
Researcher at NVIDIA // ex-Researcher at Microsoft, PhD from MIT EECS
Joined February 2020
- Tweets 73
- Following 317
- Followers 720
- Likes 91
12 Photos and videos






Kwangjun Ahn retweeted

13 Nov 2025
sacled up to 12.7B dense, 5.5T tokens.
- polynorm (optimized kernel)
- grouped diff attn (their work)
- parallel muonclip (adopt alltoall like mainhorse, essential, dion)
- 80M batch
it's still non-reasoning, also not moe though... keep pushing guys!
arxiv.org/abs/2511.07464
24 Aug 2025

they also dropped fsdp2 optimized muon. though they don't use muon for 2.6b dense model, i think it's just beginning and they are preparing larger one. they pipeline muon's comm-comp with calc flops and the code is neat. not sure if it's existing method.
huggingface.co/Motif-Technol…



3
18
124
16,948

29 Sep 2025
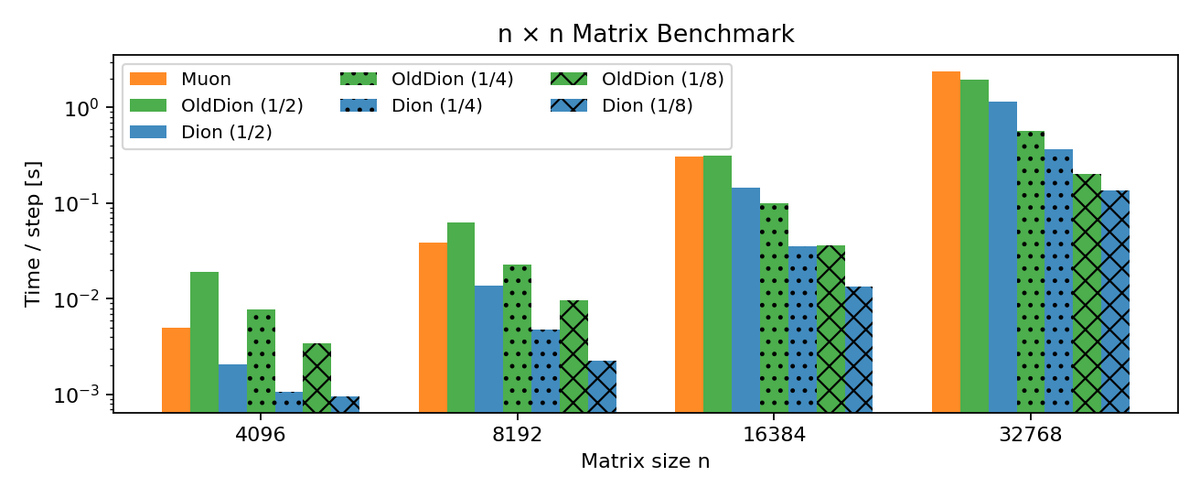
New improvement in Dion leads to a speedup that makes orthonormal updates (eg. Muon) more scalable for larger matrices. The trick: carefully using Newton-Schulz (on smaller matrices) as Dion's backend. Updates to our microsoft/dion codebase are coming soon---stay tuned!
1
4
27
2,467
Kwangjun Ahn retweeted

11 Sep 2025
Join us on Sept 24 at 8 AM PT for Microsoft Research Forum Season 2 – a virtual series highlighting purposeful research and its real-world impact, from fundamental exploration to advancing AI responsibly, scaling innovation through products and open source, and driving positive change for society. Register now: msft.it/6011scy27
1
3
25
5,793
Kwangjun Ahn retweeted

3 Aug 2025
love the repo! clean code, good practices but still not overly over-engineered, triton kernels, well documented, simple reference implementations alongside optimized code. nice
2
5
203
30,845
Kwangjun Ahn retweeted

3 Aug 2025
Lot, lot of alpha here

3 Aug 2025

I had wondered why there was no official Dion implementation by the authors... I guess now we know. This repository looks dope: FSDP Muon and Dion implementations, triton kernels for Newton-Schulz, and lots of practical advice
(1/2)
3
11
169
23,958
Kwangjun Ahn retweeted

3 Aug 2025
Looks like extremely exciting and useful work by @KwangjunA, Byron Xu, Natalie Abreu, @JohnCLangford and @GagMagakyan
github.com/microsoft/dion/
(2/2)
4
15
140
9,870
Kwangjun Ahn retweeted
3 Aug 2025
I had wondered why there was no official Dion implementation by the authors... I guess now we know. This repository looks dope: FSDP Muon and Dion implementations, triton kernels for Newton-Schulz, and lots of practical advice
(1/2)
7
18
332
75,209
Kwangjun Ahn retweeted

21 Jul 2025
[1/6] Curious about Muon, but not sure where to start? I wrote a 3-part blog series called “Understanding Muon” designed to get you up to speed—with The Matrix references, annotated source code, and thoughts on where Muon might be going.

7
42
341
35,945
Kwangjun Ahn retweeted

20 Jul 2025
Apparently Dion is now being worked on for Torch Titan: github.com/pytorch/torchtita… :-)
18 Jul 2025

Since nobody asked :-), here is my list of papers not to be missed from ICML:
1) Dion: distributed orthonormalized updates (well, technically not at ICML, but everyone's talking about it).
2) MARS: Unleashing the Power of Variance Reduction for Training Large Models
3) ...
8
102
21,387
Kwangjun Ahn retweeted

18 Jul 2025
Since nobody asked :-), here is my list of papers not to be missed from ICML:
1) Dion: distributed orthonormalized updates (well, technically not at ICML, but everyone's talking about it).
2) MARS: Unleashing the Power of Variance Reduction for Training Large Models
3) ...
6
31
424
68,667
Kwangjun Ahn retweeted

16 Jul 2025
But actually this is the og way of doing it and should stop by E-2103 to see @jxbz and Laker Newhouse whiteboard the whole paper.

16 Jul 2025
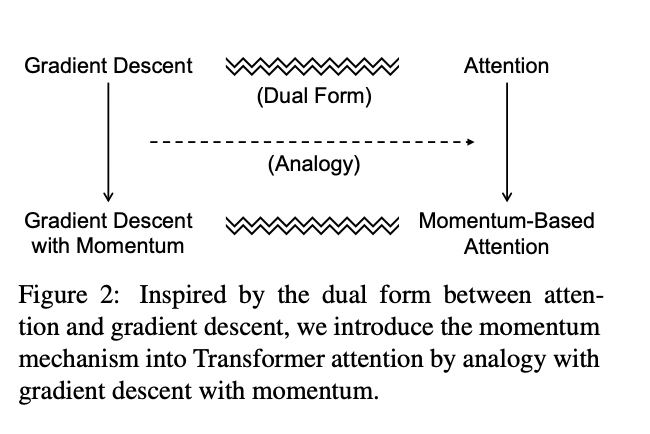
Laker and I are presenting this work in an hour at ICML poster E-2103. It’s on a theoretical framework and language (modula) for optimizers that are fast (like Shampoo) and scalable (like muP). You can think of modula as Muon extended to general layer types and network topologies

1
5
73
8,310
Kwangjun Ahn retweeted

15 Jul 2025
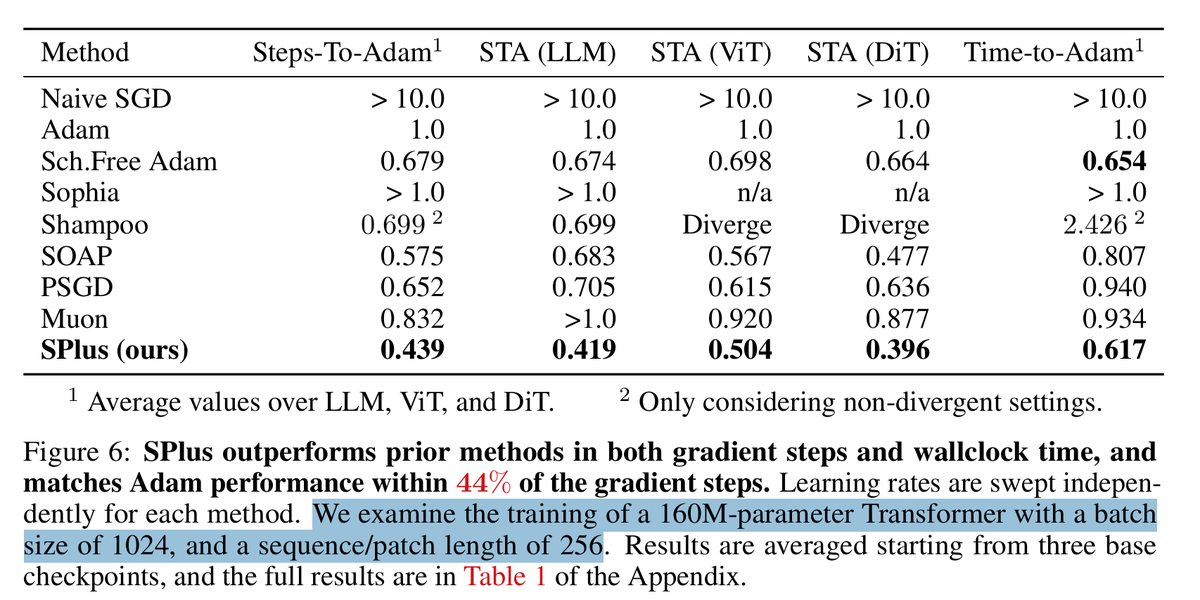
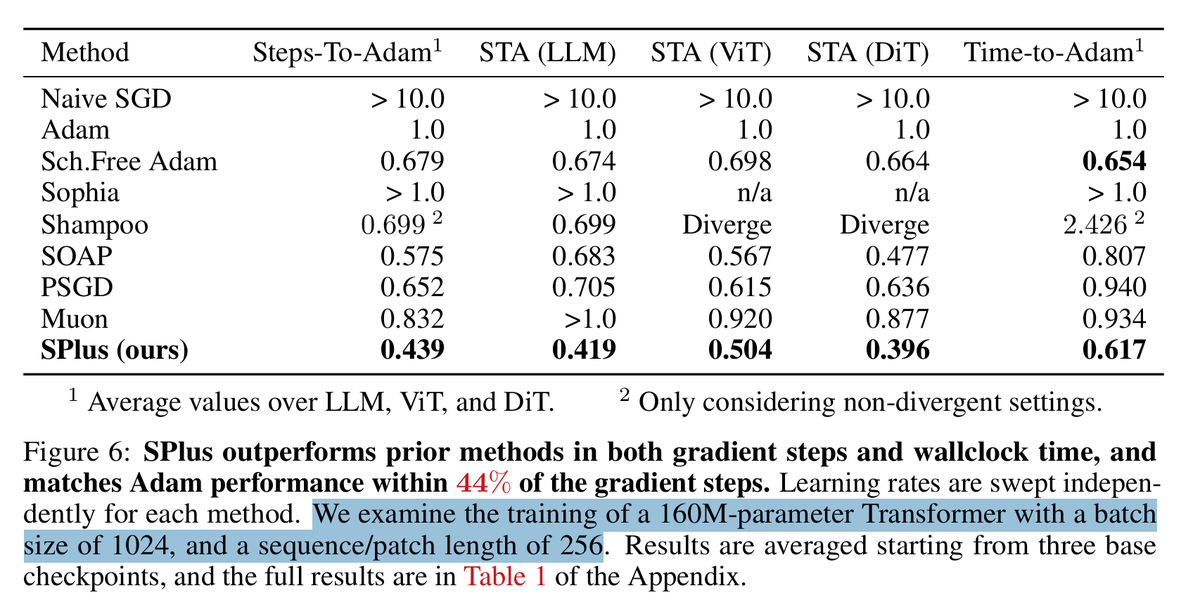
Schedule-Free methods, which forgo cosine/linear schedulers by averaging iterates and computing gradients at interpolated points, yield smoother training curves. It's still unclear why they work well, and this paper explains the phenomenon through the river-valley loss landscape.

4
17
140
13,639
Kwangjun Ahn retweeted

15 Jul 2025
If you are at ICML 2025, come check out our oral presentation about the non-convex theory of Schedule Free SGD in the Optimization session tomorrow!
This work was done with amazing collaborators @KwangjunA and @AshokCutkosky.
1
1
3
486
15 Jul 2025
ICML: come check out our Oral Presentation on Schedule-free training theory based on an elegant online learning!
7
49
3,254
Kwangjun Ahn retweeted
21 Jun 2025
1
2
18
1,077
Kwangjun Ahn retweeted

12 Jun 2025
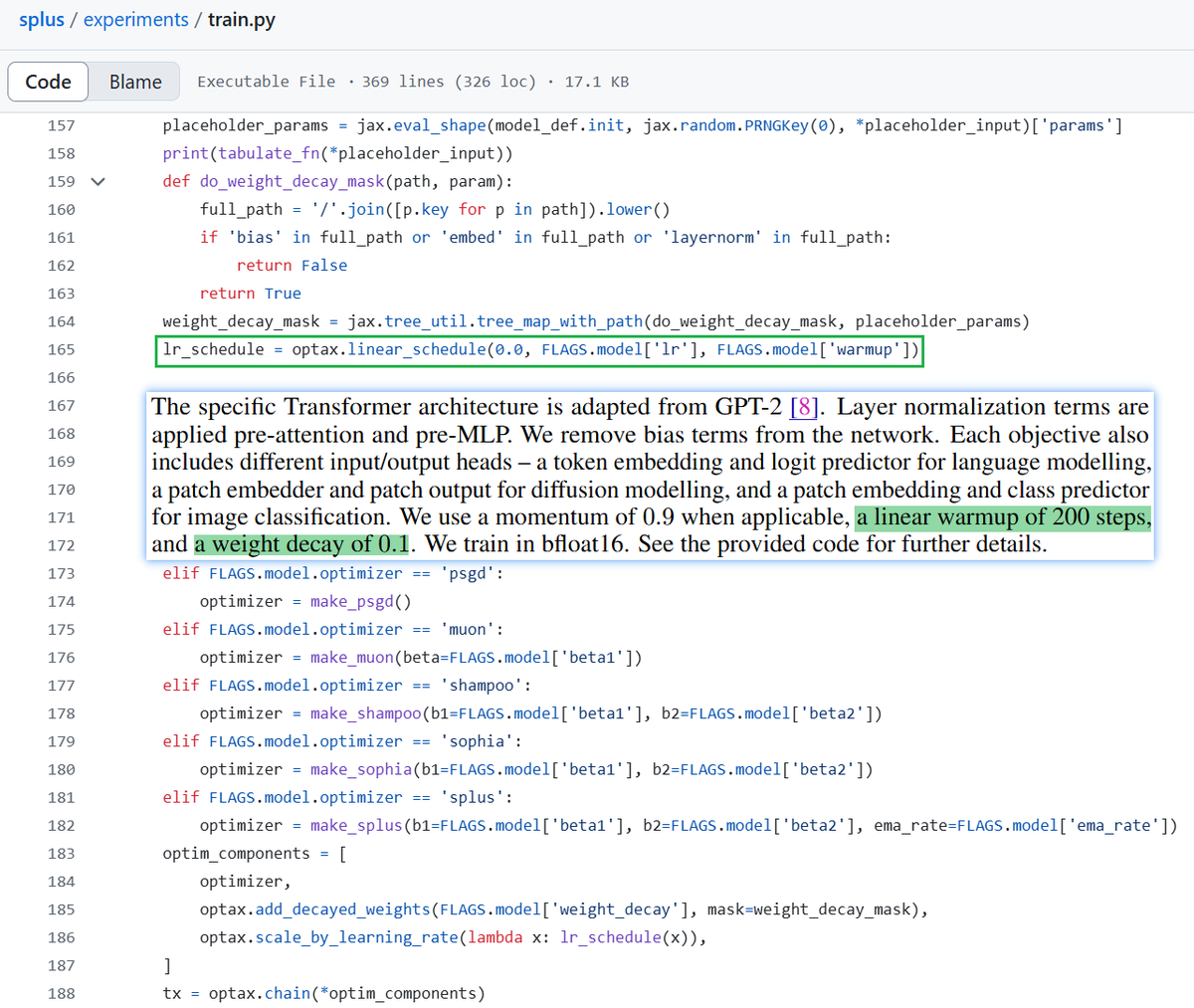
Oh I found them:
linear warmup and then constant
1
1
10
1,798
23 Apr 2025
ICLR:
@edward_s_hu and I will be presenting our work "The Belief State Transformer" at the 1st poster session. (#269) Please come check it out! (github: github.com/microsoft/BST)
15
692
Kwangjun Ahn retweeted
21 Apr 2025
The Belief State Transformer edwardshu.com/bst-website/ is at ICLR this week. The BST objective efficiently creates compact belief states: summaries of the past sufficient for all future predictions. See the short talk: microsoft.com/en-us/research… and @mgostIH for further discussion.
5
18
106
16,313
Kwangjun Ahn retweeted
23 Sep 2024
New reqs for low to high level researcher positions:
jobs.careers.microsoft.com/g… ,
jobs.careers.microsoft.com/g…,
jobs.careers.microsoft.com/g…,
jobs.careers.microsoft.com/g…,
with postdocs from Akshay and @MiroDudik x.com/MiroDudik/status/18367… . Please apply or pass to those who may :-)
31
108
36,141
Kwangjun Ahn retweeted
23 Sep 2024
Last year, we had offers accepted from @KwangjunA, @riashatislam, @Tea_Pearce , @pratyusha_PS while Akshay and @MiroDudik hired 7(!) postdocs.
23 Sep 2024

New reqs for low to high level researcher positions:
jobs.careers.microsoft.com/g… ,
jobs.careers.microsoft.com/g…,
jobs.careers.microsoft.com/g…,
jobs.careers.microsoft.com/g…,
with postdocs from Akshay and @MiroDudik x.com/MiroDudik/status/18367… . Please apply or pass to those who may :-)
2
12
4,222