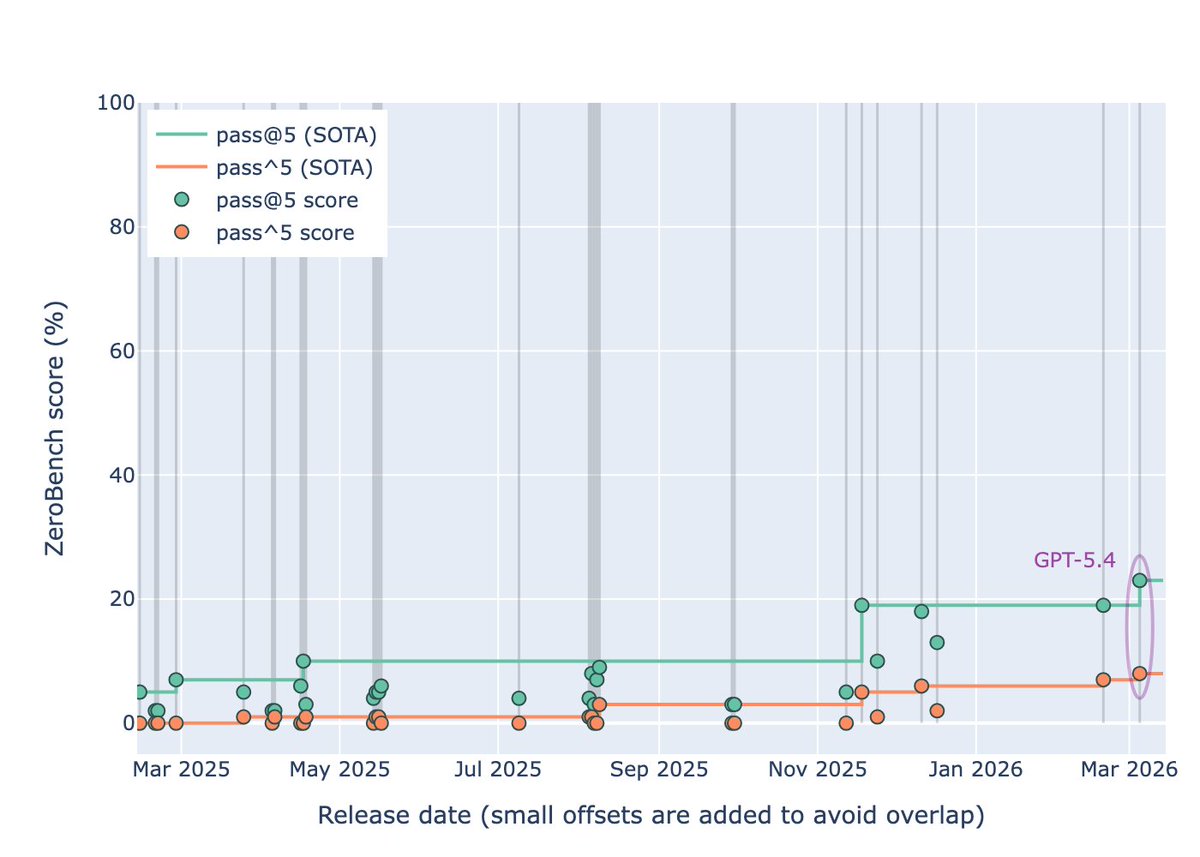
GPT-5.5 (xhigh) sets a new pass^5 high score on ZeroBench
pass@5: 22% (SOTA 23%)
pass^5: 10% (prev. SOTA 8%)
Best 5/5 reliability so far
Strong result from @sama and the OpenAI team
4
16
163
7,431
Apr 26
The matrix shows how often the models answered each question correctly across 5 samples
Leaderboard: zerobench.github.io
Data: huggingface.co/datasets/jona…
1
5
459
Apr 19
The Claude models are great for coding
But on visual reasoning they still trail the frontier
On ZeroBench (pass@5 / pass^5):
Opus 4.7 (xhigh) - 14 / 4
Opus 4.6 - 11 / 2
GPT-5.4 (xhigh) - 23 / 8
1
2
15
1,514

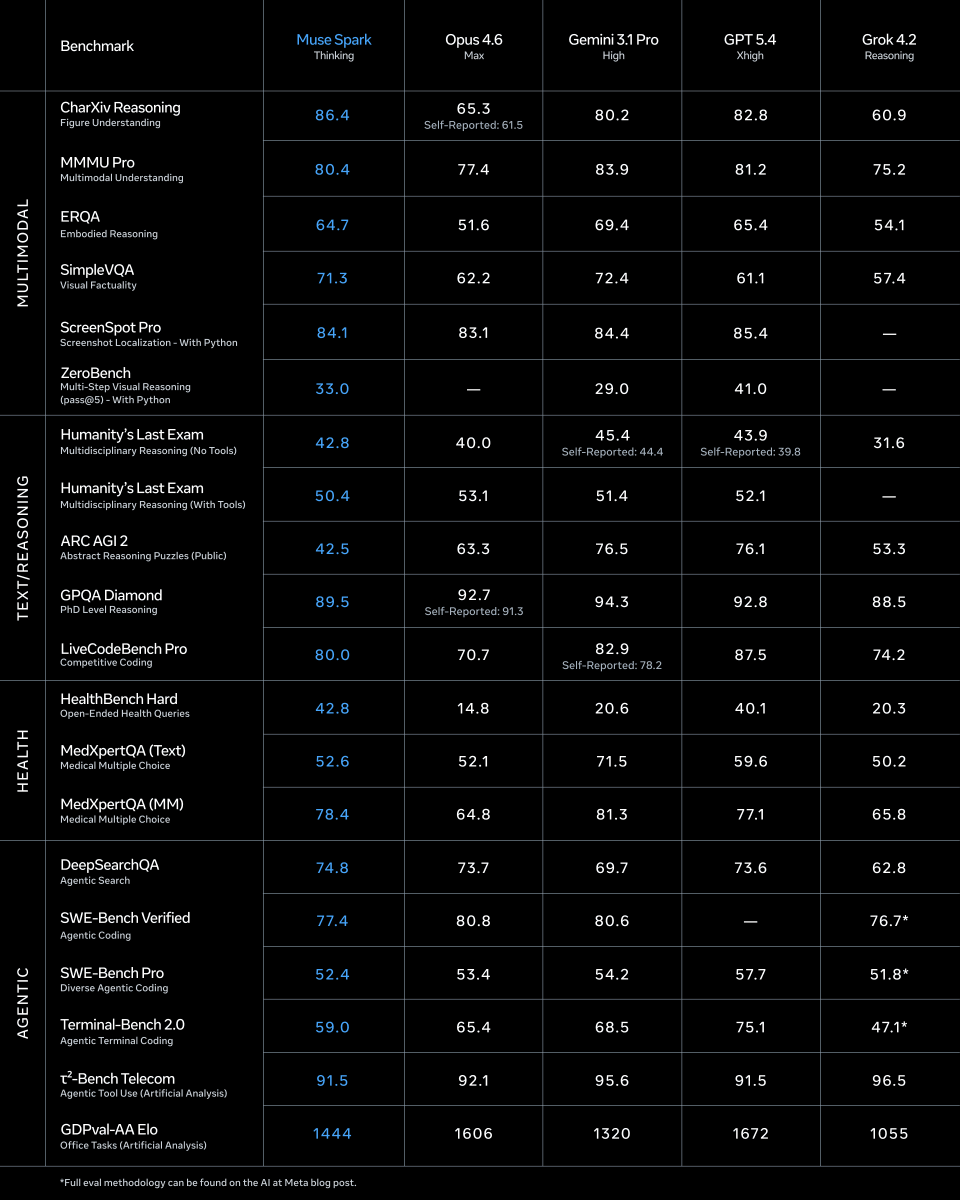
Muse Spark scores 33% pass@5 on our ZeroBench.🚀
Glad to see models getting further away from "zero".
zerobench.github.io/
Apr 8

1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
2
2
22
2,702
👀 Muse Spark scores 33% pass@5 w/ python on ZeroBench
Apr 8
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
2
6
415
📣📣 New SOTA for GRAB-lite, our graph analysis benchmark
GPT-5.4 crushes Opus 4.6: 71.0% vs 45.6%
Impressive work from @gdb and team
Updated leaderboard now live
1
1
9
1,798
Mar 22
Following yesterday's update, the @warpsurfai Node SDK now also supports @usekernel
Fast remote browser sessions for JavaScript and TypeScript
4
154
Mar 21
The @warpsurfai Python SDK now has @usekernel support
You can now run warpsurf from Python on crazy fast browser sessions
1
4
528