
Architect, Founder, Angel, Advisor, Keynote speaker, OSS: @OpenLineage @MarquezProject, ASF: Parquet Arrow Iceberg 🐖. 🦋 julien.ledem.net . he/him
Joined May 2009
- Tweets 11,050
- Following 2,092
- Followers 4,113
- Likes 2,897
1,194 Photos and videos














Pinned Tweet

18 Oct 2024
If you follow me on here, you should follow me on there:
bsky.app/profile/julien.lede…
1
1
2
1,900
Julien Le Dem retweeted

In SF during Snowflake Summit June 1-3? Duck out (ha!) to The Dive! Hear from rockstars at Anthropic, Braintrust, Lovable, Hex, & more.
See the future of lakehouses with @J_ , creator of Apache Parquet, and @zeroshade, founder at Columnar (& me!)
Register! thedive.motherduck.com/
3
9
533
Julien Le Dem retweeted

May 12
@J_ & Pierre Lacave of @datadoghq on how they rely on and contribute to key projects in the data ecosystem:
Arrow for data interchange
Substrait for plans
Calcite as an optimizer
DataFusion as an execution core
Parquet for columnar storage

2
5
222
Apr 11
Thank you for letting me keynote day 2 of the Iceberg summit. I hope you all enjoyed it!
bsky.app/profile/julien.lede…
2
1
258




Julien Le Dem retweeted
Apr 8
The database landscape is going through its biggest shift in a decade. AI workloads are pushing OLTP and OLAP closer together, object storage is becoming the de facto foundation for AI search at hundred‑billion‑ to trillion‑document scale, and agents are spinning up databases and schemas programmatically in patterns classic systems were never optimized for.
AI Council's Data Engineering & Databases track is where the builders re-architecting the stack come together. Curated by @saisrirampur, Director of Product at @ClickHouseDB, here's the lineup:
→ Hannes Mühleisen, Co-Founder & CEO at @duckdb: "Super-Secret Next Big Thing for DuckDB"
→ @nikhilbenesch, CTO at @turbopuffer: "Fast AI Search on Object Storage @ >1 Trillion Scale"
→ @J_ & Pierre Lacave, Principal Engineer & Staff Engineer at @datadoghq: "The Deconstructed Database at Datadog"
→ @iskakaushik, Engineering Lead at ClickHouseDB: "Building a Unified OLTP OLAP Database for AI Workloads"
→ Bhargavi Reddy Dokuru, Staff Data Engineer at @netflix: "Democratizing Analytics via Self Service: Netflix Games Edition"
→ @kelvich, Principal Software Engineer at @databricks & Neon co-founder: "AI Needs a New Kind of OLTP: Lakebase & Serverless Postgres in the Agent Era"
→ Robin Tang, Co-founder & CTO at @artie_labs: “Scaling CDC to Trillions of Rows: What Broke, What We Rebuilt, and What AI Demands Next”
A huge thank you to Sai for curating this awesome track!
Join us SF, May 12-14! 🎟️ aicouncil.com



5
15
1,100
Julien Le Dem retweeted

Apr 3
@J_ co-created Apache Parquet, Apache Arrow, and OpenLineage. Three projects. Three industry standards.
Parquet at Twitter in 2013. Arrow at Dremio. OpenLineage at Datakin, acquired as part of Astronomer's $213M Series C. He is now Principal Engineer at Datadog and an officer of the Apache Software Foundation. That is an unusual track record of picking the right abstraction at the right time.
His OpenXData talk argues that the current wave of challengers -- Lance, Vortex, Nimble, FastLanes, BtrBlocks, F3 -- are solving real problems but misreading what made Parquet succeed in the first place. The core contribution was not the encoding choices. It was the community consensus mechanism those choices were built inside. His case: use established open source communities to absorb these innovations rather than fragment the ecosystem across six competing formats.
He published the written version of this argument at sympathetic.ink in December 2025. OpenXData is where you can push back live.
👉 Register here: openxdata.ai

2
6
359
Julien Le Dem retweeted
18 Oct 2024
If you follow me on here, you should follow me on there:
bsky.app/profile/julien.lede…
1
1
2
1,900
11 Dec 2025
In the past few years, we’ve seen a cambrian explosion of new columnar formats, challenging the hegemony of Parquet. Presumably, the design of yore is not going to cut it moving forward. I spent some time to understand how things actually changed.
sympathetic.ink/2025/12/11/C…
3
17
91
6,572
11 Dec 2025
I also gave a talk on this topic.
Slides: docs.google.com/presentation…
Recording here: youtube.com/watch?v=S_aoc9dE…
1
8
1,121
9 Dec 2025
If you missed my talk "The advent of the open data lake" at AI By the Bay, the recording is now available.
ai.bythebay.io/talks/the-adv…
youtube.com/watch?v=xHGVCVjA…
3
543
Julien Le Dem retweeted

8 Dec 2025
There is some crazy (good) activity on the @ApacheParquet mailing list for new encodings. A sample: PFOR, FSST, ALP, Strings and Cascaded Encodings. 🤯 Huge kudos to Arnav Balyan, Prateek Gaur, and Micah Kornfield for driving this.
lists.apache.org/list.html?d…
1
6
57
5,548
14 Nov 2025
If you missed me giving it live, the slides of my talk, "Column Storage for the AI era" are available here:
docs.google.com/presentation…
1
14
117
10,366
10 Nov 2025
I’ll be speaking in Mountain View on Thursday. Come say hi!
7 Nov 2025

Parquet sparked a revolution in columnar storage. Now AI workloads are driving a new wave of change.
At 𝗢𝗽𝗲𝗻 𝗟𝗮𝗸𝗲𝗵𝗼𝘂𝘀𝗲 𝗔𝗜 𝗠𝗶𝗻𝗶 𝗦𝘂𝗺𝗺𝗶𝘁, Julien Le Dem (@datadoghq) will cover:
🔹 What’s changed since Parquet was introduced
🔹 Why new columnar formats are emerging now
🔹 The encoding advances shaping what comes next—and how they’re pushing Parquet to evolve
📅 Nov 13 | Mountain View
🔗 Register: luma.com/OLMS-1113
#openlakehouse #opensource #columnstorage #ai #parquet

1
5
1,109
7 Nov 2025
Higher latency but higher throughput on improving the overall data ecosystem.
7 Nov 2025

"If you want to go fast, go alone; If you want to go far, go together"
New Apache Parquet Community page is up: parquet.apache.org/community…

366
Julien Le Dem retweeted

31 Oct 2025
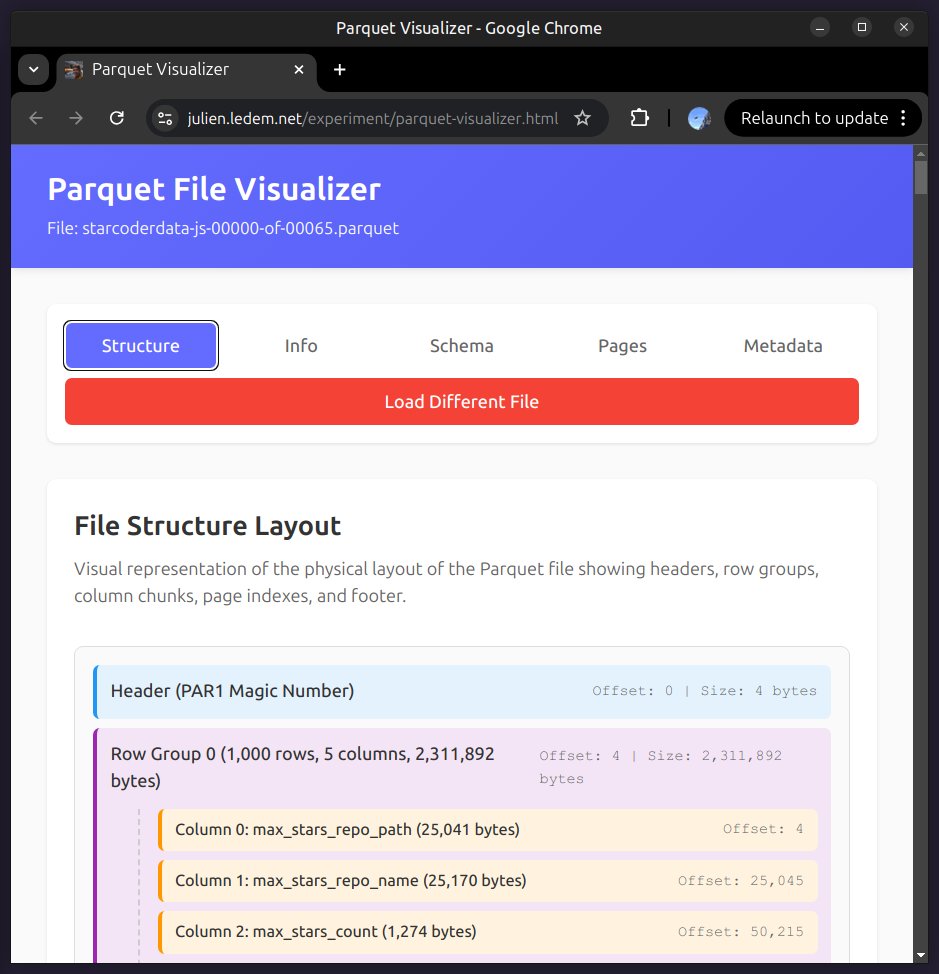
Cool parquet metadata visualizer by @J_, powered by Hyparquet
2
2
297
22 Oct 2025
If you've been wondering why we see a flurry of new columnar formats, come see me present "Column Storage for the AI Era". I'll talk about what has changed, new advances in data encoding and how that's pushing Parquet to evolve.
Event tomorrow: luma.com/pxikwty3
1
5
609
1 Oct 2025
New file format just dropped !

Our SIGMOD paper with @XinyuZeng218 @huanchenzhang @wesmckinn @pateljm on creating a next generation open-source data file format is out. F3 is a future-proof file format avoids the mistakes of Parquet.
📄 Paper: db.cs.cmu.edu/papers/2025/ze…
📁 Code: github.com/future-file-forma…
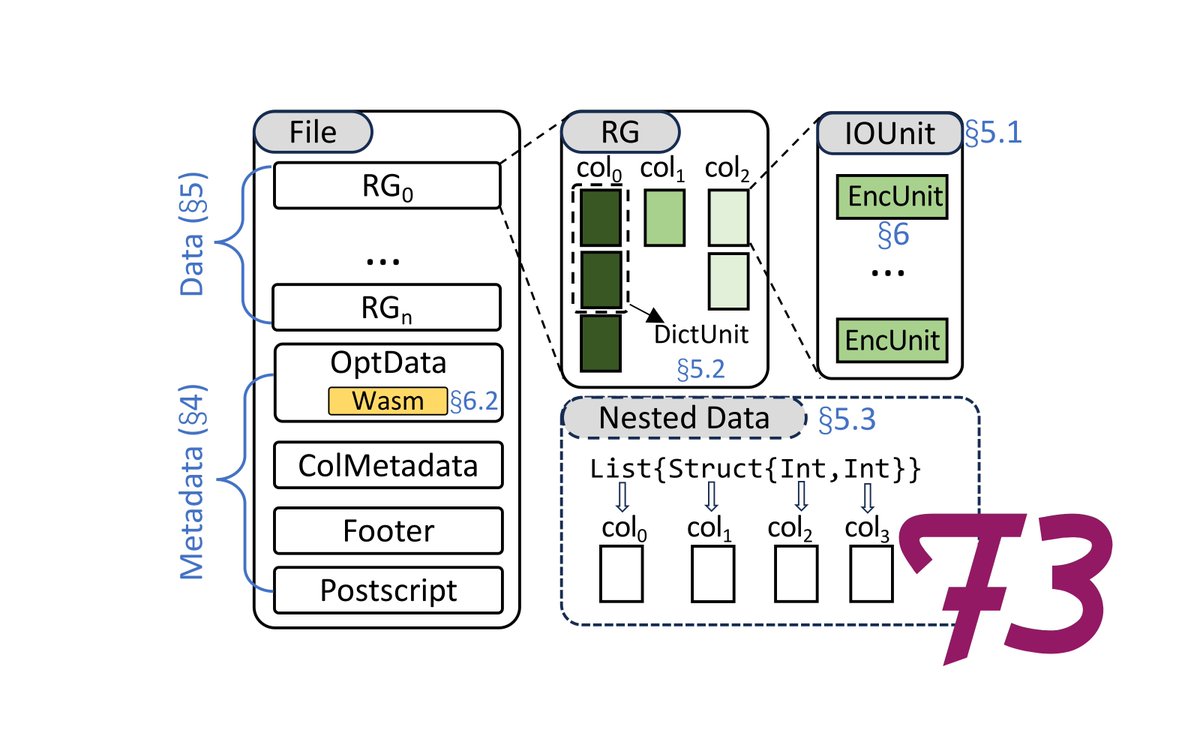
ALT F3: The Open-Source Data File Format for the Future SIGMOD 2025
2
1
3
763
24 Sep 2025
I'm trying to understand a bit better real life deployments of open source Clickhouse.
If you're using it, what does your deployment look like?
1
2
353
Julien Le Dem retweeted
27 Jul 2025
The FastLanes format paper from @afroozeh3 and @peterabcz contains interesting and practical ideas for representing SIMD friendly cascaded encodings. I think almost all of the ideas could be applied to extend @ApacheParquet as a new encoding scheme.
github.com/cwida/FastLanes/b…
3
8
69
4,692