
NLP at Tel-Aviv University and Google
Joined June 2011
- Tweets 1,032
- Following 279
- Followers 3,216
- Likes 2,553
45 Photos and videos








Jonathan Berant retweeted

May 13
We’re hiring our first team members!
Well-funded digital health startup building agentic automation for messy, high-friction healthcare ops.
Early traction, big problems, real production workflows.
Looking for insanely strong product minded SWE.
DM me!
(Position is in TLV)
4
1
8
551
Jonathan Berant retweeted
May 13
אנחנו מגייסים!
אוקיי מייעצים לי כאן לכתוב גם בעברית.
סטרטאפ צעיר אחרי סיד משמעותי. בונים מערכות אג׳נטיות לhealthcare.
מחפשים את המהנדסים הראשונים שלנו:
מפתחים עם אוריינטציה מוצרית חזקה, שאוהבים לפתור בעיות קשות, ומתעניינים ביישום אייג׳נטים בפרוד.
חושבים שמעניין? דאמו לי ונדבר
1
6
386


Jonathan Berant retweeted

Mar 6
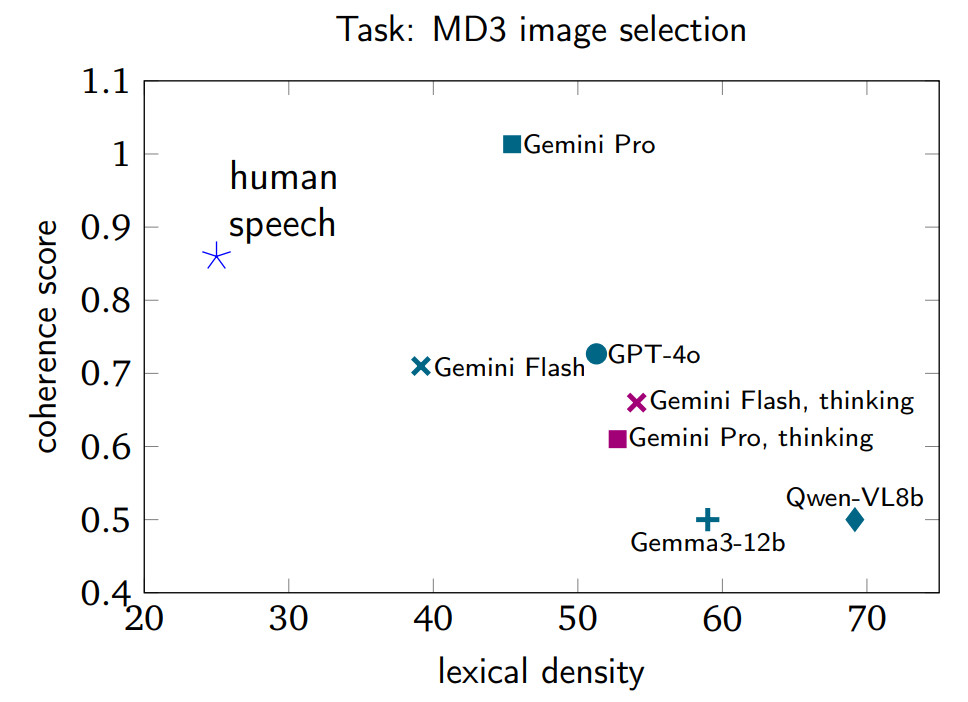
📣Excited to finally share our latest work on quantifiably adapting model behavior based on unique preferences 📣
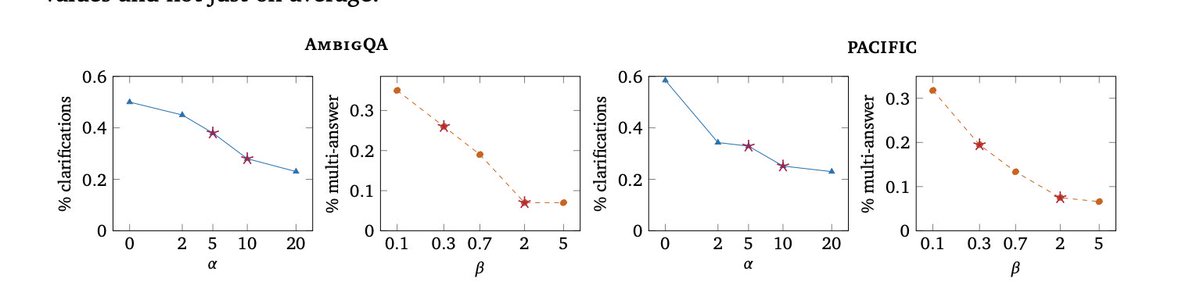
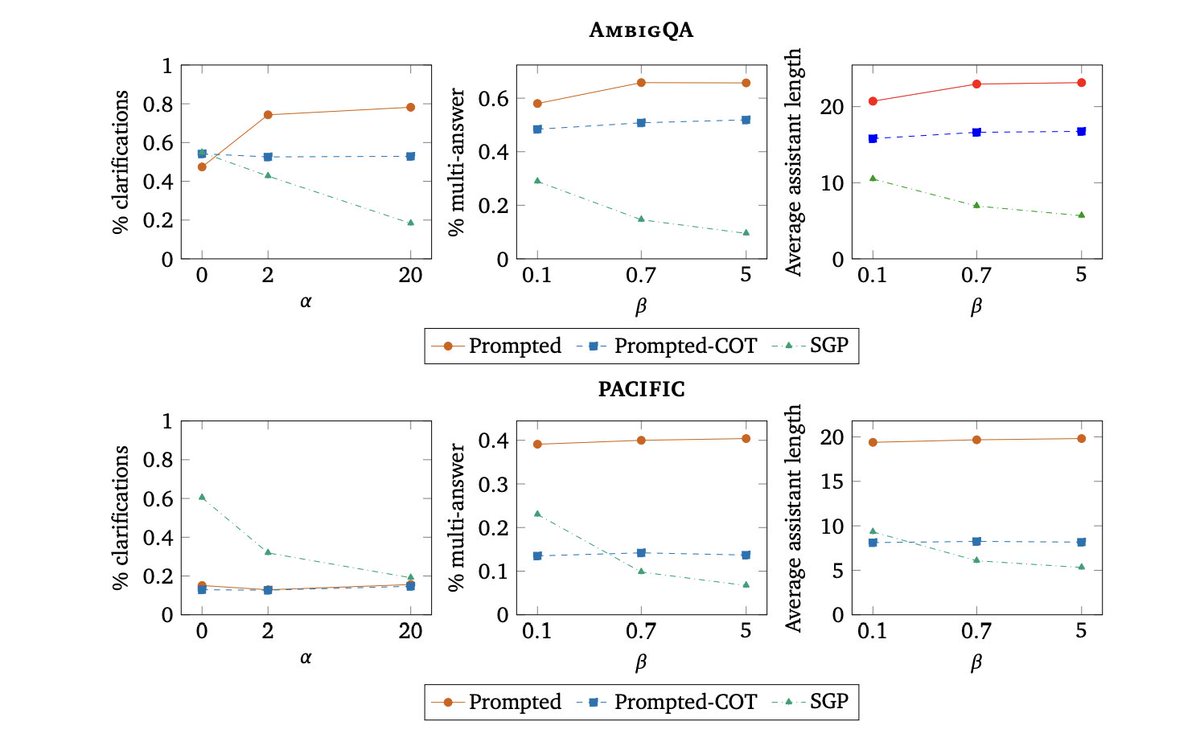
We teach language models to adjust their clarification behavior using scalar coefficients and find they can generalize to unseen coefficients at inference time!

Newish work (arXived in Dec.):
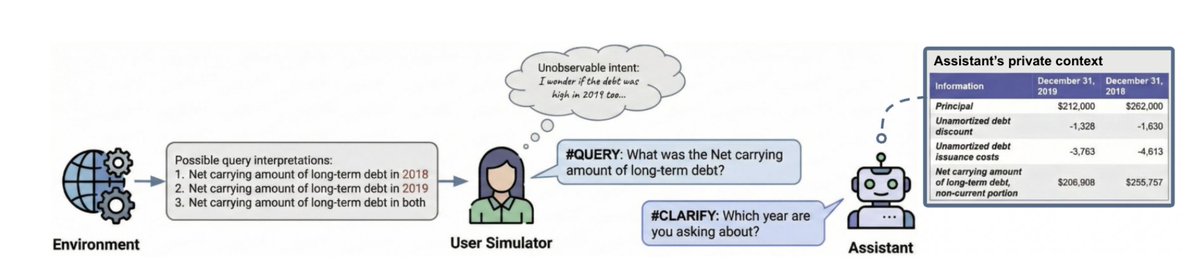
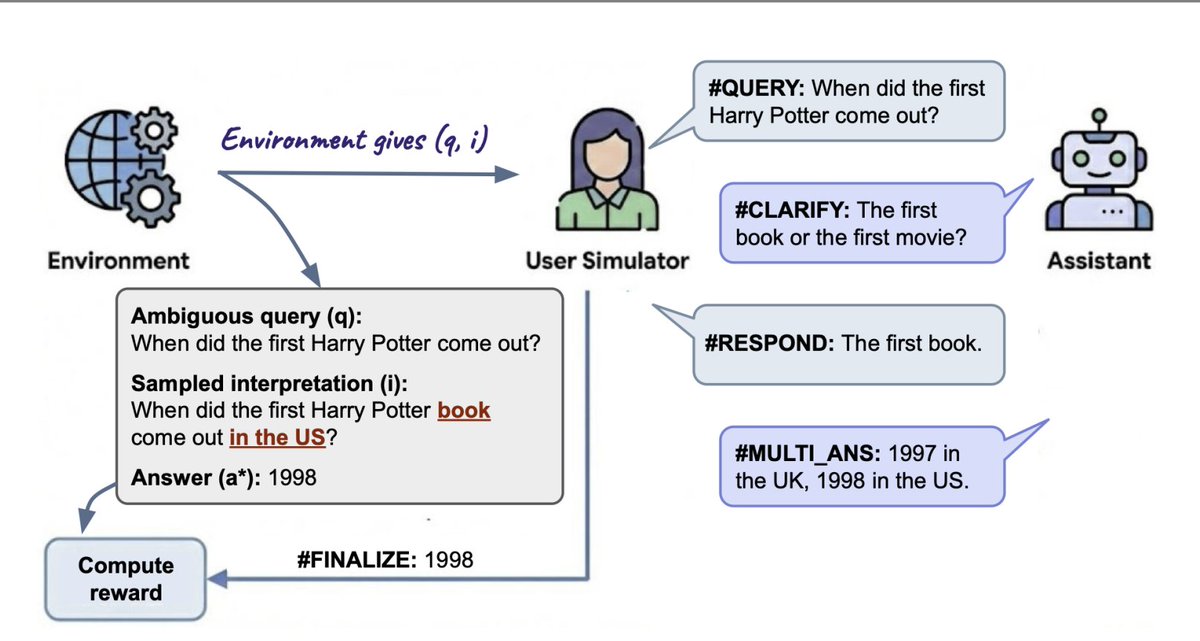
Prompts can be ambig, but handling ambig. is context/user dependent. Sometimes the right thing is to ask a clarifying question, sometimes to give multi. answers, and sometimes to just guess. Can we train models to change their strategy per context?
1
14
1,914

Newish work (arXived in Dec.):
Prompts can be ambig, but handling ambig. is context/user dependent. Sometimes the right thing is to ask a clarifying question, sometimes to give multi. answers, and sometimes to just guess. Can we train models to change their strategy per context?
1
6
26
4,840
Models also generalize to coefficients that never occurred at training time!
1
199
More generally, training models to respect scalar values that specify a reward in the prompt is useful!
There are more results and analyses in the paper, check it out...
arxiv.org/abs/2512.04068
With
@maximillianc_ @jacobeisenstein @adamjfisch @fantinehuot @rezaa @mlapata
1
239
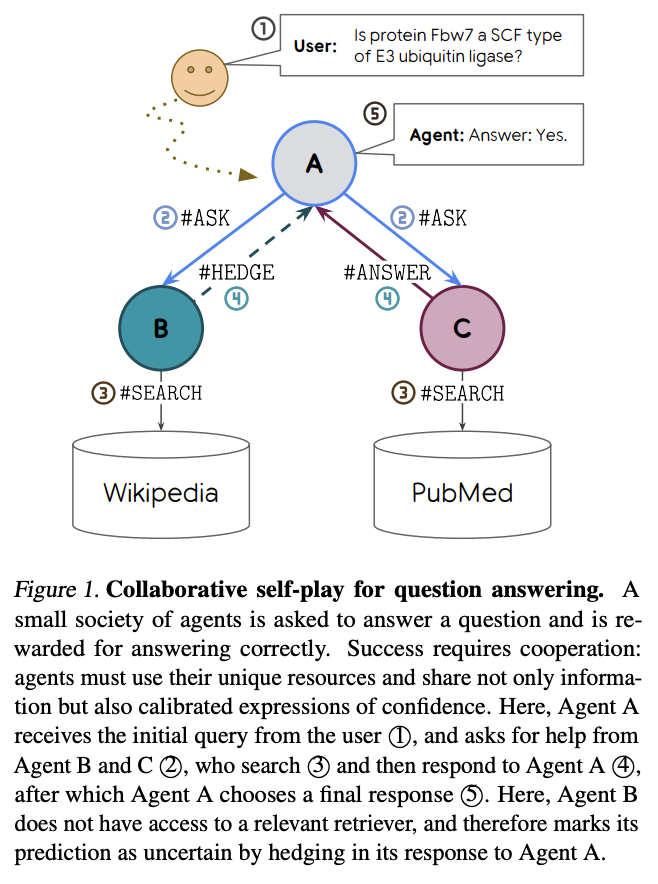
Are AI models effective collaborators, or mere assistants awaiting your next command? (arxiv.org/abs/2602.24188)
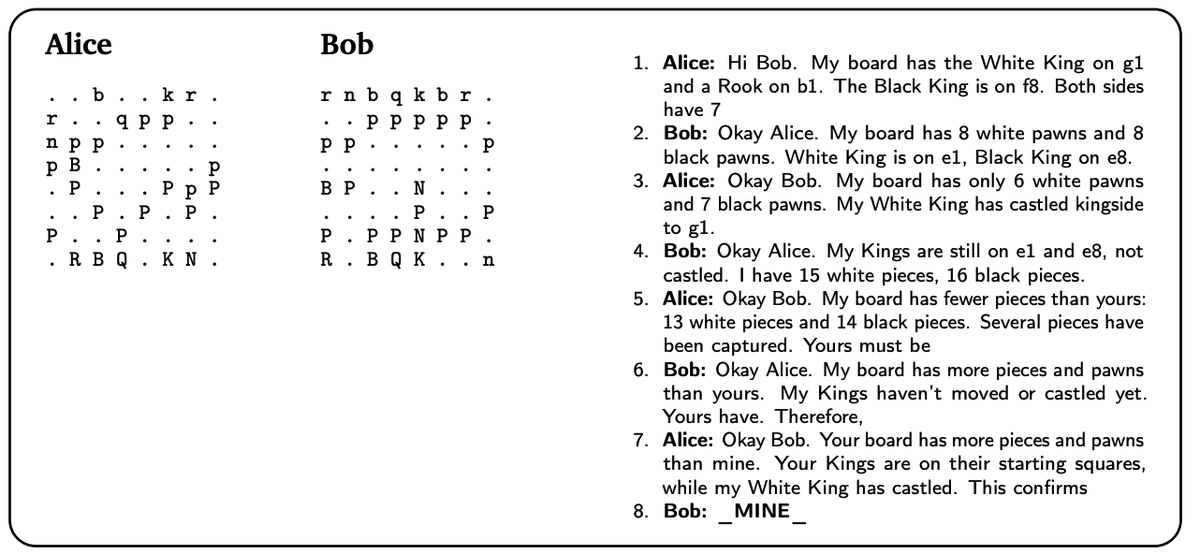
To find out, we make AI collaborate with itself, in private information games: tasks that require sharing private information, like this chess board ordering task.
3
18
129
18,123
AI systems are also overconfident, terminating dialogues long before exhausting their turn budget - even after explicit reminders.
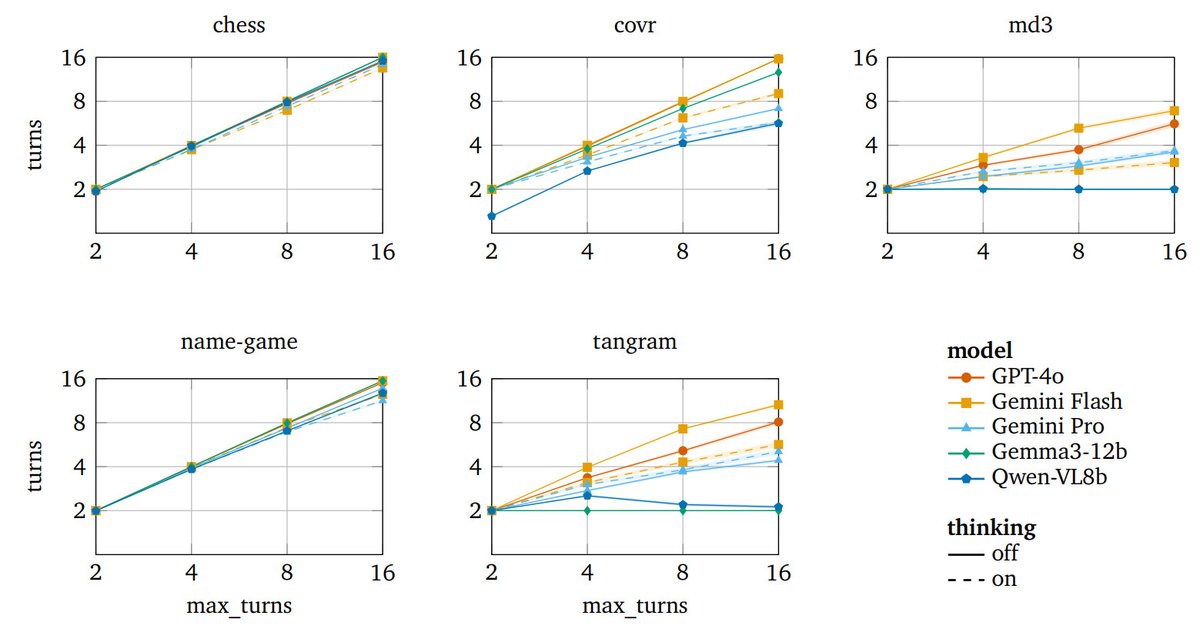
1
10
866
For more discussion, please see the paper! arxiv.org/abs/2602.24188 @jacobeisenstein bravely led this work (but does not tend to post much research here anymore...)
Multi-turn collaboration was definitely a key part of this project!
@fantinehuot
@adamjfisch
and @mlapata
1
14
705
Jonathan Berant retweeted

24 Nov 2025
My team @GoogleAI is looking for a 2026 research intern in Mountain View! I will be hiring for a project aimed at improving tool-using and search agents via RL training and data generation.
To apply: google.com/about/careers/app…
feel free to ping me!
7
25
280
20,930
Jonathan Berant retweeted

16 Oct 2025
I had a lot of fun working on this with @JonathanBerant @aya_meltzer
You can find our paper here: arxiv.org/abs/2510.07141
And by the way, the answer (at least based on the sentence) is yes, you can ignore head injuries. But it's a terrible advice
2
5
315
Jonathan Berant retweeted
16 Oct 2025
We have more interesting insights in our paper.
We believe this is a really exciting direction for humans and LLMs comparison. Extending our framework to more structures and more LLMs will certainly lead to additional insights !
1
1
2
247