
1 Photos and videos

Jan 5
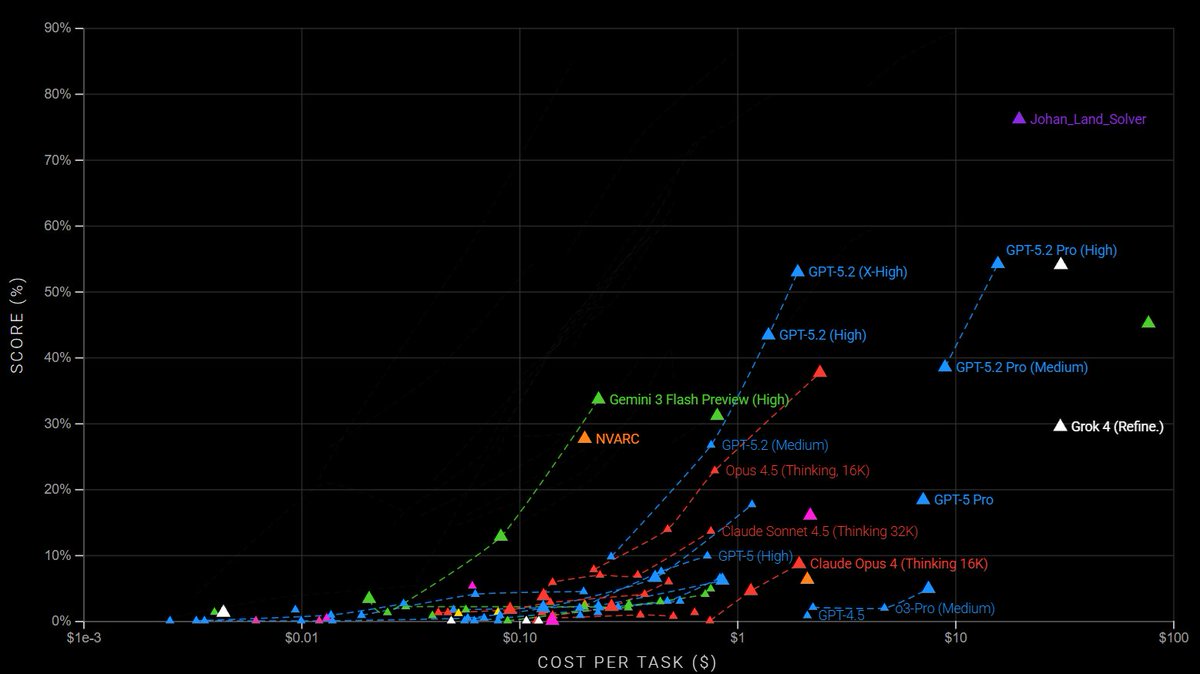
Just scored 76.11% on ARC-AGI 2 — beating public GPT-5.2 and Gemini-3-Pro baselines by >20%, and (as far as I know) the best publicly reported result so far.
Approach: what I’d call Multi-Model Reflective Reasoning
- Using GPT-5.2, Gemini-3, Opus 4.5
- Long-horizon/multi-step reasoning (~6hrs/problem)
- Agentic codegen (>100,000 python calls)
- Visual reasoning
- Council of judges
Fun fact: all solver code was written by Gemini-3-CLI.
Does this count as AI generating a new AI that beats the prior SOTA? 🤔
Full run code (open source): kaggle.com/code/johanland/jo…
@GregKamradt , holiday break is over 🙂 semi-private when?
#ARCAGI #AIResearch
17
9
92
3,949
17 Apr 2012
J Wales: "The majority of edits... are from... 600-1000 people". Waat? Not in line with #csn12 data? 10:30 @ alturl.com/ortjz
2