
I have worn many hats. I’m a herder of no cats. I'm a #healthcare #DataScientist who not-so-secretly also loves rocks and volcanoes. Opinions are just mine.
Joined June 2009
- Tweets 4,840
- Following 3,002
- Followers 828
- Likes 16,781
117 Photos and videos











I am Paula retweeted

Jun 11
The founder’s life:
– Try something new.
– Get punched in the face (repeat).
– Pivot from the “brilliant” idea that failed.
– Lose sleep, feel entirely alone.
– Your runway is now negative.
– Hear “no” 1,000 times.
– Realize that nobody will save you.
Keep going anyway.
137
87
1,091
35,355

26 Sep 2024
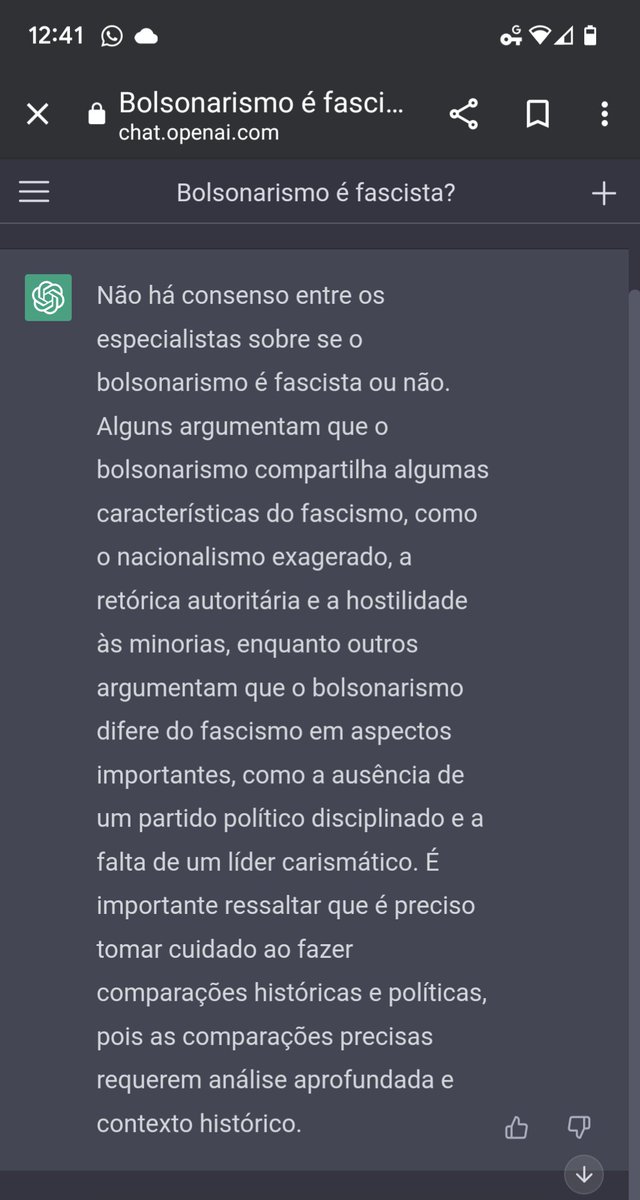
Now I know why this A.M. there was a door out of order in a brand new train. I've worked on starting up large scale eng projects, it's not that different from sending SW to production, 💩 happens even if you think you've thoroughly tested your system. The crew will sort it out

2
130
I am Paula retweeted

11 Sep 2024
🔥🔥Vice President Harris: “Those dictators are rooting for you because they know they can manipulate you with flattery and favors”
2,590
17,797
126,078
3,802,503
7 Aug 2024
Hey @Caltrain I know we're about to travel on the new EMUs, but the old trains need some "love", in particular their RESTROOMS, they stink big time!! Riding on any car forces us to be disgusted for a good 45 minutes. Can the crew at least throw some disinfectant in those toilets?
126
I am Paula retweeted

26 Mar 2024
Been using this color generator for my landing pages.
Not sure there's a better tool out there tbh
54
511
5,616
525,577
I am Paula retweeted

26 Mar 2024
Trump is selling bibles, and Fox is blaming the bridge collapse on our “broken border.”
There’s a big sector of our society that has absolutely lost its collective marbles.
3,665
4,906
31,216
715,974
I am Paula retweeted

26 Mar 2024
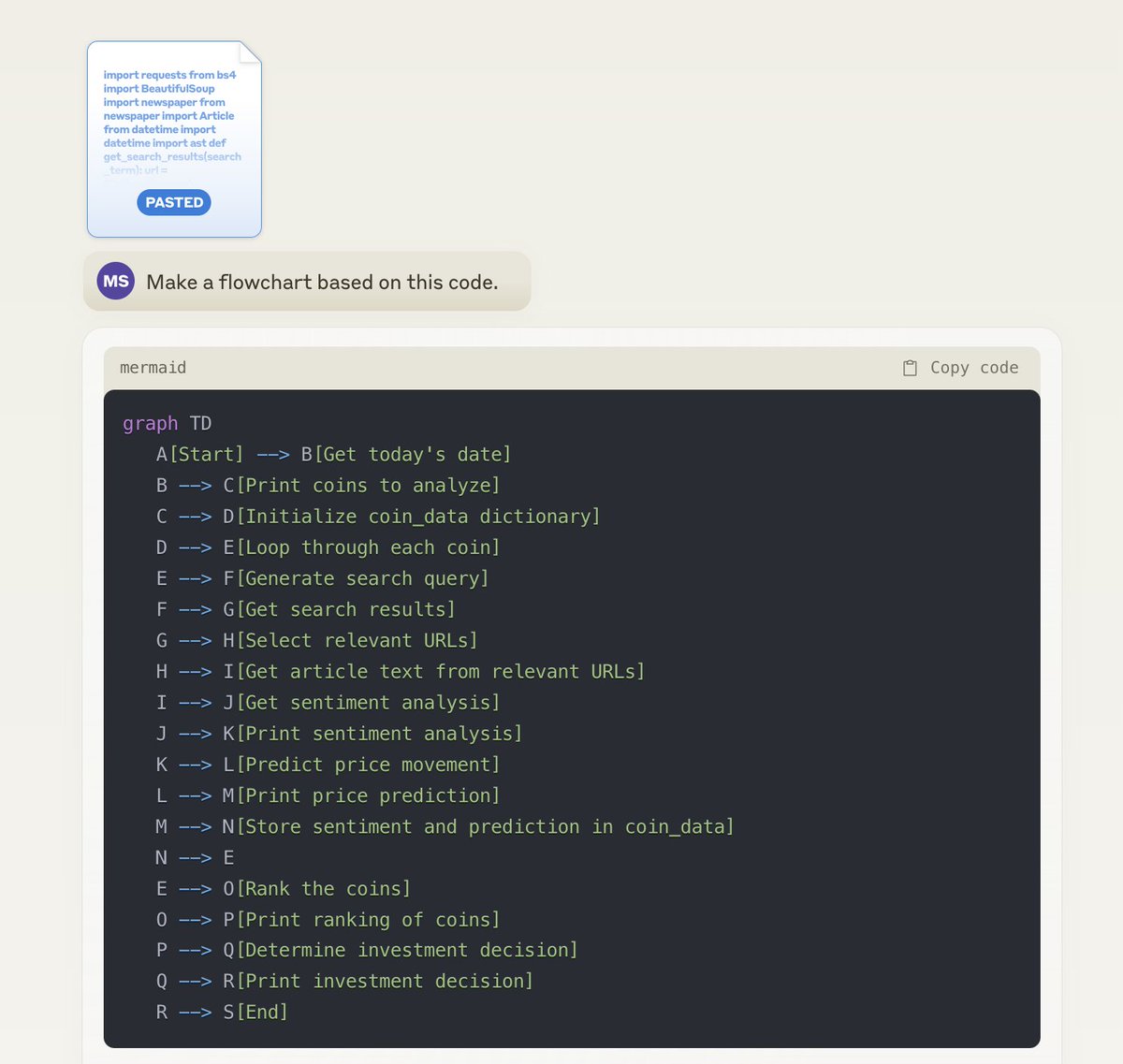
Useful Claude 3 trick to help you visualize code better.
Paste some code in, and ask it to make a flowchart.
Then, paste the flowchart code into a Mermaid viewer, and you'll get a nice, understandable visualization of your code!

37
132
1,344
122,353
I am Paula retweeted

2 Mar 2024
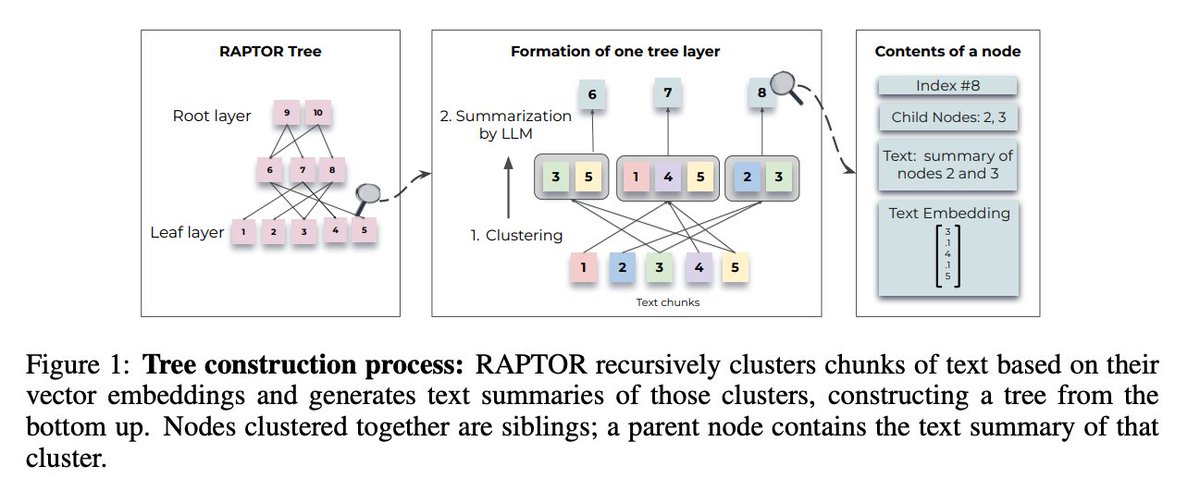
RAPTOR - a new tree-structured advanced RAG technique 🔥
A big issue with naive top-k RAG is that it retrieves low-level details best suited at answering questions over specific facts in the document.
But it struggles with any questions over higher-level context.
RAPTOR introduces a new tree-structured technique, which hierarchically clusters/summarizes chunks into a tree structure containing both high-level and low-level pieces. This lets you dynamically surface high-level / low-level context depending on the question.
For those of you who remember this is basically the grown-up version of gpt index v0, our beloved tree index 🌲
Thanks to MarouaneMaatouk and @LoganMarkewich, you can now access this as a LlamaPack in @llama_index 👇
Pack: llamahub.ai/l/llama-packs/ll…
Notebook: github.com/run-llama/llama_i…
Source paper: arxiv.org/pdf/2401.18059.pdf
12
84
504
104,594
I am Paula retweeted

2 Mar 2024
A lot of newer RAG techniques involve some form of query analysis - taking the raw user query and converting it into a more optimized version
We've added a bunch of new docs on this, including implementations of a bunch of techniques as well as some how-to guides
2 Mar 2024

✒️Query Analysis
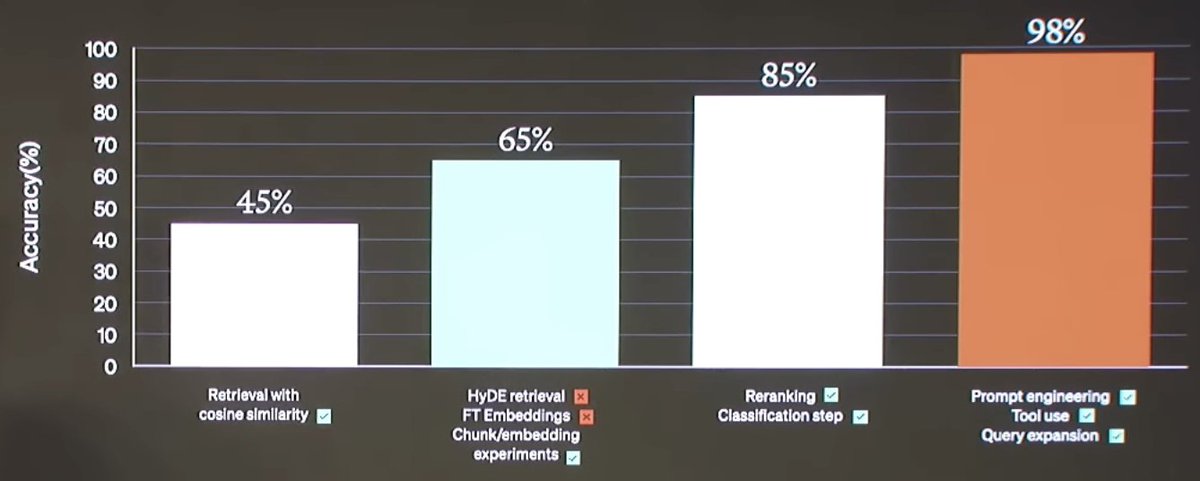
In OpenAI's retrieval talk on DevDay, they mention a bunch of strategies they experimented with
3 of these can be classified as **query analysis** a RAG technique that is becoming popular to do with LLMs
📄We've added a docs deep-dive on this
We cover six different techniques for query analysis including HyDE, Step Back Prompting, Structured Queries and more 🧪
We also have six in-depth how-to guides covering adding examples, dealing with multiple retrievers, and constructing filters 🪙
Check the docs out! We'll be pushing hard on this over the next week or so
Docs: python.langchain.com/docs/us…
2
11
132
15,816
12 Oct 2023
1
59
I am Paula retweeted

3 Oct 2023
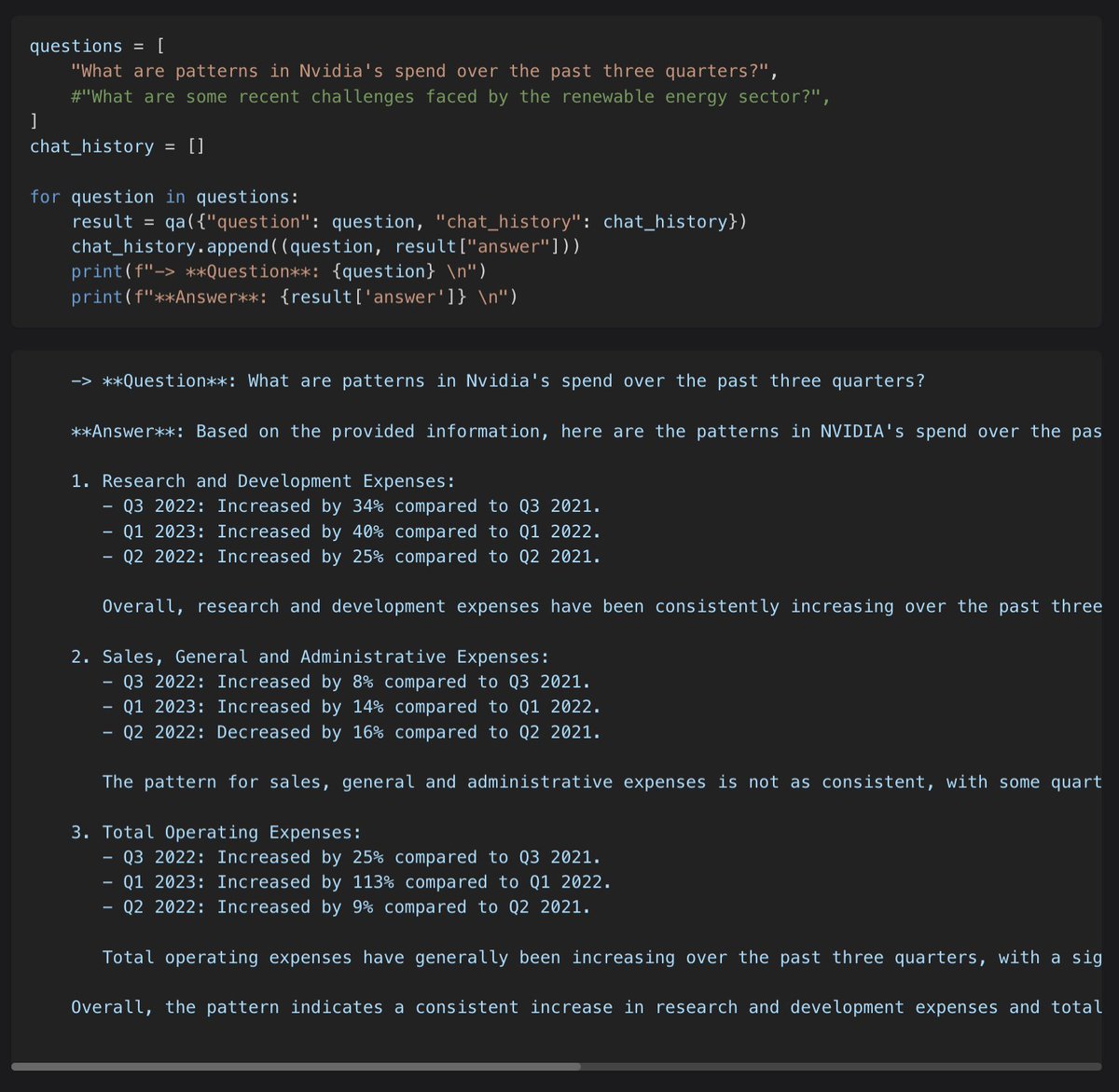
💼 Retrieve SEC Filings with LangChain
RAG infra for financial data is hard to get right. We need to parse tables, normalize entities, hybrid search, and experiment a lot.
With @Kaydotai and @CybersynInc, you can search SEC embeddings with an API ⚡️
python.langchain.com/docs/in…
7
64
340
65,026

Radiology-Llama2: Best-in-Class LLM for Radiology
Presents an LLM based on Llama 2 tailored for radiology. It's tuned on a large dataset of radiology reports to generate coherent and clinically useful impressions from radiology findings.
This an interesting use case of how to leverage instruction tuning for what I consider a hard and knowledge-intensive domain.
A few models are assessed and compared including the proposed model, Llama 2, Dolly, ChatGPT, and Alpaca. It seems that Radiology-Llama2 produces the top performance on a couple of benchmarks.
Great insights included!
arxiv.org/abs/2309.06419

3
58
294
50,564
I am Paula retweeted

27 Aug 2023
This talk is the most complete version of my thinking around Large Language Models to date, including thoughts on personal AI ethics, practical applications and the enormous impact we are already feeling from Llama 2
Video, slides, transcript & links: simonwillison.net/2023/Aug/2…
10
111
652
118,192
I am Paula retweeted

26 Aug 2023
Matt Mochary is a Silicon Valley legend.
He's coached the founders of OpenAI, Notion, Rippling, Robinhood, Coinbase, Reddit, @naval, and many others.
His entire course is open-sourced, even the templates. Here's a link 👇
docs.google.com/document/d/1…

57
836
4,890
1,152,063
I am Paula retweeted

17 Jul 2023
It’s still important to ship fast to learn.
But you won’t learn anything if your product is too buggy.
The key is to cut product scope so much that you actually can ship something bug-free.
Cut every non-essential feature.
Ship fast, with small scope, high quality.
44
148
1,158
67,982
14 Jul 2023
I love words... and languages. Word of the day: rambunctious. North America, informal. Love it!!
45
I am Paula retweeted

17 May 2023
"Automated systems are often being used to extend bureaucracy, adding additional places to deflect responsibility." A great talk and thread on AI ethics and accountability: rachel.fast.ai/posts/2023-05…
16 May 2023

Friends with no previous interest in AI ethics have been asking me about it recently, so I want to share several underlying concepts about AI & power that are important to understand. 🧵 1/
5
8
6,906
30 Jun 2023
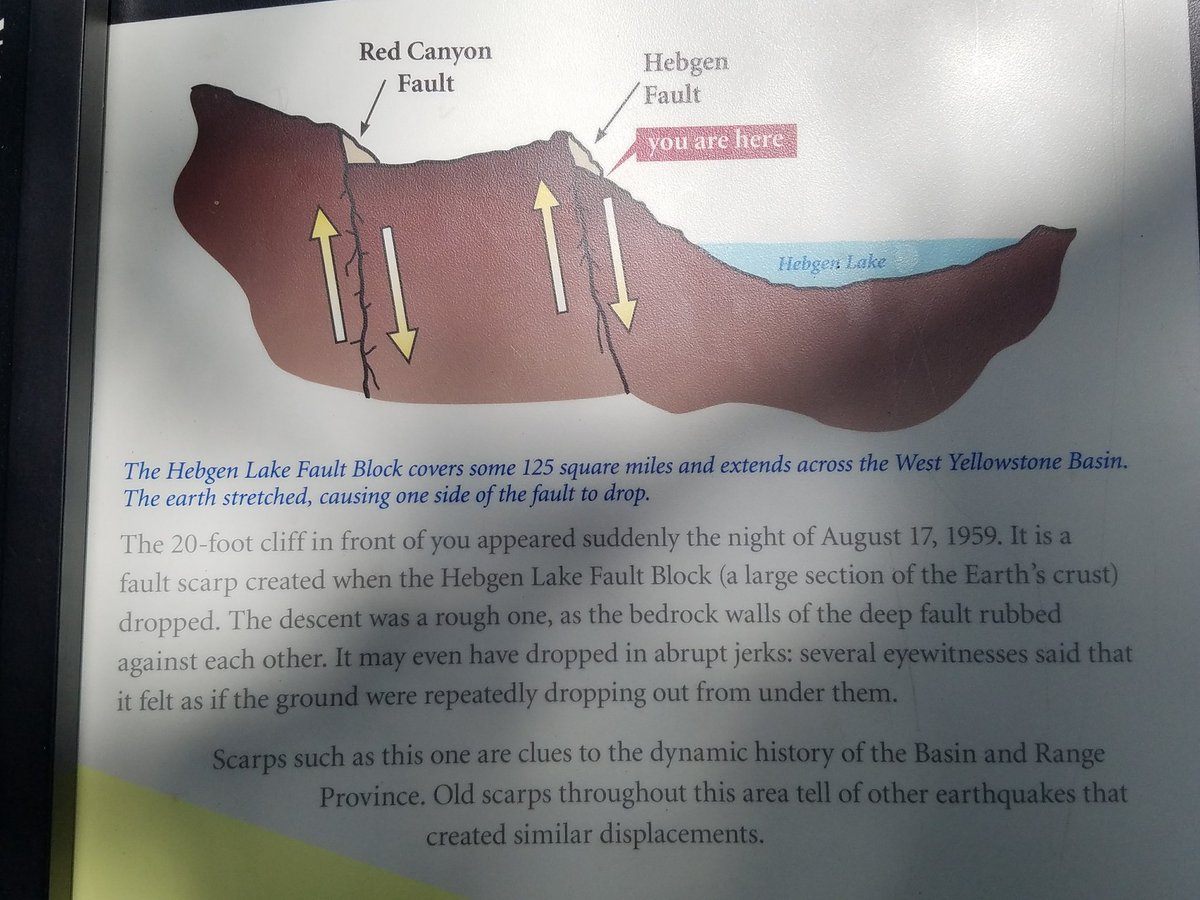
“Race is not a biologic proxy,” said Wright. “Race is a social construct and has no place being embedded in a clinical guideline like this.” 👏👏👏 statnews.com/2023/06/28/heal… via @statnews
45

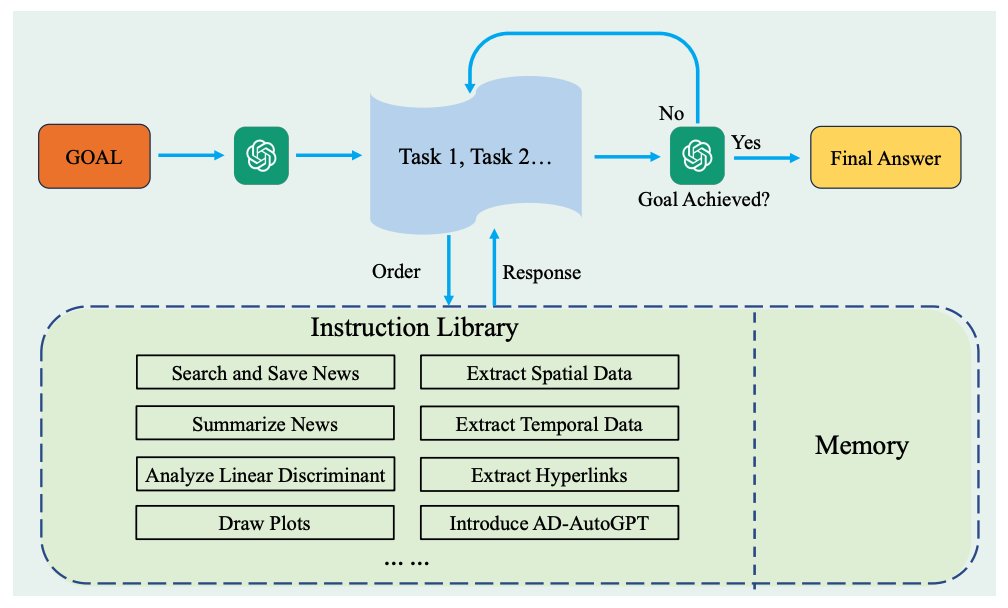
LLM Agent for Alzheimer’s Disease Infodemiology
-Data collection, processing, analysis in autonomous manner
-Trend analysis, topic mapping, etc related to Alzheimer’s Disease across new sources for public health research
-Integrates dynamic visualization
arxiv.org/abs/2306.10095
6
44
215
31,294