
PhD student @Penn @berkeley_ai working on controllable creative generation. Previously @MIT CS undergrad 🤺 research intern @Meta @Adobe.
Joined February 2021
- Tweets 22
- Following 1,116
- Followers 245
- Likes 112
8 Photos and videos
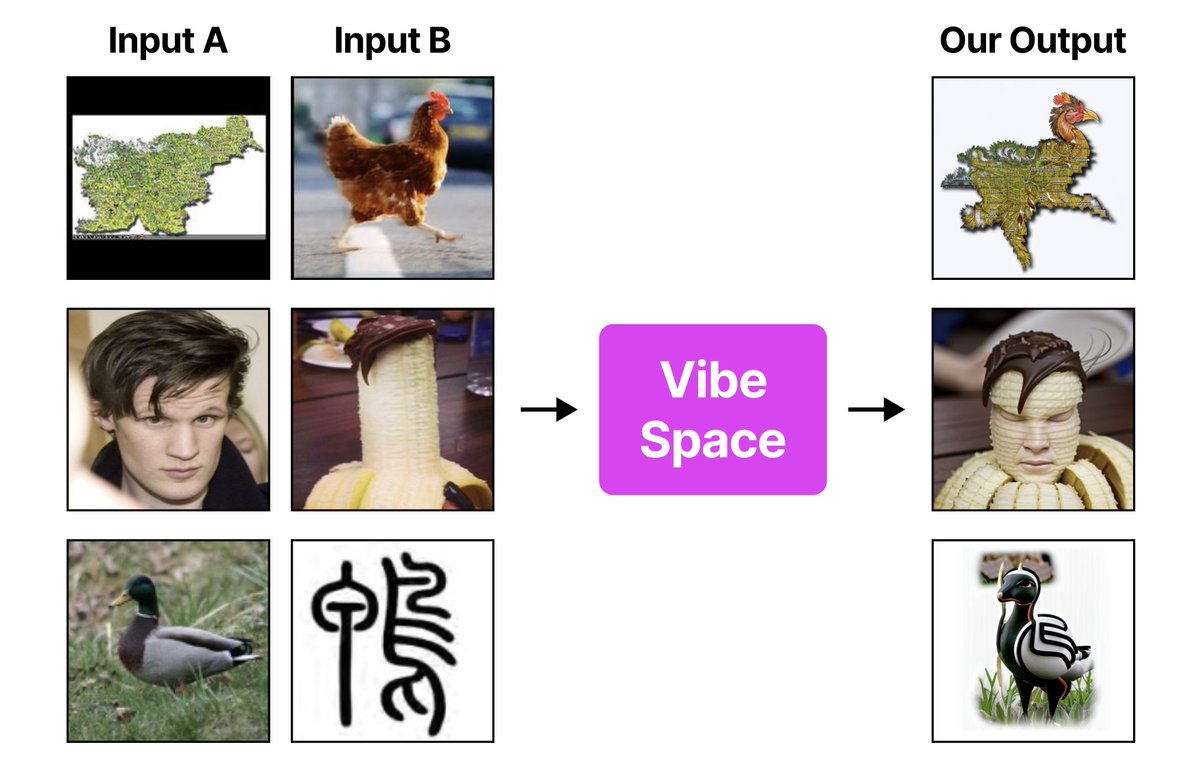







Creating new visual concepts often requires connecting distinct ideas through the 𝗺𝗼𝘀𝘁 𝗿𝗲𝗹𝗲𝘃𝗮𝗻𝘁 𝘀𝗵𝗮𝗿𝗲𝗱 𝗮𝘁𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝘀 — ✨ the vibe ✨
What we do:
1. Identify the vibe
2. Creatively connect the vibe
📄 arxiv.org/abs/2512.14884
🌐 huzeyann.github.io/VibeSpace…
1
3
305
Katherine (Kate) Xu retweeted

New paper: Back into Plato’s Cave
Are vision and language models converging to the same representation of reality? The Platonic Representation Hypothesis says yes. BUT we find the evidence for this is more fragile than it looks.
Project page: akoepke.github.io/cave_umwel…
1/9
6
68
337
89,593
Katherine (Kate) Xu retweeted

19 Nov 2025
Today we’re excited to unveil a new generation of Segment Anything Models:
1️⃣ SAM 3 enables detecting, segmenting and tracking of objects across images and videos, now with short text phrases and exemplar prompts.
🔗 Learn more about SAM 3: go.meta.me/591040
2️⃣ SAM 3D brings the model collection into the 3rd dimension to enable precise reconstruction of 3D objects and people from a single 2D image.
🔗 Learn more about SAM 3D: go.meta.me/305985
These models offer innovative capabilities and unique tools for developers and researchers to create, experiment and uplevel media workflows.
140
594
3,575
1,087,082
Katherine (Kate) Xu retweeted

27 Jun 2025
What would a World Model look like if we start from a real embodied agent acting in the real world?
It has to have: 1) A real, physically grounded and complex action space—not just abstract control signals. 2) Diverse, real-life scenarios and activities.
Or in short:
It has to be annoyingly complex—in both the action and vision space—to even get close to real life.
We did an initial attempt: Whole-Body Conditioned Egocentric Video Prediction.
In collaboration with @dans_t123 , @_amirbar, @ylecun , @trevordarrell and @JitendraMalikCV.
(For more details, check: arxiv.org/abs/2506.21552)
What we did is very simple: Predict Egocentric Video from human Actions (PEVA) - Given the past video and a future action represented by relative 3D body pose, PEVA predicts how the world looks next—from the first-person view.
By conditioning on kinematic pose trajectories, structured by the joint hierarchy of the body, it learns how physical actions shape perception.
32
133
530
176,864
Katherine (Kate) Xu retweeted

17 Jun 2024
Synthetic data has huge potential to drive new improvements in training and evaluation for computer vision. Interested in learning more about advancements and challenges? Join us at the SynData4CV Workshop at #CVPR2024 tomorrow (June 18)!
syndata4cv.github.io
14 Jun 2024

Calling all #CVPR2024 attendees!
Join us at the SynData4CV Workshop at @CVPR (Jun 18 full day at Summit 423-425) to learn more about recent advancements in synthetic data!
Explore more: syndata4cv.github.io/
6
32
4,969
Katherine (Kate) Xu retweeted

18 Apr 2024
What do you see in these images?
These are called hybrid images, originally proposed by Aude Oliva et al. They change appearance depending on size or viewing distance, and are just one kind of perceptual illusion that our method, Factorized Diffusion, can make.
10
100
447
59,199

7 Apr 2024
Excited to share our #CVPR2024 Highlight paper! 🌟
“Amodal Completion via Progressive Mixed Context Diffusion”
Our method fully visualizes occluded objects using pretrained diffusion models (without finetuning!) by overcoming occlusion co-occurrence
k8xu.github.io/amodal
2
7
62
8,975
7 Apr 2024
⚖️ How can we judge whether an object is successfully completed?
Let’s use counterfactual reasoning!
Our intuition: Outpainting incomplete objects should generate more pixels for missing object parts than outpainting complete objects
1
2
448
7 Apr 2024
🎉 Finally, we can generate diverse completions per object, thanks to the pretrained diffusion model’s powerful image prior
Grateful for my co-authors @lingzhizhang_ Jianbo Shi, and delightfully surprised by 5 positive reviews highlight distinction
See you @CVPR in Seattle!
1
4
573
3 Apr 2024
Had a fun time attending NYC Computer Vision Day sharing my work on Amodal Completion via Progressive Mixed Context Diffusion #CVPR2024
Project page: k8xu.github.io/amodal/
Event: cs.nyu.edu/~fouhey/NYCVision…
Thank you to the organizers and sponsors! 🗽
3
7
35
5,109
Katherine (Kate) Xu retweeted
8 Dec 2023
I’ll be at #NeurIPS2023 next week! Super excited to present our spotlight work, DreamSim, with @xkungfu .
Come check out our poster (#127) on Wednesday morning, and please reach out if you want to chat about representation learning, synthetic data, and/or computer vision! (1/2)
16 Jun 2023

We’re releasing a new image similarity metric and dataset!
--> DreamSim: a metric which outperforms LPIPS, CLIP, and DINO on similarity and retrieval tasks
--> NIGHTS: a dataset of synthetic images with human similarity ratings
paper code data: dreamsim-nights.github.io/
1/n

1
11
58
15,149

Brain🧠and Deep-nets🤖are massive black boxes, we don’t know how they work.
Others use Deep-nets to explain the brain:🤖 ->🧠
We do the opposite:🧠->🤖
𝐁𝐫𝐚𝐢𝐧 𝐃𝐞𝐜𝐨𝐝𝐞𝐬 𝐃𝐞𝐞𝐩 𝐍𝐞𝐭𝐬
arxiv:arxiv.org/abs/2312.01280
webpage&video:huzeyann.github.io/brain-dec…
read on 🧵
4
14
64
15,079
Katherine (Kate) Xu retweeted

17 Aug 2023
Check out our #ICCV2023 work "NeuS2" (vcai.mpi-inf.mpg.de/projects…), which reconstructs high-quality 3D geometry from multi-view images in <2 minutes. We derived a new analytical formula of the second-order derivatives for ReLU-based MLPs, leading to an efficient CUDA implementation.
3
54
297
43,642
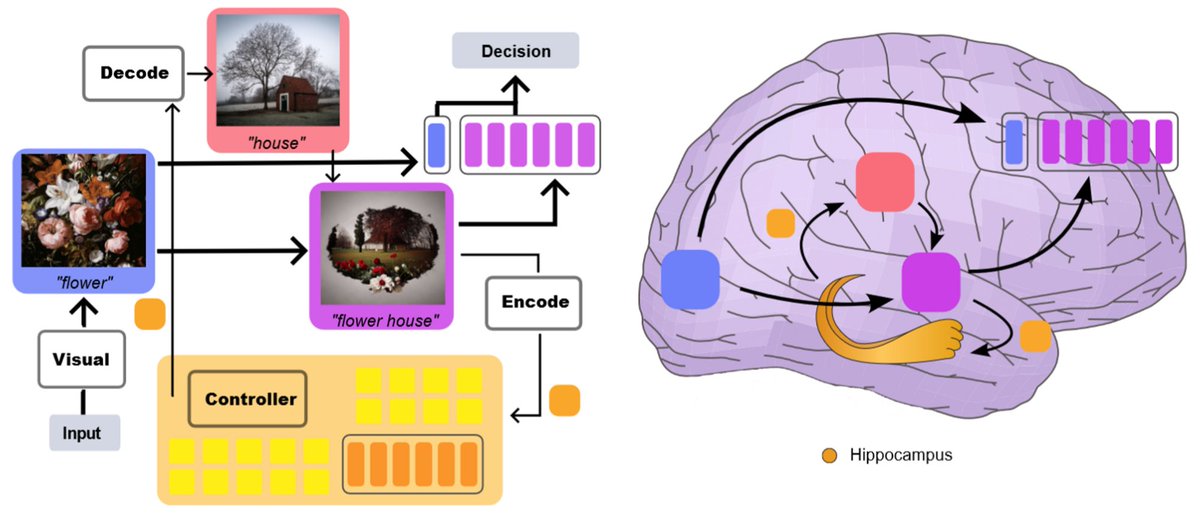
0/. Brain is not ViT. we scored 70.8 in the Algonauts 2023 visual brain competition, w/o ensemble we can do 66.8 score. other teams (including me in the past) are struggling with 60.
“memory” is the secret.
paper: arxiv.org/abs/2308.01175
code&webpage: huzeyann.github.io/mem
4
47
187
38,501
Katherine (Kate) Xu retweeted

20 Jul 2023
In our #ICCV2023 paper, we find the existence of common features we call “Rosetta Neurons” across a variety of models with different architectures, sources of supervision. and training datasets.
abs: arxiv.org/abs/2306.09346
proj: yossigandelsman.github.io/ro…
1/n
19 Jul 2023

Happy to share that our paper has been accepted at #ICCV2023!
2
4
37
5,705