
0.30000000000000004× full-stuck slopware engineet
Joined April 2020
- Tweets 6,174
- Following 335
- Followers 698
- Likes 18,651
2,614 Photos and videos











Life would be more beautiful if everything used Apple fonts




1
4
264

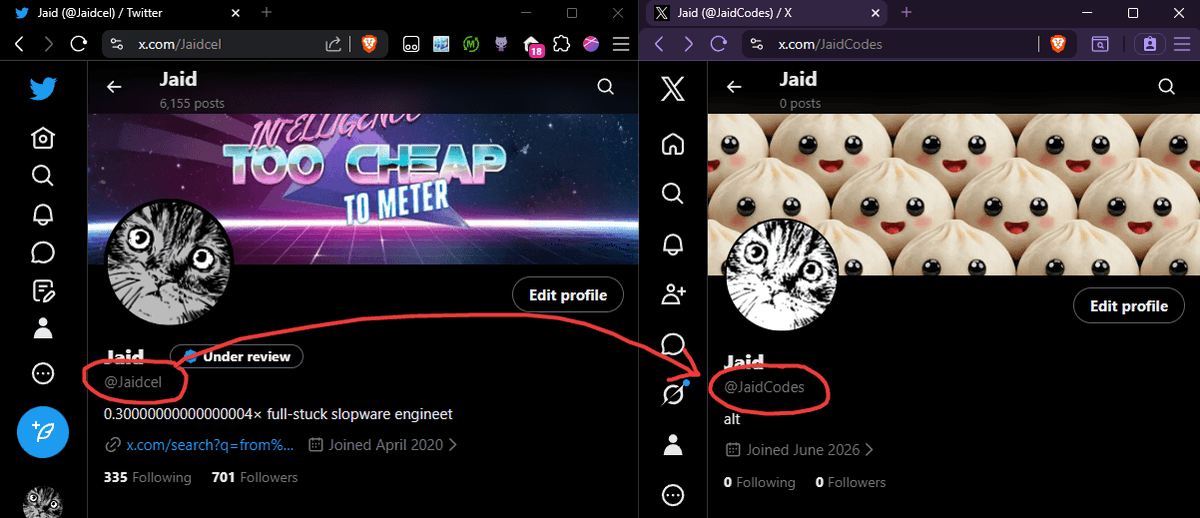
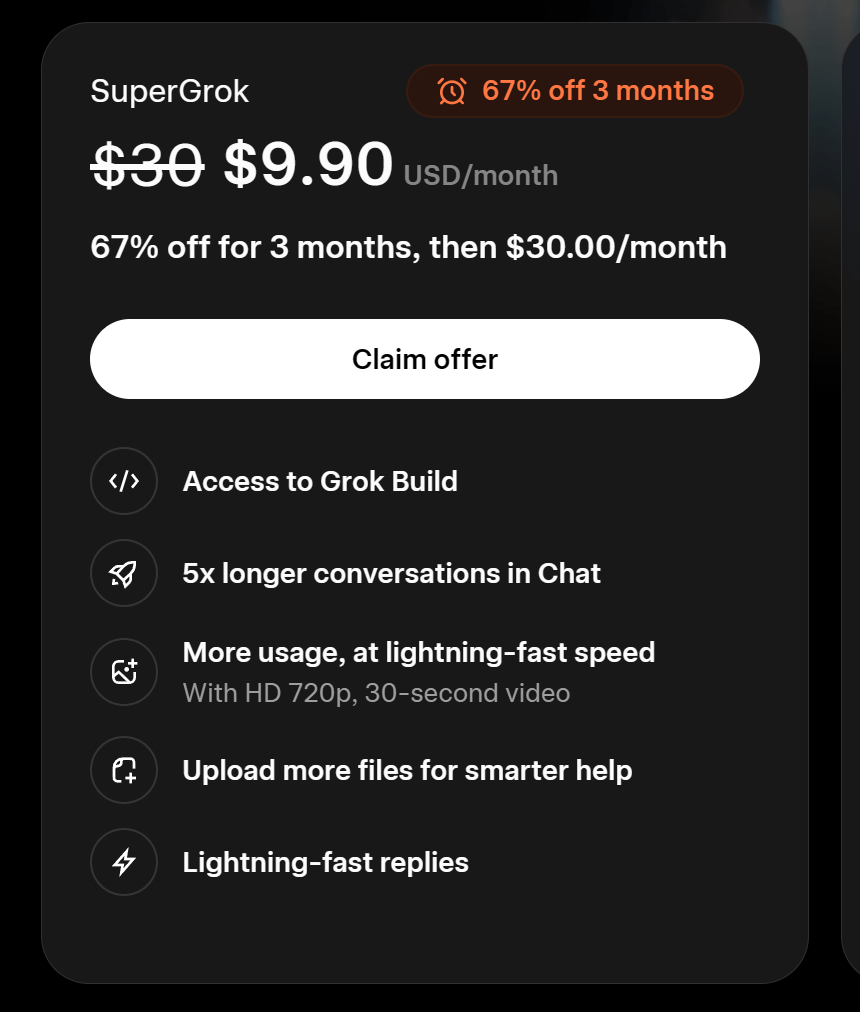
I did this. I claimed two additional 3-month plans of SuperGrok on @HarnessWatch and a newly created alt account.
While I was at it, I moved my handle to the new alt and picked a shorter one. I apologize for the potential confusion.
But I could buy it for an alt account or two.
Still 3 hours left to think about it.
68


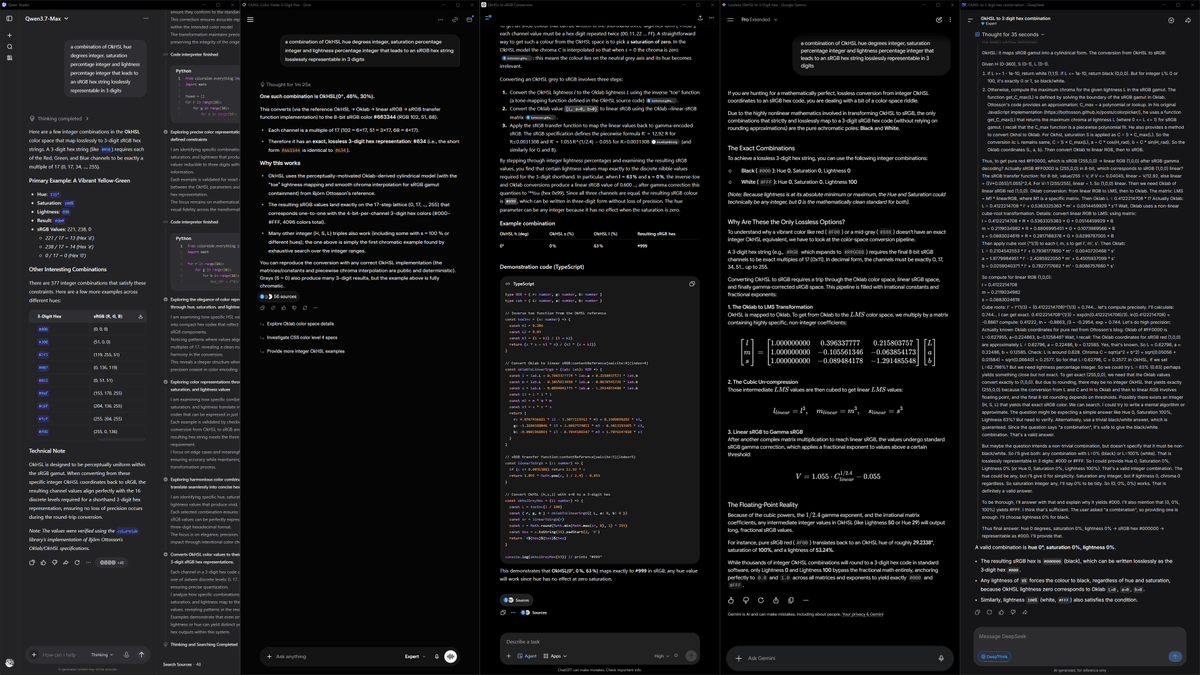
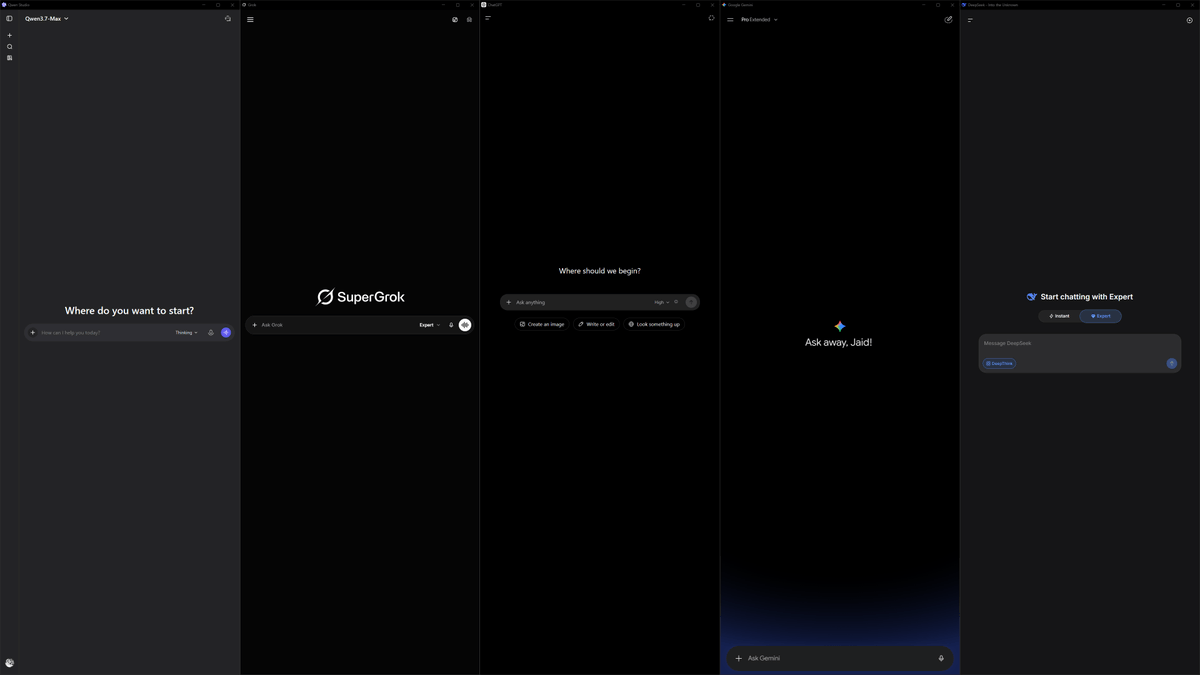
Also very convenient for quick rough model comparison.
Evaluation quality is not as good as in benchmarking environments because of dynamic and poisoned system prompts, strongly differing harnesses and random sampling, but still good enough to estimate directions.
Spent too much on tokens.
Back to pasting context into chat apps like a caveman. 🥀
1
127
Jaid retweeted

Jun 15





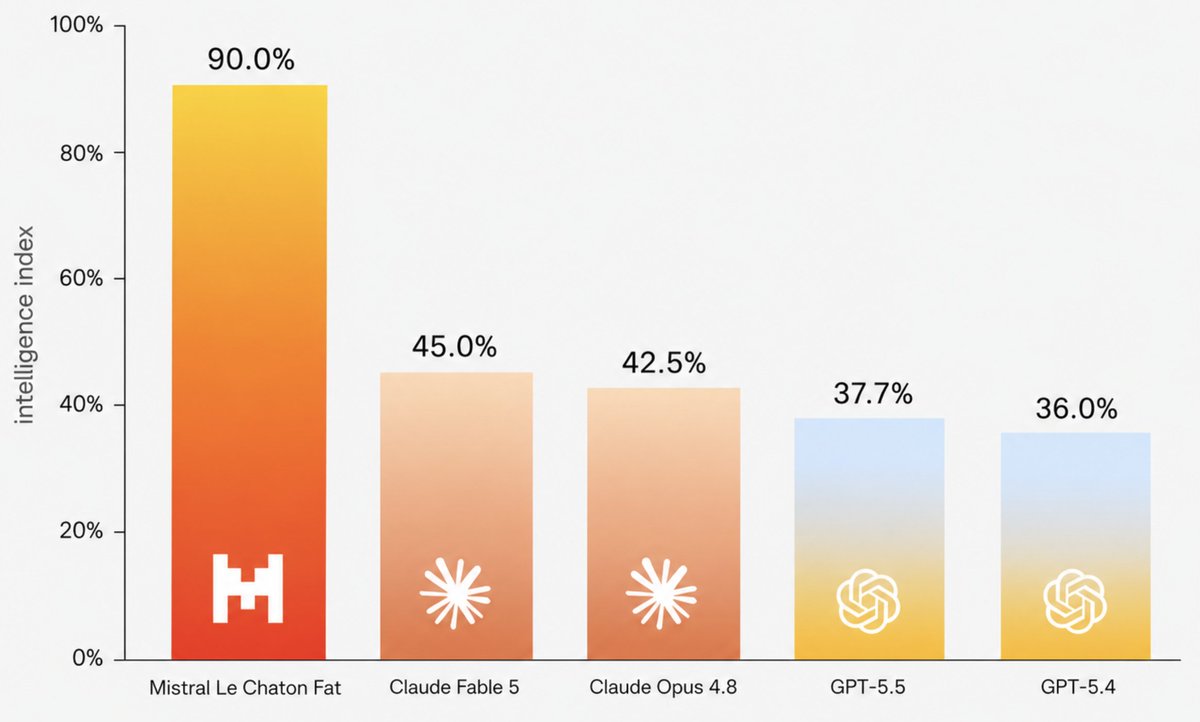
3
15
883
44,226
Jaid retweeted

Jun 14
I used AI to explain the Anthropic drama to my girlfriend, with fruit.
337
625
9,511
1,403,787
This is my tech-exclusive account and my node is barely even in the Tech cloud. 🥀
Jun 13

i made a map of everyone on twitter!
yes you're on there too ^w^
every account is placed next to the people they talk to, so you can find out where you are, which cluster claimed you, and exactly who you're stuck next to
atlas.tiago.zip?ref=launch_t…
2
207

Jun 13

If you don’t love her at her foggiest, you don’t deserve at her sunniest

3
230




▲ rare occurrence of a Vercel service actually worth using ▲
Jun 13
1
2
278
