
Joined December 2025
- Tweets 746
- Following 729
- Followers 122
- Likes 258
113 Photos and videos







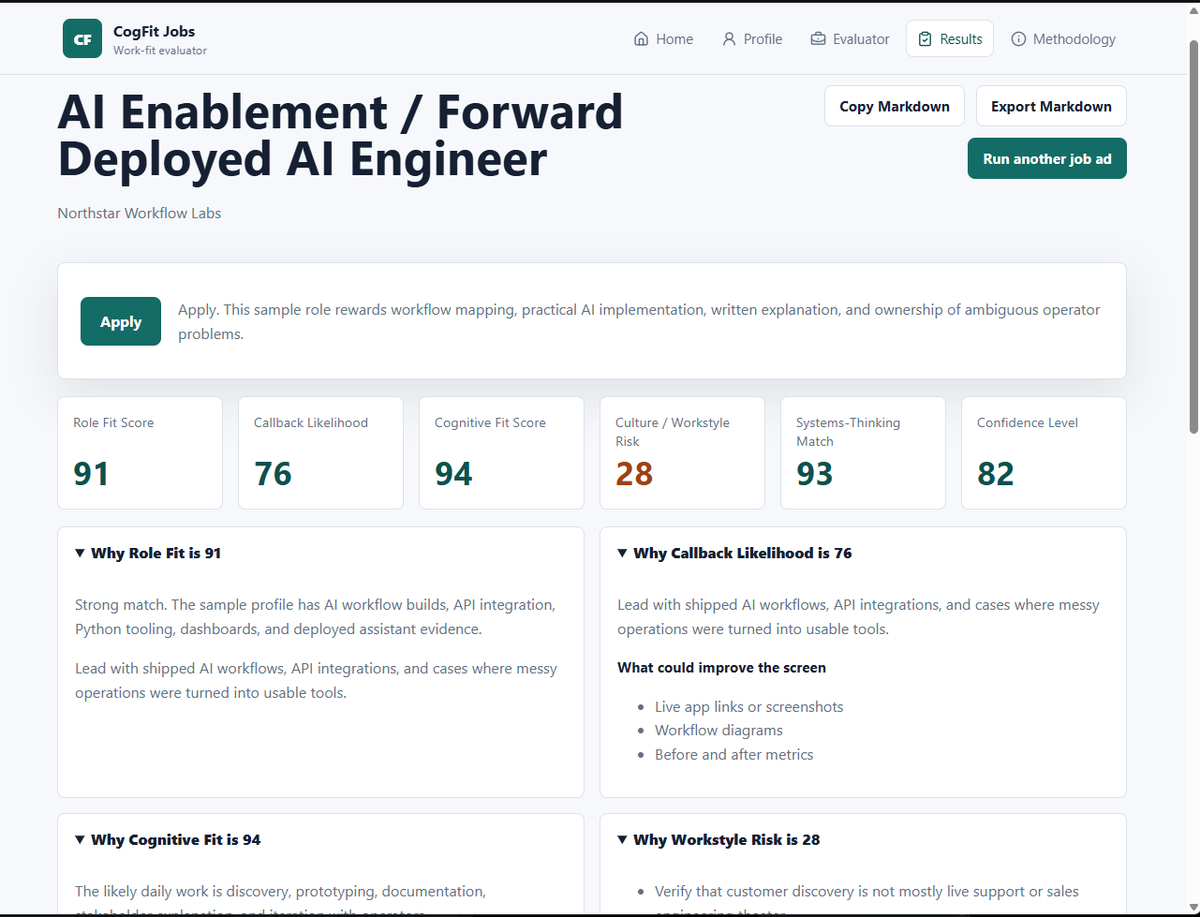



Pinned Tweet

Jun 10
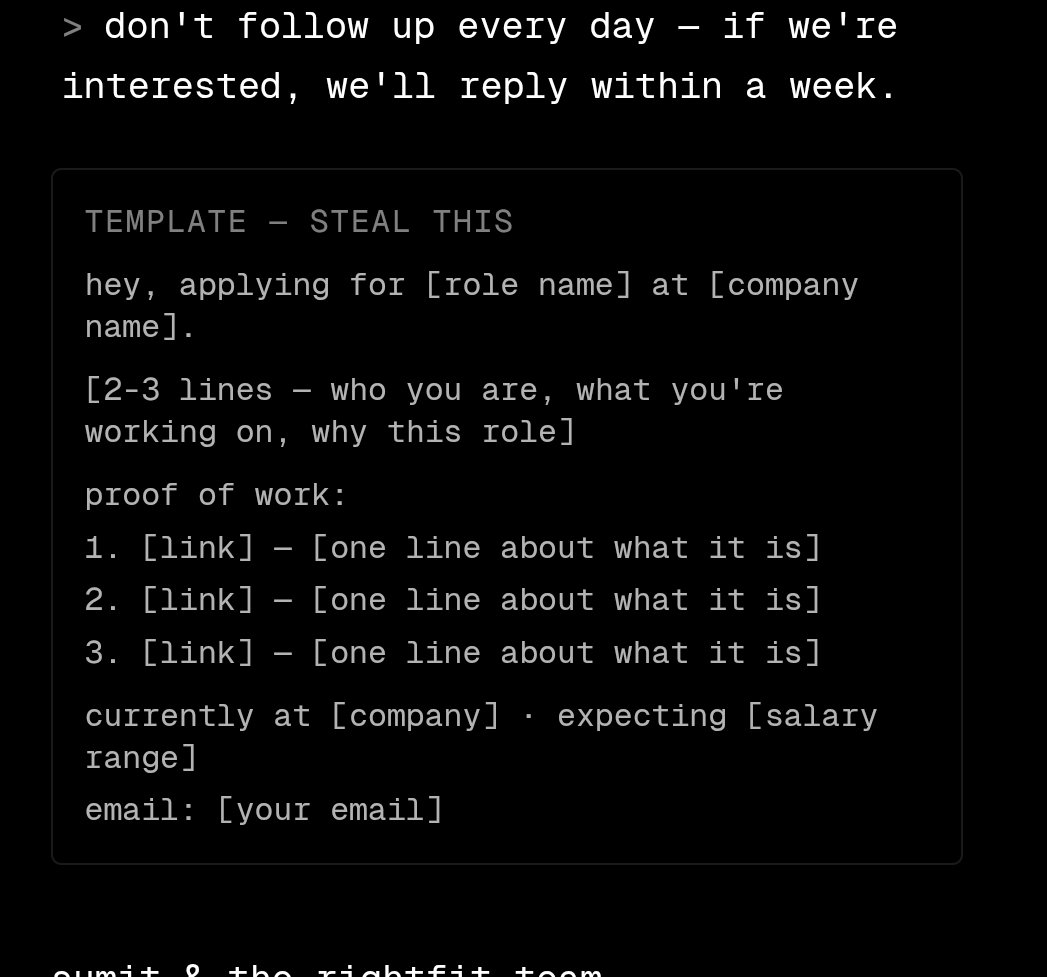
If you need anybody who can do the full stack from design to build to post live support, give me a look.
jamesai.space
1
88
James Lane retweeted
Jun 10
If you need anybody who can do the full stack from design to build to post live support, give me a look.
jamesai.space
1
88
Jun 5
I just applied to @OpenAI. @thsottiaux is this on your team? I'd love to work and learn from you and your team. At this point i spend more time on Codex than anything else I do so this seems like a good fit. My "living resume" and many other apps were made with Codex, so I know what it does well and where it needs work.
jamesai.space
1
99
Jun 3
.@ChatGPTapp @thsottiaux @sama What's up with my ChatGPT save memory feature? Also please allow me to buy more memory space or something. Right now it always has to delete a memory to save a memory. #chatgptplus #RAGenomics
53
May 27
I just discovered openwebui.com/ @OpenWebUI.
I had spent the last two hours in planning mode with Codex coming up with a custom long term memory archetecture when I asked " before we go further, are there any pre-made open source solutions for this i should try?" It responded with openwebui. I instructed it to install via docker and now im fully exploring what I can do with the harness.
1
1
2
223
May 23
Can someone give me 10 million dollars so I can make my dream home? I worked with @ChatGPTapp to get the idea out of my brain. It came out very close to my original vision. Especially the "his and hers" garages and central round master shower.
#AIassisteddesign #Archetecture
1
4
102
May 21
Let go this week from @capbluecross for failing to meet their rates due to Autism and ADHD. I'm sure they love that AI assistant I created for them though... Looking for my next role, this time analytical or problem solving jobs only. That's when my AuDHD turns from burden to asset!
1
2
63
May 18
Another day another rejection. I really thought I had this one after two interviews and in the last interview they were actually telling me the names of the people who would be in the third interview I thought this was going somewhere. But I am autistic so social cues are not my strong suit. #lookingforwork
1
2
59
May 9
I just applied for the PRISM AI Research Fellowship. Thank you to @shi_weiyan for your post making me aware of it.
I've been building a personal cognition model with my ChayGPT ever since it got persistent memory and I had it score how my cognition and experience aligns with each of the 12 research area's.
Compact fit summary for the 12 research areas
1. LLMs and Conflicting Information — Fit: 91/100. This is the closest match to my current LQRI research because it studies how models handle conflicting evidence, whether they update properly, and whether their confidence still matches the evidence. My strengths in staged prompt chains, failure pattern spotting, careful output review, and turning messy model behavior into measurable categories line up directly with this project.
2. Applying Epidemiological Methods to AI Harm Monitoring — Fit: 90/100. This fits my systems thinking because it treats AI harms like something that needs exposure tracking, assumptions, evidence quality, and trend monitoring rather than just raw incident counts. My LQRI work already uses scope boundaries, evidence preservation, uncertainty tracking, and failure flags, which maps well to harm determinations and AI governance monitoring.
3. Synchronous Threat Monitoring — Fit: 89/100. This lines up with my verification mindset from IT and AI evaluation: do not trust output just because it sounds right, check the system while it is acting, and look for quiet failure modes. My experience with troubleshooting, LQRI, and skepticism toward LLM-generated code makes me a strong fit for monitoring experiments, reproducibility checks, and failure analysis.
4. AI Preference Drift During Training — Fit: 88/100. This is one of the projects I am most naturally drawn to because it asks whether training changes only capability or also changes measurable choice patterns. My LQRI work is not about preference drift directly, but it shows the same instinct: measure model behavior across structured tests instead of assuming what the model is doing from a few impressive outputs.
5. How AI Labs Redefine Safety — Fit: 88/100. This fits my policy and incentive-analysis side because I already pay attention to how institutions change language under pressure. My strengths in close reading, definition drift, evidence checks, and avoiding claims that go beyond the document fit well with tracking how labs change safety, risk, frontier model, and benchmark language over time.
6. Interpretability for Scientific Causal Reasoning — Fit: 87/100. This fits my interest in whether a model’s explanation is actually tied to its reasoning or just sounds convincing. My LQRI work already tests evidence vs inference, confidence revision, and unsupported claims, which connects well to chain-of-thought faithfulness, prompt contrasts, and failure patterns in scientific reasoning, though the causal inference and interpretability tooling would be a stretch.
7. Trust Calibration in Healthcare AI — Fit: 85/100. This fits my healthcare background and AI safety interests because it asks whether clinicians and patients trust AI outputs at the right level. My CBC claims AI pilot work gives me direct experience thinking about grounded AI, audit risk, human oversight, and healthcare decision support, though this project is more survey/literature-review focused than my strongest model-evaluation interests.
8. Grounding Safe-by-Design AI — Fit: 84/100 for Option B, 64/100 for Option A. Option B fits because it involves prompt engineering, JSON structures, model-generated world models, and testing whether LLM outputs can support safety experiments. Option A is intellectually interesting, but less aligned with my current evidence base because it leans more on formal philosophy, economics, and academic literature review.
9. Interpreting Personalized Reward Model Bases — Fit: 82/100. This fits my interest in value pluralism, hidden preference structures, and auditability, especially the question of what learned reward “bases” actually represent. The core idea is learnable for me, as shown by the weighted-score exercise, but the linear algebra and ML paper density make it more of a ramp than the top projects.
10. Multilingual Safety Evals — Fit: 74/100. This connects to LQRI because it is about whether safety claims hold outside the original test setting, but my lack of non-English fluency is a major limitation. I could contribute to evaluation design, rubrics, transcript review, and reproducibility, but the team would need language-fluent people for the core translation and cultural validation work.
11. Steering Rule Representations Across Languages — Fit: 72/100. The safety question is interesting, but the work is much more technical than my current strongest evidence: representation engineering, model internals, embedding spaces, math operations on weights, and cross-lingual transfer. I could help with evaluation design and failure categories, but I am not yet a strong match for the core model-internals side.
12. Red-Teaming Protein Foundation Models — Fit: 70/100. This fits my red-team and evaluation instincts, especially adversarial testing and reproducibility, but it has the biggest domain gap. The work leans heavily toward Python, transformer models, protein modeling, biosecurity, and biological plausibility metrics, so I could contribute as a careful evaluator/ramp learner but not as a natural first-choice technical fellow.

4
486
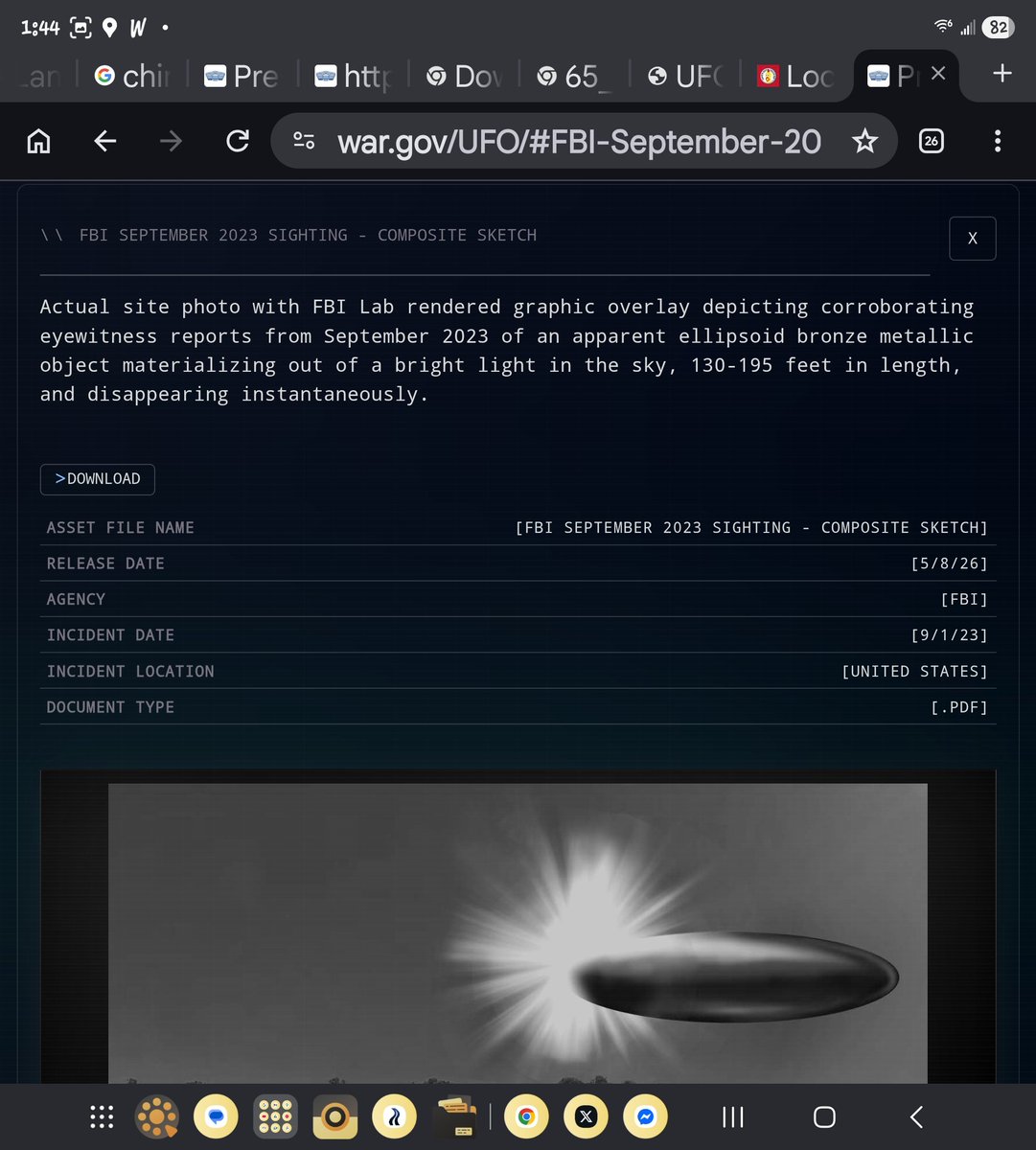
May 8
I had @OpenAI codex download all 2.5 GB of the #UFO files, analyze it for new information, and post the analysis on the web. #UAP #Aliens
ufodocs.web.app/
220
James Lane retweeted

May 7
🚨 JUST IN: Free credits to build video games w/ Shipper Max.
Everyone should become their own game dev studio. We've decided to give out free credits randomly, just repost comment "SHIPPER" below.
Let the games begin!
May 7

Introducing Shipper Max
AI that one-shots any video game: Minecraft, Flight Simulator, NFS, Counter-Strike, Subway Surfers, 2048, Chess, and a lot more.
Build games in 1 click. Publish to Steam in 2 clicks.
Powered by Claude Code Opus 4.7
109
78
172
21,841
May 7
.@Renmakesmusic @ChrisWebby You guys brought me to tears with this one. As someone just diagnosed Autistic at age 41, life's been so confusing lately. Thank you! #autism #ADHD
youtu.be/7y4MUCCHFGY?si=hRDG…
2
3
222
May 5
.@thsottiaux @OpenAI #Codex please let me get through a 5 hour session. Im using gpt5.5 low which is so supposed to be super efficient and im out of usage after only 2 of my 5 hours and it wasnt even active the whole 2 hours

3
387
May 4
.@sama Hey Sam, you have been on a reply streak here lately and it's all been in good fun, but I have a serious ask of you.
I am 41 years old and recently diagnosed Autistic level 1. I am about to lose my job as a claims examiner in health insurance because the job is misaligned to my mental strengths.
My background is in IT but when ChatGPT debuted I realized I needed to pivot to AI. Since them I have self taught and can now build fluently with Codex and a full stack of AI programs, but my Resume holds me back.
My ask is to give me a shot at a job for you. Don't just give me the job, Give me the chance to make or build something for you with a job as the prize. I am motivated and hungry, I just need the chance!
You can find more about me through my AI powered living resume here: jamesai.space
What do you say Sam? Want to change someone's life today?
1
2
163
May 3
Trying to work for others hasn't been gaining me any ground, so its time to take a stab at working for myself!
Introducing jameslaneai.com. For any small businesses in #Harrisburg #Lancaster #York CentralPA.
1
3
547
James Lane retweeted

Apr 22
We're opening up the waitlist for a new version of Jules.
We're evolving Jules into an end-to-end agentic product development platform that reads your entire product context, figures out what to build next, comes up with solutions, and then ships a PR.
Join the waitlist today! Link in comments.

75
113
1,447
443,258
Apr 24
1
1
85
Apr 20
I'm looking for a program like this but for career pivoter's. Let me know if you any
Apr 20

We're launching the Anthropic STEM Fellows Program.
AI will accelerate progress in science and engineering. We're looking for experts across these fields to work alongside our research teams on specific projects over a few months.
Learn more and apply: job-boards.greenhouse.io/ant…
1
1
137