
Joined October 2025
- Tweets 83
- Following 23
- Followers 71
- Likes 284
32 Photos and videos




Pinned Tweet

15 Dec 2025
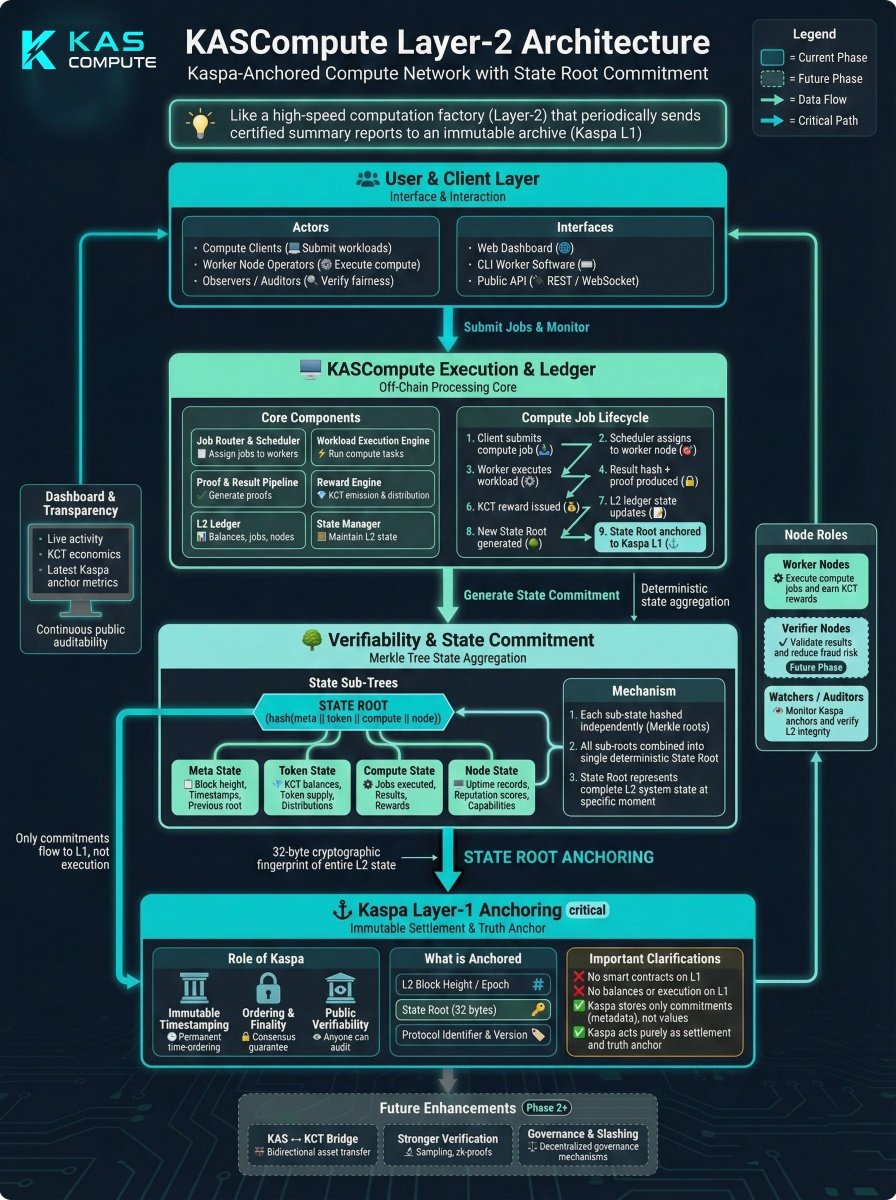
This diagram shows the core architecture of KASCompute — an off-chain compute network anchored to Kaspa Layer-1.
• Real workloads are executed by distributed worker nodes
• Results, rewards, and network state are aggregated into a deterministic state root
• The state root is periodically anchored to Kaspa for finality and public auditability
Huge thanks to @CyberVisualizer (Kaspa Visualizer) for the excellent visualization.
5
17
1,141

Today there is a bigger update because there are 3 new PRs that are ready for review.
The first one (github.com/kaspanet/vprogs/p…) fixes some bugs and introduces the SchedulerState which unifies the way we expose shared state in our framework.
The second one (github.com/kaspanet/vprogs/p…) introduces the node-framework which builds on top of the first PR and introduces a generic platform for building L2 nodes that ingest data from the Kaspa L1 to produce state changes (and eventually proofs) of the L2-execution.
The third one (github.com/kaspanet/vprogs/p…) introduces the node-vprogs-cli - an actual binary that can be executed and that follows the L1 to execute transactions in a concrete VM.
The binary is designed to support compile-time modularity, which means that by updating a single line in the backend.rs we can swap out both, the storage and the VM.
A VM is defined by three functions:
1. A pre_process_block function which extracts the relevant L2 transactions from the L1 chainblock.
2. A process_transaction function which executes a single transaction (within its scope) and produces execution-results.
3. A post_process_block function which takes the execution results of the individual transactions and stitches them together into an aggegrated proof structure which can be settled on the L1.
All steps are parallelized as much as the underlying causal structure permits.
I still have a few chores on my todo-list and there are still a few missing parts (like syncing from state that we didn't actively witness) but this is pretty much as far as we get without re-integrating with the covenants on L1, so the next steps will be to actually design the concrete framework for settling state transitions on the L1 (and consequently syncing from it).
I suspect that this will require a little bit of back and forth between the two development efforts but we are getting to the point where things start to get interesting.
41
202
611
60,132
Feb 14
KASCompute Launcher v2.1.1 is out ⚡️
New Testnet release with a major step forward in rewards accounting transparency.
What’s new in v2.1.1:
🧾 Mining rewards (KCT) tracking is now integrated
📚 Reward ledger for transparent, auditable payouts (per block / per participant)
🧩 Cleaner Node vs Miner separation clearer operator view
📡 Live job flow visibility (distribution → proofs) via logs/telemetry
If you want to test a real verifiable compute network, this release makes it much easier to measure performance and track rewards end-to-end.
Download: dashboard.kascompute.org/
Feedback & bug reports welcome.
#Kaspa #KASCompute #Compute #Infrastructure #DePIN #Testnet
1
3
115
Feb 5
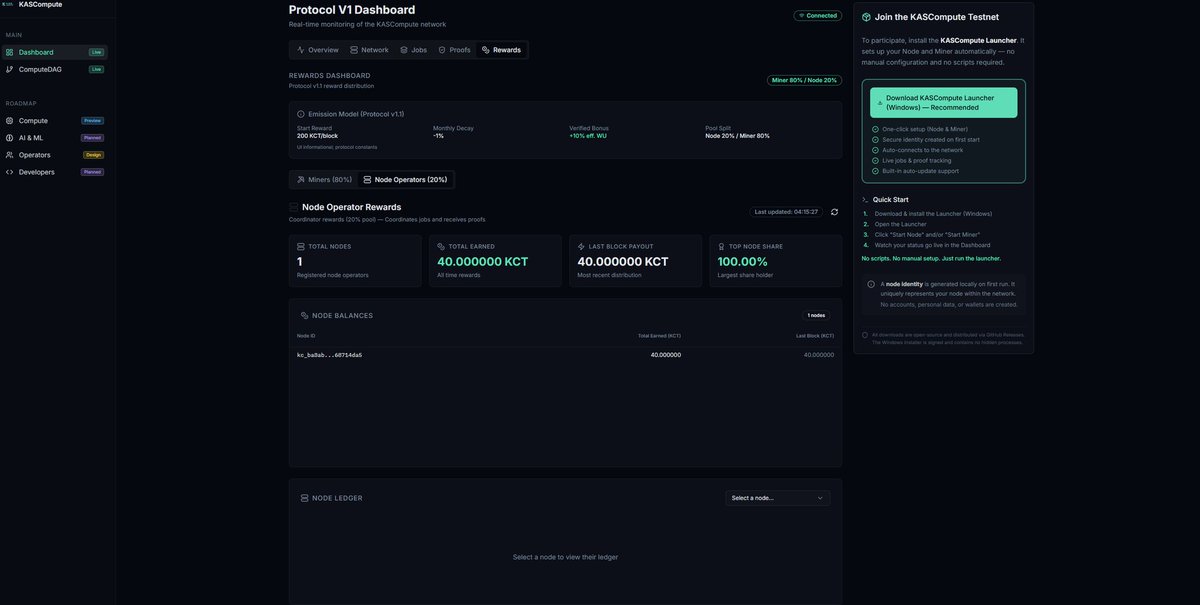
KASCompute Testnet update ⚡️ (Protocol v1.1)
✅ Rewards Dashboard is LIVE
— Emission model: 200 KCT / block, -1% monthly decay
— Pool split: Miner 80% / Node Operator 20%
— Verified bonus: 10% effective WU (signature verified)
— Live balances last block payout
— Full ledger history (per-block entries with share compute units reason)
✅ Proof-of-Compute telemetry is now visible end-to-end
— Nodes lease/assign jobs and receive proofs
— Miners execute deterministic workloads and submit signed proofs
— Node logs now show “proof received” events (miner_id WU elapsed) instead of just heartbeat spam
— Miner UI shows recent proofs signatures WU/sec last job
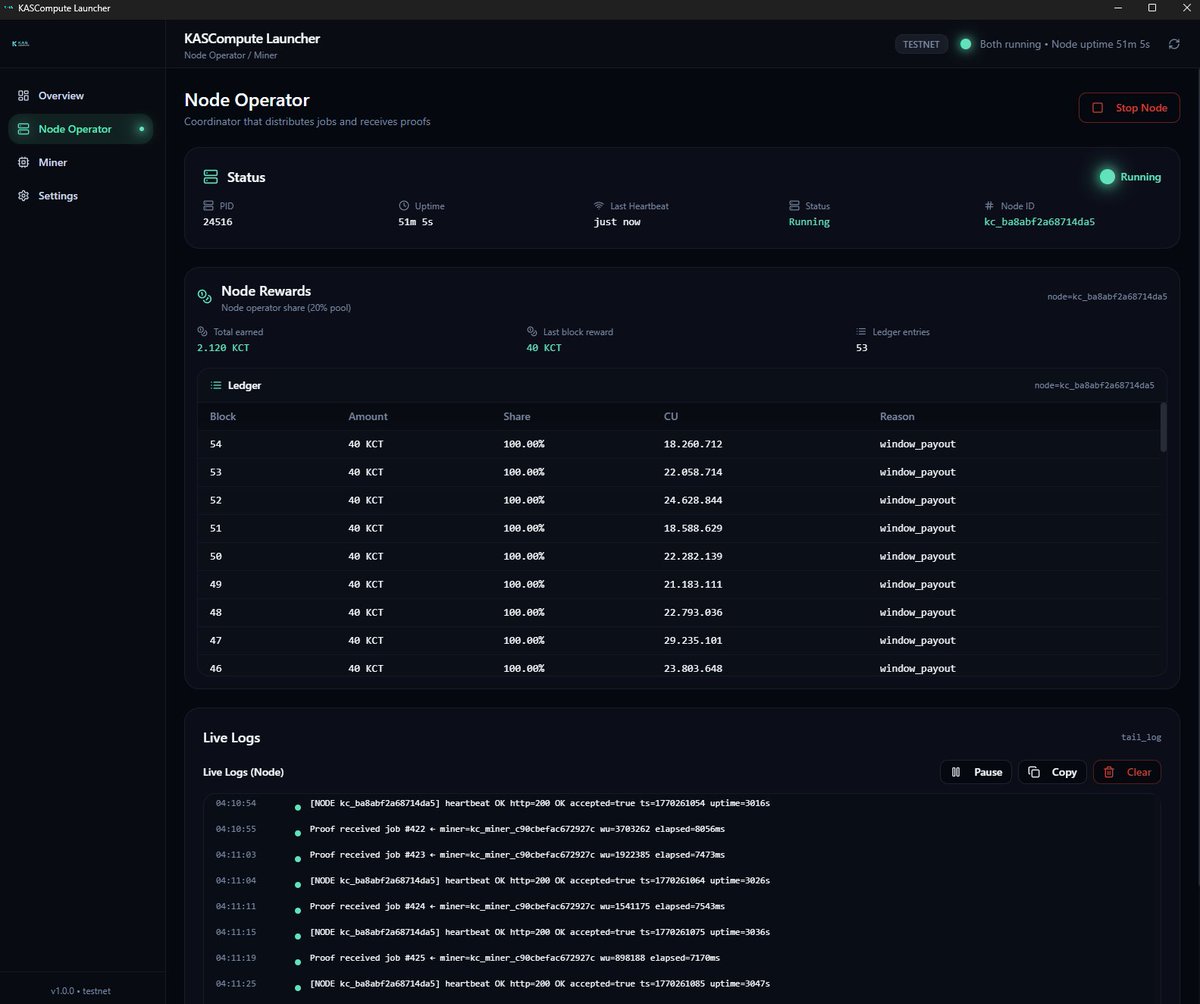
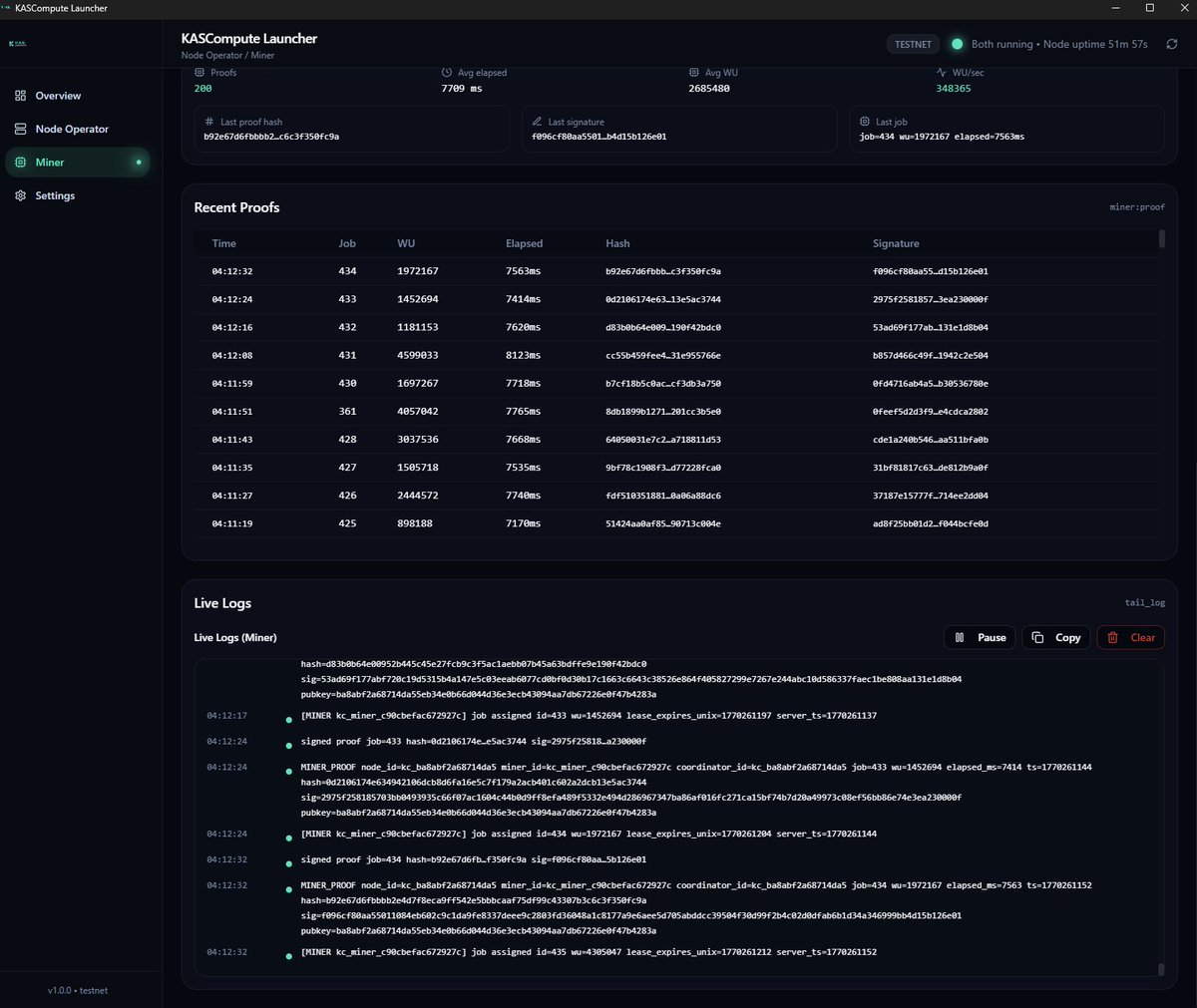
MASSIVE Launcher upgrade
Node Operator & Miner are now clearly separated with their own status, rewards, ledgers, and live logs.
New Launcher build will be online in the next days.
Screenshots below 👇

1
1
3
114
Feb 2
KASCompute — Full Project Update (Feb 2026)
Dashboard Launcher download: dashboard.kascompute.org
I want to share a complete, human, no-hype update on where KASCompute stands today — because progress should be measured in shipped software, not promises.
There is no whitepaper yet, and that’s intentional. Not because I’m hiding anything, but because right now the best use of my time is building the actual system: protocols, clients, telemetry, and the boring-but-essential work that makes infrastructure real. KASCompute is mostly powered by my own time and effort at the moment. I’m not backed by a large team or a huge budget — just a builder mindset, long nights, and a long-term plan.
Why I’m building this
I’ve seen too many “networks” that are mostly narratives. KASCompute is my attempt to do the opposite: build something you can actually run, measure, and verify. I want a system where “compute” isn’t just assumed — it’s observable, paced, and tied to real behavior. If KASCompute succeeds, it won’t be because of marketing. It will be because it works.
What KASCompute is (in one sentence)
KASCompute is decentralized compute infrastructure: nodes coordinate deterministic jobs, miners execute them, and the protocol records verifiable results plus performance telemetry — designed to be honest about what it can do today and strong enough to grow into real infrastructure.
What it is NOT
• Not a “promise of infinite GPU” tomorrow.
• Not a hype-driven AI token story.
• Not a whitepaper-first project.
It’s a build-first infrastructure experiment that’s evolving into a production-grade system.
────────────────────────────────────
1) Where we are TODAY (what already works)
────────────────────────────────────
KASCompute is already running as an end-to-end pipeline:
Node heartbeat → job assignment → compute execution → proof submission → network telemetry/stats
This isn’t a concept demo. It’s a working protocol stack you can test and observe.
Working components (current reality):
• Protocol v1 is live deployed (I’m actively iterating; current work is on release/v1.1.1).
• Node Miner run end-to-end: nodes come online, miners request work, jobs execute, proofs are submitted, and metrics update.
• ComputeDAG is implemented: jobs are structured and traceable — not treated like “black boxes”.
• Launcher Dashboard are usable with live protocol data (network state, activity, and visibility into the system).
• Rewards are being finalized: especially clear separation between roles (Node Operator vs Miner), plus leaderboard/sidecards/rewards UI clarity.
What this means in practice:
If you download the launcher and connect, you can actually see the network behavior: online presence, activity pacing, proof submissions, and the system responding in real time. That matters, because infrastructure only becomes real when people can run it and observe it.
Key principles already in the system:
• Determinism first (prioritizing jobs that can be verified and compared)
• Transparency over “trust me” (telemetry and stats are part of the protocol flow)
• Practical pacing (real networks have latency, dropouts, imperfect uptime — the protocol needs to reflect that reality)
• Clean role separation (node operator vs miner are different roles with different responsibilities and metrics)
────────────────────────────────────
2) What I’m doing RIGHT NOW (the serious work)
────────────────────────────────────
A system can “run” and still be far from mainnet. Mainnet readiness is mostly about hardening: preventing abuse, handling edge cases, and building operational reliability.
My current focus is the unglamorous but essential work:
(1) Rewards Ledger hardening
Rewards aren’t just numbers — they’re the foundation of trust. I’m finalizing:
• clear reward rules and calculations
• role clarity (Node Operator vs Miner) in UI data
• stable history/ledger behavior and edge cases
• protections against manipulation (replay/spam patterns)
• consistent pacing so rewards reflect real participation, not request frequency
• “boring correctness” over flashy numbers
(2) Security abuse protection
Open networks attract weird behavior. So the protocol needs to handle:
• rate limiting and basic DoS resistance
• replay protection and signature validation
• strict input validation and sane failure modes
• anti-spam measures to keep the system usable under pressure
The goal is not “perfect security” overnight — it’s layered hardening and clear, testable assumptions.
(3) Reliability operations (“real infra”)
Production infrastructure means the system must be observable and recoverable:
• better metrics/logging/tracing so issues are diagnosable
• recovery strategy (what happens when jobs fail, services restart, or clients disconnect)
• protocol/client versioning so older clients degrade gracefully instead of breaking
• operational clarity so the network can evolve without chaos
These parts are less glamorous, but they’re what separates a demo from real infrastructure.
(4) Developer experience & clarity
If people can’t understand how to run it, they won’t test it. So I’m improving:
• documentation that explains how the system behaves (not marketing)
• clearer UI labels and role separation
• consistent terminology so builders don’t get confused
────────────────────────────────────
3) What’s planned NEXT (near-term roadmap)
────────────────────────────────────
I’m keeping the roadmap simple and accountable. The next milestones are:
A) Finalize Rewards v1
• stable ledger deterministic accounting
• clean role separation everywhere (API UI)
• basic anti-cheat / abuse-resistant scoring
• clarity in leaderboards and rewards views
B) Protocol hardening
• improved validation, signatures, replay defenses
• rate limits safety rails
• better error semantics so clients can behave correctly
• more test coverage around the critical flows
C) Testnet reliability improvements
• clearer telemetry and dashboards
• client upgrade/version policy
• stronger operational monitoring
• improved pacing so the network “feels” stable to users
These are the milestones that move KASCompute from “it runs” to “it can survive real users”.
────────────────────────────────────
4) What’s planned LATER (only after v1 is stable)
────────────────────────────────────
I want to be direct: I’m not rushing into “AI network marketing” or promising GPU magic tomorrow.
After v1 is stable and hardened, then it makes sense to expand into:
• a more extensible job framework (standardized job types/workloads)
• more complex deterministic compute tasks
• eventually AI/rendering/batch workloads — but only when verification incentives operations are ready
• optional deeper ecosystem anchoring once the security/ops baseline is proven
Growth should come from a strong base, not from hype cycles.
────────────────────────────────────
5) Mainnet readiness (honest percentage)
────────────────────────────────────
If I define “mainnet-ready” as: secure enough, abuse-resistant, incentive-safe, operationally observable, upgradeable, and reliable under real usage…
Then today I’m around: ~55–65% mainnet-ready.
Why not higher?
Because mainnet isn’t “it compiles” or “it works on my machine.” Mainnet means:
• incentives must be hard to exploit
• abuse/spam must be controlled
• failures must be handled predictably
• monitoring and recovery must exist
• versioning must be stable
This is the difference between a prototype and infrastructure.
The good news: we are past the idea phase. We are in the hardening phase — and that’s exactly where real projects get built.
────────────────────────────────────
6) Rough timing for mainnet (milestone-based, no hype)
────────────────────────────────────
I won’t post a fake date just to sound confident. Instead:
• Mainnet Beta (early adopters) becomes realistic once Rewards Security Ops are stable enough for real usage.
→ If testing and feedback go well: months, not years.
• Production-grade mainnet typically requires multiple real test phases, because real usage finds issues you can’t predict.
→ Often 6–12 months after beta, depending on usage and feedback volume.
If the community tests hard and gives feedback, this timeline becomes faster and more realistic.
────────────────────────────────────
7) What I need from the community (practical help)
────────────────────────────────────
If you want to support KASCompute, the most valuable help is practical:
• Download test the launcher (download is on the dashboard).
• Share feedback (UX, stability, logs). Even “small” issues help.
• Report bugs / feature requests.
• If you’re a builder/team with a real batch-compute use case: reach out. I want real workloads and real feedback.
Dashboard Download: dashboard.kascompute.org
I’ll keep building this the same way: step by step, measurable releases, no empty promises. ⚡️
1
1
89
Jan 30
Thanks for having me on the community X Space today 🙌
I explained how KASCompute works end-to-end: nodes, miners, job flow, proofs/receipts, and ComputeDAG — plus a quick v1.1 update.
Recording: x.com/i/status/2017310834163…
Feedback from builders/devs is welcome ⚡️
@LevendiPro @Chris_Hutch7

3
4
339
Jan 28
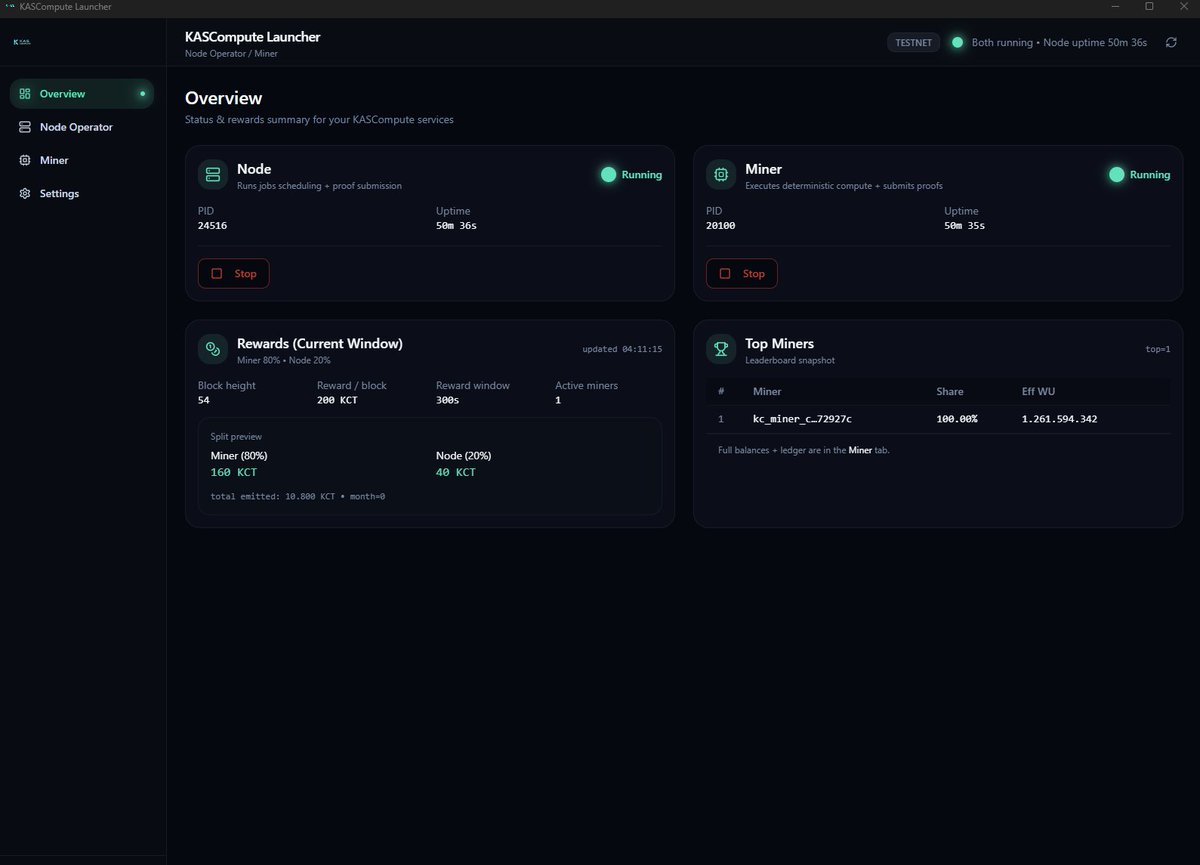
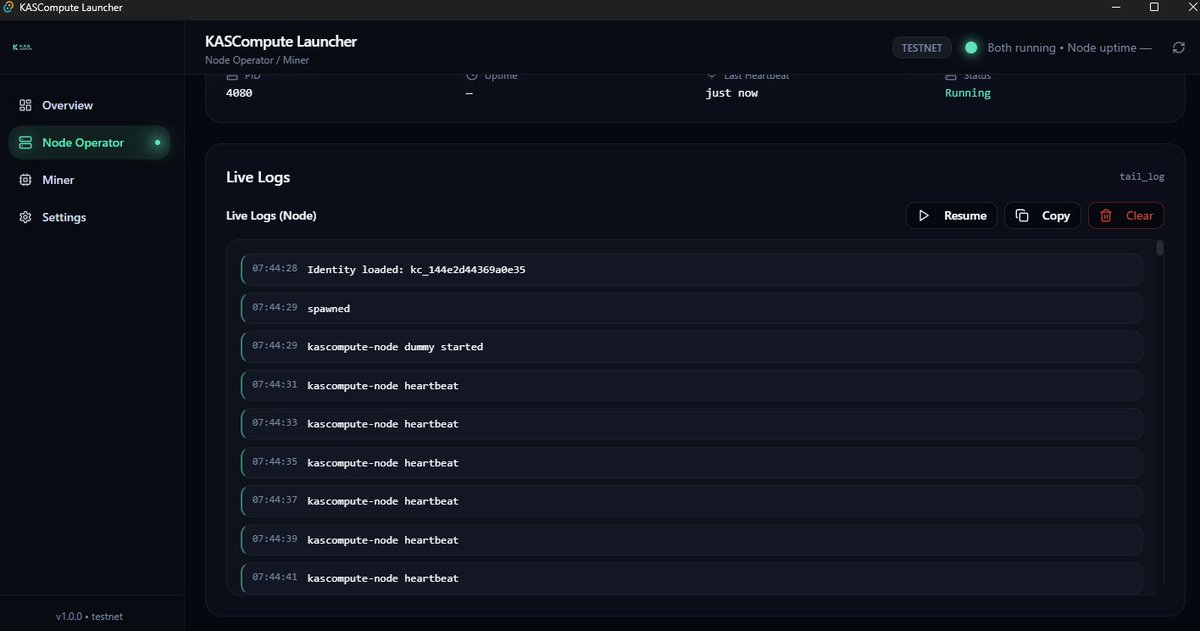
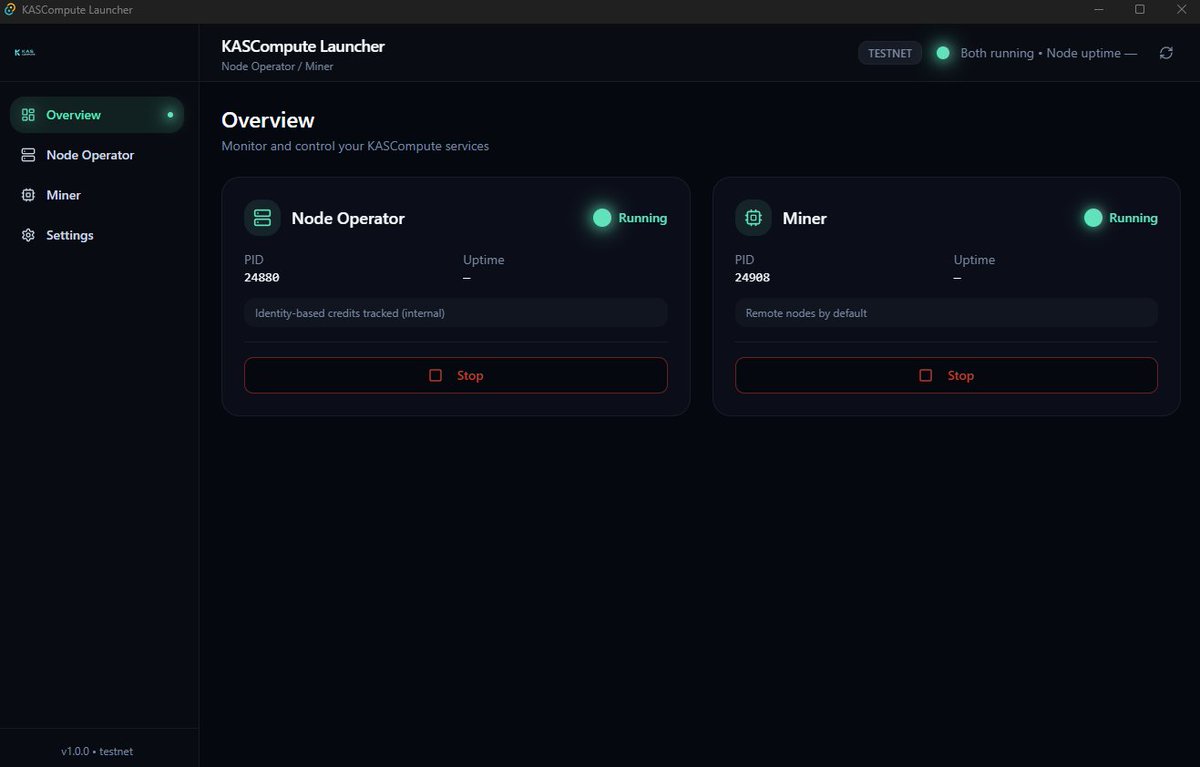
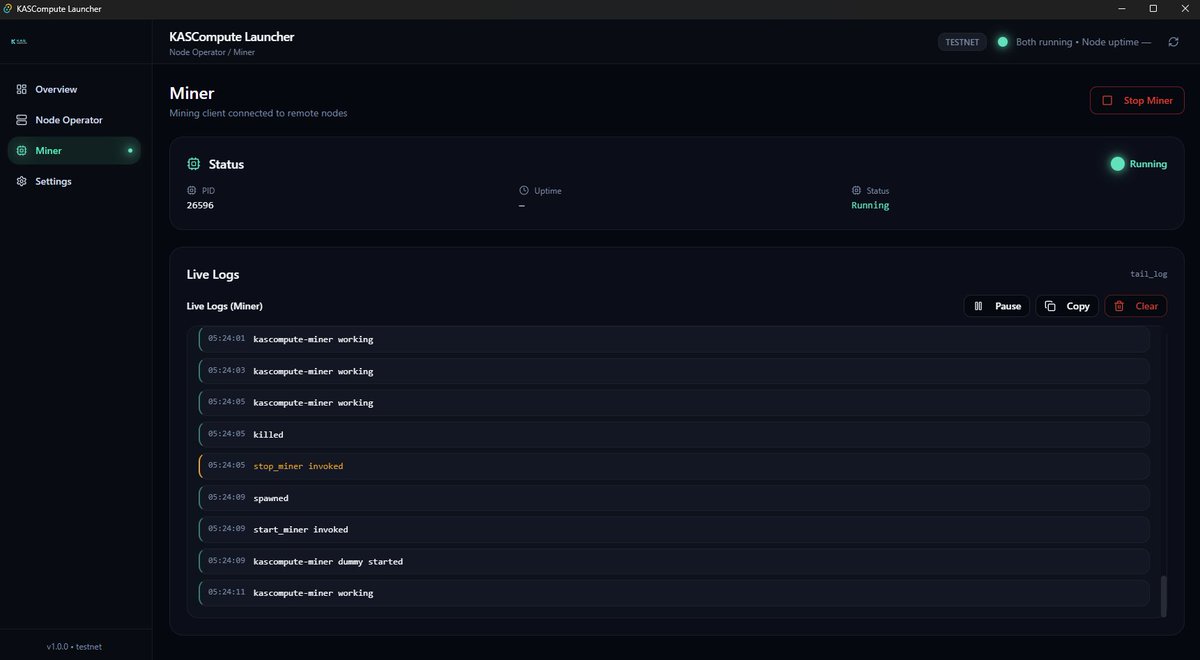
KASCompute Launcher Dashboard got a MASSIVE upgrade.
This is my biggest Testnet milestone so far: Node Miner, Proof-of-Compute telemetry, Geo presence, clean UI, and realistic pacing — all running end-to-end. ⚡️
✅ Node Miner now run as independent sidecar processes (stable / production-style)
No more “mixed loops” — clean process lifecycle, better reliability, better restarts.
✅ Miner Proof pipeline is fully restored
miner:proof events are live again and the UI stats are correct & consistent.
Proof stats now include the full set:
proofs count
avg elapsed (ms)
avg work units (WU)
WU/sec throughput
last job id
last proof hash
last signature
recent proofs table (time/job/WU/elapsed/hash/signature)
✅ Geo presence works
Nodes show up with location enrichment presence tracking — the network view finally feels “real”.
✅ Pacing fixed (no more rattling / spam)
Realistic scheduling, proper idle backoff, and stable polling intervals.
✅ Restart Supervisor Unified Logs
Auto-restart with restart-limit protection clean UI log streaming (stdout/stderr/events).
And yes: Compute DAG is implemented — jobs are no longer treated as black boxes.
This is the foundation for proper compute accounting, fairness, and future upgrades.
Download the Testnet Launcher from the GitHub Releases page or from the project site.
If you want to support: ⭐️ the repo, test it, and drop feedback.
Next steps: hardening, more metrics, and pushing towards mainnet-grade reliability.
Kaspa ecosystem infrastructure is catching up — and KASCompute is building the compute layer.
kascompute.org
#Kaspa #KASCompute #ProofOfCompute #ComputeDAG #Web3 #Infrastructure
1
3
2
191
Jan 24
Milestone reached: Compute DAG is now implemented and part of Protocol v1.
KASCompute no longer treats jobs as black boxes.
Compute is structured as a DAG of dependent steps, enabling partial verification, better scheduling, and realistic workloads — without forcing compute on-chain.
walkthrough below 👇
#Kaspa #Compute
1
1
110
Jan 18
Just submitted KASCompute to the Kaspathon.
It’s an infra-first Proof-of-Compute project, focused on verifiable execution, clear protocol boundaries, and long-term scalability for decentralized compute.
If you want to support serious infrastructure work, an upvote helps a lot. 💚
dorahacks.io/buidl/38365
5
10
427
Jan 16
KASCompute — Dev Update (Testnet)
Over the last days I’ve been heavily extending the KASCompute Launcher.
The launcher is not released yet — I’m still finishing a few critical parts before it goes public.
What’s new:
• Persistent Node Identity (Ed25519)
Each installation now generates a stable cryptographic identity
(node_id keypair), used across heartbeats, proofs and future settlement.
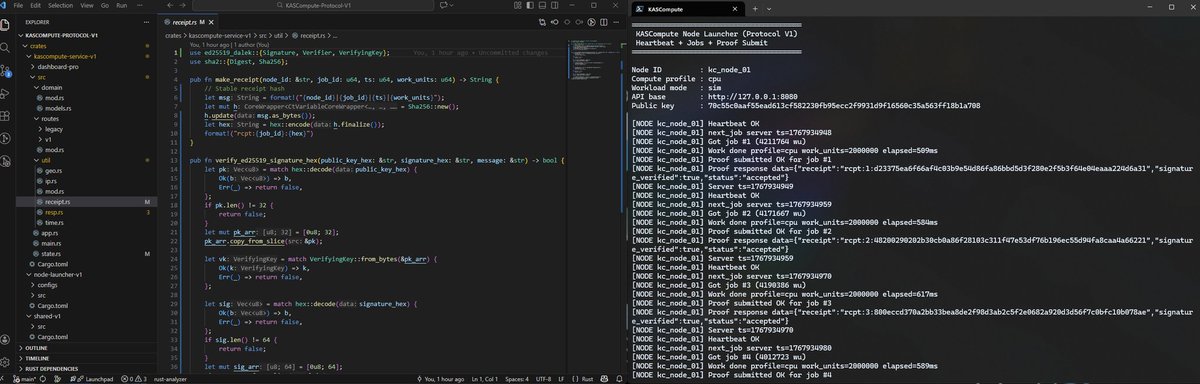
• Protocol V1 – Proof-of-Compute (off-chain)
The miner now produces deterministic, verifiable proofs: – canonical JSON payload
– sha256 (payload)
– ed25519 (signature(hash))
– public key for verification
Proofs are signed locally, submitted to the backend, and visualized live in the launcher.
• Real Miner Statistics in the UI
– Proof counter
– Average elapsed time
– Average work units
– WU/sec throughput
– Last proof hash & signature
– Scrollable Recent Proofs table (live feed)
• Single Source of Truth for Heartbeats
Node status in the UI is derived only from real node heartbeats
(no frontend polling tricks, no fake state).
• Tauri Sidecar Architecture
Node and miner run as managed sidecars
→ restart-safe, versioned, mainnet-ready by design.
Status:
Protocol V1: active
Cryptography: implemented
Settlement: off-chain
vProgs alignment: prepared
The launcher will go public only once everything is stable and clean.
More updates soon.
⚡🟢

1
2
108
Jan 14
Execution is easy.
Verification is hard.
KASCompute is designed around the hard part.
Full explanation (6 min):
1
2
89
Jan 12
I just published a new Explained page for KASCompute.
It walks through: • what the system actually is
• how nodes, miners, proofs and receipts work together
• what runs on the network today
• and what kinds of workloads (including AI) are possible later — without breaking verifiability
No hype. No promises. Just the system as it exists and where it can go.
kascompute.org/explained
2
3
103
Jan 11
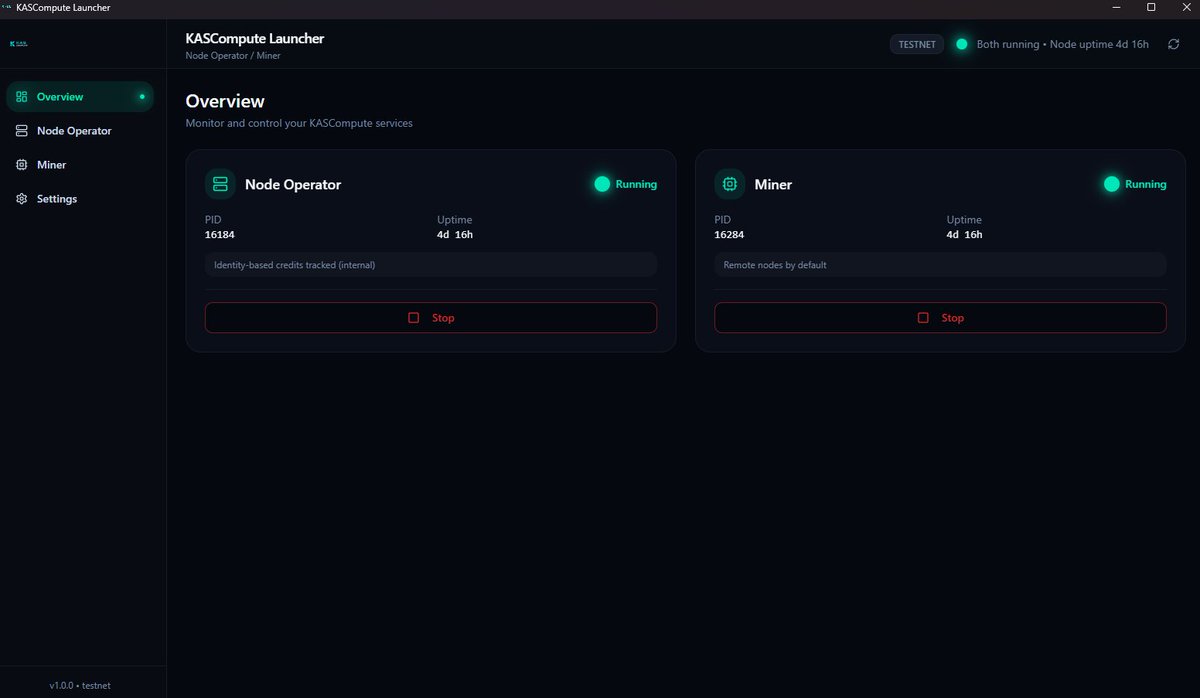
Status update: 4 days 16 hours uptime for Node Operator Miner (Launcher).
Zero crashes. Persistent processes, clean lifecycle management.
Next: hardening the execution → proof → receipt loop.
#RustLang #ProtocolEngineering #Kaspa #KASCompute
2
1
2
171
Jan 9
Protocol v1 — work in progress.
Receipts, signatures, and verification aren’t features —
they’re the backbone.
KASCompute Protocol v1 is about tightening the execution → proof → receipt loop until it’s boringly deterministic.
Still refining. Still building.
⚡
#Kaspa #ProofOfCompute #ProtocolEngineering #DecentralizedCompute #RustLang
1
1
93
Jan 7
KASCompute Launcher v0.2.1 is live.
A signed Windows launcher to run a KASCompute node and/or miner with zero manual setup.
No scripts.
No config files.
No background magic.
What the launcher does:
• Manages node & miner lifecycle
• Generates identity locally on first run
• Tracks uptime, logs & status
• Automatically reconnects & recovers
• Built-in update support
👉Download (always latest):
github.com/KASCompute/kascom…
Once running, you can monitor everything live via the dashboard:👉 dashboard.kascompute.org
(status, uptime, logs, heartbeat)
This is testnet.
Tokens and rewards have no real-world value.
Stability first.
Transparency always.
— KASCompute
#Kaspa #KASCompute #Testnet #BlockDAG #DecentralizedCompute #OpenSource
@kaspaunchained
1
1
1
75
Jan 5
KASCompute Protocol v1 is live on Testnet.
Protocol v1 defines the stable core of the network, including job execution and Proof-of-Compute verification.
Spec:
github.com/KASCompute/kascom…
47
Jan 5
🧠 KASCompute – Dev Update (Testnet)
Status: End-to-end Proof-of-Compute flow is live.
Over the last days I connected the KASCompute Launcher (Tauri) directly to the testnet backend and implemented the full compute lifecycle end to end.
✅ What’s live now
Launcher (Node Miner)
Native Tauri desktop app
Sidecar-based Node & Miner processes
Persistent Ed25519 identity per installation (kc_…)
Heartbeat & Presence
Periodic heartbeats from the launcher
Automatic geo enrichment on the backend
Explicit role signaling (node | miner | both)
Job Scheduling
/jobs/next assignment per node
Dynamic work units
Fairness-ready per-node accounting (foundation in place)
Mining / Compute Loop
Launcher-internal miner loop
Simulated workload (workload_mode: sim)
Measured execution time (elapsed_ms), work units, client version
Proof Submission
/jobs/proof with full metadata
Backend verification
Deterministic receipt per proof
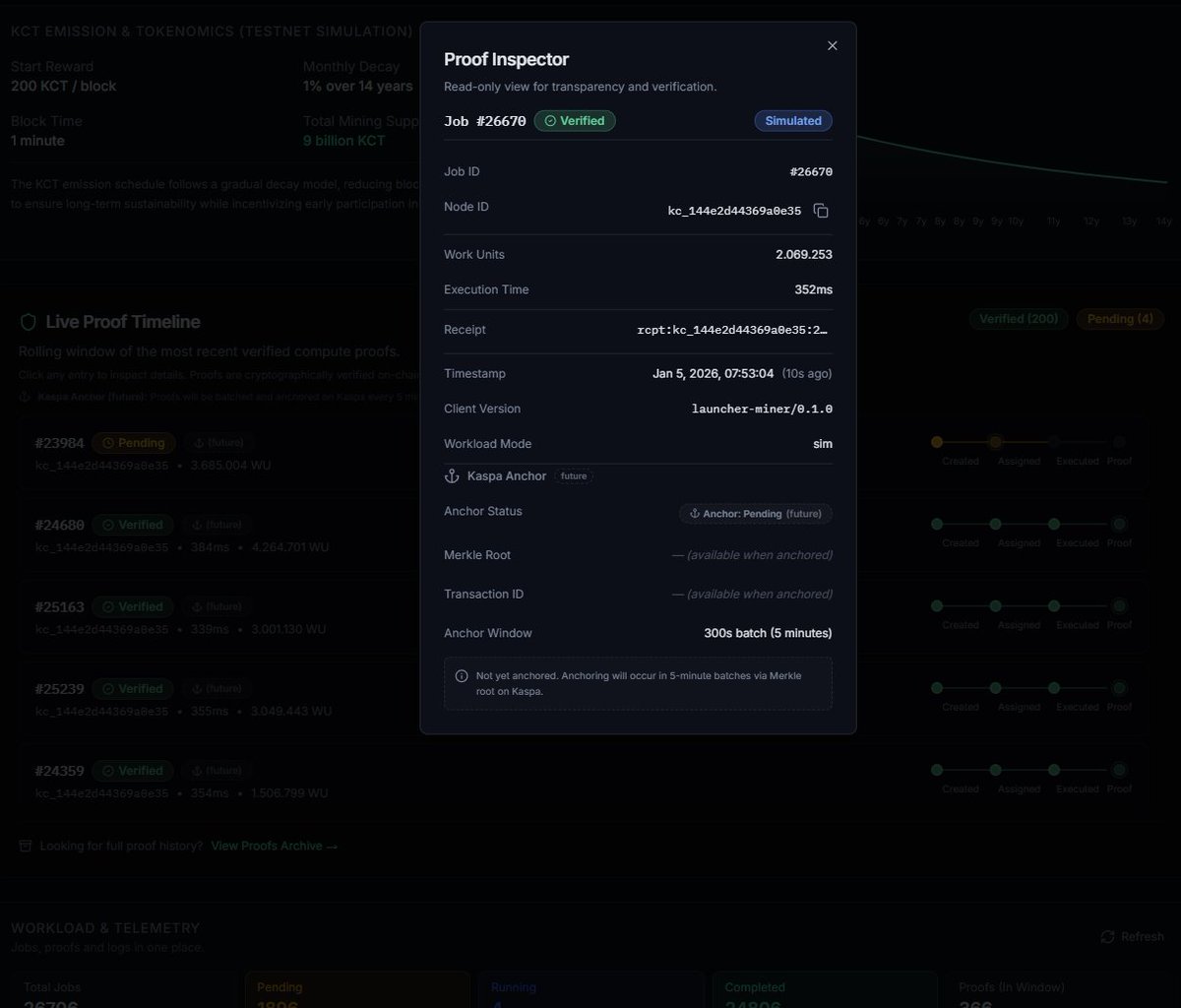
Audit & Transparency
Read-only Proof Inspector
Full traceability: Job → Node → Proof
Leaderboard & mining stats already wired
Kaspa Anchoring (Future-Ready)
300s batch window
Merkle root aggregation prepared
Anchor status already visible in proof UI
---
🧩 Architectural intent
This is not traditional mining
and not “fake compute”.
Goal: a verifiable compute layer with:
deterministic proofs
auditable job execution
future on-chain finality via Kaspa anchoring
Everything currently runs off-chain by design, keeping the system:
testnet-safe
mainnet-ready
vProg-compatible
---
🛠️ Current focus
Stabilizing Launcher ↔ Backend APIs
Hardening heartbeat, job, and proof contracts
Preparing real workloads (CPU / hash first, GPU later)
No hype.
No token talk.
Just shipping infra.
---
🔜 Next steps
Replace simulated work with real compute workloads
Difficulty & reward weighting
Merkle batch visibility
Kaspa anchor finalization
If you’re building in the Kaspa ecosystem and want to review or challenge the design, feedback is welcome.
DMs open.
#Kaspa #KASCompute #ProofOfCompute #DecentralizedCompute #BlockDAG #DevUpdate #Infrastructure

1
1
2
133
Jan 4
KASCompute Launcher – Progress Update
Today I finalized the local KASCompute Launcher:
• Start/Stop control for Node & Miner
• Real process management (no mocks)
• Live status tracking
• Live logs & heartbeat events inside the UI
Next up:
→ Full API integration with the KASCompute backend
→ Nodes sending real heartbeats
→ Miners working against the network
→ Dashboard powered by real data
This is about building real infrastructure, step by step.
More updates coming soon.
#KASCompute #Kaspa #BuildInPublic #DecentralizedCompute

1
1
55
31 Dec 2025
Happy New Year to everyone
A new year begins.
Not with noise. Not with hype.
But with intention.
We’re still early.
A small group. A few dozen people who decided to look closer instead of scrolling past.
And that matters.
Every project starts this way
with curiosity, patience, and belief before momentum exists.
2025 was about laying foundations quietly.
2026 is about proving that consistency beats scale.
To everyone who followed, tested, read, or simply stayed:
thank you for being early.
The journey is just getting started.
— KASCompute 💚
1
2
53
29 Dec 2025
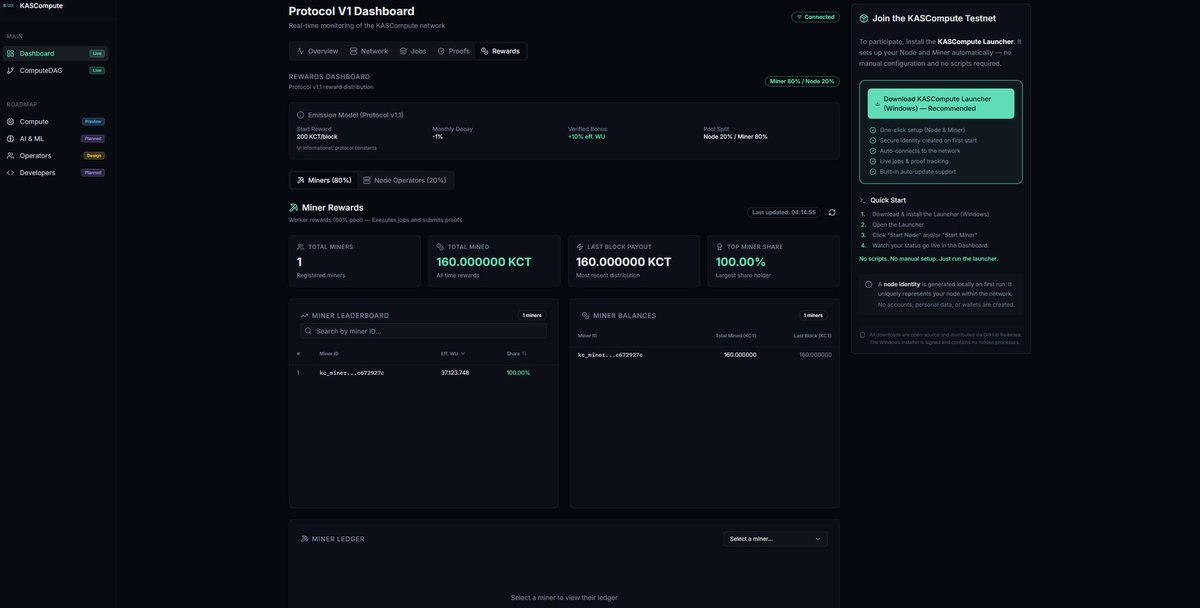
The KASCompute testnet just received a full UI overhaul.
• Clean, proof-first layout
• Live network state in real time
• Clear separation between live activity and historical data
• Metrics scoped by time windows — no misleading totals
• Built around verification, not hype
This dashboard isn’t about promises.
It shows what the network is actually doing — right now.
dashboard.kascompute.org
#KASCompute #Kaspa #Testnet #VerifiableCompute #ProofOfCompute #NewUI
3
4
85