
Joined January 2017
- Tweets 1,948
- Following 1,457
- Followers 535
- Likes 6,761
147 Photos and videos














Pinned Tweet

Do electric sheep machines dream of ... linguistics
(prompt engineer: Bralynn S. Bell; "The strangest flea market", Midjourney & Editing)

1
1
13
1,097
Jacqueline Bellon (jacbellon.bsky.social) retweeted

6 Sep 2025
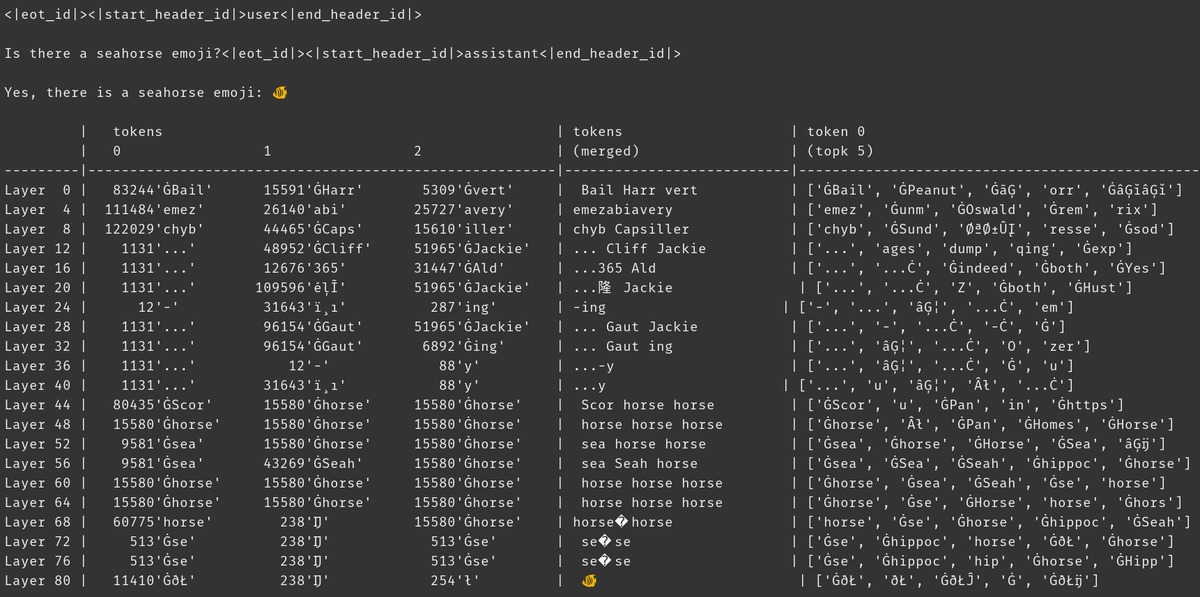
why does this happen? the model believes there's a seahorse emoji, sure, but why does that make it output a *different* emoji? here's a clue from everyone's favorite underrated interpretability tool, logit lens!
in logit lens, we use the model's lm_head in a weird way. typically, the lm_head is used to turn the residual (the internal state built up over the model layers) into a set of token probabilities after the final layer. but in logit lens, we use the lm_head after *every* layer - showing us what tokens the model would output if that layer were the final layer.
for early layers, this results in hard-to-interpret states. but as we move through the layers, the model iteratively refines the residual first towards concepts useful for continuing the text, and then towards the final prediction.
looking at the image again, at the final layer, we have the model's actual output - ĠðŁ, IJ, ł - aka, an emoji byte prefix followed by the rest of the fish emoji.
(it looks like unicode nonsense because of a tokenization quirk - don't worry about it. if you're curious, ask claude about this line of code: `bytes([byte_decoder[c] for c in 'ĠðŁIJł']).decode('utf-8') == ' 🐠'`)
but look what happens in the middle layers - we don't just get emoji bytes! we get those *concepts*, specifically the concept of a seahorse. for example, on layer 52, we get "sea horse horse". later, in the top-k, we get a mixture of "sea", "horse", and that emoji prefix, "ĠðŁ".
so what is the model thinking about? seahorse emoji! it's trying to construct a residual representation of a seahorse emoji.
why would it do that? well, let's look at how the lm_head actually works. the lm_head is a huge matrix of residual-sized vectors associated with token ids. when a residual is passed into it, it's going to compare that residual with each token vector, and in coordination with the sampler, select the token id with a vector most similar to the residual. (more technically: it's a linear layer without a bias, so v @ w.T does dot products with each unembedding vector, then log_softmax and argmax/temperature sample.)
so if the model wants to output the word "hello", it needs to construct a residual similar to the vector for the "hello" output token that the lm_head can turn into the hello token id. and if the model wants to output a seahorse emoji, it needs to construct a residual similar to the vector for the seahorse emoji output token(s) - which in theory could be any arbitrary value, but in practice is seahorse emoji, word2vec style.
the only problem is the seahorse emoji doesn't exist! so when this seahorse emoji residual hits the lm_head, it does its dot product over all the vectors, and the sampler picks the closest token - a fish emoji.
now, that discretization is valuable information! you can see in Armistice's example that when the token gets emplaced back into the context autoregressively, the model can tell it isn't a seahorse emoji. so it tries again, jiggles the residual around and gets a slightly different emoji, rinse and repeat until it realizes what's going on, gives up, or runs out of output tokens.
but until the model gets the wrong output token from the lm_head, it just doesn't know that there isn't a seahorse emoji in the lm_head. it assumes that seahorse emoji will produce the token(s) it wants.
------------------
to speculate (even more), i wonder if this a part of the benefit of RL - it gives the models information about their lm_head that's otherwise difficult to get at because it's at the end of the layer stack. (remember that base models are not trained on their own outputs / rollouts - that only happens in RL.)


45
153
1,294
180,046
Jacqueline Bellon (jacbellon.bsky.social) retweeted

22 Sep 2025
Putting wheels on this cross to bear is the best possible metaphor for American Evangelicalism

1,231
18,572
190,249
5,422,747
Human-technology and human-media interactions through adversarial attacks
youtube.com/watch?v=IsFgcyPd…
38
Gilbert Simondon's Image Theory and Human-technology Relations through Imagination and AI image generation. In: Philipp Roth et al. (Hrsg.): Making Media Futures: Machine Visions and Technological Imaginations. Routledge.
doi.org/10.4324/978100346791…
2
2
522
𝐀𝐫𝐭𝐢𝐟𝐢𝐜𝐢𝐚𝐥 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 𝐚𝐧𝐝 𝐍𝐞𝐰 𝐇𝐮𝐦𝐚𝐧-𝐓𝐞𝐜𝐡𝐧𝐨𝐥𝐨𝐠𝐲 𝐑𝐞𝐥𝐚𝐭𝐢𝐨𝐧𝐬 𝐚𝐬 𝐚 𝐂𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞 𝐟𝐨𝐫 𝐭𝐡𝐞 𝐏𝐡𝐢𝐥𝐨𝐬𝐨𝐩𝐡𝐲 𝐨𝐟 𝐒𝐜𝐢𝐞𝐧𝐜𝐞
May, 23rd 2025, 09:00-16:00 (CET), University of Münster
uni-tuebingen.de/en/277482
2
1
106
Call for Abstracts for
"Artificial Intelligence and New Human-Technology Relations as a Challenge for the Philosophy of Science"
23.05.2025, 10-16 Uhr, University of Münster (Senatssaal am Schlossplatz 1)
108
Jacqueline Bellon (jacbellon.bsky.social) retweeted

15 Oct 2024
🟠 En menos de un mes, los mayores especialistas en Simondon del planeta se reúnen en Lisboa.
cful.letras.ulisboa.pt/praxi…

1
10
18
1,855
Jacqueline Bellon (jacbellon.bsky.social) retweeted

9 Oct 2024
The #NobelPrizeinPhysics2024 for Hopfield & Hinton rewards plagiarism and incorrect attribution in computer science. It's mostly about Amari's "Hopfield network" and the "Boltzmann Machine."
1. The Lenz-Ising recurrent architecture with neuron-like elements was published in 1925 [L20][I24][I25]. In 1972, Shun-Ichi Amari made it adaptive such that it could learn to associate input patterns with output patterns by changing its connection weights [AMH1]. However, Amari is only briefly cited in the "Scientific Background to the Nobel Prize in Physics 2024." Unfortunately, Amari's net was later called the "Hopfield network." Hopfield republished it 10 years later [AMH2], without citing Amari, not even in later papers.
2. The related Boltzmann Machine paper by Ackley, Hinton, and Sejnowski (1985) [BM] was about learning internal representations in hidden units of neural networks (NNs) [S20]. It didn't cite the first working algorithm for deep learning of internal representations by Ivakhnenko & Lapa (Ukraine, 1965)[DEEP1-2][HIN]. It didn't cite Amari's separate work (1967-68)[GD1-2] on learning internal representations in deep NNs end-to-end through stochastic gradient descent (SGD). Not even the later surveys by the authors [S20][DL3][DLP] nor the "Scientific Background to the Nobel Prize in Physics 2024" mention these origins of deep learning. ([BM] also did not cite relevant prior work by Sherrington & Kirkpatrick [SK75] & Glauber [G63].)
3. The Nobel Committee also lauds Hinton et al.'s 2006 method for layer-wise pretraining of deep NNs (2006) [UN4]. However, this work neither cited the original layer-wise training of deep NNs by Ivakhnenko & Lapa (1965)[DEEP1-2] nor the original work on unsupervised pretraining of deep NNs (1991) [UN0-1][DLP].
4. The "Popular information" says: “At the end of the 1960s, some discouraging theoretical results caused many researchers to suspect that these neural networks would never be of any real use." However, deep learning research was obviously alive and kicking in the 1960s-70s, especially outside of the Anglosphere [DEEP1-2][GD1-3][CNN1][DL1-2][DLP][DLH].
5. Many additional cases of plagiarism and incorrect attribution can be found in the following reference [DLP], which also contains the other references above. One can start with Sec. 3:
[DLP] J. Schmidhuber (2023). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, Swiss AI Lab IDSIA, 14 Dec 2023. people.idsia.ch/~juergen/ai-…
See also the following reference [DLH] for a history of the field:
[DLH] J. Schmidhuber (2022). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, IDSIA, Lugano, Switzerland, 2022. Preprint arXiv:2212.11279. people.idsia.ch/~juergen/dee… (This extends the 2015 award-winning survey people.idsia.ch/~juergen/dee…)
209
1,184
5,332
1,161,823
Jacqueline Bellon (jacbellon.bsky.social) retweeted

30 Sep 2024
Are we ready for a world where our data is exposed at a glance? @CaineArdayfio and I offer an answer to protect yourself here:
tinyurl.com/meet-ixray
374
1,587
5,305
1,232,411
Jacqueline Bellon (jacbellon.bsky.social) retweeted
30 Sep 2024
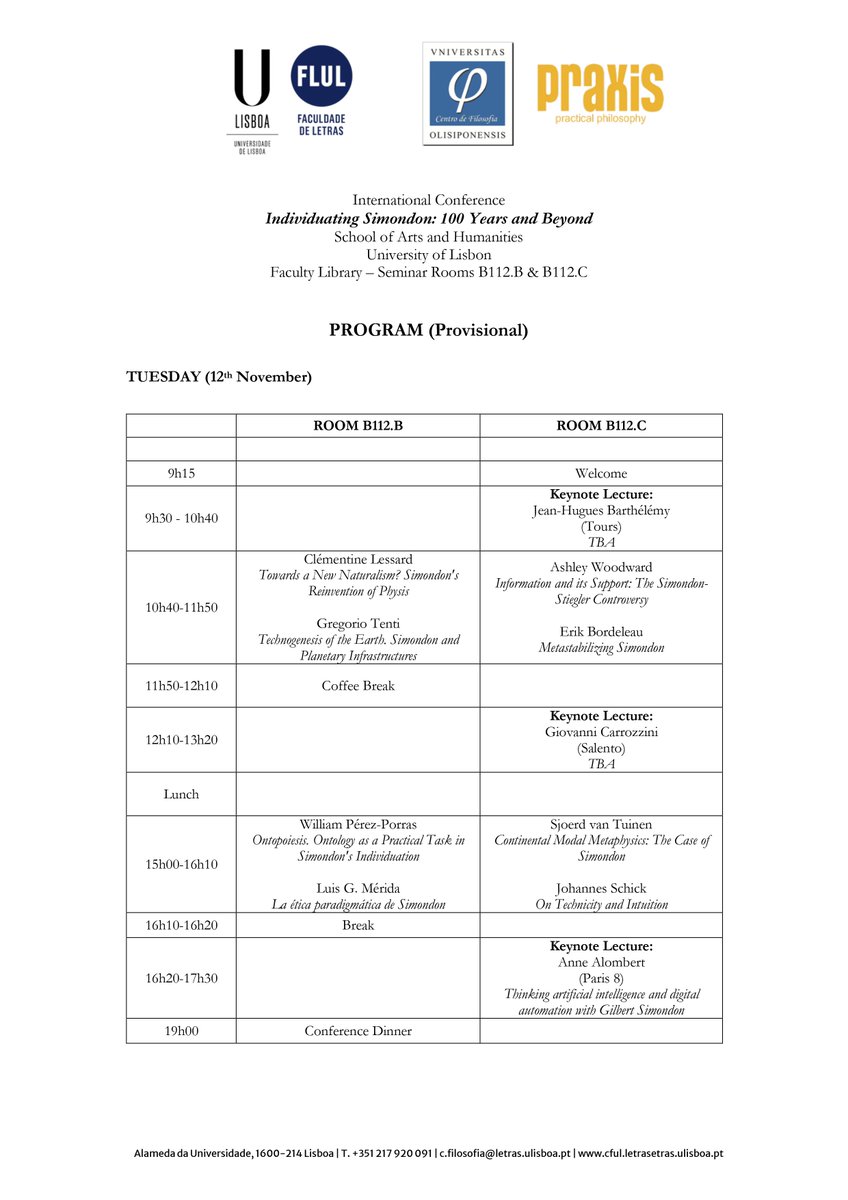
‼️🌍 Programa provisional del congreso de Lisboa por el centenario de Gilbert Simondon. Si estáis por la ciudad en esas fechas, no me lo perdería. Cartelazo.
1/3
1
7
19
1,888
Plausibel, aber unwahr: Sozialisation und Wahrscheinlichkeitspapageien
link.springer.com/chapter/10…
46
Finally published:
"Technology Socialisation?"
link.springer.com/book/10.10…
48
Jacqueline Bellon (jacbellon.bsky.social) retweeted

17 Jul 2024
Claude is similarly spassy
5
7
208
24,159
Jacqueline Bellon (jacbellon.bsky.social) retweeted

16 Jul 2024
😂

477
1,058
15,794
3,529,084
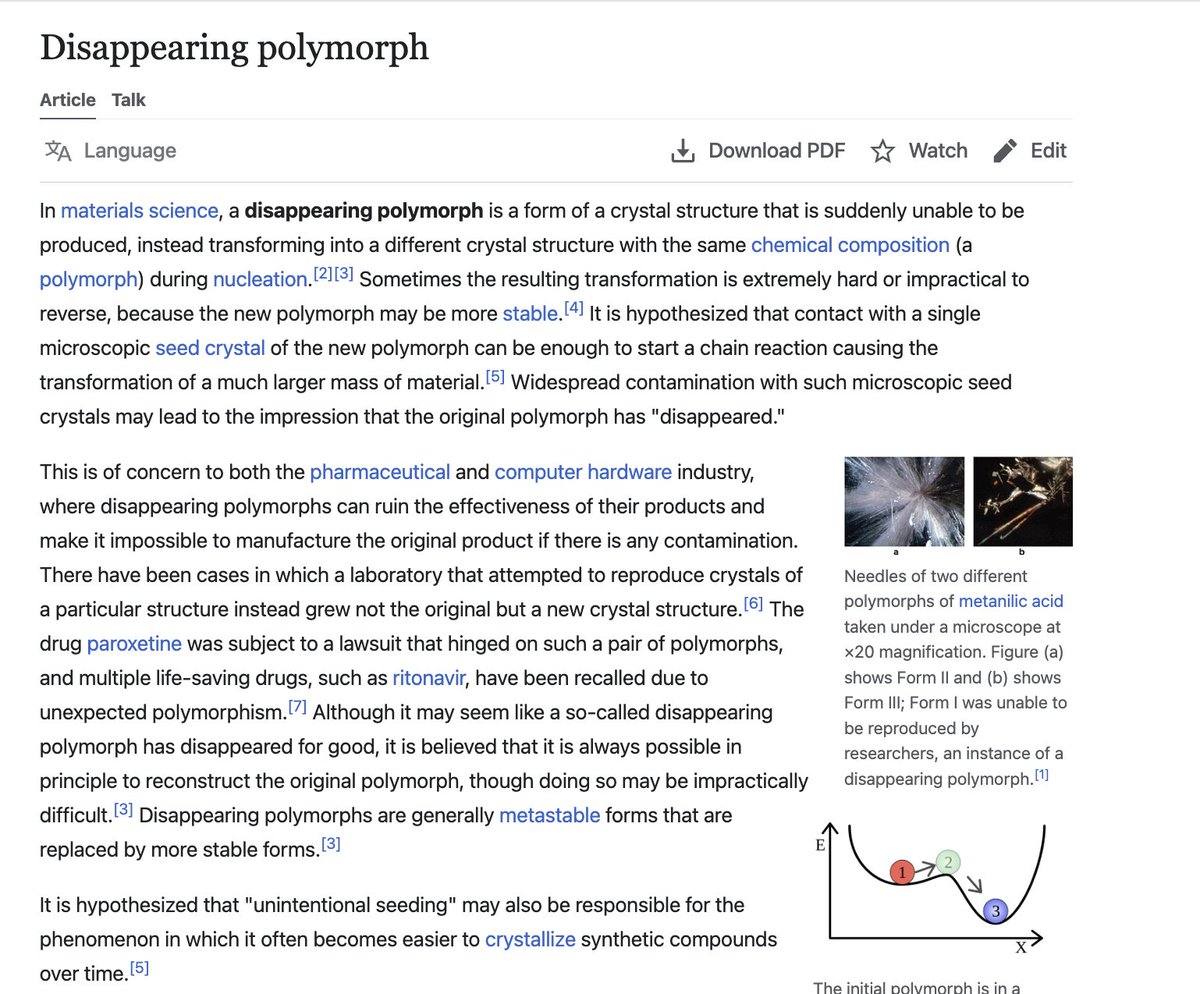
It is interesting, and it also is pretty much the main idea that Gilbert Simondon based his individuation theory (on the becoming of all things) on <3

1
100
Jacqueline Bellon (jacbellon.bsky.social) retweeted

3 Jul 2024
To all prospective PhD students of the world:
If you generate your research statement using chatGPT, your grade will be 0, and you will not be invited to the interview.
So, please save your and the committee's time.

1,060
312
6,732
3,183,102
remember early internet? was like this

I made a website. it's called "one million checkboxes dot com". it has one million checkboxes on it.
checking a box checks it for everyone.
that's it. have fun!
74

I wonder if this means Europeans just won't have access to some foundational models, or, if these rules will make the global market comply to these rules to not loose Europe
26 Mar 2024

FYI, the AI Act also addresses Copyright laundering of multi-national companies that try to dodge jurisdictions.
Providers will have to respect EU Copyright law, including training as "expressive use" if they want to sell/deploy in Europe.

1
2
347
👾 Technical objects afford more than what is intended by marketing logic. - The better you know your way around, the easier it is to help shape, counteract, be creative, make informed decisions and act in a self-determined way.
3
75